 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
3D Perception based Imitation Learning under Limited Demonstration for Laparoscope Control in Robotic Surgery
Apr 07, 2022

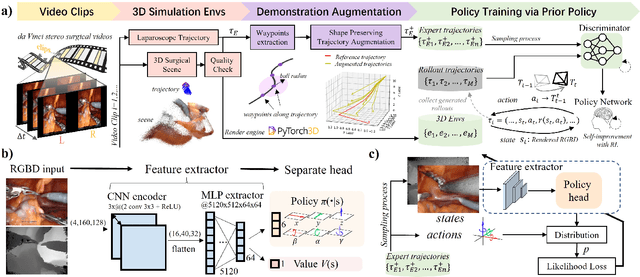
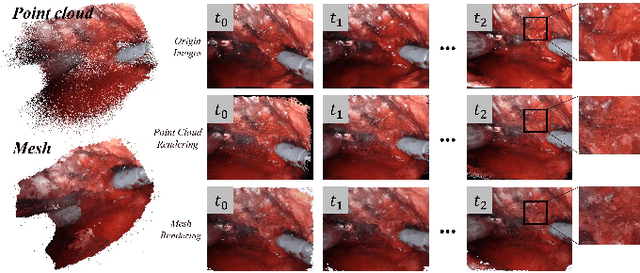
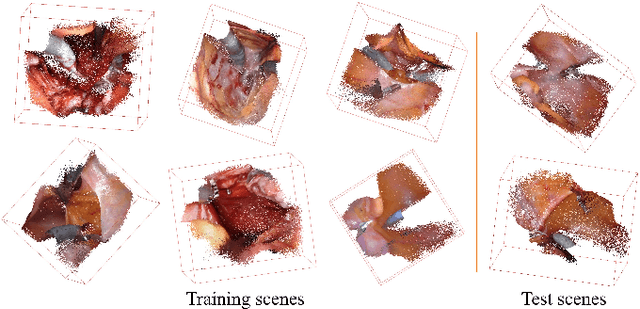
Automatic laparoscope motion control is fundamentally important for surgeons to efficiently perform operations. However, its traditional control methods based on tool tracking without considering information hidden in surgical scenes are not intelligent enough, while the latest supervised imitation learning (IL)-based methods require expensive sensor data and suffer from distribution mismatch issues caused by limited demonstrations. In this paper, we propose a novel Imitation Learning framework for Laparoscope Control (ILLC) with reinforcement learning (RL), which can efficiently learn the control policy from limited surgical video clips. Specially, we first extract surgical laparoscope trajectories from unlabeled videos as the demonstrations and reconstruct the corresponding surgical scenes. To fully learn from limited motion trajectory demonstrations, we propose Shape Preserving Trajectory Augmentation (SPTA) to augment these data, and build a simulation environment that supports parallel RGB-D rendering to reinforce the RL policy for interacting with the environment efficiently. With adversarial training for IL, we obtain the laparoscope control policy based on the generated rollouts and surgical demonstrations. Extensive experiments are conducted in unseen reconstructed surgical scenes, and our method outperforms the previous IL methods, which proves the feasibility of our unified learning-based framework for laparoscope control.
Transferred Q-learning
Feb 09, 2022We consider $Q$-learning with knowledge transfer, using samples from a target reinforcement learning (RL) task as well as source samples from different but related RL tasks. We propose transfer learning algorithms for both batch and online $Q$-learning with offline source studies. The proposed transferred $Q$-learning algorithm contains a novel re-targeting step that enables vertical information-cascading along multiple steps in an RL task, besides the usual horizontal information-gathering as transfer learning (TL) for supervised learning. We establish the first theoretical justifications of TL in RL tasks by showing a faster rate of convergence of the $Q$ function estimation in the offline RL transfer, and a lower regret bound in the offline-to-online RL transfer under certain similarity assumptions. Empirical evidences from both synthetic and real datasets are presented to back up the proposed algorithm and our theoretical results.
