 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
mSHINE: A Multiple-meta-paths Simultaneous Learning Framework for Heterogeneous Information Network Embedding
Apr 09, 2021
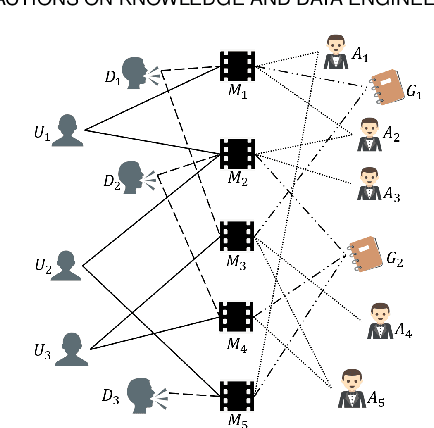
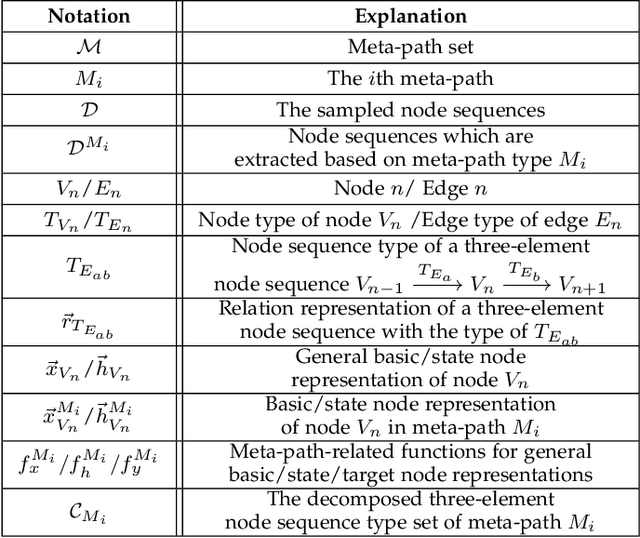
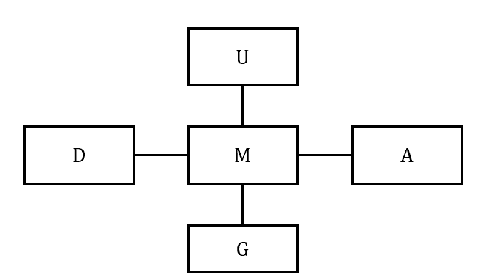
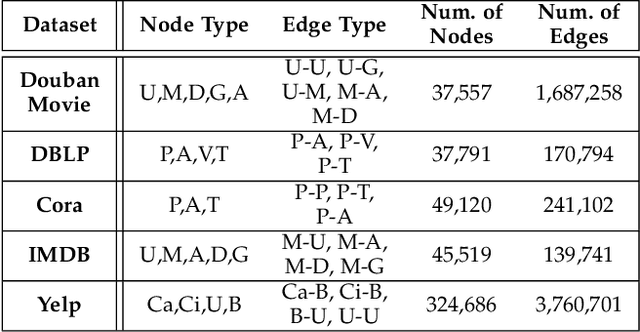
Heterogeneous information networks(HINs) become popular in recent years for its strong capability of modelling objects with abundant information using explicit network structure. Network embedding has been proved as an effective method to convert information networks into lower-dimensional space, whereas the core information can be well preserved. However, traditional network embedding algorithms are sub-optimal in capturing rich while potentially incompatible semantics provided by HINs. To address this issue, a novel meta-path-based HIN representation learning framework named mSHINE is designed to simultaneously learn multiple node representations for different meta-paths. More specifically, one representation learning module inspired by the RNN structure is developed and multiple node representations can be learned simultaneously, where each representation is associated with one respective meta-path. By measuring the relevance between nodes with the designed objective function, the learned module can be applied in downstream link prediction tasks. A set of criteria for selecting initial meta-paths is proposed as the other module in mSHINE which is important to reduce the optimal meta-path selection cost when no prior knowledge of suitable meta-paths is available. To corroborate the effectiveness of mSHINE, extensive experimental studies including node classification and link prediction are conducted on five real-world datasets. The results demonstrate that mSHINE outperforms other state-of-the-art HIN embedding methods.
