 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Onto4MAT: A Swarm Shepherding Ontology for Generalised Multi-Agent Teaming
Mar 24, 2022
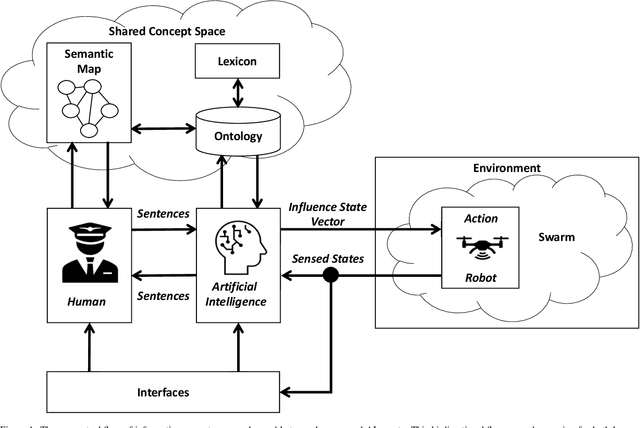
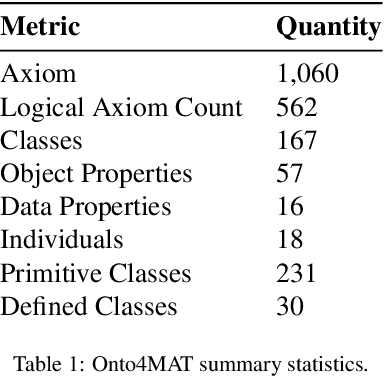
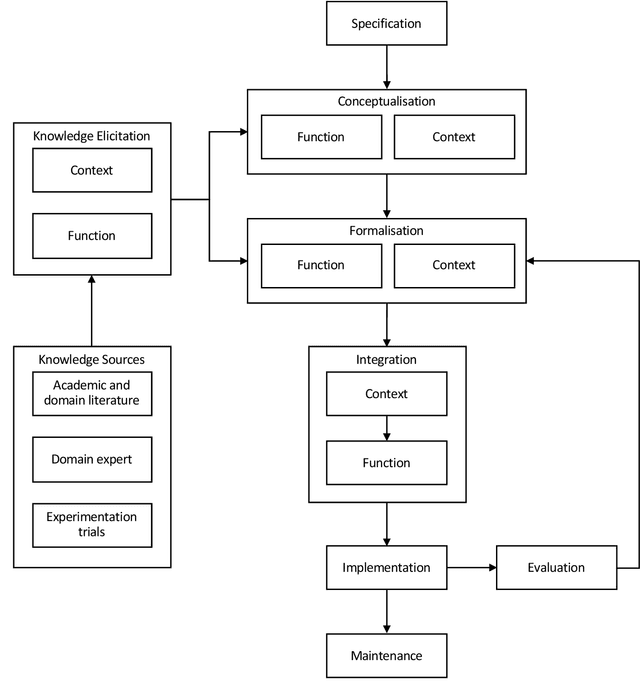
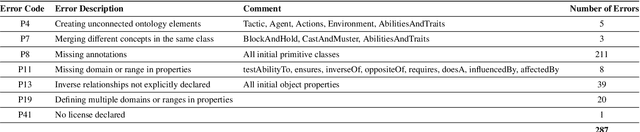
Research in multi-agent teaming has increased substantially over recent years, with knowledge-based systems to support teaming processes typically focused on delivering functional (communicative) solutions for a team to act meaningfully in response to direction. Enabling humans to effectively interact and team with a swarm of autonomous cognitive agents is an open research challenge in Human-Swarm Teaming research, partially due to the focus on developing the enabling architectures to support these systems. Typically, bi-directional transparency and shared semantic understanding between agents has not prioritised a designed mechanism in Human-Swarm Teaming, potentially limiting how a human and a swarm team can share understanding and information\textemdash data through concepts and contexts\textemdash to achieve a goal. To address this, we provide a formal knowledge representation design that enables the swarm Artificial Intelligence to reason about its environment and system, ultimately achieving a shared goal. We propose the Ontology for Generalised Multi-Agent Teaming, Onto4MAT, to enable more effective teaming between humans and teams through the biologically-inspired approach of shepherding.
