 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Self-Supervised, Differentiable Kalman Filter for Uncertainty-Aware Visual-Inertial Odometry
Mar 14, 2022
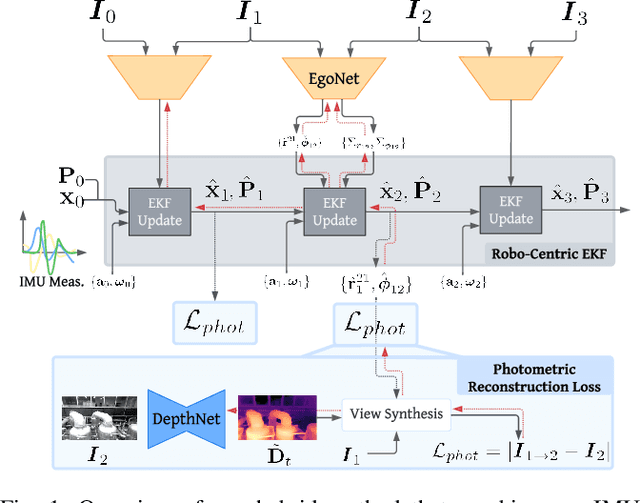
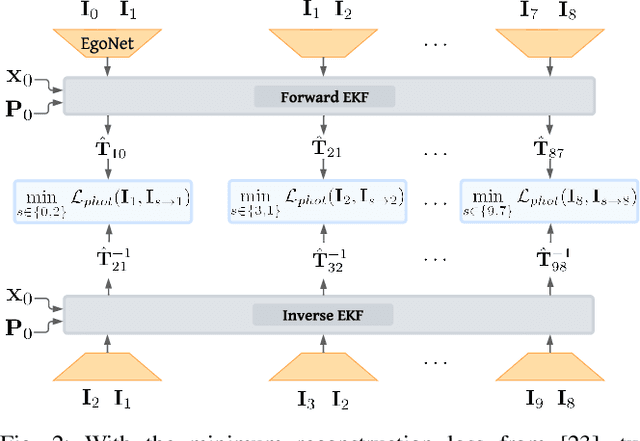
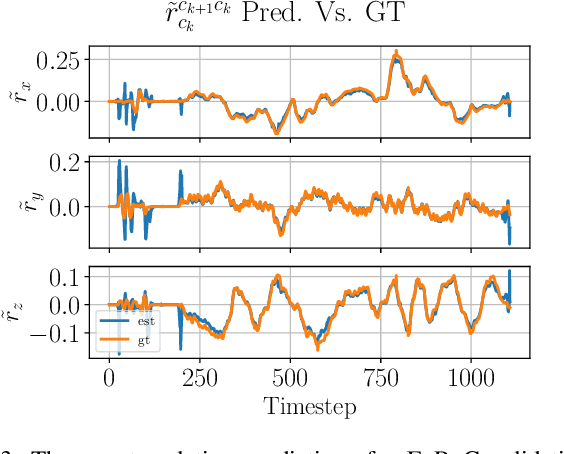

Traditionally, visual-inertial-odometry (VIO) systems rely on filtering or optimization-based frameworks for robot egomotion estimation. While these methods are accurate under nominal conditions, they are prone to failure in degraded environments, where illumination changes, fast camera motion, or textureless scenes are present. Learning-based systems have the potential to outperform classical implementations in degraded environments, but are, currently, less accurate than classical methods in nominal settings. A third class, of hybrid systems, attempts to leverage the advantages of both systems. Herein, we introduce a framework for training a hybrid VIO system. Our approach uses a differentiable Kalman filter with an IMU-based process model and a robust, neural network-based relative pose measurement model. By utilizing the data efficiency of self-supervised learning, we show that our system significantly outperforms a similar, supervised system, while enabling online retraining. To demonstrate the utility of our approach, we evaluate our system on a visually degraded version of the EuRoC dataset. Notably, we find that, in cases where classical estimators consistently diverge, our estimator does not diverge or suffer from a significant reduction in accuracy. Finally, our system, by properly utilizing the metric information contained in the IMU measurements, is able to recover metric scale, while other self-supervised monocular VIO approaches cannot.