Cross-subject Action Unit Detection with Meta Learning and Transformer-based Relation Modeling
May 18, 2022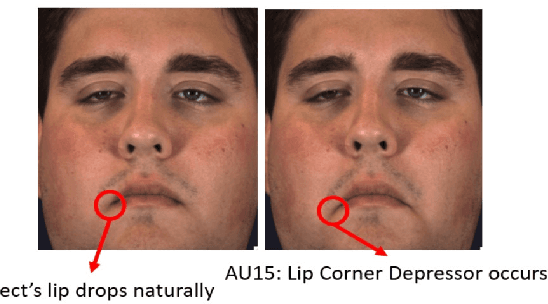
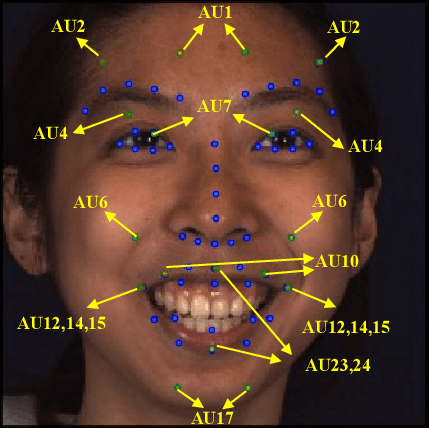
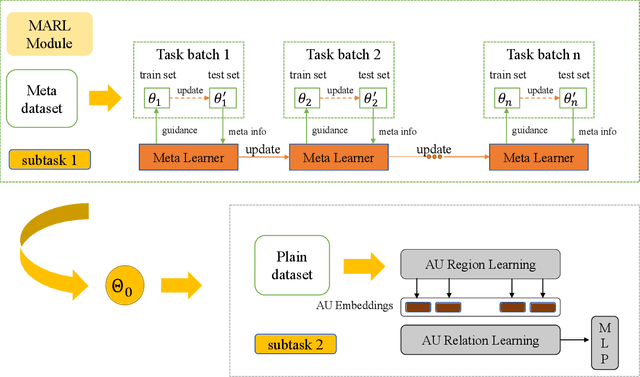
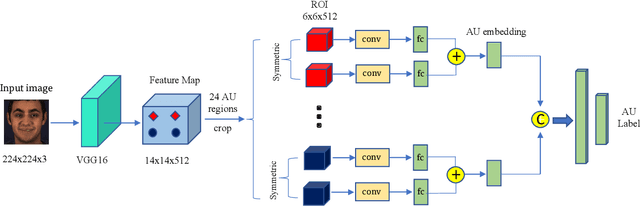
Facial Action Unit (AU) detection is a crucial task for emotion analysis from facial movements. The apparent differences of different subjects sometimes mislead changes brought by AUs, resulting in inaccurate results. However, most of the existing AU detection methods based on deep learning didn't consider the identity information of different subjects. The paper proposes a meta-learning-based cross-subject AU detection model to eliminate the identity-caused differences. Besides, a transformer-based relation learning module is introduced to learn the latent relations of multiple AUs. To be specific, our proposed work is composed of two sub-tasks. The first sub-task is meta-learning-based AU local region representation learning, called MARL, which learns discriminative representation of local AU regions that incorporates the shared information of multiple subjects and eliminates identity-caused differences. The second sub-task uses the local region representation of AU of the first sub-task as input, then adds relationship learning based on the transformer encoder architecture to capture AU relationships. The entire training process is cascaded. Ablation study and visualization show that our MARL can eliminate identity-caused differences, thus obtaining a robust and generalized AU discriminative embedding representation. Our results prove that on the two public datasets BP4D and DISFA, our method is superior to the state-of-the-art technology, and the F1 score is improved by 1.3% and 1.4%, respectively.
