 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An efficient approach for tracking the aerosol-cloud interactions formed by ship emissions using GOES-R satellite imagery and AIS ship tracking information
Aug 12, 2021

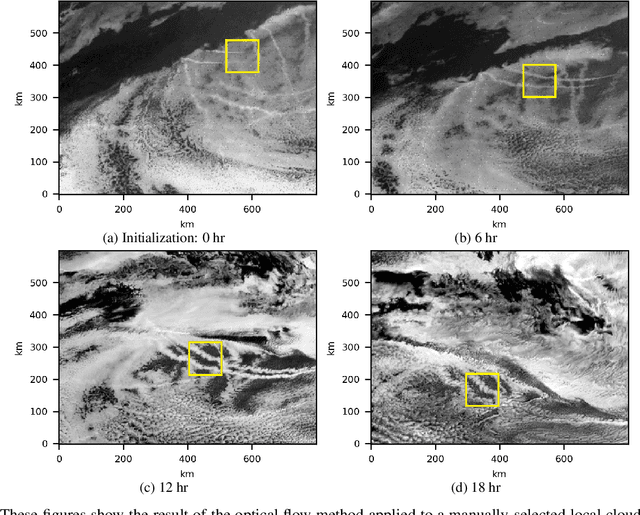

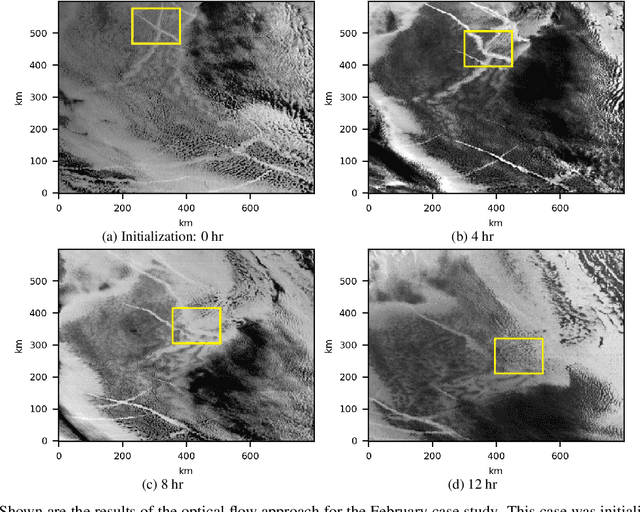
Ship emissions can form linear cloud features, or ship tracks, when atmospheric water vapor condenses on aerosols in the ship exhaust. These features are of interest because they are observable and traceable examples of marine cloud brightening, a mechanism that has been studied as a potential approach for solar climate intervention. Ship tracks can be observed throughout the diurnal cycle via space-borne assets like the Advanced Baseline Imagers on the National Oceanic and Atmospheric Administration Geostationary Operational Environmental Satellites, the GOES-R series. Due to complex atmospheric dynamics, it can be difficult to track these aerosol perturbations over space and time to precisely characterize how long a single emission source can significantly contribute to indirect radiative forcing. We combine GOES-17 satellite imagery with ship location information to demonstrate two feasible methods of tracing the trajectories of ship-emitted aerosols after they begin mixing with low boundary layer clouds in three test cases. The first method uses the parcel trajectory model HYSPLIT, which was driven by well-studied physical processes but often could not follow the ship track beyond 8 hours. The second method uses the image processing technique, optical flow, which could follow the track throughout its lifetime, but requires high contrast features for best performance. These approaches show that ship tracks persist as visible, linear features beyond 9 hr and sometimes longer than 24 hr. This research sets the stage for a more thorough exploration of the atmospheric conditions and exhaust compositions that produce ship tracks and factors that determine track persistence.
Dealing with collinearity in large-scale linear system identification using Bayesian regularization
Mar 25, 2022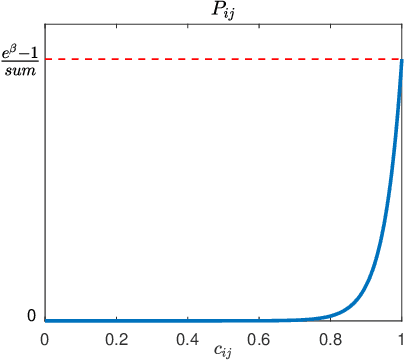
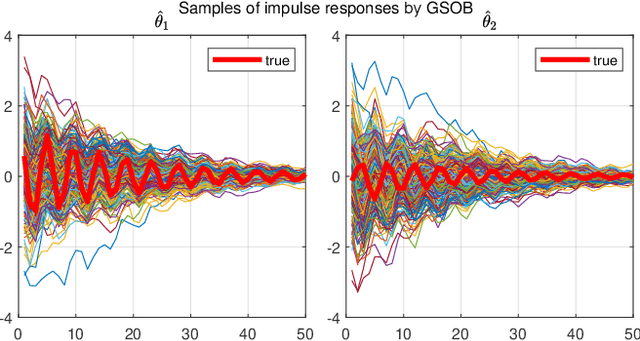
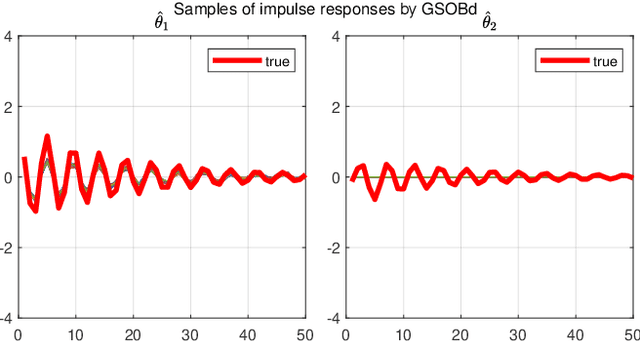
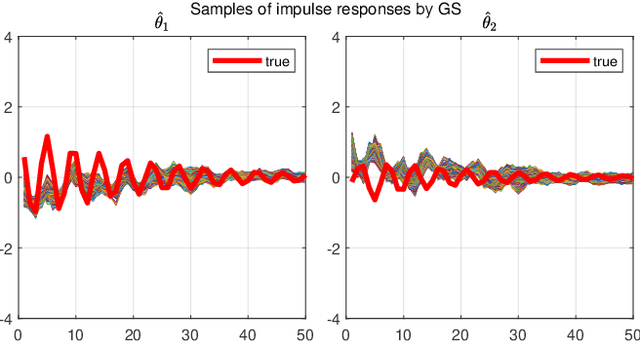
