 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Written Theorems Explorable by Grounding Them in Formal Representations
Apr 03, 2026LLM-generated explanations can make technical content more accessible, but there is a ceiling on what they can support interactively. Because LLM outputs are static text, they cannot be executed or stepped through. We argue that grounding explanations in a formalized representation enables interactive affordances beyond what static text supports. We instantiate this idea for mathematical proof comprehension with explorable theorems, a system that uses LLMs to translate a theorem and its written proof into Lean, a programming language for machine-checked proofs, and links the written proof with the Lean code. Readers can work through the proof at a step-level granularity, test custom examples or counterexamples, and trace the logical dependencies bridging each step. Each worked-out step is produced by executing the Lean proof on that example and extracting its intermediate state. A user study ($n = 16$) shows potential advantages of this approach: in a proof-reading task, participants who had access to the provided explorability features gave better, more correct, and more detailed answers to comprehension questions, demonstrating a stronger overall understanding of the underlying mathematics.
LitPivot: Developing Well-Situated Research Ideas Through Dynamic Contextualization and Critique within the Literature Landscape
Apr 03, 2026Developing a novel research idea is hard. It must be distinct enough from prior work to claim a contribution while also building on it. This requires iteratively reviewing literature and refining an idea based on what a researcher reads; yet when an idea changes, the literature that matters often changes with it. Most tools offer limited support for this interplay: literature tools help researchers understand a fixed body of work, while ideation tools evaluate ideas against a static, pre-curated set of papers. We introduce literature-initiated pivots, a mechanism where engagement with literature prompts revision to a developing idea, and where that revision changes which literature is relevant. We operationalize this in LitPivot, where researchers concurrently draft and vet an idea. LitPivot dynamically retrieves clusters of papers relevant to a selected part of the idea and proposes literature-informed critiques for how to revise it. A lab study ($n{=}17$) shows researchers produced higher-rated ideas with stronger self-reported understanding of the literature space; an open-ended study ($n{=}5$) reveals how researchers use LitPivot to iteratively evolve their own ideas.
Scaling Text-Rich Image Understanding via Code-Guided Synthetic Multimodal Data Generation
Feb 20, 2025Reasoning about images with rich text, such as charts and documents, is a critical application of vision-language models (VLMs). However, VLMs often struggle in these domains due to the scarcity of diverse text-rich vision-language data. To address this challenge, we present CoSyn, a framework that leverages the coding capabilities of text-only large language models (LLMs) to automatically create synthetic text-rich multimodal data. Given input text describing a target domain (e.g., "nutrition fact labels"), CoSyn prompts an LLM to generate code (Python, HTML, LaTeX, etc.) for rendering synthetic images. With the underlying code as textual representations of the synthetic images, CoSyn can generate high-quality instruction-tuning data, again relying on a text-only LLM. Using CoSyn, we constructed a dataset comprising 400K images and 2.7M rows of vision-language instruction-tuning data. Comprehensive experiments on seven benchmarks demonstrate that models trained on our synthetic data achieve state-of-the-art performance among competitive open-source models, including Llama 3.2, and surpass proprietary models such as GPT-4V and Gemini 1.5 Flash. Furthermore, CoSyn can produce synthetic pointing data, enabling VLMs to ground information within input images, showcasing its potential for developing multimodal agents capable of acting in real-world environments.
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
Grounded Intuition of GPT-Vision's Abilities with Scientific Images
Nov 03, 2023GPT-Vision has impressed us on a range of vision-language tasks, but it comes with the familiar new challenge: we have little idea of its capabilities and limitations. In our study, we formalize a process that many have instinctively been trying already to develop "grounded intuition" of this new model. Inspired by the recent movement away from benchmarking in favor of example-driven qualitative evaluation, we draw upon grounded theory and thematic analysis in social science and human-computer interaction to establish a rigorous framework for qualitative evaluation in natural language processing. We use our technique to examine alt text generation for scientific figures, finding that GPT-Vision is particularly sensitive to prompting, counterfactual text in images, and relative spatial relationships. Our method and analysis aim to help researchers ramp up their own grounded intuitions of new models while exposing how GPT-Vision can be applied to make information more accessible.
CALYPSO: LLMs as Dungeon Masters' Assistants
Aug 15, 2023



