 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetector-Evasive LLM Paraphrasing via Constrained Policy Optimization
May 29, 2026AI-text detectors are vulnerable to paraphrasing and detector-guided paraphrasing attacks, but existing detector-evasion methods often lack precise control over semantic preservation. In particular, optimizing directly for detector evasion can degrade fine-grained semantics, whereas scalarized reward designs provide only indirect, weight-sensitive control over the evasion-semantics trade-off. We address this limitation by formulating detector-evasive LLM paraphrasing as a Constrained Markov Decision Process, where detector evasion is the primary objective and semantic preservation is enforced as an explicit constraint. We propose Detector Evasion Policy Optimization (DEPO), a Lagrangian primal-dual reinforcement learning algorithm with a novel GRPO-style group-based policy update. DEPO adaptively balances semantic preservation and detector evasion during training, enabling the policy to improve attack success within a prescribed semantic-preservation region. Experiments on MAGE, M4, RAID, and peer-review datasets, evaluated against MAGE, RoBERTa, RADAR, Binoculars, and Fast-DetectGPT detectors, show that DEPO achieves strong detector evasion while precisely satisfying the semantic preservation constraint. DEPO also exhibits cross-domain, cross-detector, and prompt-level robustness.
WorldMemArena: Evaluating Multimodal Agent Memory Through Action-World Interaction
May 28, 2026Multimodal large language models are increasingly deployed as long-horizon agents, where memory must do more than recall: it must track an evolving world, revise what has gone stale, and surface the right evidence at decision time. Existing benchmarks measure recall over static dialogue, collapse memory into a single end-of-task accuracy, and reduce visual observations to captions, leaving us unable to localize failures to writing, maintenance, retrieval, or use. The rise of agent harnesses that author their own memory sharpens this gap, since we have no principled way to compare hand-designed pipelines with self-managing alternatives. To close these gaps, we formulate multimodal agent memory as an Action-World Interaction Loop with an observable four-stage lifecycle, and instantiate it in WorldMemArena: 400 multi-session multimodal tasks spanning Lifelong Evolution (evolving personal and task states) and Agentic Execution (memory from real observations, actions, and feedback), annotated with gold memory points, updates, distractors, and evidence chains for stage-level diagnosis. This enables the first head-to-head comparison of long-context, manually designed (RAG and external memory systems), and harness-based memory agents. Results show that: (1) better memory writing and storage do not guarantee better performance; (2) multimodal memory still struggles to fully use visual evidence; (3) systems are unstable across domains and degrade on realistic agentic trajectories; and (4) harness memory is more flexible but remains costly and less reliable.
Auditing Agent Harness Safety
May 14, 2026LLM agents increasingly run inside execution harnesses that dispatch tools, allocate resources, and route messages between specialized components. However, a harness can return a correct, benign answer over a trajectory that accesses unauthorized resources or leaks context to the wrong agent. Output-level evaluation cannot see these failures, yet most safety benchmarks score only final outputs or terminal states, even though many violations occur mid-trajectory rather than at termination. The central question is whether the harness respects user intent, permission boundaries, and information-flow constraints throughout execution. To address this gap, we propose HarnessAudit, a framework that audits full execution trajectories across boundary compliance, execution fidelity, and system stability, with a focus on multi-agent harnesses where these risks are most pronounced. We further introduce HarnessAudit-Bench, a benchmark of 210 tasks across eight real-world domains, instantiated in both single-agent and multi-agent configurations with embedded safety constraints. Evaluating ten harness configurations across frontier models and three multi-agent frameworks, we find that: (i) task completion is misaligned with safe execution, and violations accumulate with trajectory length; (ii) safety risks vary across domains, task types, and agent roles; (iii) most violations concentrate in resource access and inter-agent information transfer; and (iv) multi-agent collaboration expands the safety risk surface, while harness design sets the upper bound of safe deployment.
ConvexBench: Can LLMs Recognize Convex Functions?