We consider the identification of large-scale linear and stable dynamic systems whose outputs may be the result of many correlated inputs. Hence, severe ill-conditioning may affect the estimation problem. This is a scenario often arising when modeling complex physical systems given by the interconnection of many sub-units where feedback and algebraic loops can be encountered. We develop a strategy based on Bayesian regularization where any impulse response is modeled as the realization of a zero-mean Gaussian process. The stable spline covariance is used to include information on smooth exponential decay of the impulse responses. We then design a new Markov chain Monte Carlo scheme that deals with collinearity and is able to efficiently reconstruct the posterior of the impulse responses. It is based on a variation of Gibbs sampling which updates possibly overlapping blocks of the parameter space on the basis of the level of collinearity affecting the different inputs. Numerical experiments are included to test the goodness of the approach where hundreds of impulse responses form the system and inputs correlation may be very high.
Learning Robust Representation through Graph Adversarial Contrastive Learning
Jan 31, 2022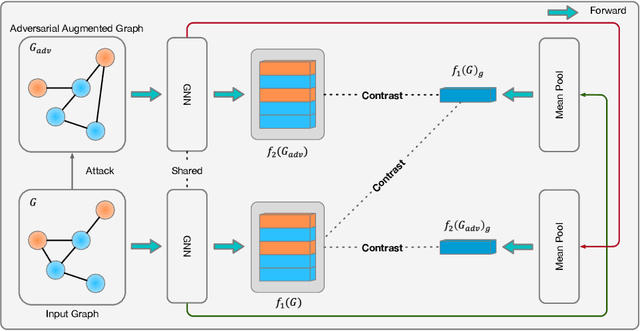
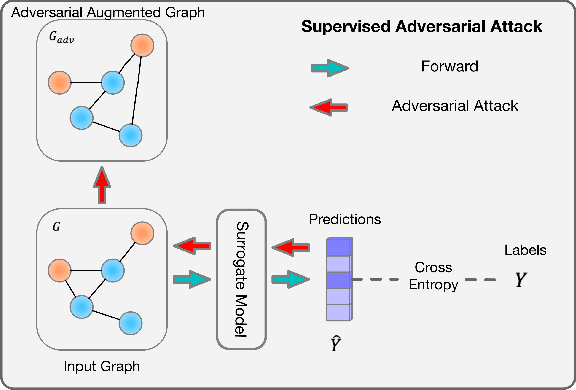
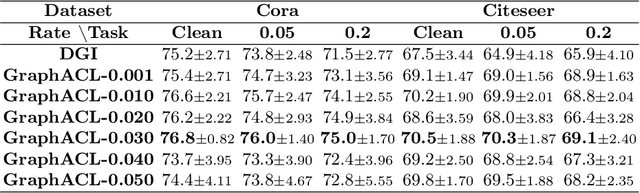
Existing studies show that node representations generated by graph neural networks (GNNs) are vulnerable to adversarial attacks, such as unnoticeable perturbations of adjacent matrix and node features. Thus, it is requisite to learn robust representations in graph neural networks. To improve the robustness of graph representation learning, we propose a novel Graph Adversarial Contrastive Learning framework (GraphACL) by introducing adversarial augmentations into graph self-supervised learning. In this framework, we maximize the mutual information between local and global representations of a perturbed graph and its adversarial augmentations, where the adversarial graphs can be generated in either supervised or unsupervised approaches. Based on the Information Bottleneck Principle, we theoretically prove that our method could obtain a much tighter bound, thus improving the robustness of graph representation learning. Empirically, we evaluate several methods on a range of node classification benchmarks and the results demonstrate GraphACL could achieve comparable accuracy over previous supervised methods.