FedVLN: Privacy-preserving Federated Vision-and-Language Navigation
Mar 28, 2022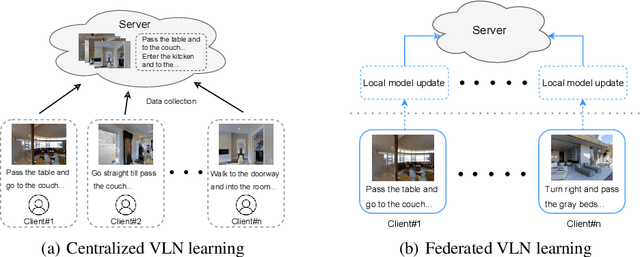
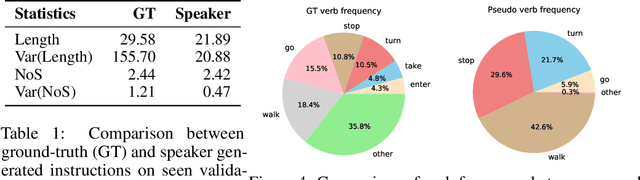
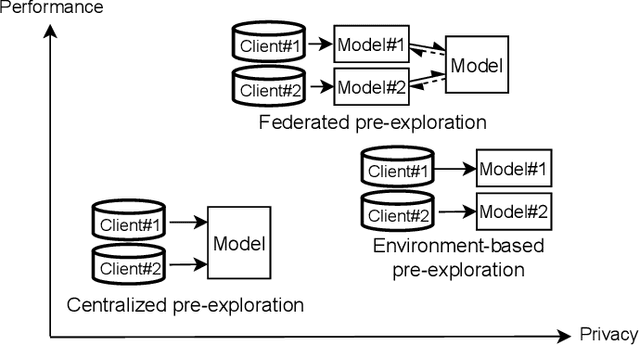
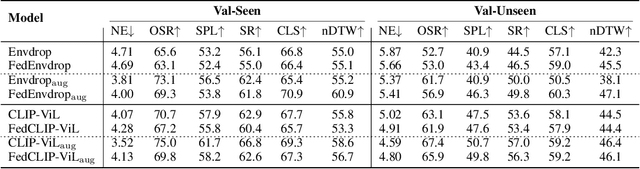
Data privacy is a central problem for embodied agents that can perceive the environment, communicate with humans, and act in the real world. While helping humans complete tasks, the agent may observe and process sensitive information of users, such as house environments, human activities, etc. In this work, we introduce privacy-preserving embodied agent learning for the task of Vision-and-Language Navigation (VLN), where an embodied agent navigates house environments by following natural language instructions. We view each house environment as a local client, which shares nothing other than local updates with the cloud server and other clients, and propose a novel federated vision-and-language navigation (FedVLN) framework to protect data privacy during both training and pre-exploration. Particularly, we propose a decentralized training strategy to limit the data of each client to its local model training and a federated pre-exploration method to do partial model aggregation to improve model generalizability to unseen environments. Extensive results on R2R and RxR datasets show that under our FedVLN framework, decentralized VLN models achieve comparable results with centralized training while protecting seen environment privacy, and federated pre-exploration significantly outperforms centralized pre-exploration while preserving unseen environment privacy.
Object Memory Transformer for Object Goal Navigation
Mar 24, 2022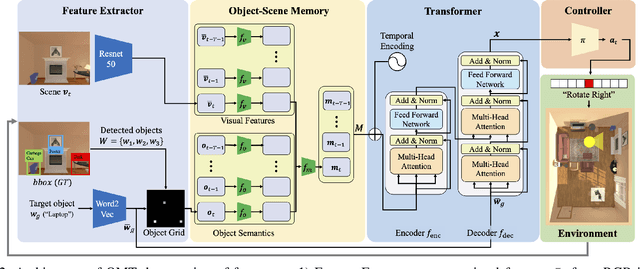
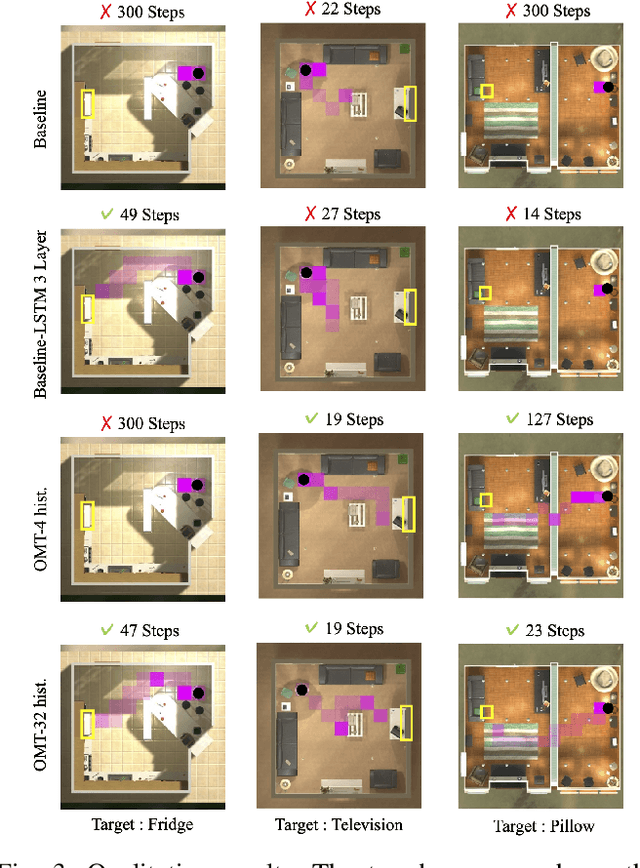
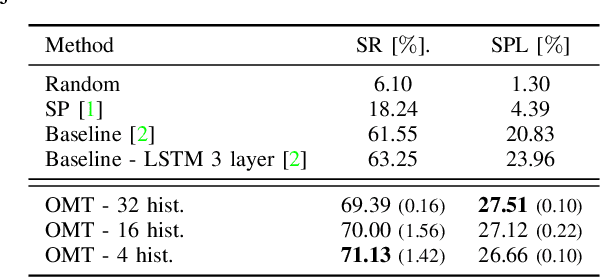
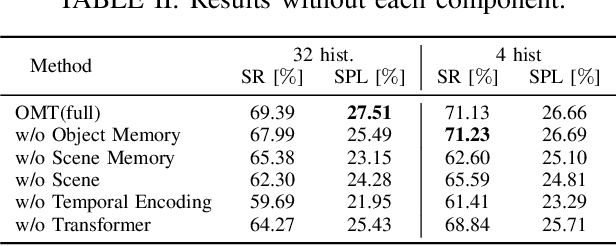
