 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
What do we learn? Debunking the Myth of Unsupervised Outlier Detection
Jun 08, 2022
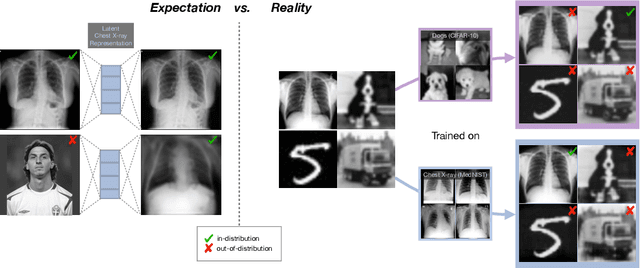
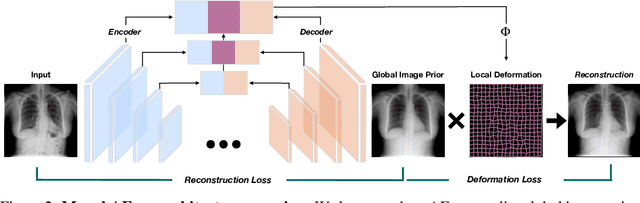
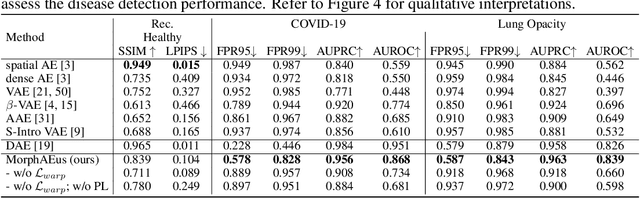
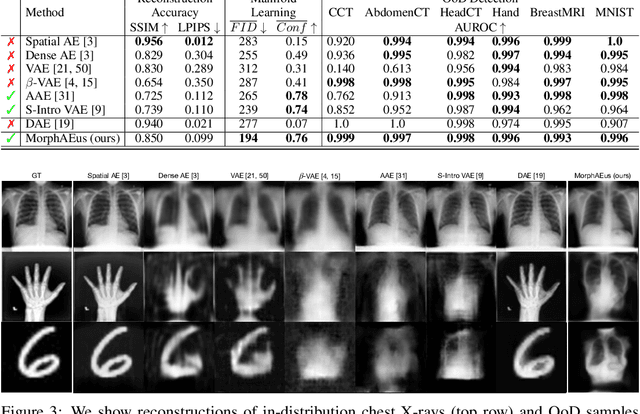
Even though auto-encoders (AEs) have the desirable property of learning compact representations without labels and have been widely applied to out-of-distribution (OoD) detection, they are generally still poorly understood and are used incorrectly in detecting outliers where the normal and abnormal distributions are strongly overlapping. In general, the learned manifold is assumed to contain key information that is only important for describing samples within the training distribution, and that the reconstruction of outliers leads to high residual errors. However, recent work suggests that AEs are likely to be even better at reconstructing some types of OoD samples. In this work, we challenge this assumption and investigate what auto-encoders actually learn when they are posed to solve two different tasks. First, we propose two metrics based on the Fr\'echet inception distance (FID) and confidence scores of a trained classifier to assess whether AEs can learn the training distribution and reliably recognize samples from other domains. Second, we investigate whether AEs are able to synthesize normal images from samples with abnormal regions, on a more challenging lung pathology detection task. We have found that state-of-the-art (SOTA) AEs are either unable to constrain the latent manifold and allow reconstruction of abnormal patterns, or they are failing to accurately restore the inputs from their latent distribution, resulting in blurred or misaligned reconstructions. We propose novel deformable auto-encoders (MorphAEus) to learn perceptually aware global image priors and locally adapt their morphometry based on estimated dense deformation fields. We demonstrate superior performance over unsupervised methods in detecting OoD and pathology.