Exploring the Impact of Negative Samples of Contrastive Learning: A Case Study of Sentence Embedding
Mar 01, 2022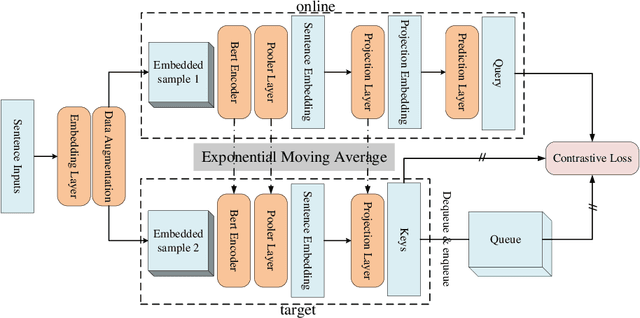
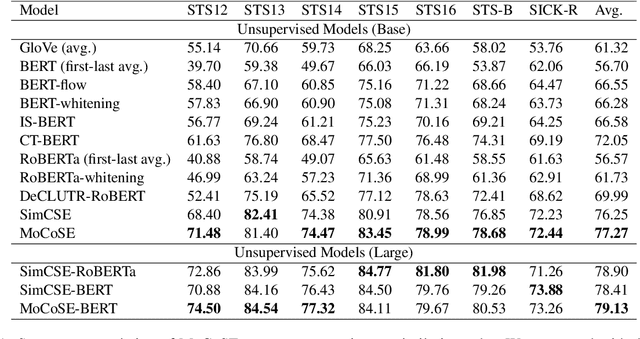
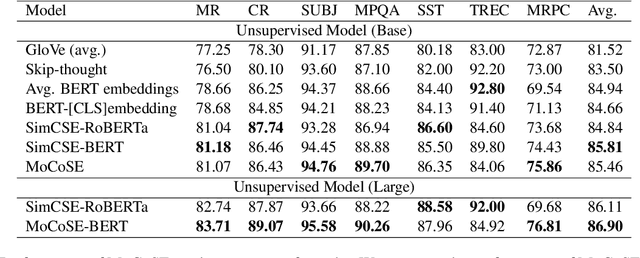
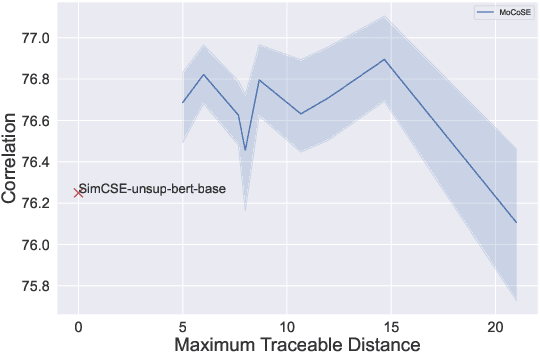
Contrastive learning is emerging as a powerful technique for extracting knowledge from unlabeled data. This technique requires a balanced mixture of two ingredients: positive (similar) and negative (dissimilar) samples. This is typically achieved by maintaining a queue of negative samples during training. Prior works in the area typically uses a fixed-length negative sample queue, but how the negative sample size affects the model performance remains unclear. The opaque impact of the number of negative samples on performance when employing contrastive learning aroused our in-depth exploration. This paper presents a momentum contrastive learning model with negative sample queue for sentence embedding, namely MoCoSE. We add the prediction layer to the online branch to make the model asymmetric and together with EMA update mechanism of the target branch to prevent model from collapsing. We define a maximum traceable distance metric, through which we learn to what extent the text contrastive learning benefits from the historical information of negative samples. Our experiments find that the best results are obtained when the maximum traceable distance is at a certain range, demonstrating that there is an optimal range of historical information for a negative sample queue. We evaluate the proposed unsupervised MoCoSE on the semantic text similarity (STS) task and obtain an average Spearman's correlation of $77.27\%$. Source code is available at https://github.com/xbdxwyh/mocose
Hierarchical Sketch Induction for Paraphrase Generation
Mar 21, 2022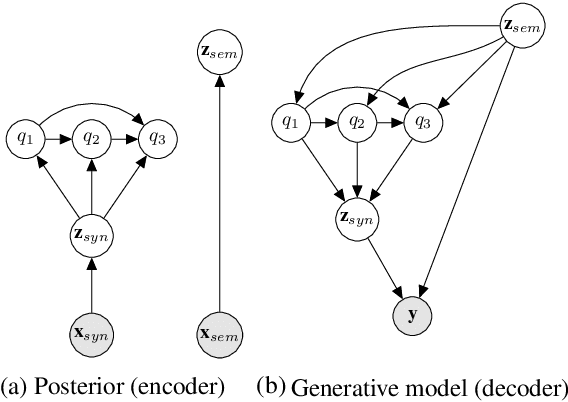
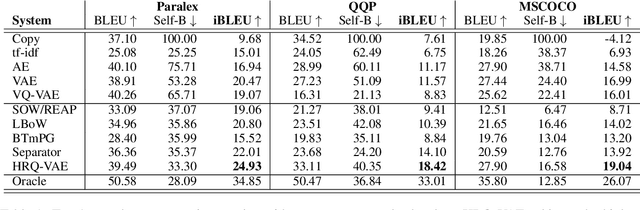