This paper presents a reinforcement learning method for object goal navigation (ObjNav) where an agent navigates in 3D indoor environments to reach a target object based on long-term observations of objects and scenes. To this end, we propose Object Memory Transformer (OMT) that consists of two key ideas: 1) Object-Scene Memory (OSM) that enables to store long-term scenes and object semantics, and 2) Transformer that attends to salient objects in the sequence of previously observed scenes and objects stored in OSM. This mechanism allows the agent to efficiently navigate in the indoor environment without prior knowledge about the environments, such as topological maps or 3D meshes. To the best of our knowledge, this is the first work that uses a long-term memory of object semantics in a goal-oriented navigation task. Experimental results conducted on the AI2-THOR dataset show that OMT outperforms previous approaches in navigating in unknown environments. In particular, we show that utilizing the long-term object semantics information improves the efficiency of navigation.
Learning Where to Learn in Cross-View Self-Supervised Learning
Mar 28, 2022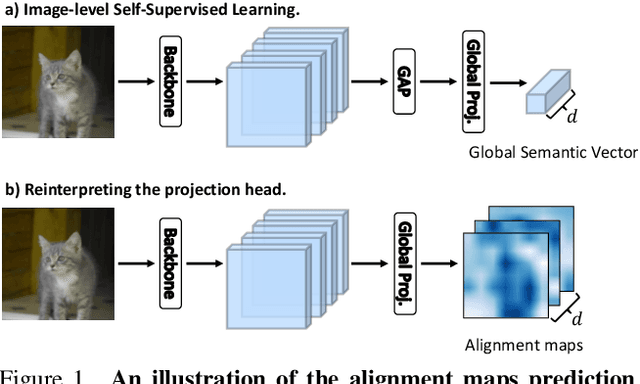
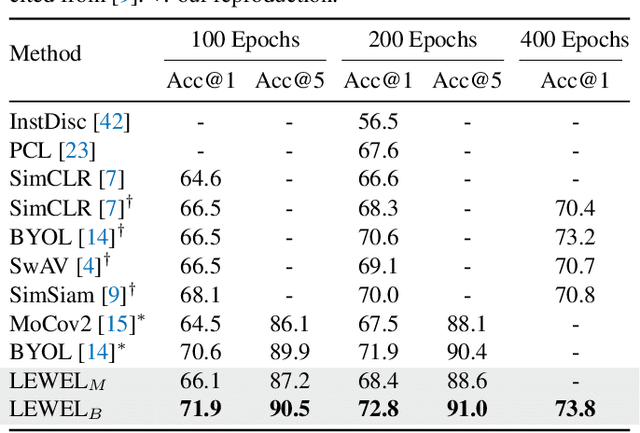
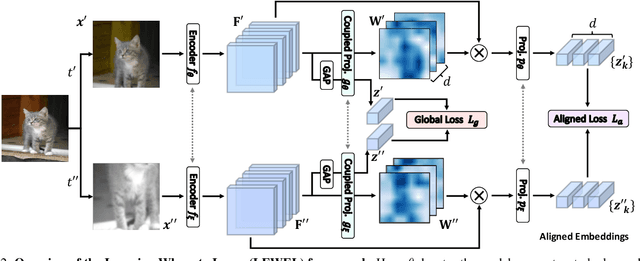
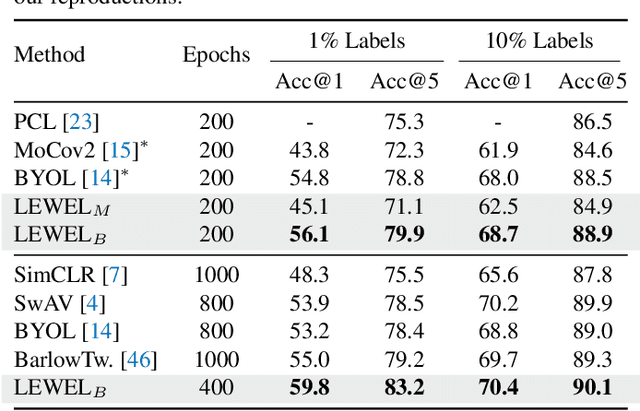
Self-supervised learning (SSL) has made enormous progress and largely narrowed the gap with the supervised ones, where the representation learning is mainly guided by a projection into an embedding space. During the projection, current methods simply adopt uniform aggregation of pixels for embedding; however, this risks involving object-irrelevant nuisances and spatial misalignment for different augmentations. In this paper, we present a new approach, Learning Where to Learn (LEWEL), to adaptively aggregate spatial information of features, so that the projected embeddings could be exactly aligned and thus guide the feature learning better. Concretely, we reinterpret the projection head in SSL as a per-pixel projection and predict a set of spatial alignment maps from the original features by this