Vision Transformer with Cross-attention by Temporal Shift for Efficient Action Recognition
Apr 01, 2022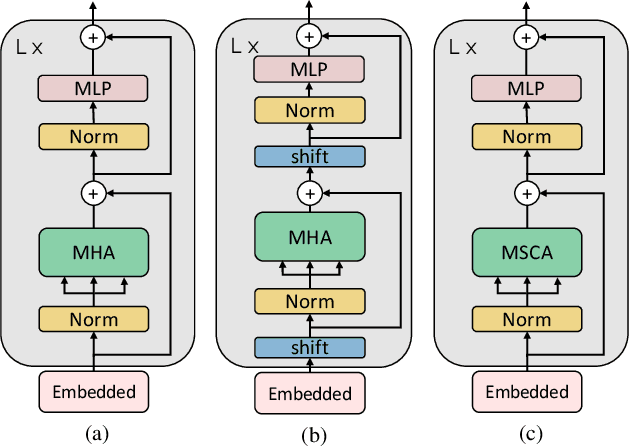
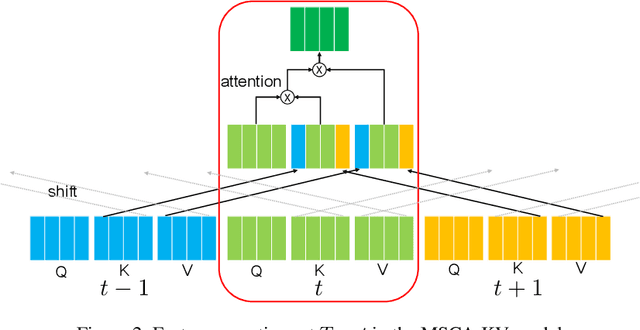
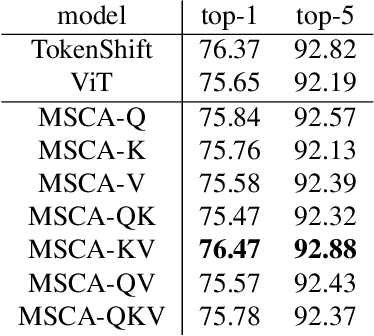
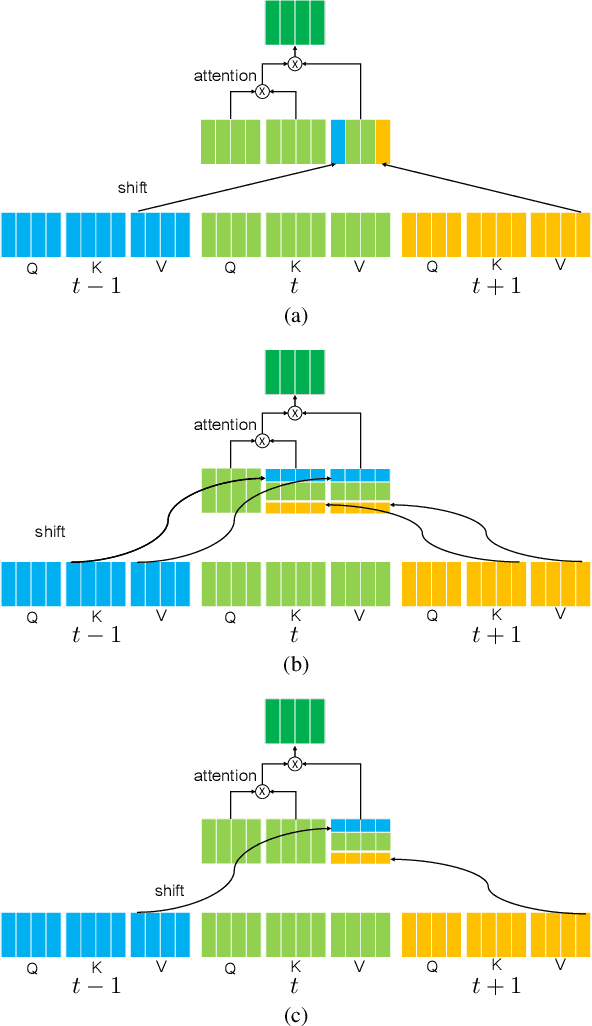
We propose Multi-head Self/Cross-Attention (MSCA), which introduces a temporal cross-attention mechanism for action recognition, based on the structure of the Multi-head Self-Attention (MSA) mechanism of the Vision Transformer (ViT). Simply applying ViT to each frame of a video frame can capture frame features, but cannot model temporal features. However, simply modeling temporal information with CNN or Transfomer is computationally expensive. TSM that perform feature shifting assume a CNN and cannot take advantage of the ViT structure. The proposed model captures temporal information by shifting the Query, Key, and Value in the calculation of MSA of ViT. This is efficient without additional coinformationmputational effort and is a suitable structure for extending ViT over temporal. Experiments on Kineitcs400 show the effectiveness of the proposed method and its superiority over previous methods.