We propose a generative model of paraphrase generation, that encourages syntactic diversity by conditioning on an explicit syntactic sketch. We introduce Hierarchical Refinement Quantized Variational Autoencoders (HRQ-VAE), a method for learning decompositions of dense encodings as a sequence of discrete latent variables that make iterative refinements of increasing granularity. This hierarchy of codes is learned through end-to-end training, and represents fine-to-coarse grained information about the input. We use HRQ-VAE to encode the syntactic form of an input sentence as a path through the hierarchy, allowing us to more easily predict syntactic sketches at test time. Extensive experiments, including a human evaluation, confirm that HRQ-VAE learns a hierarchical representation of the input space, and generates paraphrases of higher quality than previous systems.
SOS! Self-supervised Learning Over Sets Of Handled Objects In Egocentric Action Recognition
Apr 10, 2022
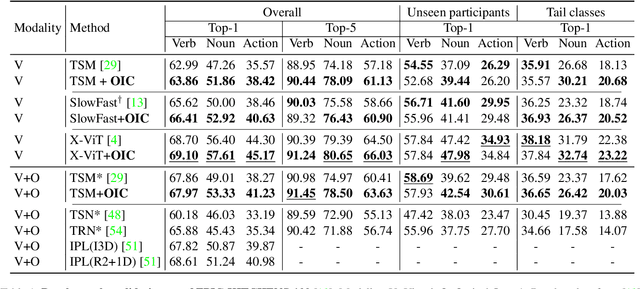

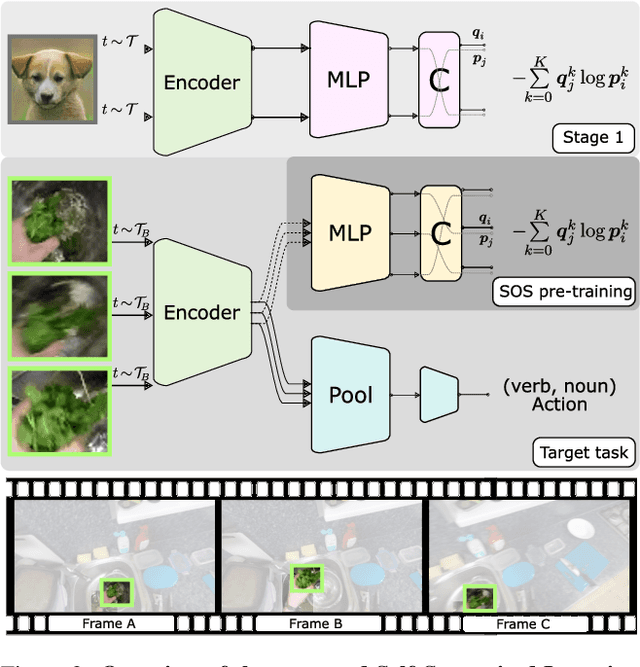
Learning an egocentric action recognition model from video data is challenging due to distractors (e.g., irrelevant objects) in the background. Further integrating object information into an action model is hence beneficial. Existing methods often leverage a generic object detector to identify and represent the objects in the scene. However, several important issues remain. Object class annotations of good quality for the target domain (dataset) are still required for learning good object representation. Besides, previous methods deeply couple the existing action models and need to retrain them jointly with object representation, leading to costly and inflexible integration. To overcome both limitations, we introduce Self-Supervised Learning Over Sets (SOS), an approach to pre-train a generic Objects In Contact (OIC) representation model from video object regions detected by an off-the-shelf hand-object contact detector. Instead of augmenting object regions individually as in conventional self-supervised learning, we view the action process as a means of natural data transformations with unique spatio-temporal continuity and exploit the inherent relationships among per-video object sets. Extensive experiments on two datasets, EPIC-KITCHENS-100 and EGTEA, show that our OIC significantly boosts the performance of multiple state-of-the-art video classification models.