weight-sharing projection head. A spectrum of aligned embeddings is thus obtained by aggregating the features with spatial weighting according to these alignment maps. As a result of this adaptive alignment, we observe substantial improvements on both image-level prediction and dense prediction at the same time: LEWEL improves MoCov2 by 1.6%/1.3%/0.5%/0.4% points, improves BYOL by 1.3%/1.3%/0.7%/0.6% points, on ImageNet linear/semi-supervised classification, Pascal VOC semantic segmentation, and object detection, respectively.
FairRank: Fairness-aware Single-tower Ranking Framework for News Recommendation
Apr 01, 2022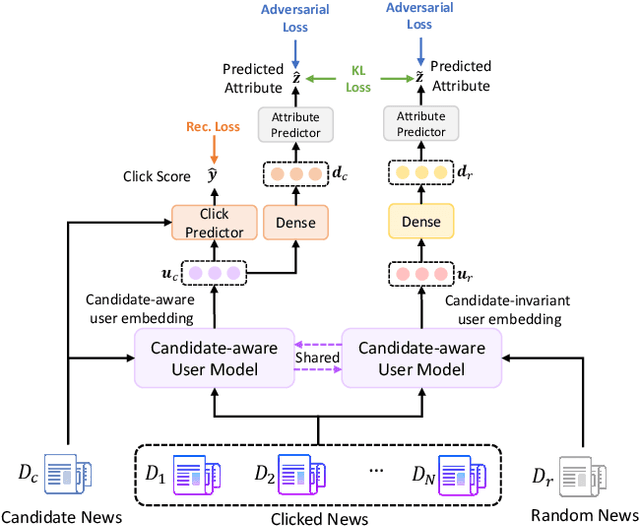

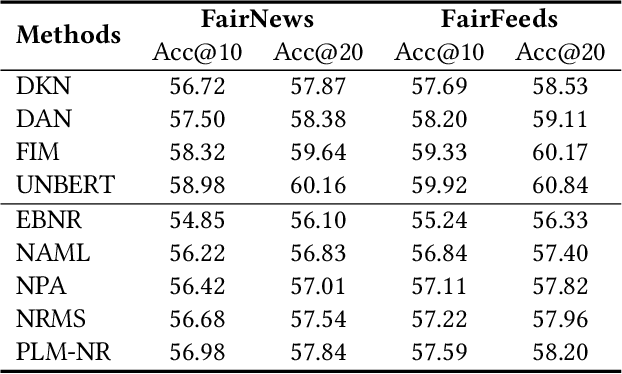

Single-tower models are widely used in the ranking stage of news recommendation to accurately rank candidate news according to their fine-grained relatedness with user interest indicated by user behaviors. However, these models can easily inherit the biases related to users' sensitive attributes (e.g., demographics) encoded in training click data, and may generate recommendation results that are unfair to users with certain attributes. In this paper, we propose FairRank, which is a fairness-aware single-tower ranking framework for news recommendation. Since candidate news selection can be biased, we propose to use a shared candidate-aware user model to match user interest with a real displayed candidate news and a random news, respectively, to learn a candidate-aware user embedding that reflects user interest in candidate news and a candidate-invariant user embedding that indicates intrinsic user interest. We apply adversarial learning to both of them to reduce the biases brought by sensitive user attributes. In addition, we use a KL loss to regularize the attribute labels inferred from the two user embeddings to be similar, which can make the model capture less candidate-aware bias information. Extensive experiments on two datasets show that FairRank can improve the fairness of various single-tower news ranking models with minor performance losses.