Injecting Knowledge Base Information into End-to-End Joint Entity and Relation Extraction and Coreference Resolution
Jul 05, 2021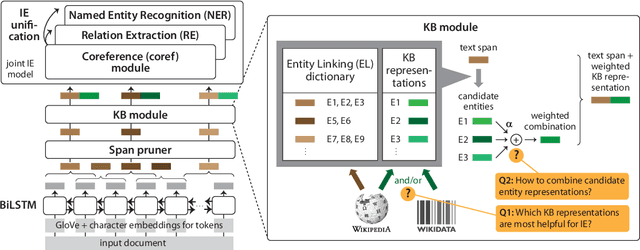

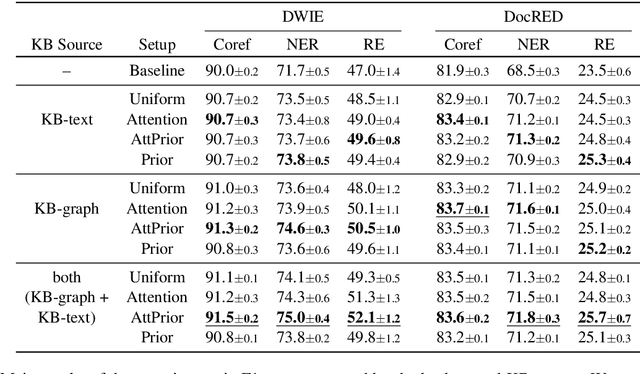

We consider a joint information extraction (IE) model, solving named entity recognition, coreference resolution and relation extraction jointly over the whole document. In particular, we study how to inject information from a knowledge base (KB) in such IE model, based on unsupervised entity linking. The used KB entity representations are learned from either (i) hyperlinked text documents (Wikipedia), or (ii) a knowledge graph (Wikidata), and appear complementary in raising IE performance. Representations of corresponding entity linking (EL) candidates are added to text span representations of the input document, and we experiment with (i) taking a weighted average of the EL candidate representations based on their prior (in Wikipedia), and (ii) using an attention scheme over the EL candidate list. Results demonstrate an increase of up to 5% F1-score for the evaluated IE tasks on two datasets. Despite a strong performance of the prior-based model, our quantitative and qualitative analysis reveals the advantage of using the attention-based approach.
Protecting Celebrities from DeepFake with Identity Consistency Transformer
Apr 05, 2022
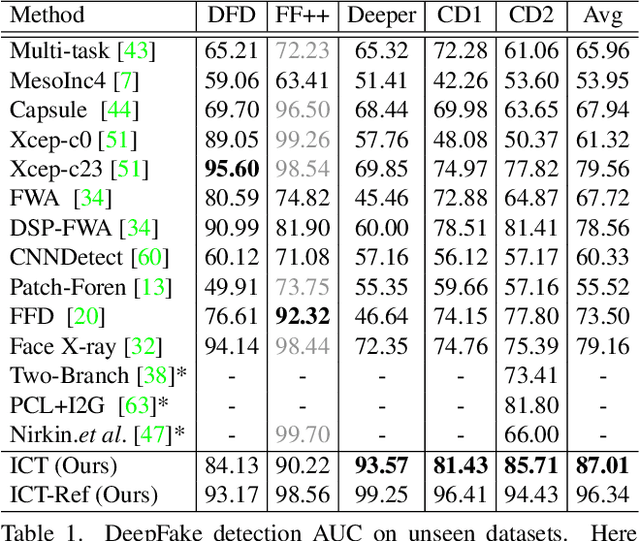

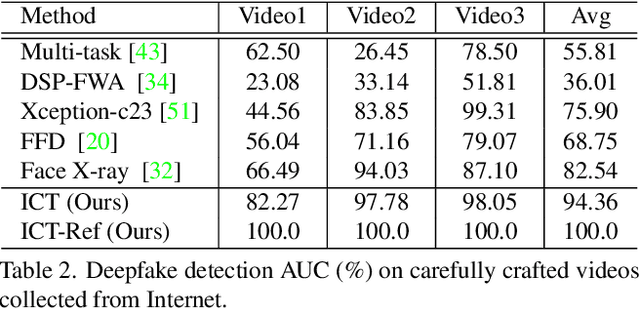
In this work we propose Identity Consistency Transformer, a novel face forgery detection method that focuses on high-level semantics, specifically identity information, and detecting a suspect face by finding identity inconsistency in inner and outer face regions. The Identity Consistency Transformer incorporates a consistency loss for identity consistency determination. We show that Identity Consistency Transformer exhibits superior generalization ability not only across different datasets but also across various types of image degradation forms found in real-world applications including deepfake videos. The Identity Consistency Transformer can be easily enhanced with additional identity information when such information is available, and for this reason it is especially well-suited for detecting face forgeries involving celebrities. Code will be released at \url{https://github.com/LightDXY/ICT_DeepFake}
DeStripe: A Self2Self Spatio-Spectral Graph Neural Network with Unfolded Hessian for Stripe Artifact Removal in Light-sheet Microscopy
Jun 27, 2022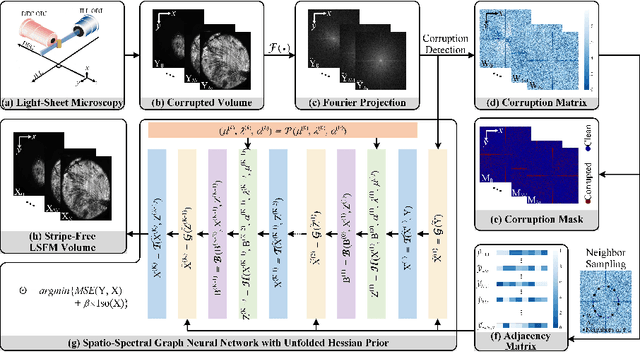
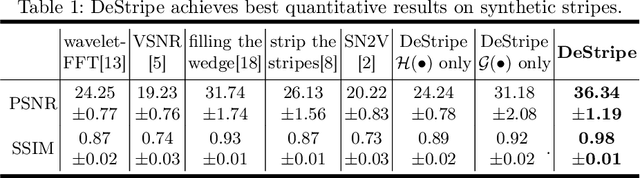

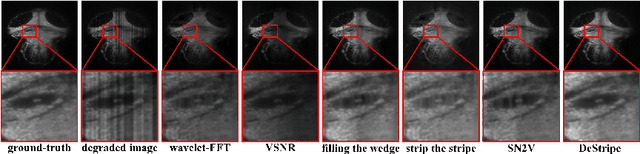