The multi-modal universe of fast-fashion: the Visuelle 2.0 benchmark
Apr 14, 2022

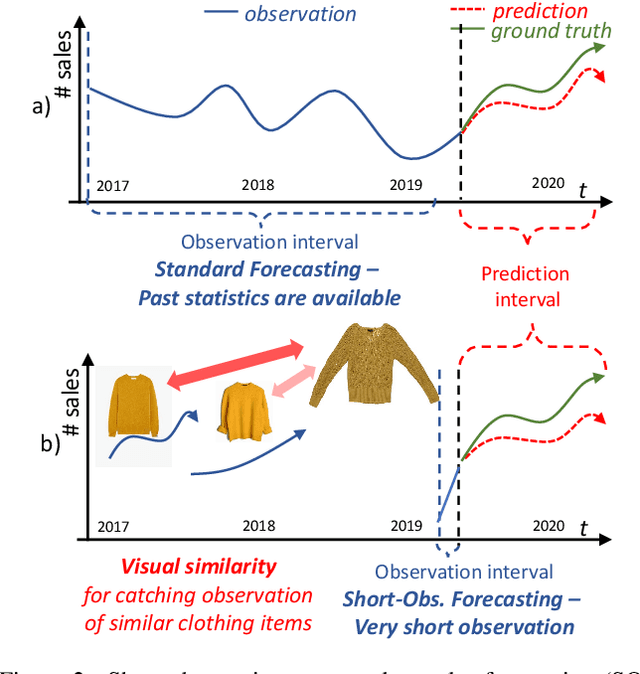
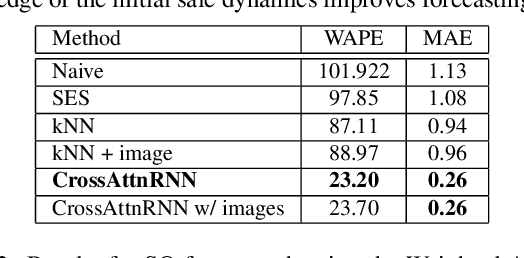
We present Visuelle 2.0, the first dataset useful for facing diverse prediction problems that a fast-fashion company has to manage routinely. Furthermore, we demonstrate how the use of computer vision is substantial in this scenario. Visuelle 2.0 contains data for 6 seasons / 5355 clothing products of Nuna Lie, a famous Italian company with hundreds of shops located in different areas within the country. In particular, we focus on a specific prediction problem, namely short-observation new product sale forecasting (SO-fore). SO-fore assumes that the season has started and a set of new products is on the shelves of the different stores. The goal is to forecast the sales for a particular horizon, given a short, available past (few weeks), since no earlier statistics are available. To be successful, SO-fore approaches should capture this short past and exploit other modalities or exogenous data. To these aims, Visuelle 2.0 is equipped with disaggregated data at the item-shop level and multi-modal information for each clothing item, allowing computer vision approaches to come into play. The main message that we deliver is that the use of image data with deep networks boosts performances obtained when using the time series in long-term forecasting scenarios, ameliorating the WAPE by 8.2% and the MAE by 7.7%. The dataset is available at: https://humaticslab.github.io/forecasting/visuelle.