S$^2$SQL: Injecting Syntax to Question-Schema Interaction Graph Encoder for Text-to-SQL Parsers
Mar 14, 2022



The task of converting a natural language question into an executable SQL query, known as text-to-SQL, is an important branch of semantic parsing. The state-of-the-art graph-based encoder has been successfully used in this task but does not model the question syntax well. In this paper, we propose S$^2$SQL, injecting Syntax to question-Schema graph encoder for Text-to-SQL parsers, which effectively leverages the syntactic dependency information of questions in text-to-SQL to improve the performance. We also employ the decoupling constraint to induce diverse relational edge embedding, which further improves the network's performance. Experiments on the Spider and robustness setting Spider-Syn demonstrate that the proposed approach outperforms all existing methods when pre-training models are used, resulting in a performance ranks first on the Spider leaderboard.
A Global Modeling Approach for Load Forecasting in Distribution Networks
Apr 01, 2022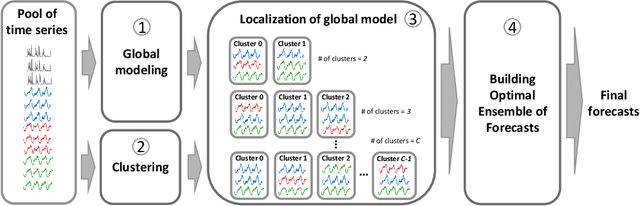
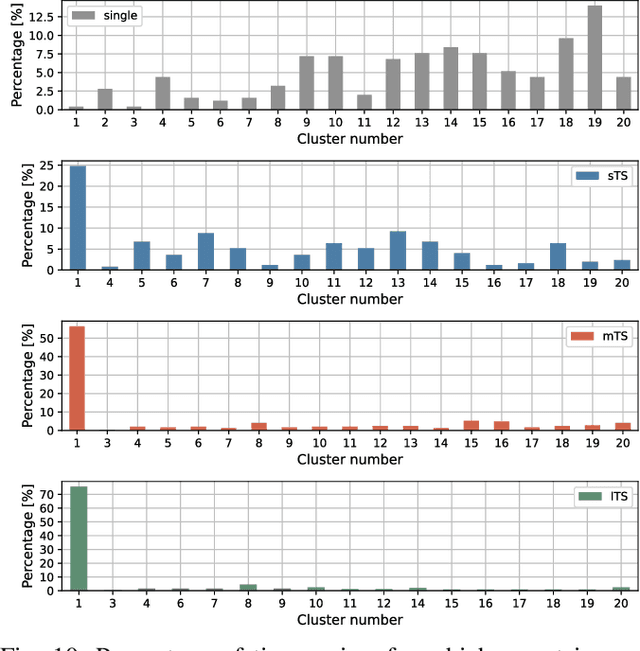
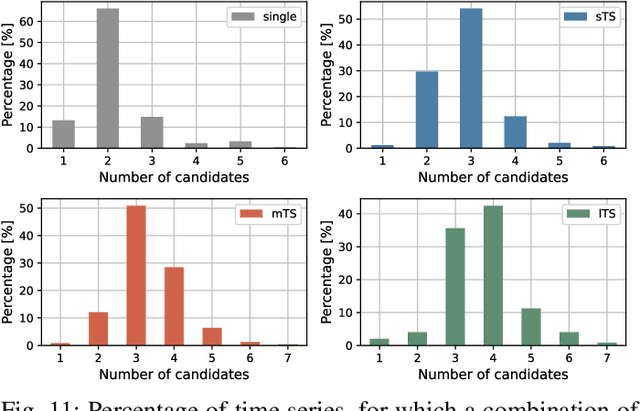
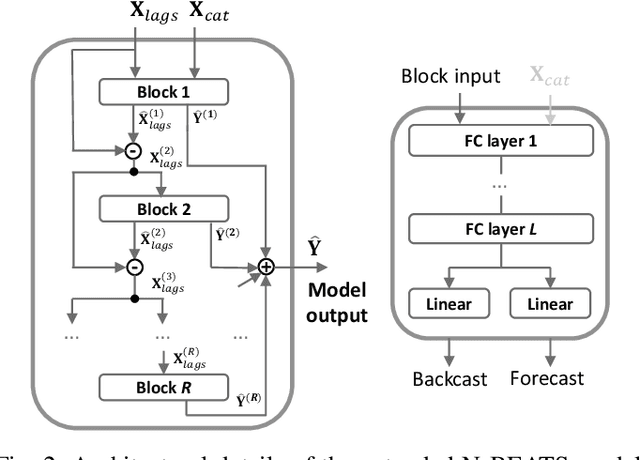
Efficient load forecasting is needed to ensure better observability in the distribution networks, whereas such forecasting is made possible by an increasing number of smart meter installations. Because distribution networks include a large amount of different loads at various aggregation levels, such as individual consumers, transformer stations and feeders loads, it is impractical to develop individual (or so-called local) forecasting models for each load separately. Furthermore, such local models ignore the strong dependencies between different loads that might be present due to their spatial proximity and the characteristics of the distribution network. To