Distributed learning optimisation of Cox models can leak patient data: Risks and solutions
Apr 12, 2022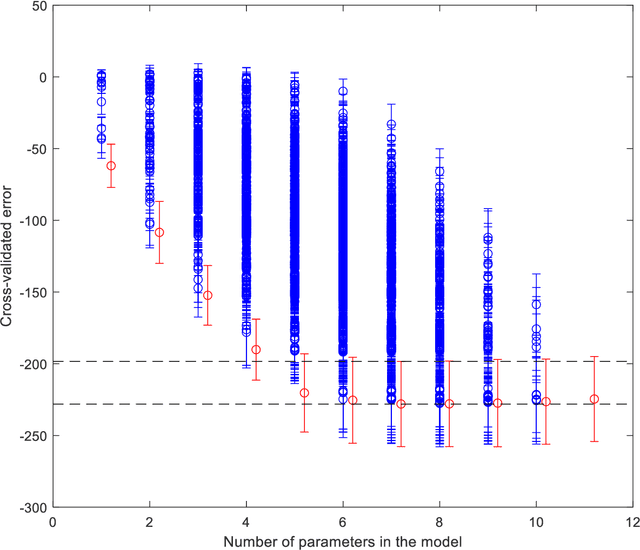
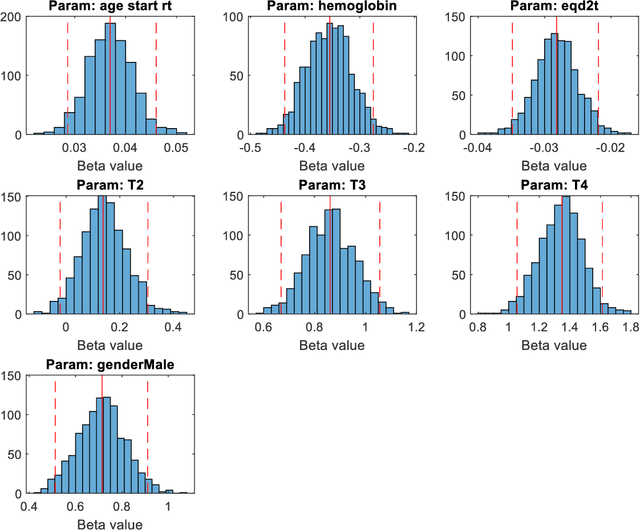
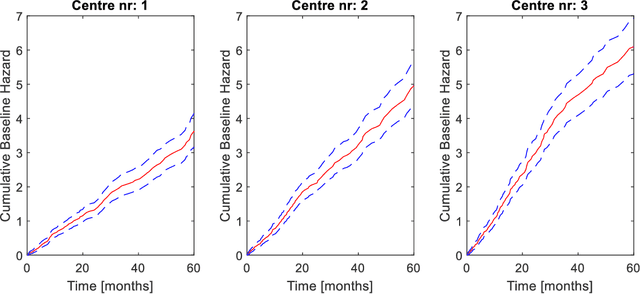
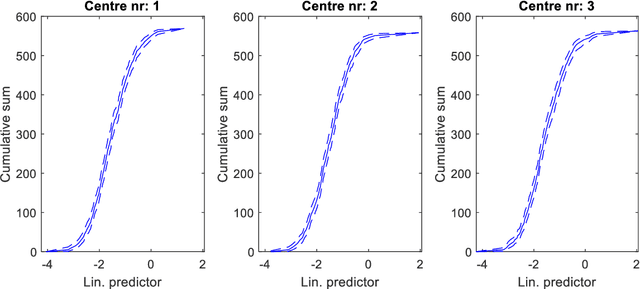
Medical data are often highly sensitive, and frequently there are missing data. Due to the data's sensitive nature, there is an interest in creating modelling methods where the data are kept in each local centre to preserve their privacy, but yet the model can be trained on and learn from data across multiple centres. Such an approach might be distributed machine learning (federated learning, collaborative learning) in which a model is iteratively calculated based on aggregated local model information from each centre. However, even though no specific data are leaving the centre, there is a potential risk that the exchanged information is sufficient to reconstruct all or part of the patient data, which would hamper the safety-protecting rationale idea of distributed learning. This paper demonstrates that the optimisation of a Cox survival model can lead to patient data leakage. Following this, we suggest a way to optimise and validate a Cox model that avoids these problems in a secure way. The feasibility of the suggested method is demonstrated in a provided Matlab code that also includes methods for handling missing data.