Light-sheet fluorescence microscopy (LSFM) is a cutting-edge volumetric imaging technique that allows for three-dimensional imaging of mesoscopic samples with decoupled illumination and detection paths. Although the selective excitation scheme of such a microscope provides intrinsic optical sectioning that minimizes out-of-focus fluorescence background and sample photodamage, it is prone to light absorption and scattering effects, which results in uneven illumination and striping artifacts in the images adversely. To tackle this issue, in this paper, we propose a blind stripe artifact removal algorithm in LSFM, called DeStripe, which combines a self-supervised spatio-spectral graph neural network with unfolded Hessian prior. Specifically, inspired by the desirable properties of Fourier transform in condensing striping information into isolated values in the frequency domain, DeStripe firstly localizes the potentially corrupted Fourier coefficients by exploiting the structural difference between unidirectional stripe artifacts and more isotropic foreground images. Affected Fourier coefficients can then be fed into a graph neural network for recovery, with a Hessian regularization unrolled to further ensure structures in the standard image space are well preserved. Since in realistic, stripe-free LSFM barely exists with a standard image acquisition protocol, DeStripe is equipped with a Self2Self denoising loss term, enabling artifact elimination without access to stripe-free ground truth images. Competitive experimental results demonstrate the efficacy of DeStripe in recovering corrupted biomarkers in LSFM with both synthetic and real stripe artifacts.
Transfer Learning via Test-Time Neural Networks Aggregation
Jun 27, 2022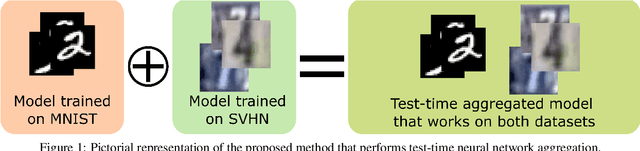
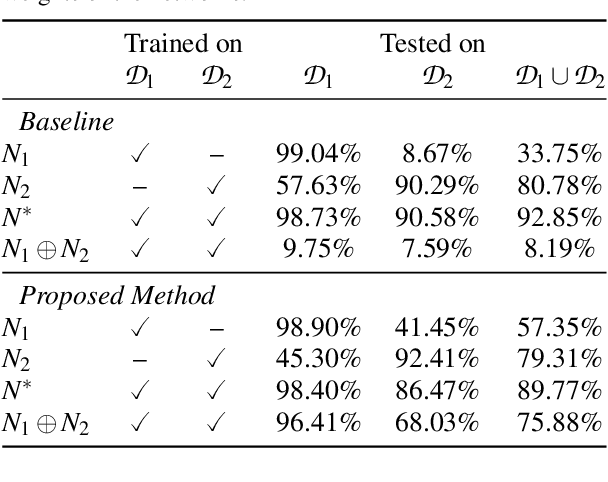
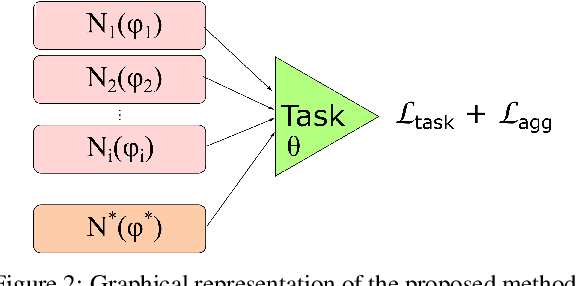
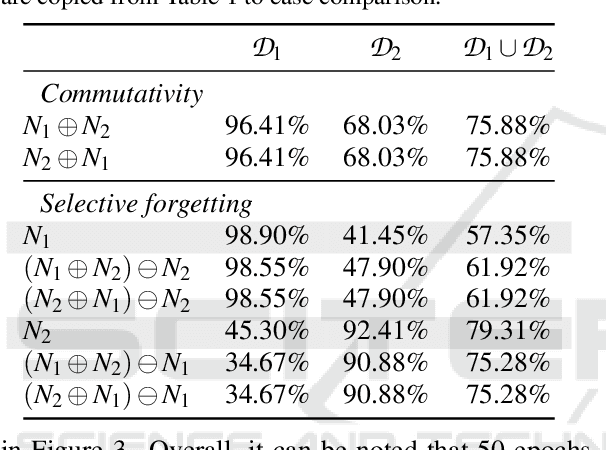
It has been demonstrated that deep neural networks outperform traditional machine learning. However, deep networks lack generalisability, that is, they will not perform as good as in a new (testing) set drawn from a different distribution due to the domain shift. In order to tackle this known issue, several transfer learning approaches have been proposed, where the knowledge of a trained model is transferred into another to improve performance with different data. However, most of these approaches require additional training steps, or they suffer from catastrophic forgetting that occurs when a trained model has overwritten previously learnt knowledge. We address both problems with a novel transfer learning