Audio-Visual Fusion Layers for Event Type Aware Video Recognition
Feb 12, 2022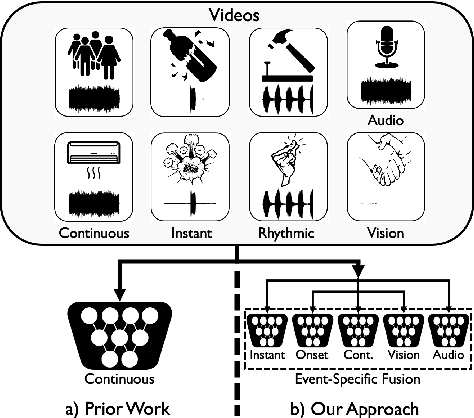
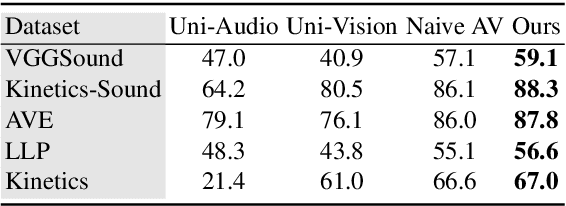
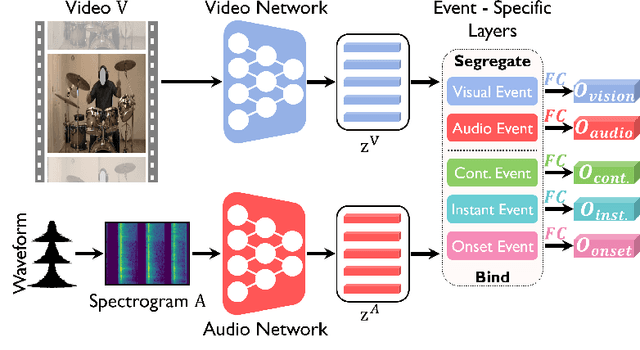
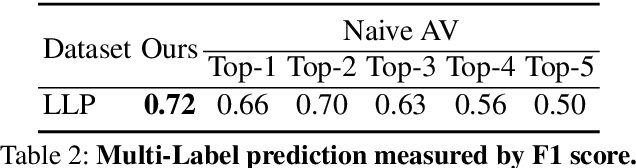
Human brain is continuously inundated with the multisensory information and their complex interactions coming from the outside world at any given moment. Such information is automatically analyzed by binding or segregating in our brain. While this task might seem effortless for human brains, it is extremely challenging to build a machine that can perform similar tasks since complex interactions cannot be dealt with single type of integration but requires more sophisticated approaches. In this paper, we propose a new model to address the multisensory integration problem with individual event-specific layers in a multi-task learning scheme. Unlike previous works where single type of fusion is used, we design event-specific layers to deal with different audio-visual relationship tasks, enabling different ways of audio-visual formation. Experimental results show that our event-specific layers can discover unique properties of the audio-visual relationships in the videos. Moreover, although our network is formulated with single labels, it can output additional true multi-labels to represent the given videos. We demonstrate that our proposed framework also exposes the modality bias of the video data category-wise and dataset-wise manner in popular benchmark datasets.
AdaTest:Reinforcement Learning and Adaptive Sampling for On-chip Hardware Trojan Detection
Apr 12, 2022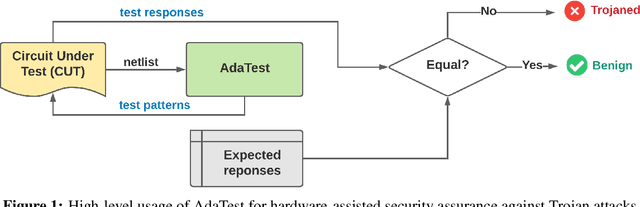
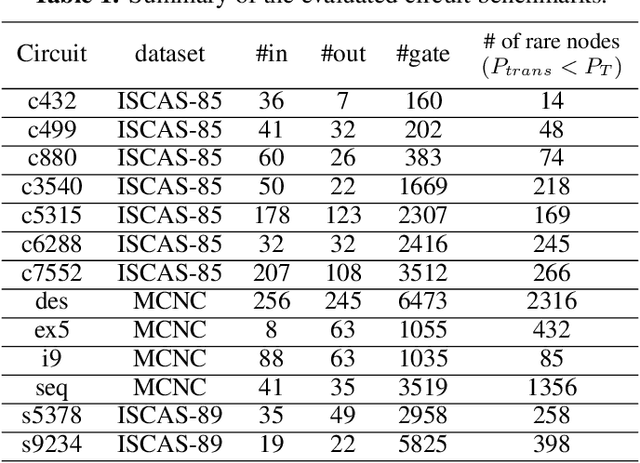
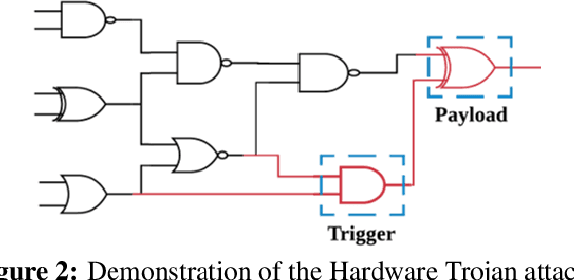
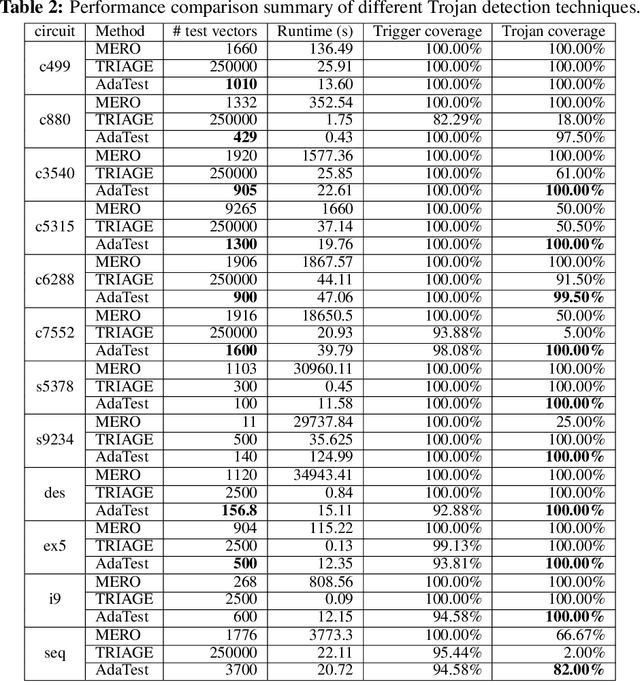
This paper proposes AdaTest, a novel adaptive test pattern generation framework for efficient and reliable Hardware Trojan (HT) detection. HT is a backdoor attack that tampers with the design of victim integrated circuits (ICs). AdaTest improves the existing HT detection techniques in terms of scalability and accuracy of detecting smaller Trojans in the presence of noise and variations. To achieve high trigger coverage, AdaTest leverages Reinforcement Learning (RL) to produce a diverse set of test inputs. Particularly, we