Recurrent Neural Networks with Mixed Hierarchical Structures and EM Algorithm for Natural Language Processing
Jan 21, 2022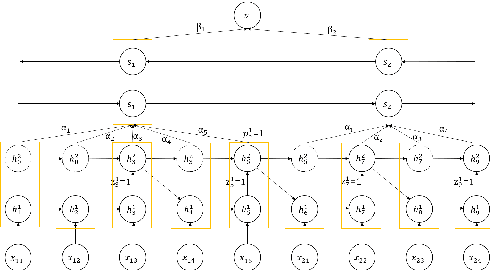

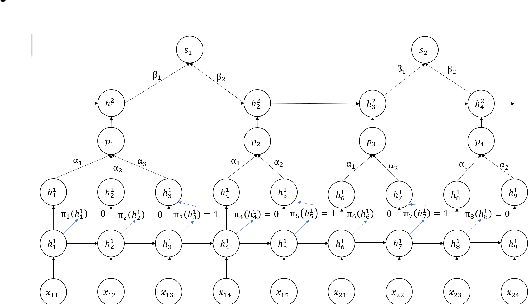
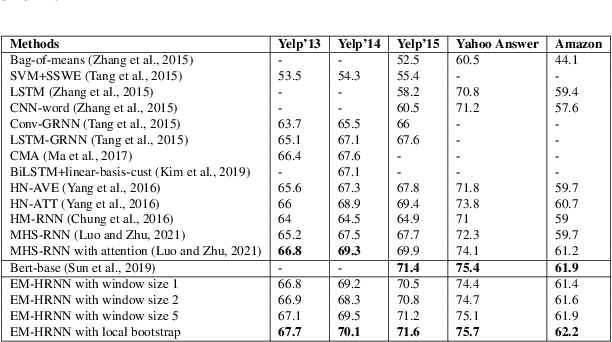
How to obtain hierarchical representations with an increasing level of abstraction becomes one of the key issues of learning with deep neural networks. A variety of RNN models have recently been proposed to incorporate both explicit and implicit hierarchical information in modeling languages in the literature. In this paper, we propose a novel approach called the latent indicator layer to identify and learn implicit hierarchical information (e.g., phrases), and further develop an EM algorithm to handle the latent indicator layer in training. The latent indicator layer further simplifies a text's hierarchical structure, which allows us to seamlessly integrate different levels of attention mechanisms into the structure. We called the resulting architecture as the EM-HRNN model. Furthermore, we develop two bootstrap strategies to effectively and efficiently train the EM-HRNN model on long text documents. Simulation studies and real data applications demonstrate that the EM-HRNN model with bootstrap training outperforms other RNN-based models in document classification tasks. The performance of the EM-HRNN model is comparable to a Transformer-based method called Bert-base, though the former is much smaller model and does not require pre-training.
Description-Driven Task-Oriented Dialog Modeling
Jan 21, 2022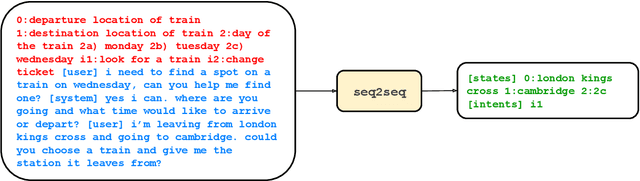

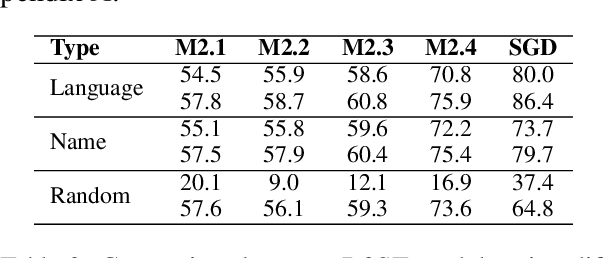

Task-oriented dialogue (TOD) systems are required to identify key information from conversations for the completion of given tasks. Such information is conventionally specified in terms of intents and slots contained in task-specific ontology or schemata. Since these schemata are designed by system developers, the naming convention for slots and intents is not uniform across tasks, and may not convey their semantics effectively. This can lead to models memorizing arbitrary patterns in data, resulting in suboptimal performance and generalization. In this paper, we propose that schemata should be modified by replacing names or notations entirely with natural language descriptions. We show that a language description-driven system exhibits better understanding of task specifications, higher performance on state tracking, improved data efficiency, and effective zero-shot transfer to unseen tasks. Following this paradigm, we present a simple yet effective Description-Driven Dialog State Tracking (D3ST) model, which relies purely on schema descriptions and an "index-picking" mechanism. We demonstrate the superiority in quality, data efficiency and robustness of our approach as measured on the MultiWOZ (Budzianowski et al.,2018), SGD (Rastogi et al., 2020), and the recent SGD-X (Lee et al., 2021) benchmarks.