Recurrent Video Restoration Transformer with Guided Deformable Attention
Jun 05, 2022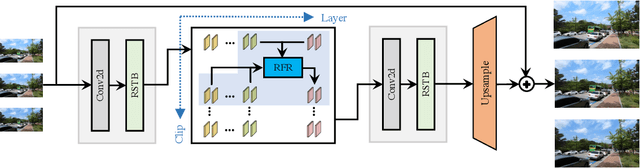
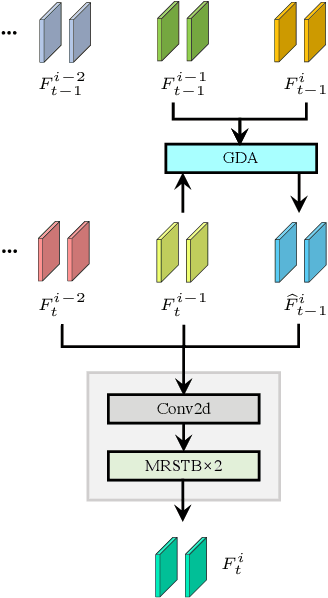
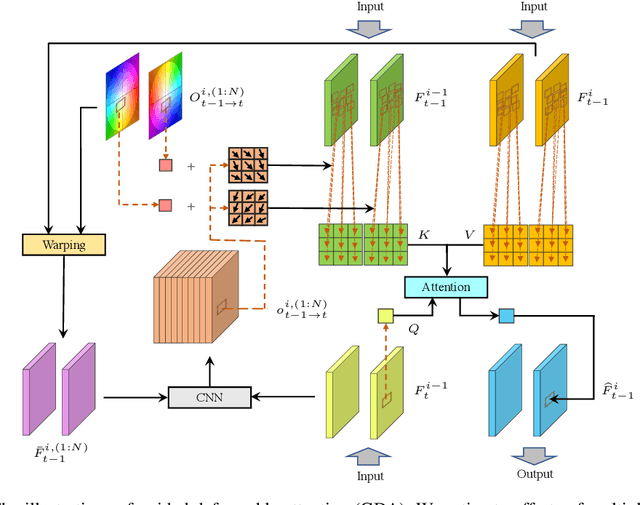
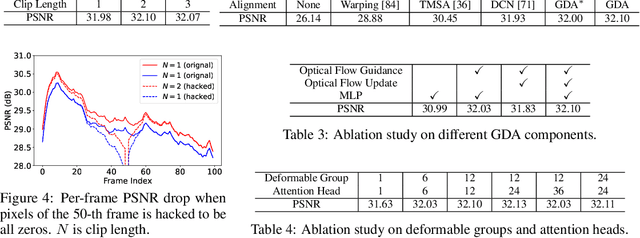
Video restoration aims at restoring multiple high-quality frames from multiple low-quality frames. Existing video restoration methods generally fall into two extreme cases, i.e., they either restore all frames in parallel or restore the video frame by frame in a recurrent way, which would result in different merits and drawbacks. Typically, the former has the advantage of temporal information fusion. However, it suffers from large model size and intensive memory consumption; the latter has a relatively small model size as it shares parameters across frames; however, it lacks long-range dependency modeling ability and parallelizability. In this paper, we attempt to integrate the advantages of the two cases by proposing a recurrent video restoration transformer, namely RVRT. RVRT processes local neighboring frames in parallel within a globally recurrent framework which can achieve a good trade-off between model size, effectiveness, and efficiency. Specifically, RVRT divides the video into multiple clips and uses the previously inferred clip feature to estimate the subsequent clip feature. Within each clip, different frame features are jointly updated with implicit feature aggregation. Across different clips, the guided deformable attention is designed for clip-to-clip alignment, which predicts multiple relevant locations from the whole inferred clip and aggregates their features by the attention mechanism. Extensive experiments on video super-resolution, deblurring, and denoising show that the proposed RVRT achieves state-of-the-art performance on benchmark datasets with balanced model size, testing memory and runtime.
