 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Information Encoded in X-vectors
Paper and Code
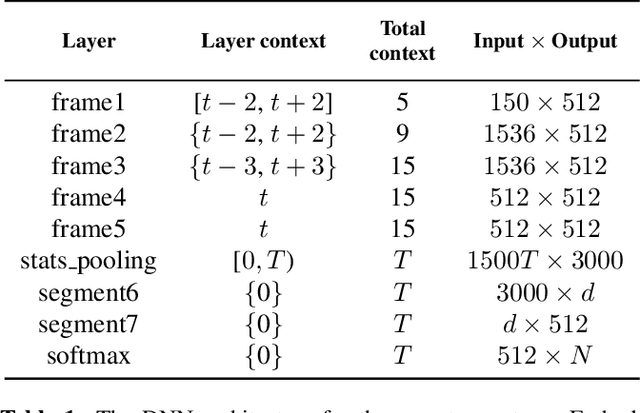
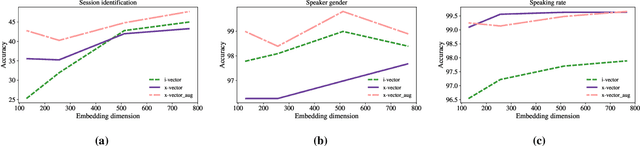

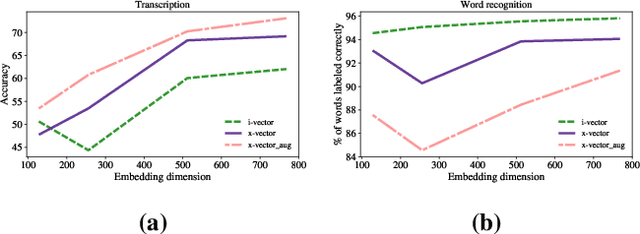
Deep neural network based speaker embeddings, such as x-vectors, have been shown to perform well in text-independent speaker recognition/verification tasks. In this paper, we use simple classifiers to investigate the contents encoded by x-vector embeddings. We probe these embeddings for information related to the speaker, channel, transcription (sentence, words, phones), and meta information about the utterance (duration and augmentation type), and compare these with the information encoded by i-vectors across a varying number of dimensions. We also study the effect of data augmentation during extractor training on the information captured by x-vectors. Experiments on the RedDots data set show that x-vectors capture spoken content and channel-related information, while performing well on speaker verification tasks.