Learning Invariable Semantical Representation from Language for Extensible Policy Generalization
Jan 26, 2022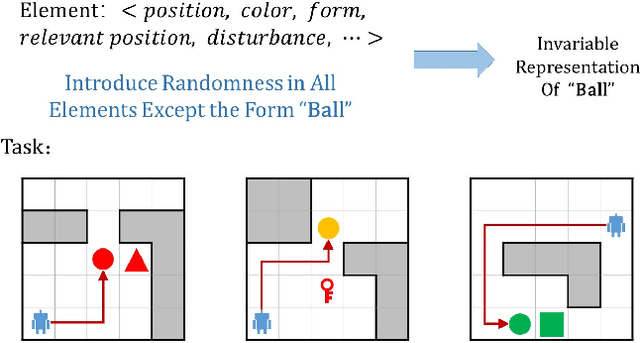
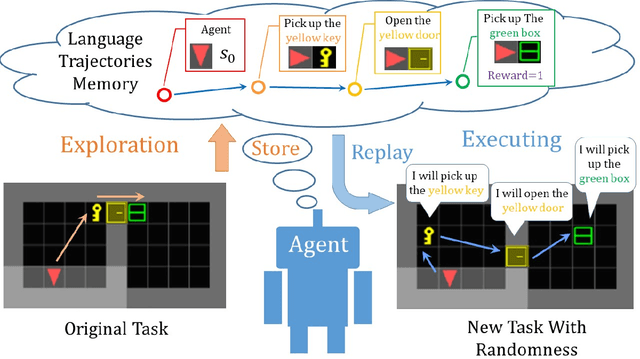
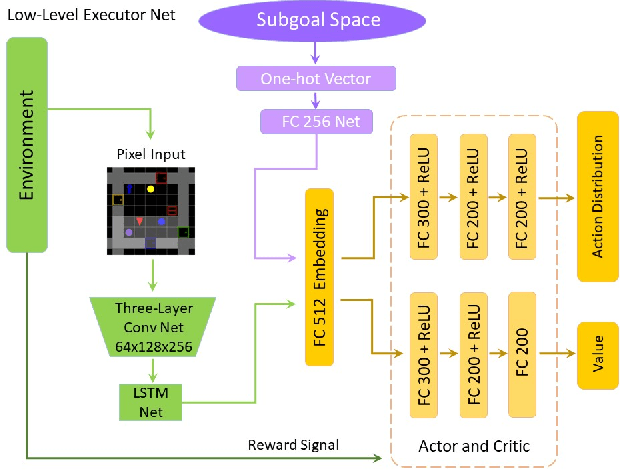
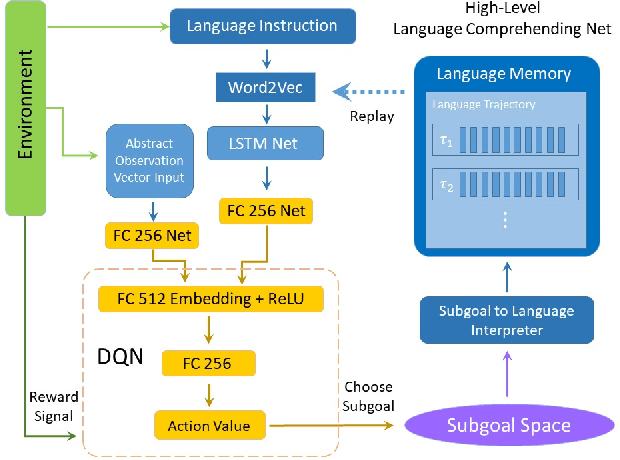
Recently, incorporating natural language instructions into reinforcement learning (RL) to learn semantically meaningful representations and foster generalization has caught many concerns. However, the semantical information in language instructions is usually entangled with task-specific state information, which hampers the learning of semantically invariant and reusable representations. In this paper, we propose a method to learn such representations called element randomization, which extracts task-relevant but environment-agnostic semantics from instructions using a set of environments with randomized elements, e.g., topological structures or textures, yet the same language instruction. We theoretically prove the feasibility of learning semantically invariant representations through randomization. In practice, we accordingly develop a hierarchy of policies, where a high-level policy is designed to modulate the behavior of a goal-conditioned low-level policy by proposing subgoals as semantically invariant representations. Experiments on challenging long-horizon tasks show that (1) our low-level policy reliably generalizes to tasks against environment