address these issues, this paper proposes a global modeling approach based on deep learning for efficient forecasting of a large number of loads in distribution networks. In this way, the computational burden of training a large amount of local forecasting models can be largely reduced, and the cross-series information shared among different loads can be utilized. Additionally, an unsupervised localization mechanism and optimal ensemble construction strategy are also proposed to localize/personalize the forecasting model to different groups of loads and to improve the forecasting accuracy further. Comprehensive experiments are conducted on real-world smart meter data to demonstrate the superiority of the proposed approach compared to competing methods.
A Generative Deep Learning Approach to Stochastic Downscaling of Precipitation Forecasts
Apr 05, 2022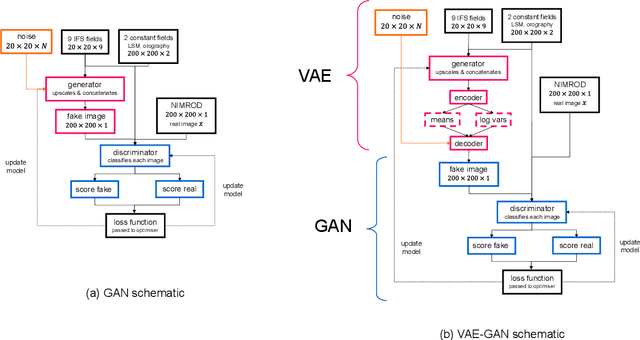
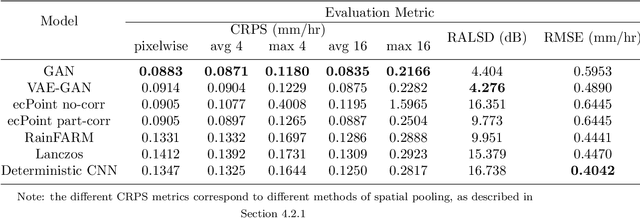
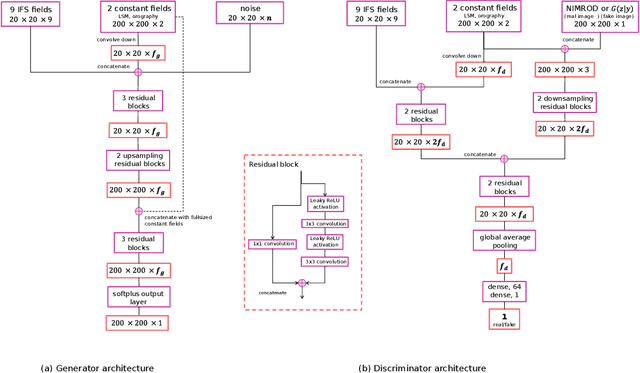
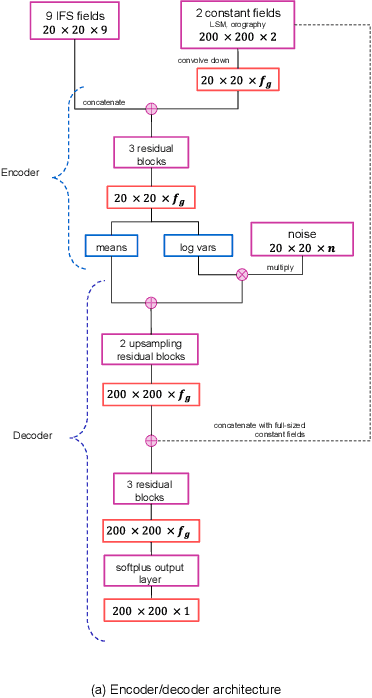
Despite continuous improvements, precipitation forecasts are still not as accurate and reliable as those of other meteorological variables. A major contributing factor to this is that several key processes affecting precipitation distribution and intensity occur below the resolved scale of global weather models. Generative adversarial networks (GANs) have been demonstrated by the computer vision community to be successful at super-resolution problems, i.e., learning to add fine-scale structure to coarse images. Leinonen et al. (2020) previously applied a GAN to produce ensembles of reconstructed high-resolution atmospheric fields, given coarsened input data. In this paper, we demonstrate this approach can be extended to the more challenging problem of increasing the accuracy and resolution of comparatively low-resolution input from a weather forecasting model, using high-resolution radar measurements as a "ground truth". The neural network must