Self-supervised Learning of Audio Representations from Audio-Visual Data using Spatial Alignment
Jun 02, 2022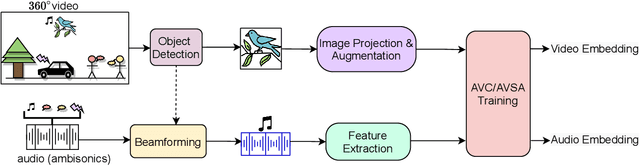
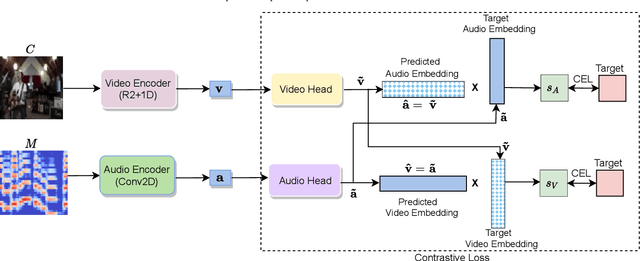
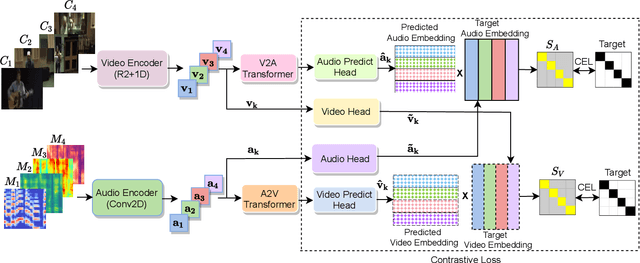

Learning from audio-visual data offers many possibilities to express correspondence between the audio and visual content, similar to the human perception that relates aural and visual information. In this work, we present a method for self-supervised representation learning based on audio-visual spatial alignment (AVSA), a more sophisticated alignment task than the audio-visual correspondence (AVC). In addition to the correspondence, AVSA also learns from the spatial location of acoustic and visual content. Based on 360$^\text{o}$ video and Ambisonics audio, we propose selection of visual objects using object detection, and beamforming of the audio signal towards the detected objects, attempting to learn the spatial alignment between objects and the sound they produce. We investigate the use of spatial audio features to represent the audio input, and different audio formats: Ambisonics, mono, and stereo. Experimental results show a 10 $\%$ improvement on AVSA for the first order ambisonics intensity vector (FOA-IV) in comparison with log-mel spectrogram features; the addition of object-oriented crops also brings significant performance increases for the human action recognition downstream task. A number of audio-only downstream tasks are devised for testing the effectiveness of the learnt audio feature representation, obtaining performance comparable to state-of-the-art methods on acoustic scene classification from ambisonic and binaural audio.
