 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXRZero-G0: Pushing the Frontier of Dexterous Robotic Manipulation with Interfaces, Quality and Ratios
Apr 14, 2026The acquisition of high-quality, action-aligned demonstration data remains a fundamental bottleneck in scaling foundation models for dexterous robot manipulation. Although robot-free human demonstrations (e.g., the UMI paradigm) offer a scalable alternative to traditional teleoperation, current systems are constrained by sub-optimal hardware ergonomics, open-loop workflows, and a lack of systematic data-mixing strategies. To address these limitations, we present XRZero-G0, a hardware-software co-designed system for embodied data collection and policy learning. The system features an ergonomic, virtual reality interface equipped with a top-view camera and dual specialized grippers to directly improve collection efficiency. To ensure dataset reliability, we propose a closed-loop collection, inspection, training, and evaluation pipeline for non-proprioceptive data. This workflow achieves an 85% data validity rate and establishes a transparent mechanism for quality control. Furthermore, we investigate the empirical scaling behaviors and optimal mixing ratios of robot-free data. Extensive experiments indicate that combining a minimal volume of real-robot data with large-scale robot-free data (e.g., a 10:1 ratio) achieves performance comparable to exclusively real-robot datasets, while reducing acquisition costs by a factor of twenty. Utilizing XRZero-G0, we construct a 2,000-hour robot-free dataset that enables zero-shot cross-embodiment transfer to a target physical robot, demonstrating a highly scalable methodology for generalized real-world manipulation.Our project repository: https://github.com/X-Square-Robot/XRZero-G0
Enhancing Text-to-Image Generation via End-Edge Collaborative Hybrid Super-Resolution
Jan 21, 2026Artificial Intelligence-Generated Content (AIGC) has made significant strides, with high-resolution text-to-image (T2I) generation becoming increasingly critical for improving users' Quality of Experience (QoE). Although resource-constrained edge computing adequately supports fast low-resolution T2I generations, achieving high-resolution output still faces the challenge of ensuring image fidelity at the cost of latency. To address this, we first investigate the performance of super-resolution (SR) methods for image enhancement, confirming a fundamental trade-off that lightweight learning-based SR struggles to recover fine details, while diffusion-based SR achieves higher fidelity at a substantial computational cost. Motivated by these observations, we propose an end-edge collaborative generation-enhancement framework. Upon receiving a T2I generation task, the system first generates a low-resolution image based on adaptively selected denoising steps and super-resolution scales at the edge side, which is then partitioned into patches and processed by a region-aware hybrid SR policy. This policy applies a diffusion-based SR model to foreground patches for detail recovery and a lightweight learning-based SR model to background patches for efficient upscaling, ultimately stitching the enhanced ones into the high-resolution image. Experiments show that our system reduces service latency by 33% compared with baselines while maintaining competitive image quality.
Global-Local Medical SAM Adaptor Based on Full Adaption
Sep 26, 2024

Emerging of visual language models, such as the segment anything model (SAM), have made great breakthroughs in the field of universal semantic segmentation and significantly aid the improvements of medical image segmentation, in particular with the help of Medical SAM adaptor (Med-SA). However, Med-SA still can be improved, as it fine-tunes SAM in a partial adaption manner. To resolve this problem, we present a novel global medical SAM adaptor (GMed-SA) with full adaption, which can adapt SAM globally. We further combine GMed-SA and Med-SA to propose a global-local medical SAM adaptor (GLMed-SA) to adapt SAM both globally and locally. Extensive experiments have been performed on the challenging public 2D melanoma segmentation dataset. The results show that GLMed-SA outperforms several state-of-the-art semantic segmentation methods on various evaluation metrics, demonstrating the superiority of our methods.