approach that uses network aggregation. We train dataset-specific networks together with an aggregation network in a unified framework. The loss function includes two main components: a task-specific loss (such as cross-entropy) and an aggregation loss. The proposed aggregation loss allows our model to learn how trained deep network parameters can be aggregated with an aggregation operator. We demonstrate that the proposed approach learns model aggregation at test time without any further training step, reducing the burden of transfer learning to a simple arithmetical operation. The proposed approach achieves comparable performance w.r.t. the baseline. Besides, if the aggregation operator has an inverse, we will show that our model also inherently allows for selective forgetting, i.e., the aggregated model can forget one of the datasets it was trained on, retaining information on the others.
* 8 pages
TextDCT: Arbitrary-Shaped Text Detection via Discrete Cosine Transform Mask
Jun 27, 2022

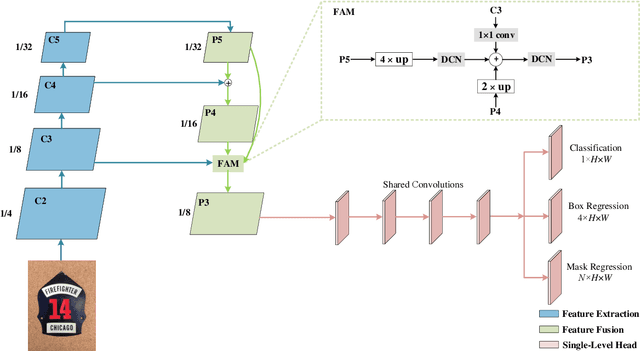
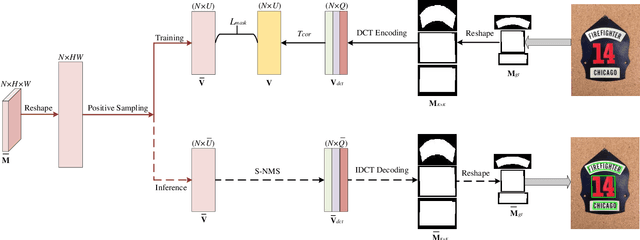
Arbitrary-shaped scene text detection is a challenging task due to the variety of text changes in font, size, color, and orientation. Most existing regression based methods resort to regress the masks or contour points of text regions to model the text instances. However, regressing the complete masks requires high training complexity, and contour points are not sufficient to capture the details of highly curved texts. To tackle the above limitations, we propose a novel light-weight anchor-free text detection framework called TextDCT, which adopts the discrete cosine transform (DCT) to encode the text masks as compact vectors. Further, considering the imbalanced number of training samples among pyramid layers, we only employ a single-level head for top-down prediction. To model the multi-scale texts in a single-level head, we introduce a novel positive sampling strategy by treating the shrunk text region as positive samples, and design a feature awareness module (FAM) for spatial-awareness and scale-awareness by fusing rich contextual information and focusing on more significant features. Moreover, we propose a segmented non-maximum suppression (S-NMS) method that can filter low-quality mask regressions. Extensive experiments are conducted on four challenging datasets, which demonstrate our TextDCT obtains competitive performance on both accuracy and efficiency. Specifically, TextDCT achieves F-measure of 85.1 at 17.2 frames per second (FPS) and F-measure of 84.9 at 15.1 FPS for CTW1500 and Total-Text datasets, respectively.