User-Centric Conversational Recommendation with Multi-Aspect User Modeling
Apr 20, 2022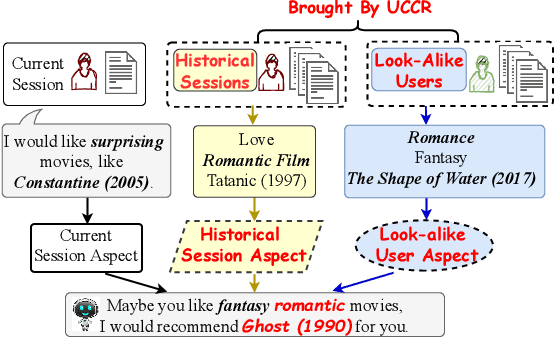
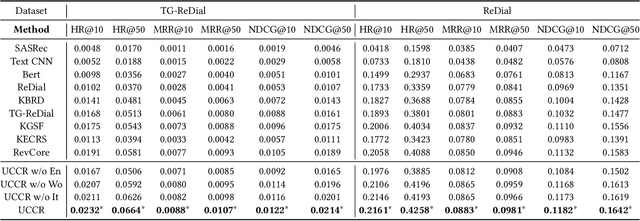
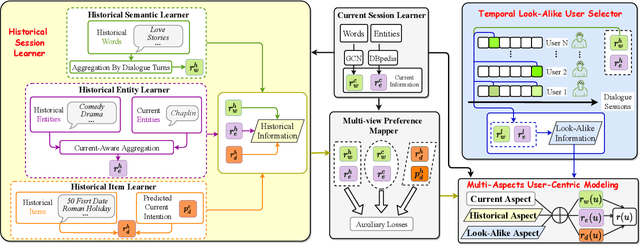
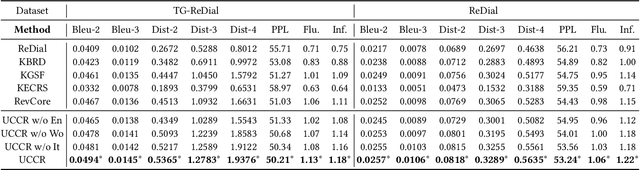
Conversational recommender systems (CRS) aim to provide highquality recommendations in conversations. However, most conventional CRS models mainly focus on the dialogue understanding of the current session, ignoring other rich multi-aspect information of the central subjects (i.e., users) in recommendation. In this work, we highlight that the user's historical dialogue sessions and look-alike users are essential sources of user preferences besides the current dialogue session in CRS. To systematically model the multi-aspect information, we propose a User-Centric Conversational Recommendation (UCCR) model, which returns to the essence of user preference learning in CRS tasks. Specifically, we propose a historical session learner to capture users' multi-view preferences from knowledge, semantic, and consuming views as supplements to the current preference signals. A multi-view preference mapper is conducted to learn the intrinsic correlations among different views in current and historical sessions via self-supervised objectives. We also design a temporal look-alike user selector to understand users via their similar users. The learned multi-aspect multi-view user preferences are then used for the recommendation and dialogue generation. In experiments, we conduct comprehensive evaluations on both Chinese and English CRS datasets. The significant improvements over competitive models in both recommendation and dialogue generation verify the superiority of UCCR.
Info-Evo: Using Information Geometry to Guide Evolutionary Program Learning
Feb 20, 2021A novel optimization strategy, Info-Evo, is described, in which natural gradient search using nonparametric Fisher information is used to provide ongoing guidance to an evolutionary learning algorithm, so that the evolutionary process preferentially moves in the directions identified as "shortest paths" according to the natural gradient. Some specifics regarding the application of this approach to automated program learning are reviewed, including a strategy for integrating Info-Evo into the MOSES program learning framework.