Resource-Efficient Generative AI Model Deployment in Mobile Edge Networks
Sep 09, 2024



The surging development of Artificial Intelligence-Generated Content (AIGC) marks a transformative era of the content creation and production. Edge servers promise attractive benefits, e.g., reduced service delay and backhaul traffic load, for hosting AIGC services compared to cloud-based solutions. However, the scarcity of available resources on the edge pose significant challenges in deploying generative AI models. In this paper, by characterizing the resource and delay demands of typical generative AI models, we find that the consumption of storage and GPU memory, as well as the model switching delay represented by I/O delay during the preloading phase, are significant and vary across models. These multidimensional coupling factors render it difficult to make efficient edge model deployment decisions. Hence, we present a collaborative edge-cloud framework aiming to properly manage generative AI model deployment on the edge. Specifically, we formulate edge model deployment problem considering heterogeneous features of models as an optimization problem, and propose a model-level decision selection algorithm to solve it. It enables pooled resource sharing and optimizes the trade-off between resource consumption and delay in edge generative AI model deployment. Simulation results validate the efficacy of the proposed algorithm compared with baselines, demonstrating its potential to reduce overall costs by providing feature-aware model deployment decisions.
Learning to Trust Your Feelings: Leveraging Self-awareness in LLMs for Hallucination Mitigation
Jan 27, 2024



We evaluate the ability of Large Language Models (LLMs) to discern and express their internal knowledge state, a key factor in countering factual hallucination and ensuring reliable application of LLMs. We observe a robust self-awareness of internal knowledge state in LLMs, evidenced by over 85% accuracy in knowledge probing. However, LLMs often fail to express their internal knowledge during generation, leading to factual hallucinations. We develop an automated hallucination annotation tool, Dreamcatcher, which merges knowledge probing and consistency checking methods to rank factual preference data. Using knowledge preference as reward, We propose a Reinforcement Learning from Knowledge Feedback (RLKF) training framework, leveraging reinforcement learning to enhance the factuality and honesty of LLMs. Our experiments across multiple models show that RLKF training effectively enhances the ability of models to utilize their internal knowledge state, boosting performance in a variety of knowledge-based and honesty-related tasks.
AcademicGPT: Empowering Academic Research
Nov 21, 2023



Large Language Models (LLMs) have demonstrated exceptional capabilities across various natural language processing tasks. Yet, many of these advanced LLMs are tailored for broad, general-purpose applications. In this technical report, we introduce AcademicGPT, designed specifically to empower academic research. AcademicGPT is a continual training model derived from LLaMA2-70B. Our training corpus mainly consists of academic papers, thesis, content from some academic domain, high-quality Chinese data and others. While it may not be extensive in data scale, AcademicGPT marks our initial venture into a domain-specific GPT tailored for research area. We evaluate AcademicGPT on several established public benchmarks such as MMLU and CEval, as well as on some specialized academic benchmarks like PubMedQA, SCIEval, and our newly-created ComputerScienceQA, to demonstrate its ability from general knowledge ability, to Chinese ability, and to academic ability. Building upon AcademicGPT's foundation model, we also developed several applications catered to the academic area, including General Academic Question Answering, AI-assisted Paper Reading, Paper Review, and AI-assisted Title and Abstract Generation.
Never Lost in the Middle: Improving Large Language Models via Attention Strengthening Question Answering
Nov 15, 2023



While large language models (LLMs) are equipped with longer text input capabilities than before, they are struggling to seek correct information in long contexts. The "lost in the middle" problem challenges most LLMs, referring to the dramatic decline in accuracy when correct information is located in the middle. To overcome this crucial issue, this paper proposes to enhance the information searching and reflection ability of LLMs in long contexts via specially designed tasks called Attention Strengthening Multi-doc QA (ASM QA). Following these tasks, our model excels in focusing more precisely on the desired information. Experimental results show substantial improvement in Multi-doc QA and other benchmarks, superior to state-of-the-art models by 13.7% absolute gain in shuffled settings, by 21.5% in passage retrieval task. We release our model, Ziya-Reader to promote related research in the community.