Feb 01, 2026Convex analysis is a modern branch of mathematics with many applications. As Large Language Models (LLMs) start to automate research-level math and sciences, it is important for LLMs to demonstrate the ability to understand and reason with convexity. We introduce \cb, a scalable and mechanically verifiable benchmark for testing \textit{whether LLMs can identify the convexity of a symbolic objective under deep functional composition.} Experiments on frontier LLMs reveal a sharp compositional reasoning gap: performance degrades rapidly with increasing depth, dropping from an F1-score of $1.0$ at depth $2$ to approximately $0.2$ at depth $100$. Inspection of models' reasoning traces indicates two failure modes: \textit{parsing failure} and \textit{lazy reasoning}. To address these limitations, we propose an agentic divide-and-conquer framework that (i) offloads parsing to an external tool to construct an abstract syntax tree (AST) and (ii) enforces recursive reasoning over each intermediate sub-expression with focused context. This framework reliably mitigates deep-composition failures, achieving substantial performance improvement at large depths (e.g., F1-Score $= 1.0$ at depth $100$).
TrustEnergy: A Unified Framework for Accurate and Reliable User-level Energy Usage Prediction
Jan 19, 2026Energy usage prediction is important for various real-world applications, including grid management, infrastructure planning, and disaster response. Although a plethora of deep learning approaches have been proposed to perform this task, most of them either overlook the essential spatial correlations across households or fail to scale to individualized prediction, making them less effective for accurate fine-grained user-level prediction. In addition, due to the dynamic and uncertain nature of energy usage caused by various factors such as extreme weather events, quantifying uncertainty for reliable prediction is also significant, but it has not been fully explored in existing work. In this paper, we propose a unified framework called TrustEnergy for accurate and reliable user-level energy usage prediction. There are two key technical components in TrustEnergy, (i) a Hierarchical Spatiotemporal Representation module to efficiently capture both macro and micro energy usage patterns with a novel memory-augmented spatiotemporal graph neural network, and (ii) an innovative Sequential Conformalized Quantile Regression module to dynamically adjust uncertainty bounds to ensure valid prediction intervals over time, without making strong assumptions about the underlying data distribution. We implement and evaluate our TrustEnergy framework by working with an electricity provider in Florida, and the results show our TrustEnergy can achieve a 5.4% increase in prediction accuracy and 5.7% improvement in uncertainty quantification compared to state-of-the-art baselines.
NestGNN: A Graph Neural Network Framework Generalizing the Nested Logit Model for Travel Mode Choice
Sep 08, 2025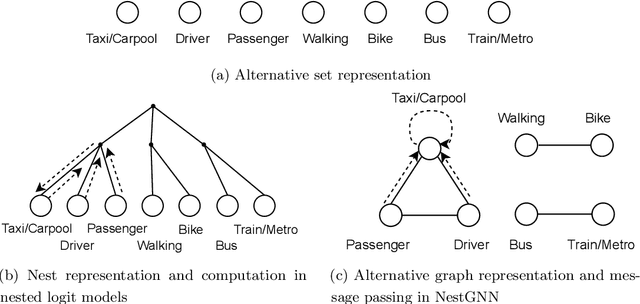
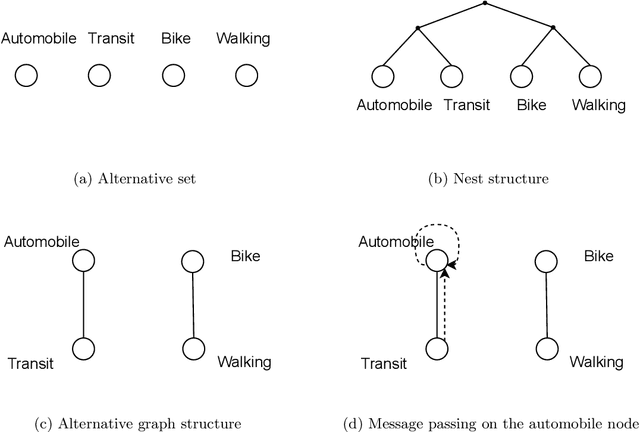

Nested logit (NL) has been commonly used for discrete choice analysis, including a wide range of applications such as travel mode choice, automobile ownership, or location decisions. However, the classical NL models are restricted by their limited representation capability and handcrafted utility specification. While researchers introduced deep neural networks (DNNs) to tackle such challenges, the existing DNNs cannot explicitly capture inter-alternative correlations in the discrete choice context. To address the challenges, this study proposes a novel concept - alternative graph - to represent the relationships among travel mode alternatives. Using a nested alternative graph, this study further designs a nested-utility graph neural network (NestGNN) as a generalization of the classical NL model in the neural network family. Theoretically, NestGNNs generalize the classical NL models and existing DNNs in terms of model representation, while retaining the crucial two-layer substitution patterns of the NL models: proportional substitution within a nest but non-proportional substitution beyond a nest. Empirically, we find that the NestGNNs significantly outperform the benchmark models, particularly the corresponding NL models by 9.2\%. As shown by elasticity tables and substitution visualization, NestGNNs retain the two-layer substitution patterns as the NL model, and yet presents more flexibility in its model design space. Overall, our study demonstrates the power of NestGNN in prediction, interpretation, and its flexibility of generalizing the classical NL model for analyzing travel mode choice.