progressively generate test vectors with high reward values in an iterative manner. In each iteration, the test set is evaluated and adaptively expanded as needed. Furthermore, AdaTest integrates adaptive sampling to prioritize test samples that provide more information for HT detection, thus reducing the number of samples while improving the sample quality for faster exploration. We develop AdaTest with a Software/Hardware co-design principle and provide an optimized on-chip architecture solution. AdaTest's architecture minimizes the hardware overhead in two ways:(i) Deploying circuit emulation on programmable hardware to accelerate reward evaluation of the test input; (ii) Pipelining each computation stage in AdaTest by automatically constructing auxiliary circuit for test input generation, reward evaluation, and adaptive sampling. We evaluate AdaTest's performance on various HT benchmarks and compare it with two prior works that use logic testing for HT detection. Experimental results show that AdaTest engenders up to two orders of test generation speedup and two orders of test set size reduction compared to the prior works while achieving the same level or higher Trojan detection rate.
DISCO: Comprehensive and Explainable Disinformation Detection
Mar 09, 2022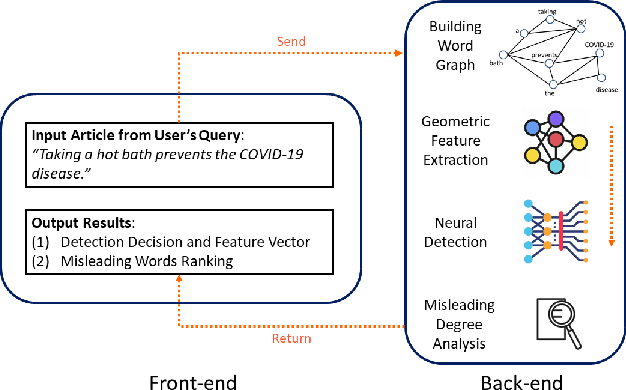

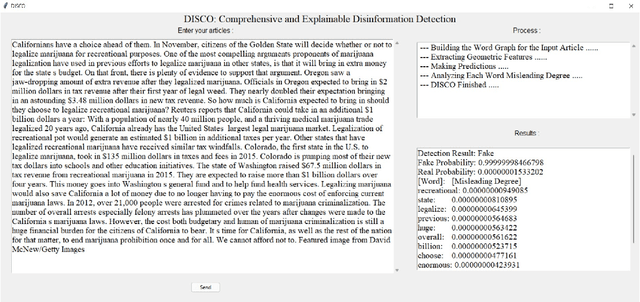
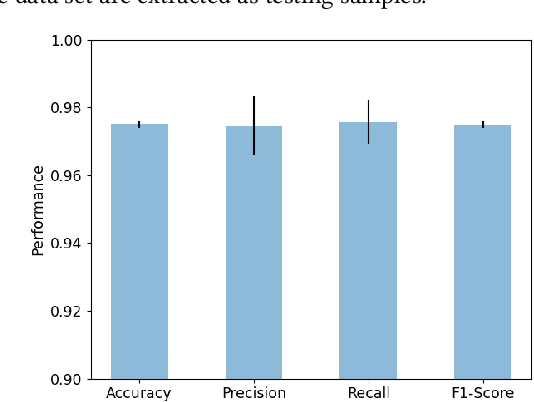
Disinformation refers to false information deliberately spread to influence the general public, and the negative impact of disinformation on society can be observed for numerous issues, such as political agendas and manipulating financial markets. In this paper, we identify prevalent challenges and advances related to automated disinformation detection from multiple aspects, and propose a comprehensive and explainable disinformation detection framework called DISCO. It leverages the heterogeneity of disinformation and addresses the prediction opaqueness. Then we provide a demonstration of DISCO on a real-world fake news detection task with satisfactory detection accuracy and explanation. The demo video and source code of DISCO is now publicly available. We expect that our demo could pave the way for addressing the limitations of identification, comprehension, and explainability as a whole.