Exploring the Impact of Negative Samples of Contrastive Learning: A Case Study of Sentence Embedding
Mar 16, 2022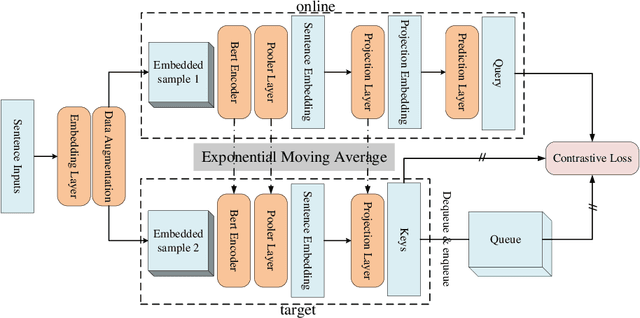
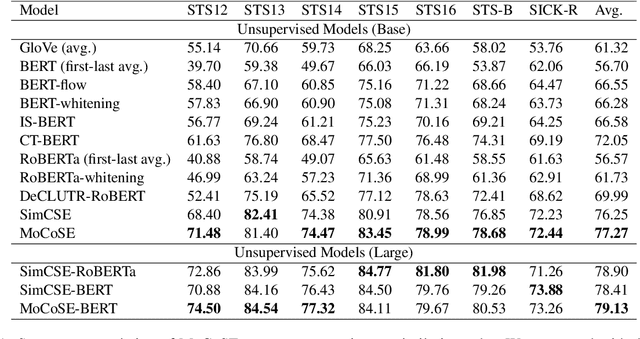
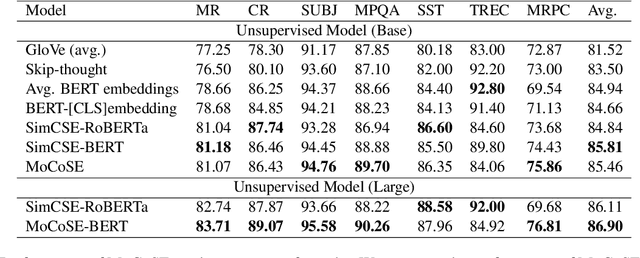
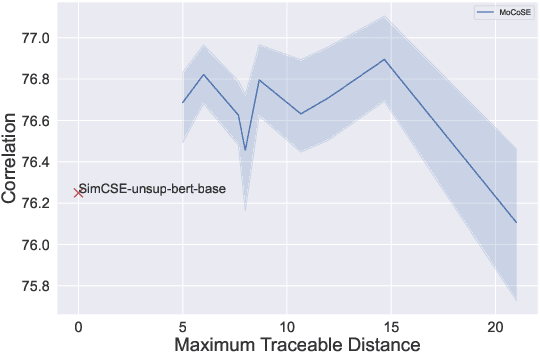
Contrastive learning is emerging as a powerful technique for extracting knowledge from unlabeled data. This technique requires a balanced mixture of two ingredients: positive (similar) and negative (dissimilar) samples. This is typically achieved by maintaining a queue of negative samples during training. Prior works in the area typically uses a fixed-length negative sample queue, but how the negative sample size affects the model performance remains unclear. The opaque impact of the number of negative samples on performance when employing contrastive learning aroused our in-depth exploration. This paper presents a momentum contrastive learning model with negative sample queue for sentence embedding, namely MoCoSE. We add the prediction layer to the online branch to make the model asymmetric and together with EMA update mechanism of the target branch to prevent the model from collapsing. We define a maximum traceable distance metric, through which we learn to what extent the text contrastive learning benefits from the historical information of negative samples. Our experiments find that the best results are obtained when the maximum traceable distance is at a certain range, demonstrating that there is an optimal range of historical information for a negative sample queue. We evaluate the proposed unsupervised MoCoSE on the semantic text similarity (STS) task and obtain an average Spearman's correlation of $77.27\%$. Source code is available at https://github.com/xbdxwyh/mocose.