Analyzing the Dependency of ConvNets on Spatial Information
Feb 05, 2020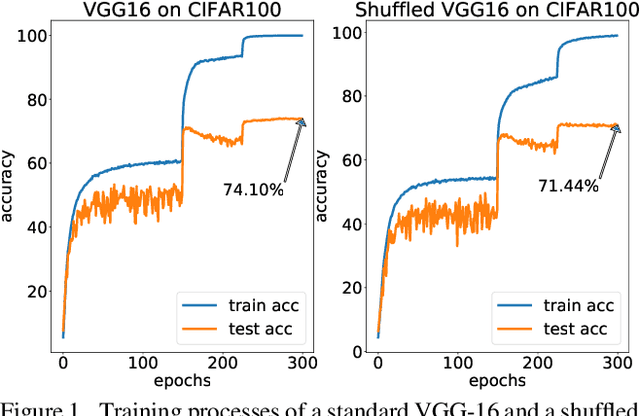
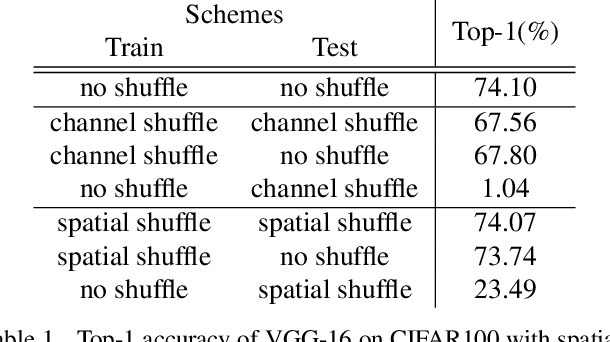
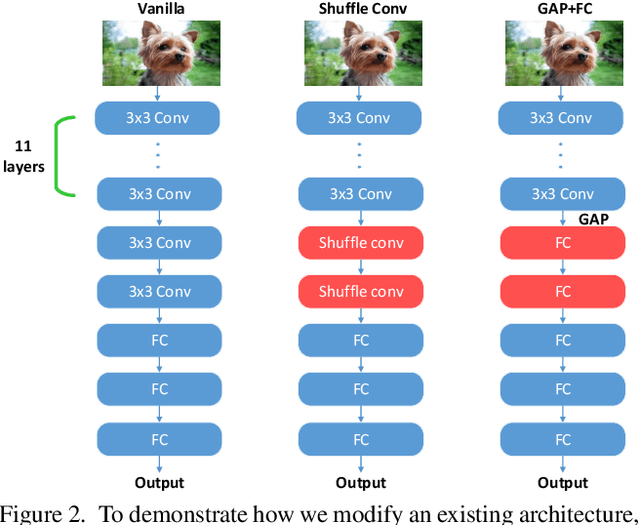
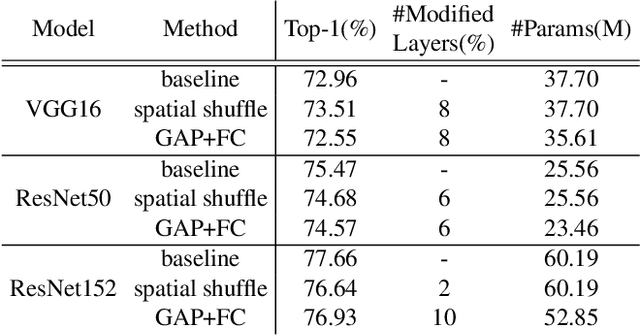
Intuitively, image classification should profit from using spatial information. Recent work, however, suggests that this might be overrated in standard CNNs. In this paper, we are pushing the envelope and aim to further investigate the reliance on spatial information. We propose spatial shuffling and GAP+FC to destroy spatial information during both training and testing phases. Interestingly, we observe that spatial information can be deleted from later layers with small performance drops, which indicates spatial information at later layers is not necessary for good performance. For example, test accuracy of VGG-16 only drops by 0.03% and 2.66% with spatial information completely removed from the last 30% and 53% layers on CIFAR100, respectively. Evaluation on several object recognition datasets (CIFAR100, Small-ImageNet, ImageNet) with a wide range of CNN architectures (VGG16, ResNet50, ResNet152) shows an overall consistent pattern.