Temporal Point Cloud Completion with Pose Disturbance
Feb 07, 2022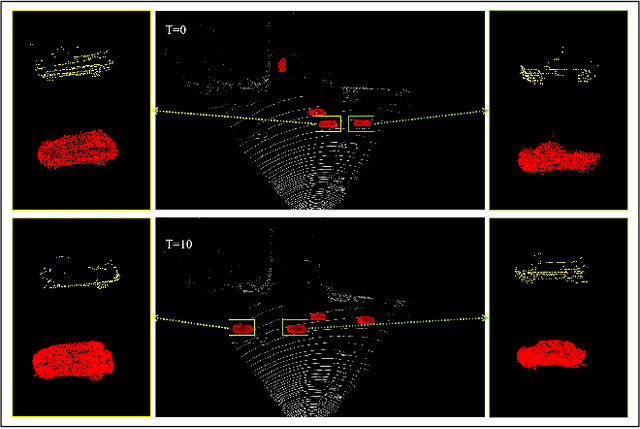
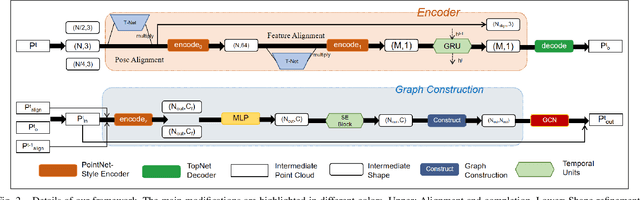
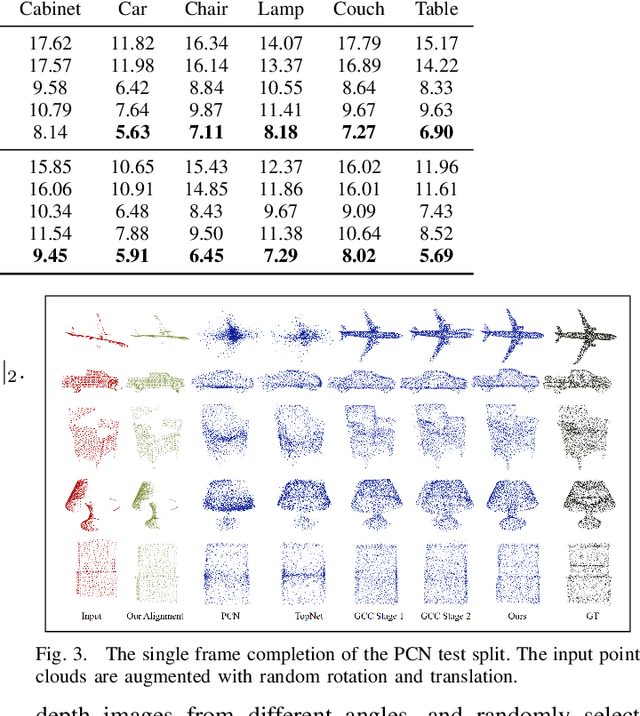
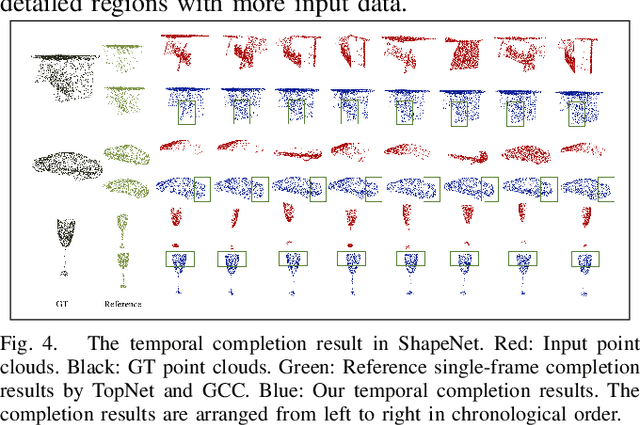
Point clouds collected by real-world sensors are always unaligned and sparse, which makes it hard to reconstruct the complete shape of object from a single frame of data. In this work, we manage to provide complete point clouds from sparse input with pose disturbance by limited translation and rotation. We also use temporal information to enhance the completion model, refining the output with a sequence of inputs. With the help of gated recovery units(GRU) and attention mechanisms as temporal units, we propose a point cloud completion framework that accepts a sequence of unaligned and sparse inputs, and outputs consistent and aligned point clouds. Our network performs in an online manner and presents a refined point cloud for each frame, which enables it to be integrated into any SLAM or reconstruction pipeline. As far as we know, our framework is the first to utilize temporal information and ensure temporal consistency with limited transformation. Through experiments in ShapeNet and KITTI, we prove that our framework is effective in both synthetic and real-world datasets.