UQGNN: Uncertainty Quantification of Graph Neural Networks for Multivariate Spatiotemporal Prediction
Aug 12, 2025



Spatiotemporal prediction plays a critical role in numerous real-world applications such as urban planning, transportation optimization, disaster response, and pandemic control. In recent years, researchers have made significant progress by developing advanced deep learning models for spatiotemporal prediction. However, most existing models are deterministic, i.e., predicting only the expected mean values without quantifying uncertainty, leading to potentially unreliable and inaccurate outcomes. While recent studies have introduced probabilistic models to quantify uncertainty, they typically focus on a single phenomenon (e.g., taxi, bike, crime, or traffic crashes), thereby neglecting the inherent correlations among heterogeneous urban phenomena. To address the research gap, we propose a novel Graph Neural Network with Uncertainty Quantification, termed UQGNN for multivariate spatiotemporal prediction. UQGNN introduces two key innovations: (i) an Interaction-aware Spatiotemporal Embedding Module that integrates a multivariate diffusion graph convolutional network and an interaction-aware temporal convolutional network to effectively capture complex spatial and temporal interaction patterns, and (ii) a multivariate probabilistic prediction module designed to estimate both expected mean values and associated uncertainties. Extensive experiments on four real-world multivariate spatiotemporal datasets from Shenzhen, New York City, and Chicago demonstrate that UQGNN consistently outperforms state-of-the-art baselines in both prediction accuracy and uncertainty quantification. For example, on the Shenzhen dataset, UQGNN achieves a 5% improvement in both prediction accuracy and uncertainty quantification.
SAM2-SGP: Enhancing SAM2 for Medical Image Segmentation via Support-Set Guided Prompting
Jun 24, 2025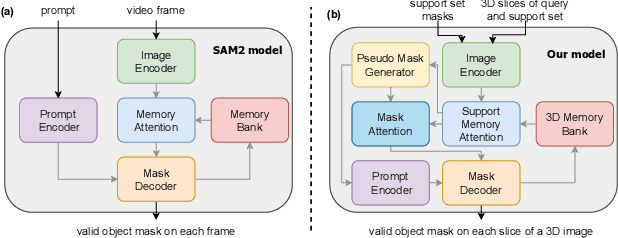
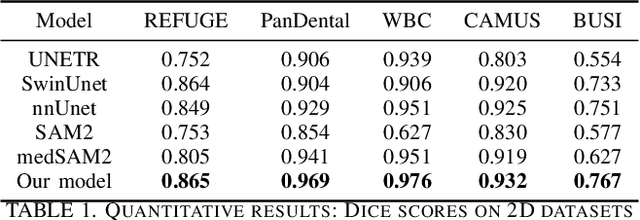
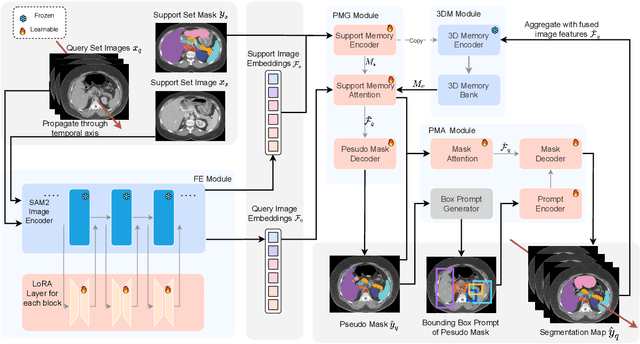
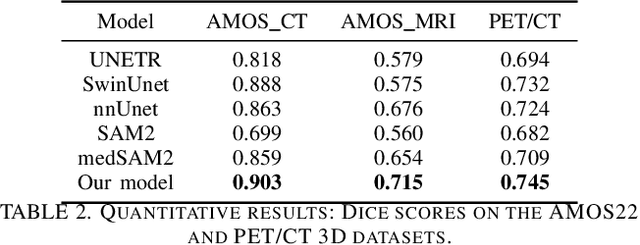
Although new vision foundation models such as Segment Anything Model 2 (SAM2) have significantly enhanced zero-shot image segmentation capabilities, reliance on human-provided prompts poses significant challenges in adapting SAM2 to medical image segmentation tasks. Moreover, SAM2's performance in medical image segmentation was limited by the domain shift issue, since it was originally trained on natural images and videos. To address these challenges, we proposed SAM2 with support-set guided prompting (SAM2-SGP), a framework that eliminated the need for manual prompts. The proposed model leveraged the memory mechanism of SAM2 to generate pseudo-masks using image-mask pairs from a support set via a Pseudo-mask Generation (PMG) module. We further introduced a novel Pseudo-mask Attention (PMA) module, which used these pseudo-masks to automatically generate bounding boxes and enhance localized feature extraction by guiding attention to relevant areas. Furthermore, a low-rank adaptation (LoRA) strategy was adopted to mitigate