Feasibility Study of Multi-Site Split Learning for Privacy-Preserving Medical Systems under Data Imbalance Constraints in COVID-19, X-Ray, and Cholesterol Dataset
Feb 21, 2022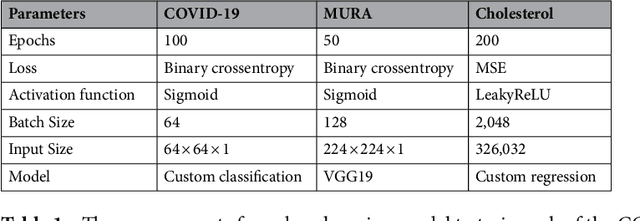

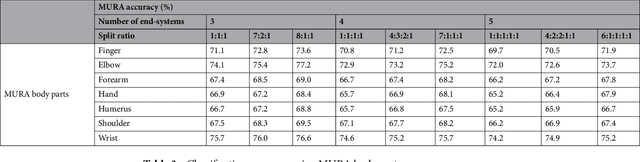

It seems as though progressively more people are in the race to upload content, data, and information online; and hospitals haven't neglected this trend either. Hospitals are now at the forefront for multi-site medical data sharing to provide groundbreaking advancements in the way health records are shared and patients are diagnosed. Sharing of medical data is essential in modern medical research. Yet, as with all data sharing technology, the challenge is to balance improved treatment with protecting patient's personal information. This paper provides a novel split learning algorithm coined the term, "multi-site split learning", which enables a secure transfer of medical data between multiple hospitals without fear of exposing personal data contained in patient records. It also explores the effects of varying the number of end-systems and the ratio of data-imbalance on the deep learning performance. A guideline for the most optimal configuration of split learning that ensures privacy of patient data whilst achieving performance is empirically given. We argue the benefits of our multi-site split learning algorithm, especially regarding the privacy preserving factor, using CT scans of COVID-19 patients, X-ray bone scans, and cholesterol level medical data.
On the Benefits of Selectivity in Pseudo-Labeling for Unsupervised Multi-Source-Free Domain Adaptation
Feb 16, 2022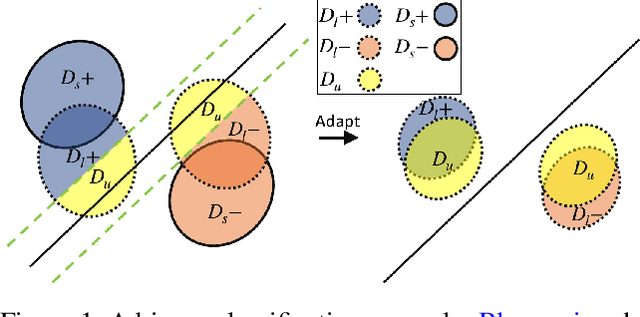
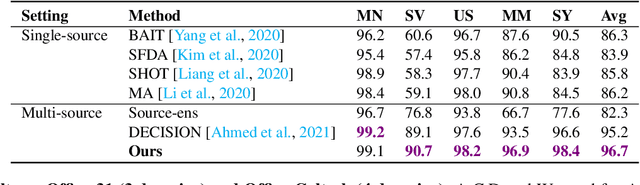
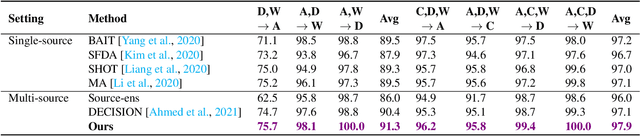
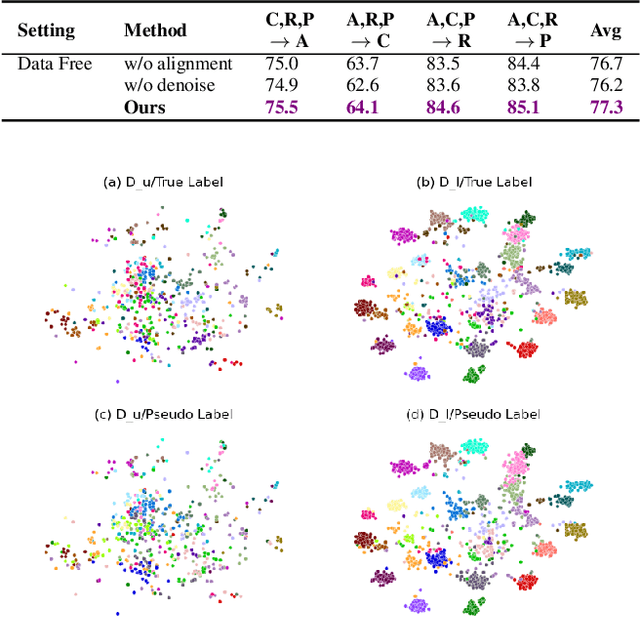
Due to privacy, storage, and other constraints, there is a growing need for unsupervised domain adaptation techniques in machine learning that do not require access to the data used to train a collection of source models. Existing methods for such multi-source-free domain adaptation typically train a target model using supervised techniques in conjunction