Learning 3D Object Shape and Layout without 3D Supervision
Jun 14, 2022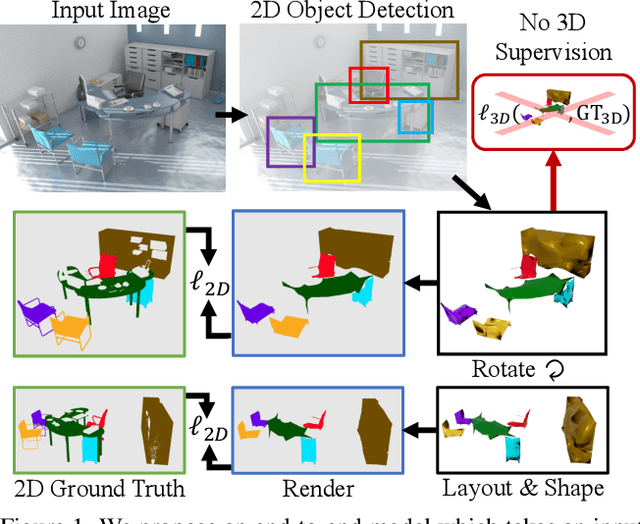
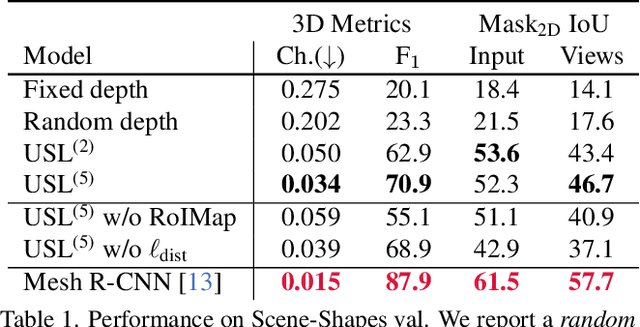
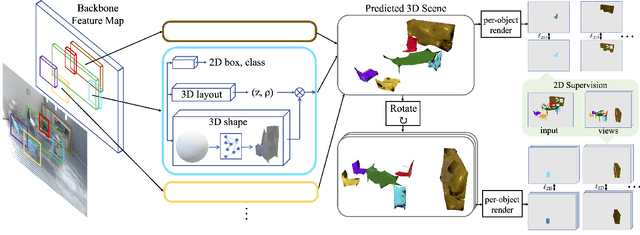
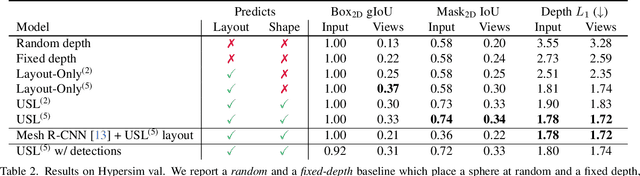
A 3D scene consists of a set of objects, each with a shape and a layout giving their position in space. Understanding 3D scenes from 2D images is an important goal, with applications in robotics and graphics. While there have been recent advances in predicting 3D shape and layout from a single image, most approaches rely on 3D ground truth for training which is expensive to collect at scale. We overcome these limitations and propose a method that learns to predict 3D shape and layout for objects without any ground truth shape or layout information: instead we rely on multi-view images with 2D supervision which can more easily be collected at scale. Through extensive experiments on 3D Warehouse, Hypersim, and ScanNet we demonstrate that our approach scales to large datasets of realistic images, and compares favorably to methods relying on 3D ground truth. On Hypersim and ScanNet where reliable 3D ground truth is not available, our approach outperforms supervised approaches trained on smaller and less diverse datasets.