learn to add resolution and structure whilst accounting for non-negligible forecast error. We show that GANs and VAE-GANs can match the statistical properties of state-of-the-art pointwise post-processing methods whilst creating high-resolution, spatially coherent precipitation maps. Our model compares favourably to the best existing downscaling methods in both pixel-wise and pooled CRPS scores, power spectrum information and rank histograms (used to assess calibration). We test our models and show that they perform in a range of scenarios, including heavy rainfall.
Weakly-Supervised End-to-End CAD Retrieval to Scan Objects
Mar 24, 2022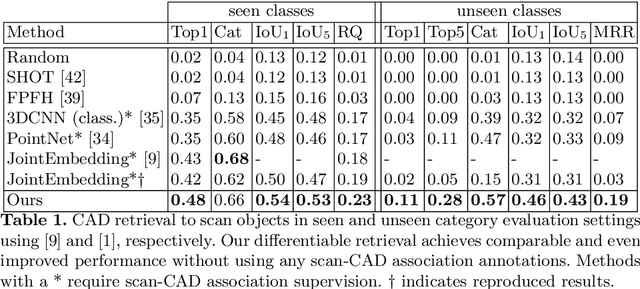
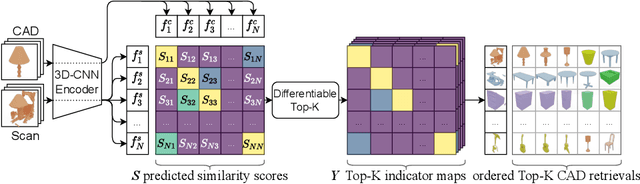
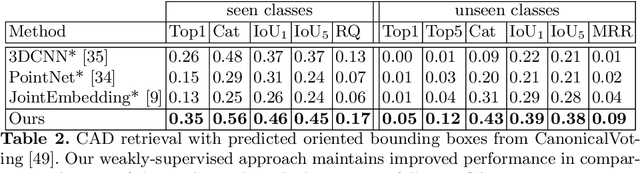
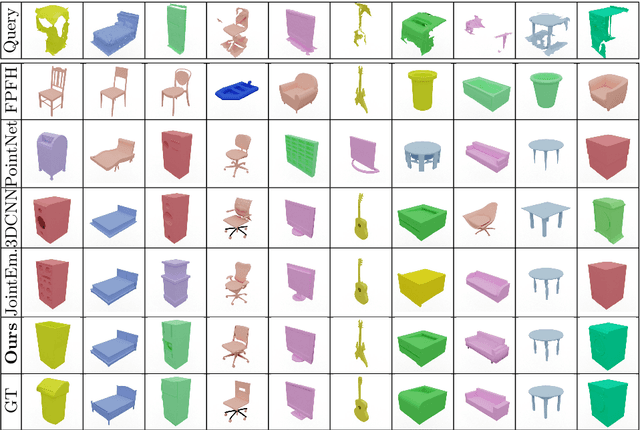
CAD model retrieval to real-world scene observations has shown strong promise as a basis for 3D perception of objects and a clean, lightweight mesh-based scene representation; however, current approaches to retrieve CAD models to a query scan rely on expensive manual annotations of 1:1 associations of CAD-scan objects, which typically contain strong lower-level geometric differences. We thus propose a new weakly-supervised approach to retrieve semantically and structurally similar CAD models to a query 3D scanned scene without requiring any CAD-scan associations, and only object detection information as oriented bounding boxes. Our approach leverages a fully-differentiable top-$k$ retrieval layer, enabling end-to-end training guided by geometric and perceptual similarity of the top retrieved CAD models to the scan queries. We demonstrate that our weakly-supervised approach can outperform fully-supervised retrieval methods on challenging real-world ScanNet scans, and maintain robustness for unseen class categories, achieving significantly improved performance over fully-supervised state of the art in zero-shot CAD retrieval.
The Variational Bandwidth Bottleneck: Stochastic Evaluation on an Information Budget