with pseudo-labels for the target data, which are produced by the available source models. However, we show that assigning pseudo-labels to only a subset of the target data leads to improved performance. In particular, we develop an information-theoretic bound on the generalization error of the resulting target model that demonstrates an inherent bias-variance trade-off controlled by the subset choice. Guided by this analysis, we develop a method that partitions the target data into pseudo-labeled and unlabeled subsets to balance the trade-off. In addition to exploiting the pseudo-labeled subset, our algorithm further leverages the information in the unlabeled subset via a traditional unsupervised domain adaptation feature alignment procedure. Experiments on multiple benchmark datasets demonstrate the superior performance of the proposed method.
Learning to Synthesize Volumetric Meshes from Vision-based Tactile Imprints
Mar 29, 2022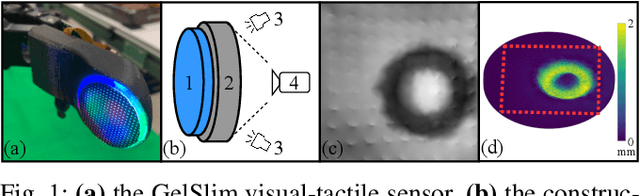
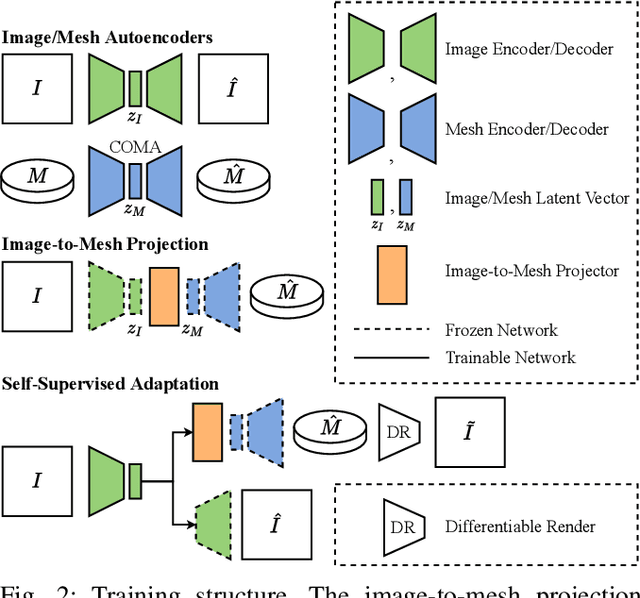


Vision-based tactile sensors typically utilize a deformable elastomer and a camera mounted above to provide high-resolution image observations of contacts. Obtaining accurate volumetric meshes for the deformed elastomer can provide direct contact information and benefit robotic grasping and manipulation. This paper focuses on learning to synthesize the volumetric mesh of the elastomer based on the image imprints acquired from vision-based tactile sensors. Synthetic image-mesh pairs and real-world images are gathered from 3D finite element methods (FEM) and physical sensors, respectively. A graph neural network (GNN) is introduced to learn the image-to-mesh mappings with supervised learning. A self-supervised adaptation method and image augmentation techniques are proposed to transfer networks from simulation to reality, from primitive contacts to unseen contacts, and from one sensor to another. Using these learned and adapted networks, our proposed method can accurately reconstruct the deformation of the real-world tactile sensor elastomer in various domains, as indicated by the quantitative and qualitative results.