changes; (2) our hierarchical policy exhibits extensible generalization in unseen new tasks that can be decomposed into several solvable sub-tasks; and (3) by storing and replaying language trajectories as succinct policy representations, the agent can complete tasks in a one-shot fashion, i.e., once one successful trajectory has been attained.
Physical Layer Authentication for LEO Satellite Constellations
Feb 17, 2022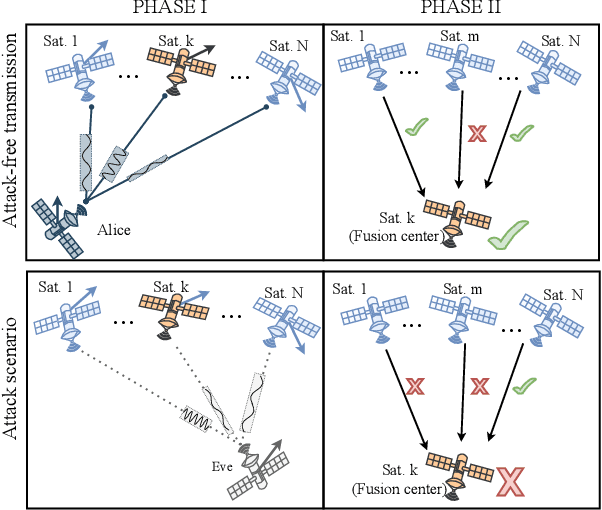
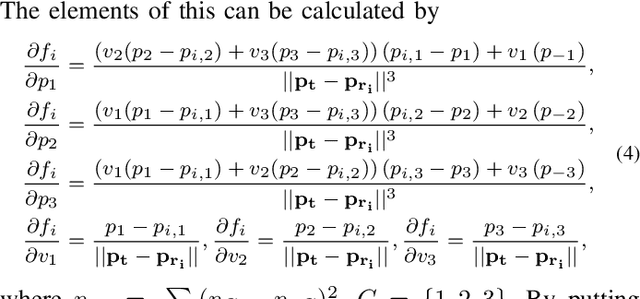
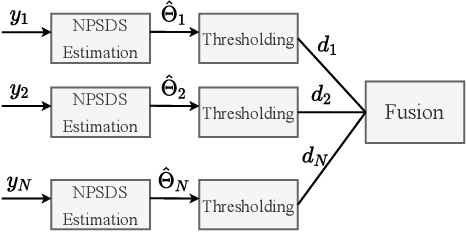
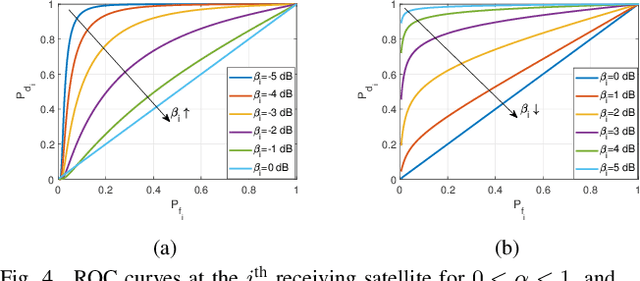
Physical layer authentication (PLA) is the process of claiming identity of a node based on its physical layer characteristics such as channel fading or hardware imperfections. In this work, we propose a novel PLA method for the inter-satellite communication links (ISLs) of the LEO satellites. In the proposed PLA method, multiple receiving satellites validate the identity of the transmitter by comparing the Doppler frequency measurements with the reference mobility information of the legitimate transmitter and then fuse their decision considering the selected decision rule. Analytical expressions are obtained for the spoofing detection probability and false alarm probability of the fusion methods. Numerically obtained high authentication performance results pave the way to a novel and easily integrable authentication mechanism for the LEO satellite networks.