Learning to Remove: Towards Isotropic Pre-trained BERT Embedding
Apr 12, 2021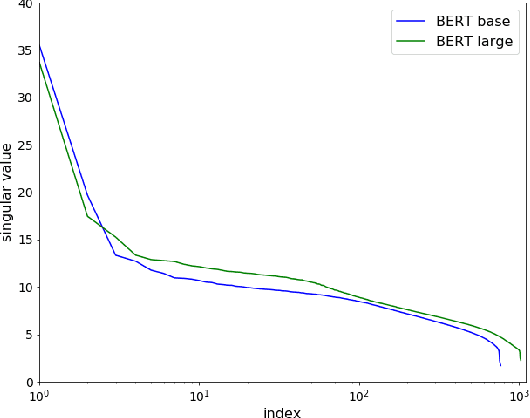
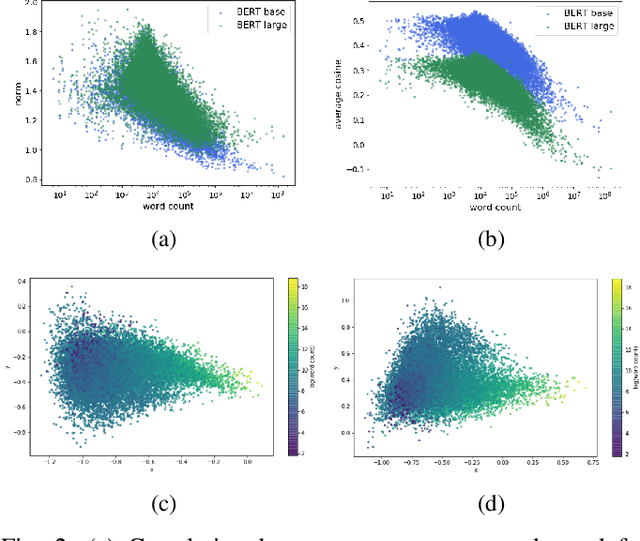
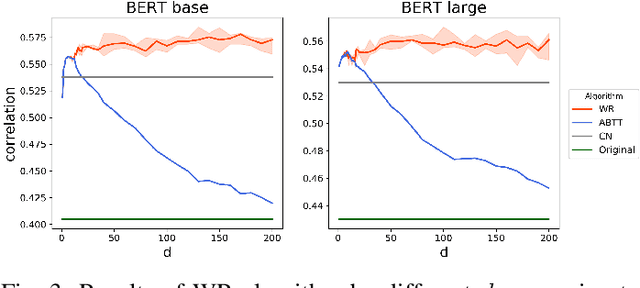
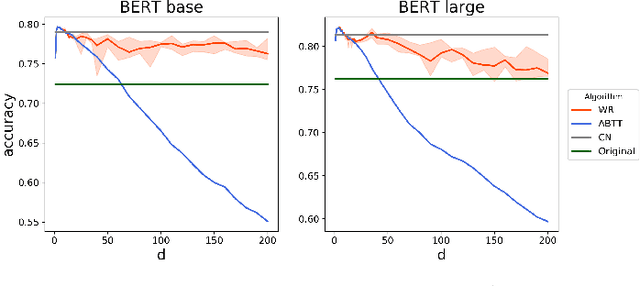
Pre-trained language models such as BERT have become a more common choice of natural language processing (NLP) tasks. Research in word representation shows that isotropic embeddings can significantly improve performance on downstream tasks. However, we measure and analyze the geometry of pre-trained BERT embedding and find that it is far from isotropic. We find that the word vectors are not centered around the origin, and the average cosine similarity between two random words is much higher than zero, which indicates that the word vectors are distributed in a narrow cone and deteriorate the representation capacity of word embedding. We propose a simple, and yet effective method to fix this problem: remove several dominant directions of BERT embedding with a set of learnable weights. We train the weights on word similarity tasks and show that processed embedding is more isotropic. Our method is evaluated on three standardized tasks: word similarity, word analogy, and semantic textual similarity. In all tasks, the word embedding processed by our method consistently outperforms the original embedding (with average improvement of 13% on word analogy and 16% on semantic textual similarity) and two baseline methods. Our method is also proven to be more robust to changes of hyperparameter.