 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Enriched Latent Visual Reasoning
May 19, 2026Multimodal latent-space reasoning aims to replace explicit thinking with images by performing visual reasoning directly in a compact latent space. However, existing approaches largely rely on visual supervision and produce latent representations that lack sufficient semantic richness, limiting their ability to support diverse region-level reasoning tasks. In this work, we introduce Semantic-Enriched Latent Visual Reasoning (SLVR), a two-stage learning framework that enriches latent representations with attribute-level visual semantics and aligns them with diverse reasoning objectives. In the first stage, SLVR learns semantically enriched region-centric latents under fine-grained attribute supervision. In the second stage, we design Multi-query Group Relative Policy Optimization (M-GRPO) to align latent representations across multiple queries grounded in the same region. To support this framework, we construct SLV-Set, comprising approximately 400K region-level attribute annotations and 800K multi-query question answering samples, and introduce SV-QA, a benchmark that evaluates latent reasoning under semantic variation. Experiments demonstrate that SLVR improves the robustness and semantic consistency of latent visual reasoning compared to existing baselines.
Learning Invariable Semantical Representation from Language for Extensible Policy Generalization
Jan 26, 2022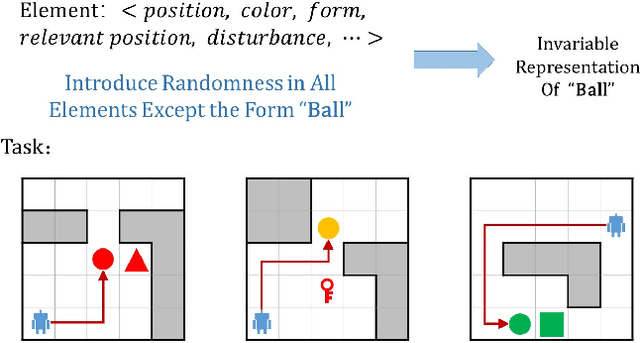
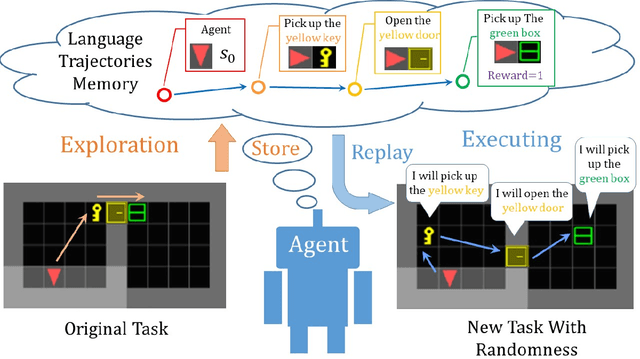
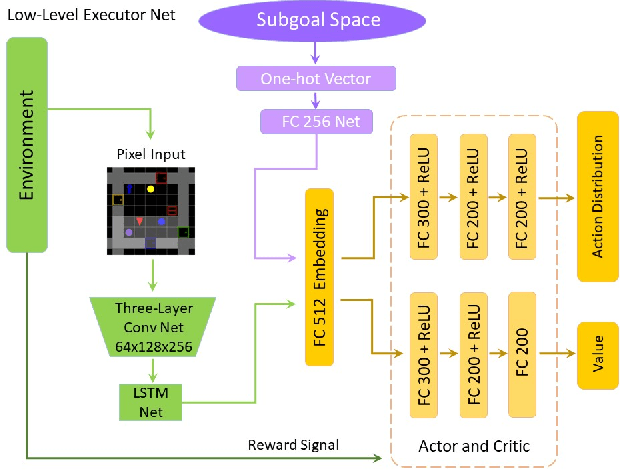
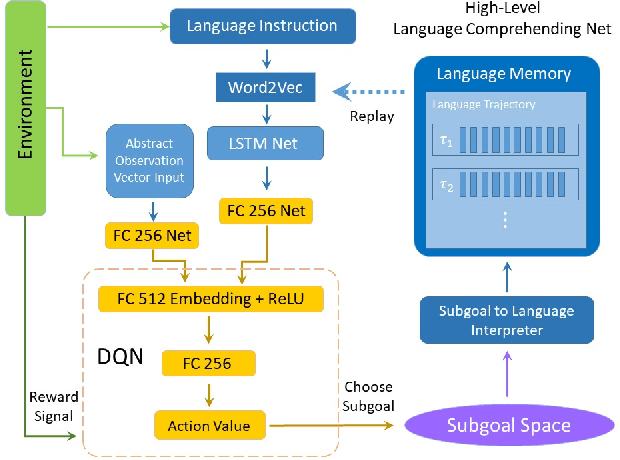
Recently, incorporating natural language instructions into reinforcement learning (RL) to learn semantically meaningful representations and foster generalization has caught many concerns. However, the semantical information in language instructions is usually entangled with task-specific state information, which hampers the learning of semantically invariant and reusable representations. In this paper, we propose a method to learn such representations called element randomization, which extracts task-relevant but environment-agnostic semantics from instructions using a set of environments with randomized elements, e.g., topological structures or textures, yet the same language instruction. We theoretically prove the feasibility of learning semantically invariant representations through randomization. In practice, we accordingly develop a hierarchy of policies, where a high-level policy is designed to modulate the behavior of a goal-conditioned low-level policy by proposing subgoals as semantically invariant representations. Experiments on challenging long-horizon tasks show that (1) our low-level policy reliably generalizes to tasks against environment changes; (2) our hierarchical policy exhibits extensible generalization in unseen new tasks that can be decomposed into several solvable sub-tasks; and (3) by storing and replaying language trajectories as succinct policy representations, the agent can complete tasks in a one-shot fashion, i.e., once one successful trajectory has been attained.