Modeling Information Need of Users in Search Sessions
Jan 03, 2020


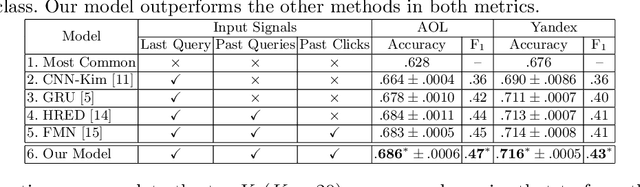
Users issue queries to Search Engines, and try to find the desired information in the results produced. They repeat this process if their information need is not met at the first place. It is crucial to identify the important words in a query that depict the actual information need of the user and will determine the course of a search session. To this end, we propose a sequence-to-sequence based neural architecture that leverages the set of past queries issued by users, and results that were explored by them. Firstly, we employ our model for predicting the words in the current query that are important and would be retained in the next query. Additionally, as a downstream application of our model, we evaluate it on the widely popular task of next query suggestion. We show that our intuitive strategy of capturing information need can yield superior performance at these tasks on two large real-world search log datasets.
Probing the Information Encoded in x-vectors
Sep 13, 2019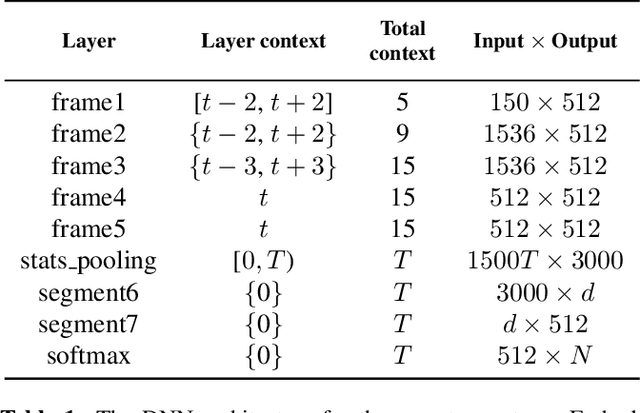
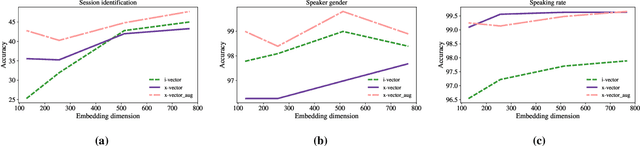

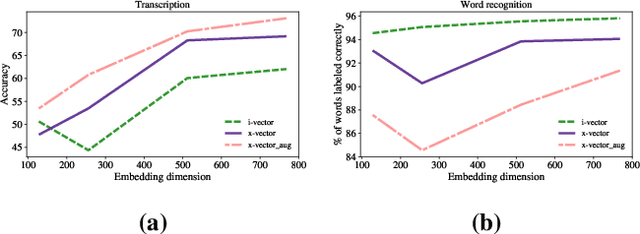
Deep neural network based speaker embeddings, such as x-vectors, have been shown to perform well in text-independent speaker recognition/verification tasks. In this paper, we use simple classifiers to investigate the contents encoded by x-vector embeddings. We probe these embeddings for information related to the speaker, channel, transcription (sentence, words, phones), and meta information about the utterance (duration and augmentation type), and compare these with the information encoded by i-vectors across a varying number of dimensions. We also study the effect of data augmentation during extractor training on the information captured by x-vectors. Experiments on the RedDots data set show that x-vectors capture spoken content and channel-related information, while performing well on speaker verification tasks.