Label uncertainty-guided multi-stream model for disease screening
Jan 28, 2022
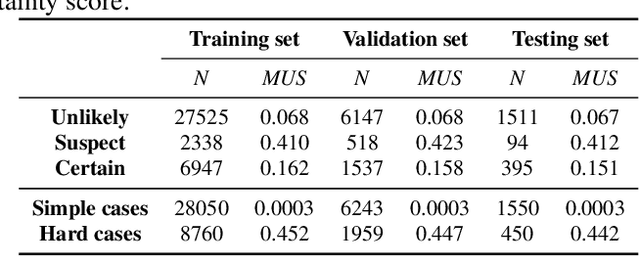
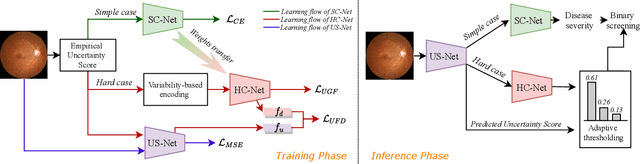
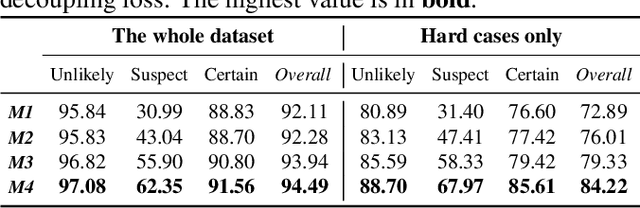
The annotation of disease severity for medical image datasets often relies on collaborative decisions from multiple human graders. The intra-observer variability derived from individual differences always persists in this process, yet the influence is often underestimated. In this paper, we cast the intra-observer variability as an uncertainty problem and incorporate the label uncertainty information as guidance into the disease screening model to improve the final decision. The main idea is dividing the images into simple and hard cases by uncertainty information, and then developing a multi-stream network to deal with different cases separately. Particularly, for hard cases, we strengthen the network's capacity in capturing the correct disease features and resisting the interference of uncertainty. Experiments on a fundus image-based glaucoma screening case study show that the proposed model outperforms several baselines, especially in screening hard cases.
Spectral and Energy Efficiency of DCO-OFDM in Visible Light Communication Systems with Finite-Alphabet Inputs