A lightweight multi-scale context network for salient object detection in optical remote sensing images
May 18, 2022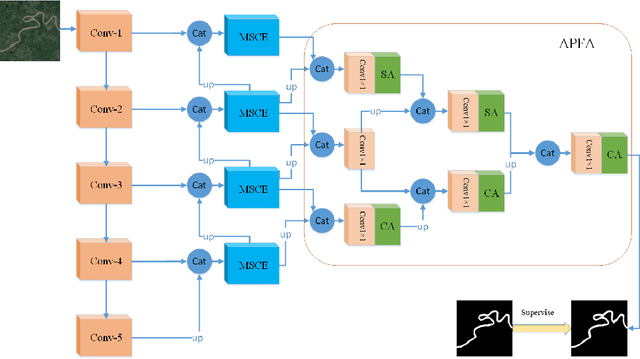
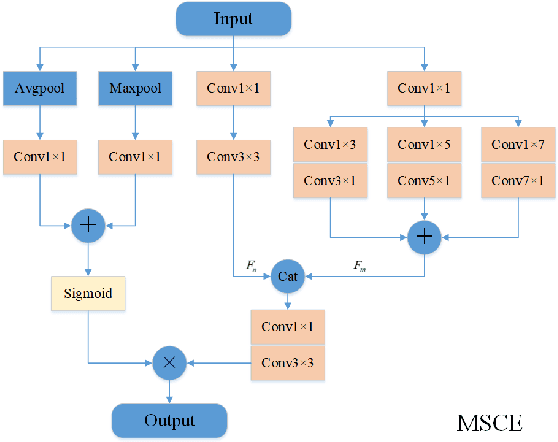
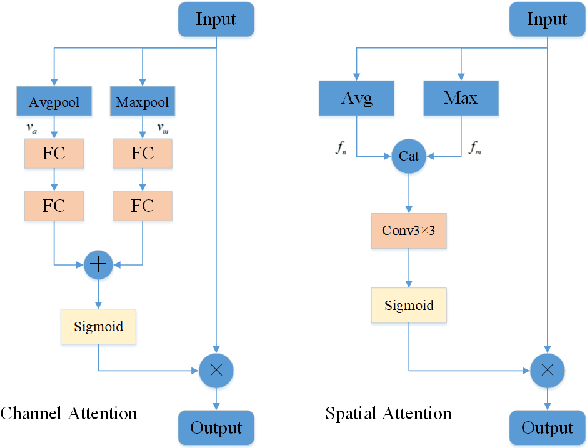

Due to the more dramatic multi-scale variations and more complicated foregrounds and backgrounds in optical remote sensing images (RSIs), the salient object detection (SOD) for optical RSIs becomes a huge challenge. However, different from natural scene images (NSIs), the discussion on the optical RSI SOD task still remains scarce. In this paper, we propose a multi-scale context network, namely MSCNet, for SOD in optical RSIs. Specifically, a multi-scale context extraction module is adopted to address the scale variation of salient objects by effectively learning multi-scale contextual information. Meanwhile, in order to accurately detect complete salient objects in complex backgrounds, we design an attention-based pyramid feature aggregation mechanism for gradually aggregating and refining the salient regions from the multi-scale context extraction module. Extensive experiments on two benchmarks demonstrate that MSCNet achieves competitive performance with only 3.26M parameters. The code will be available at https://github.com/NuaaYH/MSCNet.
Disentangling Spatial-Temporal Functional Brain Networks via Twin-Transformers
Apr 20, 2022

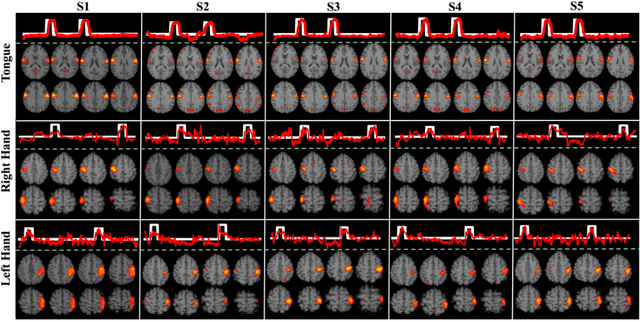
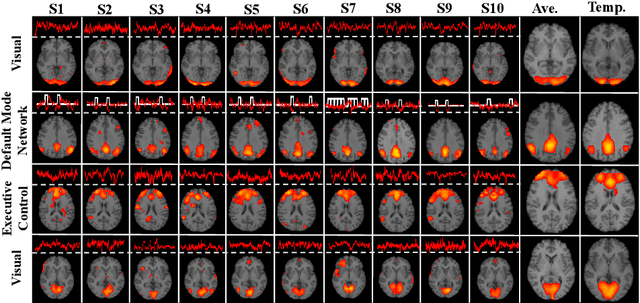
How to identify and characterize functional brain networks (BN) is fundamental to gain system-level insights into the mechanisms of brain organizational architecture. Current functional magnetic resonance (fMRI) analysis highly relies on prior knowledge of specific patterns in either spatial (e.g., resting-state network) or temporal (e.g., task stimulus) domain. In addition, most approaches aim to find group-wise common functional networks, individual-specific functional networks have been rarely studied. In this work, we propose a novel Twin-Transformers framework to simultaneously infer common and individual functional networks in both spatial and temporal space, in a self-supervised manner. The first transformer takes space-divided information as input and generates spatial features, while the second transformer takes time-related information as input and outputs temporal features. The spatial and temporal features are further separated into common and individual ones via interactions (weights sharing) and constraints between the two transformers. We applied our TwinTransformers to Human Connectome Project (HCP) motor task-fMRI dataset and identified multiple common brain networks, including both task-related and resting-state networks (e.g., default mode network). Interestingly, we also successfully recovered a set of individual-specific networks that are not related to task stimulus and only exist at the individual level.