Paper Plain: Making Medical Research Papers Approachable to Healthcare Consumers with Natural Language Processing
Feb 28, 2022
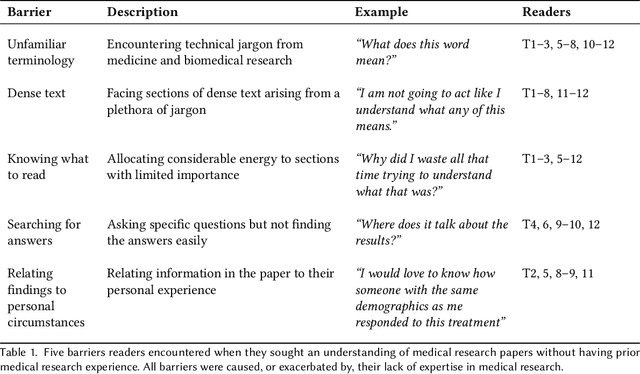

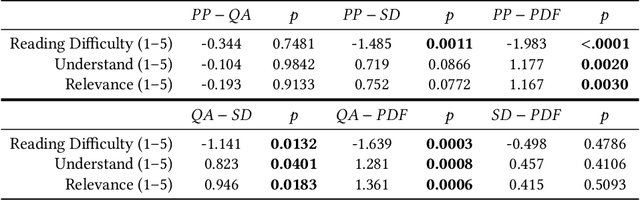
When seeking information not covered in patient-friendly documents, like medical pamphlets, healthcare consumers may turn to the research literature. Reading medical papers, however, can be a challenging experience. To improve access to medical papers, we introduce a novel interactive interface-Paper Plain-with four features powered by natural language processing: definitions of unfamiliar terms, in-situ plain language section summaries, a collection of key questions that guide readers to answering passages, and plain language summaries of the answering passages. We evaluate Paper Plain, finding that participants who use Paper Plain have an easier time reading and understanding research papers without a loss in paper comprehension compared to those who use a typical PDF reader. Altogether, the study results suggest that guiding readers to relevant passages and providing plain language summaries, or "gists," alongside the original paper content can make reading medical papers easier and give readers more confidence to approach these papers.
CNN LEGO: Disassembling and Assembling Convolutional Neural Network
Mar 25, 2022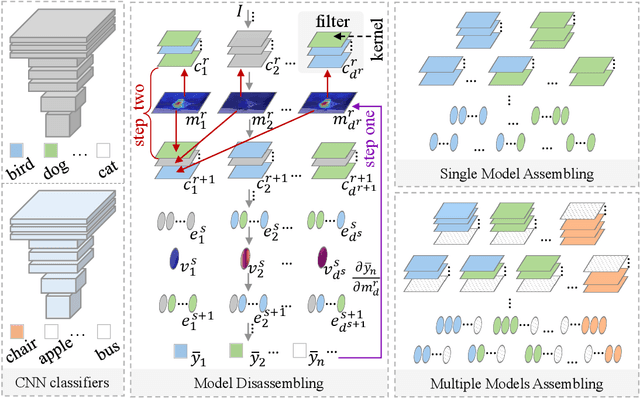
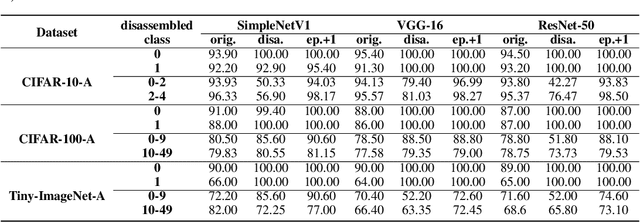
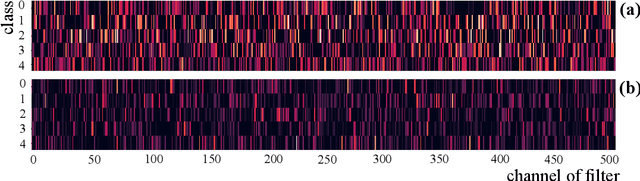
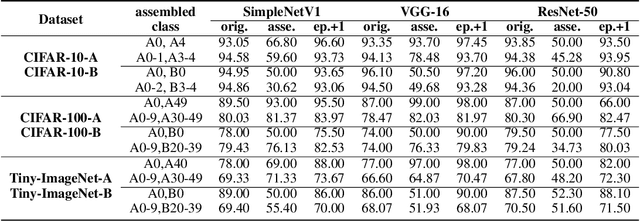
Convolutional Neural Network (CNN), which mimics human visual perception mechanism, has been successfully used in many computer vision areas. Some psychophysical studies show that the visual perception mechanism synchronously processes the form, color, movement, depth, etc., in the initial stage [7,20] and then integrates all information for final recognition [38]. What's more, the human visual system [20] contains different subdivisions or different tasks. Inspired by the above visual perception mechanism, we investigate a new task, termed as Model Disassembling and Assembling (MDA-Task), which can disassemble the deep models into independent parts and assemble those parts into a new deep model without performance cost like playing LEGO toys. To this end, we propose a feature route attribution technique (FRAT) for disassembling