Feb 02, 2022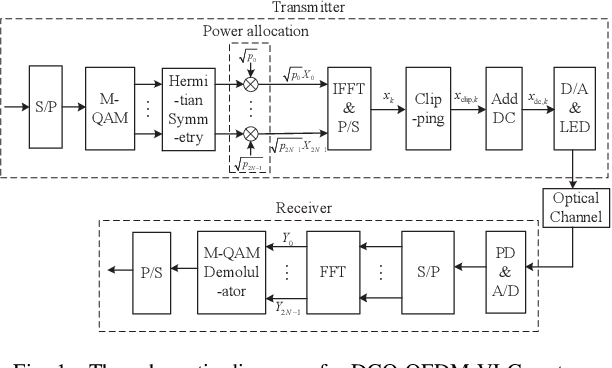
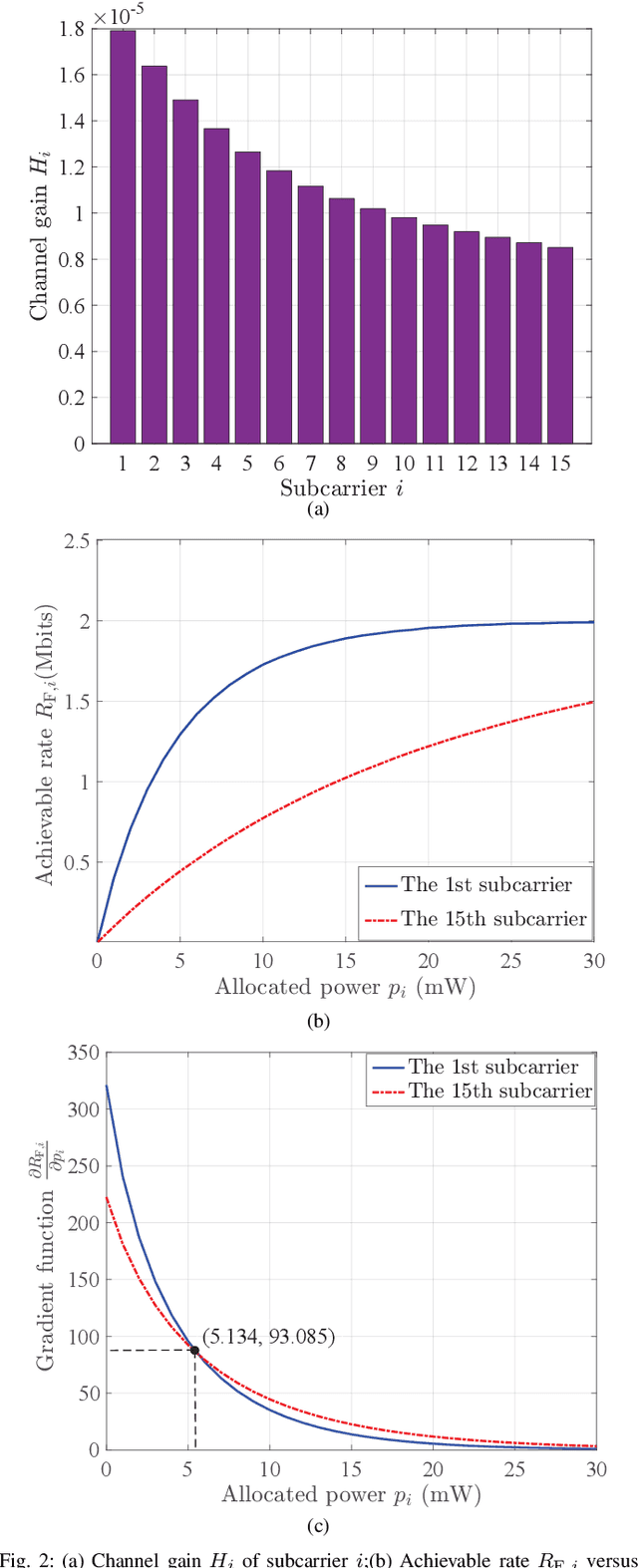
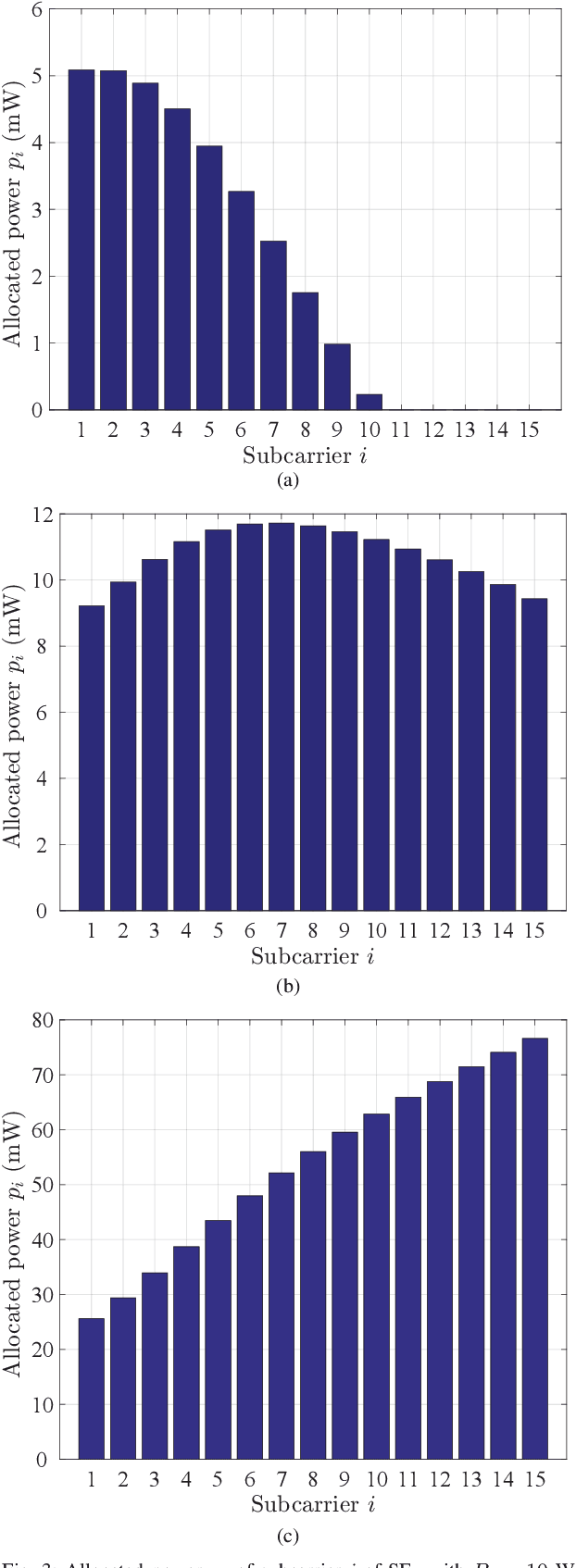
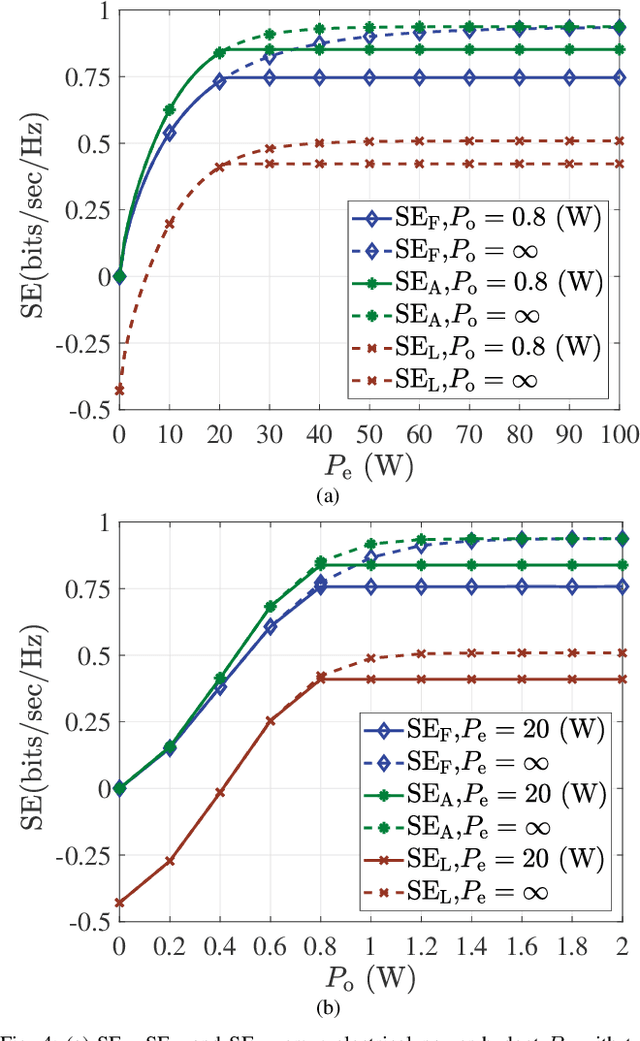
The bound of the information transmission rate of direct current biased optical orthogonal frequency division multiplexing (DCO-OFDM) for visible light communication (VLC) with finite-alphabet inputs is yet unknown, where the corresponding spectral efficiency (SE) and energy efficiency (EE) stems out as the open research problems. In this paper, we derive the exact achievable rate of {the} DCO-OFDM system with finite-alphabet inputs for the first time. Furthermore, we investigate SE maximization problems of {the} DCO-OFDM system subject to both electrical and optical power constraints. By exploiting the relationship between the mutual information and the minimum mean-squared error, we propose a multi-level mercury-water-filling power allocation scheme to achieve the maximum SE. Moreover, the EE maximization problems of {the} DCO-OFDM system are studied, and the Dinkelbach-type power allocation scheme is developed for the maximum EE. Numerical results verify the effectiveness of the proposed theories and power allocation schemes.