Apr 24, 2020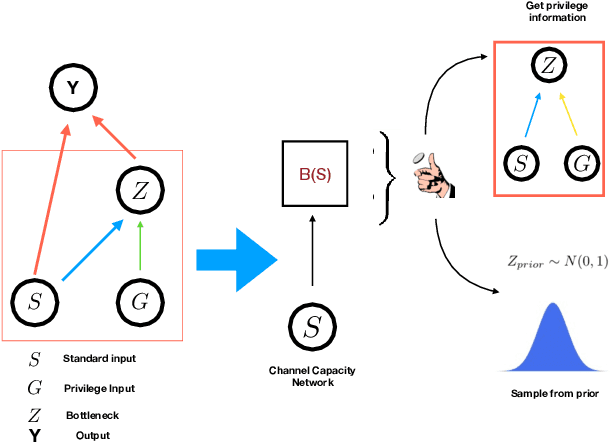

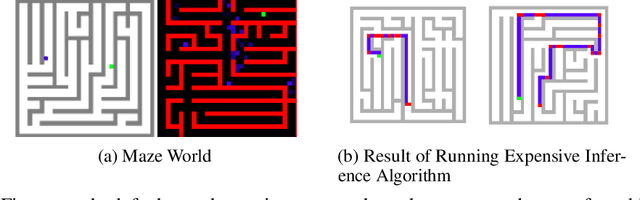
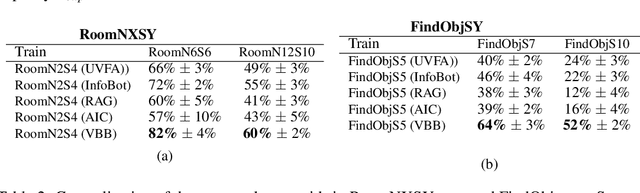
In many applications, it is desirable to extract only the relevant information from complex input data, which involves making a decision about which input features are relevant. The information bottleneck method formalizes this as an information-theoretic optimization problem by maintaining an optimal tradeoff between compression (throwing away irrelevant input information), and predicting the target. In many problem settings, including the reinforcement learning problems we consider in this work, we might prefer to compress only part of the input. This is typically the case when we have a standard conditioning input, such as a state observation, and a "privileged" input, which might correspond to the goal of a task, the output of a costly planning algorithm, or communication with another agent. In such cases, we might prefer to compress the privileged input, either to achieve better generalization (e.g., with respect to goals) or to minimize access to costly information (e.g., in the case of communication). Practical implementations of the information bottleneck based on variational inference require access to the privileged input in order to compute the bottleneck variable, so although they perform compression, this compression operation itself needs unrestricted, lossless access. In this work, we propose the variational bandwidth bottleneck, which decides for each example on the estimated value of the privileged information before seeing it, i.e., only based on the standard input, and then accordingly chooses stochastically, whether to access the privileged input or not. We formulate a tractable approximation to this framework and demonstrate in a series of reinforcement learning experiments that it can improve generalization and reduce access to computationally costly information.