The role of a Dungeon Master, or DM, in the game Dungeons & Dragons is to perform multiple tasks simultaneously. The DM must digest information about the game setting and monsters, synthesize scenes to present to other players, and respond to the players' interactions with the scene. Doing all of these tasks while maintaining consistency within the narrative and story world is no small feat of human cognition, making the task tiring and unapproachable to new players. Large language models (LLMs) like GPT-3 and ChatGPT have shown remarkable abilities to generate coherent natural language text. In this paper, we conduct a formative evaluation with DMs to establish the use cases of LLMs in D&D and tabletop gaming generally. We introduce CALYPSO, a system of LLM-powered interfaces that support DMs with information and inspiration specific to their own scenario. CALYPSO distills game context into bite-sized prose and helps brainstorm ideas without distracting the DM from the game. When given access to CALYPSO, DMs reported that it generated high-fidelity text suitable for direct presentation to players, and low-fidelity ideas that the DM could develop further while maintaining their creative agency. We see CALYPSO as exemplifying a paradigm of AI-augmented tools that provide synchronous creative assistance within established game worlds, and tabletop gaming more broadly.
Complex Mathematical Symbol Definition Structures: A Dataset and Model for Coordination Resolution in Definition Extraction
May 24, 2023Mathematical symbol definition extraction is important for improving scholarly reading interfaces and scholarly information extraction (IE). However, the task poses several challenges: math symbols are difficult to process as they are not composed of natural language morphemes; and scholarly papers often contain sentences that require resolving complex coordinate structures. We present SymDef, an English language dataset of 5,927 sentences from full-text scientific papers where each sentence is annotated with all mathematical symbols linked with their corresponding definitions. This dataset focuses specifically on complex coordination structures such as "respectively" constructions, which often contain overlapping definition spans. We also introduce a new definition extraction method that masks mathematical symbols, creates a copy of each sentence for each symbol, specifies a target symbol, and predicts its corresponding definition spans using slot filling. Our experiments show that our definition extraction model significantly outperforms RoBERTa and other strong IE baseline systems by 10.9 points with a macro F1 score of 84.82. With our dataset and model, we can detect complex definitions in scholarly documents to make scientific writing more readable.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
From Who You Know to What You Read: Augmenting Scientific Recommendations with Implicit Social Networks
Apr 21, 2022



The ever-increasing pace of scientific publication necessitates methods for quickly identifying relevant papers. While neural recommenders trained on user interests can help, they still result in long, monotonous lists of suggested papers. To improve the discovery experience we introduce multiple new methods for \em augmenting recommendations with textual relevance messages that highlight knowledge-graph connections between recommended papers and a user's publication and interaction history. We explore associations mediated by author entities and those using citations alone. In a large-scale, real-world study, we show how our approach significantly increases engagement -- and future engagement when mediated by authors -- without introducing bias towards highly-cited authors. To expand message coverage for users with less publication or interaction history, we develop a novel method that highlights connections with proxy authors of interest to users and evaluate it in a controlled lab study. Finally, we synthesize design implications for future graph-based messages.
Paper Plain: Making Medical Research Papers Approachable to Healthcare Consumers with Natural Language Processing
Feb 28, 2022
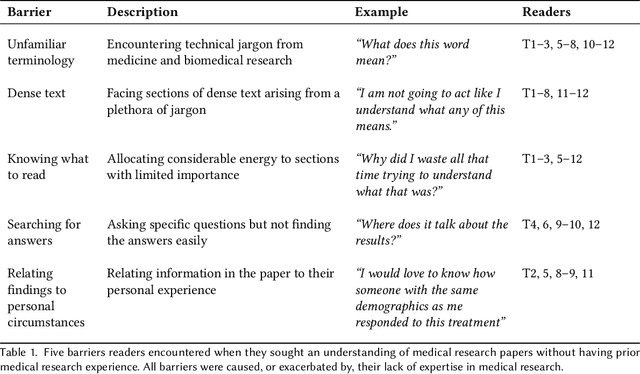

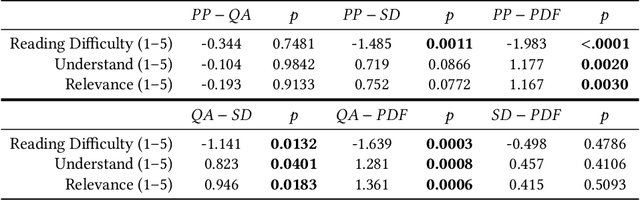
When seeking information not covered in patient-friendly documents, like medical pamphlets, healthcare consumers may turn to the research literature. Reading medical papers, however, can be a challenging experience. To improve access to medical papers, we introduce a novel interactive interface-Paper Plain-with four features powered by natural language processing: definitions of unfamiliar terms, in-situ plain language section summaries, a collection of key questions that guide readers to answering passages, and plain language summaries of the answering passages. We evaluate Paper Plain, finding that participants who use Paper Plain have an easier time reading and understanding research papers without a loss in paper comprehension compared to those who use a typical PDF reader. Altogether, the study results suggest that guiding readers to relevant passages and providing plain language summaries, or "gists," alongside the original paper content can make reading medical papers easier and give readers more confidence to approach these papers.