* 14 pages, 14 figures, accepted by IEEE Transactions on Wireless Communications
Towards Robust Adaptive Object Detection under Noisy Annotations
Apr 06, 2022
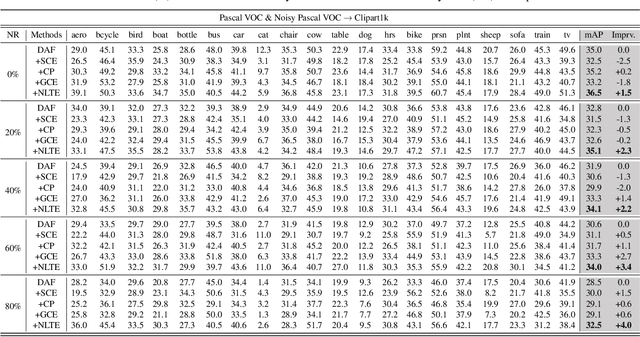
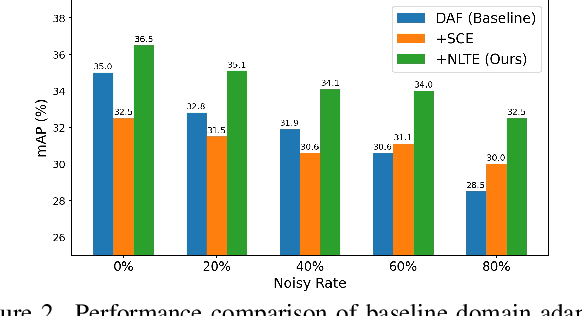
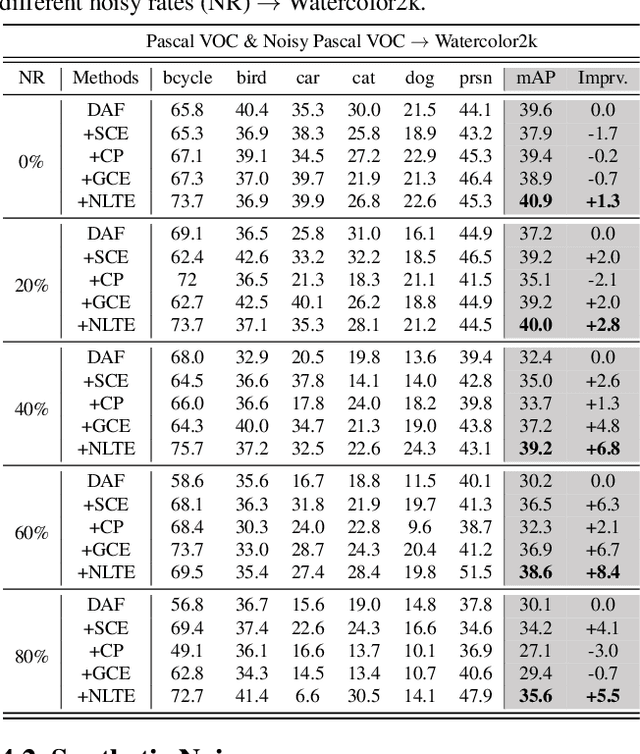
Domain Adaptive Object Detection (DAOD) models a joint distribution of images and labels from an annotated source domain and learns a domain-invariant transformation to estimate the target labels with the given target domain images. Existing methods assume that the source domain labels are completely clean, yet large-scale datasets often contain error-prone annotations due to instance ambiguity, which may lead to a biased source distribution and severely degrade the performance of the domain adaptive detector de facto. In this paper, we represent the first effort to formulate noisy DAOD and propose a Noise Latent Transferability Exploration (NLTE) framework to address this issue. It is featured with 1) Potential Instance Mining (PIM), which leverages eligible proposals to recapture the miss-annotated instances from the background; 2) Morphable Graph Relation Module (MGRM), which models the adaptation feasibility and transition probability of noisy samples with relation matrices; 3) Entropy-Aware Gradient Reconcilement (EAGR), which incorporates the semantic information into the discrimination process and enforces the gradients provided by noisy and clean samples to be consistent towards learning domain-invariant representations. A thorough evaluation on benchmark DAOD datasets with noisy source annotations validates the effectiveness of NLTE. In particular, NLTE improves the mAP by 8.4\% under 60\% corrupted annotations and even approaches the ideal upper bound of training on a clean source dataset.