CNN classifiers in this paper. In FRAT, the positive derivatives of predicted class probability w.r.t. the feature maps are adopted to locate the critical features in each layer. Then, relevance analysis between the critical features and preceding/subsequent parameter layers is adopted to bridge the route between two adjacent parameter layers. In the assembling phase, class-wise components of each layer are assembled into a new deep model for a specific task. Extensive experiments demonstrate that the assembled CNN classifier can achieve close accuracy with the original classifier without any fine-tune, and excess original performance with one-epoch fine-tune. What's more, we also conduct massive experiments to verify the broad application of MDA-Task on model decision route visualization, model compression, knowledge distillation, transfer learning, incremental learning, and so on.
Back to Reality: Weakly-supervised 3D Object Detection with Shape-guided Label Enhancement
Mar 10, 2022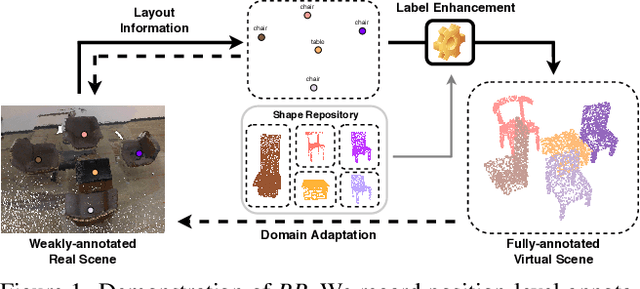

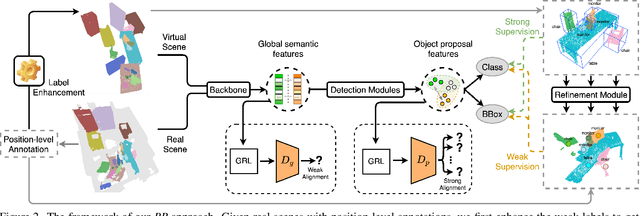

In this paper, we propose a weakly-supervised approach for 3D object detection, which makes it possible to train strong 3D detector with position-level annotations (i.e. annotations of object centers). In order to remedy the information loss from box annotations to centers, our method, namely Back to Reality (BR), makes use of synthetic 3D shapes to convert the weak labels into fully-annotated virtual scenes as stronger supervision, and in turn utilizes the perfect virtual labels to complement and refine the real labels. Specifically, we first assemble 3D shapes into physically reasonable virtual scenes according to the coarse scene layout extracted from position-level annotations. Then we go back to reality by applying a virtual-to-real domain adaptation method, which refine the weak labels and additionally supervise the training of detector with the virtual scenes. Furthermore, we propose a more challenging benckmark for indoor 3D object detection with more diversity in object sizes to better show the potential of BR. With less than 5% of the labeling labor, we achieve comparable detection performance with some popular fully-supervised approaches on the widely used ScanNet dataset. Code is available at: https://github.com/xuxw98/BackToReality