Transfer and Share: Semi-Supervised Learning from Long-Tailed Data
May 26, 2022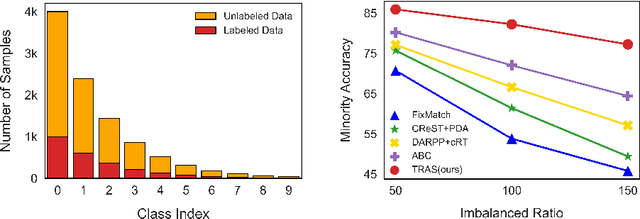
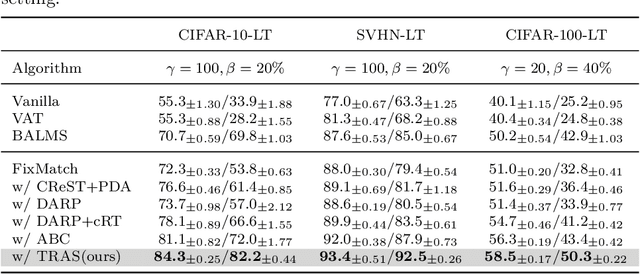
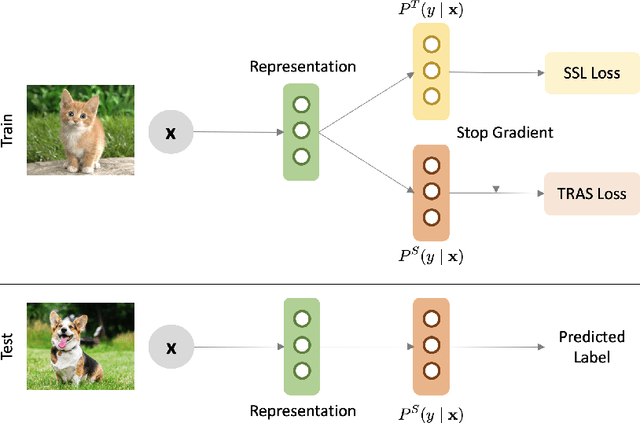

Long-Tailed Semi-Supervised Learning (LTSSL) aims to learn from class-imbalanced data where only a few samples are annotated. Existing solutions typically require substantial cost to solve complex optimization problems, or class-balanced undersampling which can result in information loss. In this paper, we present the TRAS (TRAnsfer and Share) to effectively utilize long-tailed semi-supervised data. TRAS transforms the imbalanced pseudo-label distribution of a traditional SSL model via a delicate function to enhance the supervisory signals for minority classes. It then transfers the distribution to a target model such that the minority class will receive significant attention. Interestingly, TRAS shows that more balanced pseudo-label distribution can substantially benefit minority-class training, instead of seeking to generate accurate pseudo-labels as in previous works. To simplify the approach, TRAS merges the training of the traditional SSL model and the target model into a single procedure by sharing the feature extractor, where both classifiers help improve the representation learning. According to extensive experiments, TRAS delivers much higher accuracy than state-of-the-art methods in the entire set of classes as well as minority classes.