the domain shift issue. The proposed framework was evaluated on both 2D and 3D datasets across multiple medical imaging modalities, including fundus photography, X-ray, computed tomography (CT), magnetic resonance imaging (MRI), positron emission tomography (PET), and ultrasound. The results demonstrated a significant performance improvement over state-of-the-art models, such as nnUNet and SwinUNet, as well as foundation models, such as SAM2 and MedSAM2, underscoring the effectiveness of the proposed approach. Our code is publicly available at https://github.com/astlian9/SAM_Support.
Fairness Overfitting in Machine Learning: An Information-Theoretic Perspective
Jun 09, 2025Despite substantial progress in promoting fairness in high-stake applications using machine learning models, existing methods often modify the training process, such as through regularizers or other interventions, but lack formal guarantees that fairness achieved during training will generalize to unseen data. Although overfitting with respect to prediction performance has been extensively studied, overfitting in terms of fairness loss has received far less attention. This paper proposes a theoretical framework for analyzing fairness generalization error through an information-theoretic lens. Our novel bounding technique is based on Efron-Stein inequality, which allows us to derive tight information-theoretic fairness generalization bounds with both Mutual Information (MI) and Conditional Mutual Information (CMI). Our empirical results validate the tightness and practical relevance of these bounds across diverse fairness-aware learning algorithms. Our framework offers valuable insights to guide the design of algorithms improving fairness generalization.
In-Context Watermarks for Large Language Models
May 22, 2025



The growing use of large language models (LLMs) for sensitive applications has highlighted the need for effective watermarking techniques to ensure the provenance and accountability of AI-generated text. However, most existing watermarking methods require access to the decoding process, limiting their applicability in real-world settings. One illustrative example is the use of LLMs by dishonest reviewers in the context of academic peer review, where conference organizers have no access to the model used but still need to detect AI-generated reviews. Motivated by this gap, we introduce In-Context Watermarking (ICW), which embeds watermarks into generated text solely through prompt engineering, leveraging LLMs' in-context learning and instruction-following abilities. We investigate four ICW strategies at different levels of granularity, each paired with a tailored detection method. We further examine the Indirect Prompt Injection (IPI) setting as a specific case study, in which watermarking is covertly triggered by modifying input documents such as academic manuscripts. Our experiments validate the feasibility of ICW as a model-agnostic, practical watermarking approach. Moreover, our findings suggest that as LLMs become more capable, ICW offers a promising direction for scalable and accessible content attribution.