Dog nose print matching with dual global descriptor based on Contrastive Learning
Jun 01, 2022

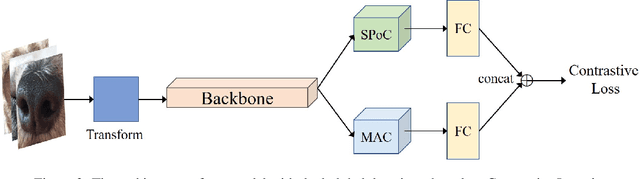

Recent studies in biometric-based identification tasks have shown that deep learning methods can achieve better performance. These methods generally extract the global features as descriptor to represent the original image. Nonetheless, it does not perform well for biometric identification under fine-grained tasks. The main reason is that the single image descriptor contains insufficient information to represent image. In this paper, we present a dual global descriptor model, which combines multiple global descriptors to exploit multi level image features. Moreover, we utilize a contrastive loss to enlarge the distance between image representations of confusing classes. The proposed framework achieves the top2 on the CVPR2022 Biometrics Workshop Pet Biometric Challenge. The source code and trained models are publicly available at: https://github.com/flyingsheepbin/pet-biometrics
Wideband Audio Waveform Evaluation Networks: Efficient, Accurate Estimation of Speech Qualities
Jun 27, 2022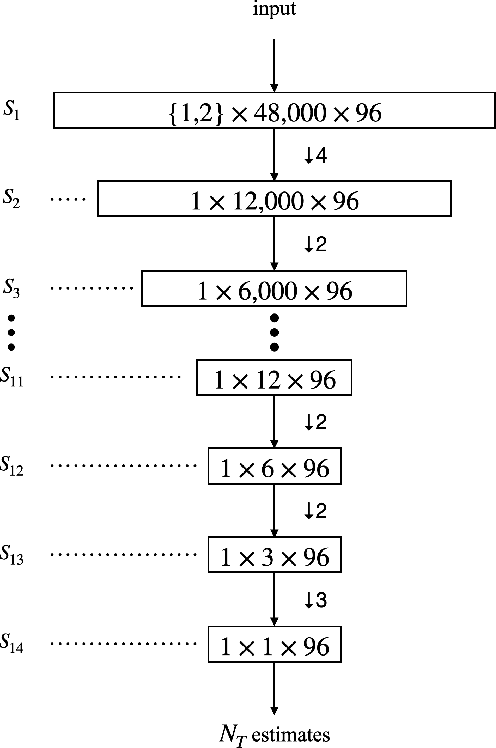
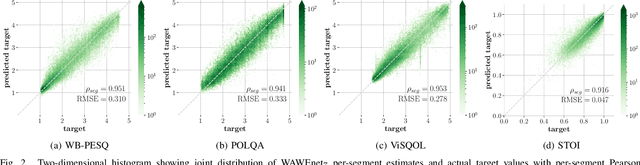
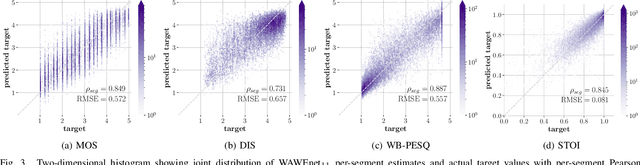
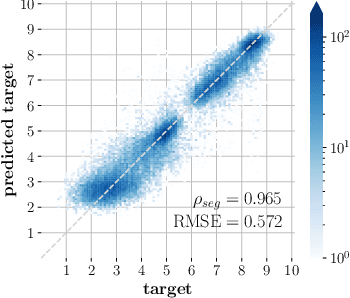
Wideband Audio Waveform Evaluation Networks (WAWEnets) are convolutional neural networks that operate directly on wideband audio waveforms in order to produce evaluations of those waveforms. In the present work these evaluations give qualities of telecommunications speech (e.g., noisiness, intelligibility, overall speech quality). WAWEnets are no-reference networks because they do not require ``reference'' (original or undistorted) versions of the waveforms they evaluate. Our initial WAWEnet publication introduced four WAWEnets and each emulated the output of an established full-reference speech quality or intelligibility estimation algorithm. We have updated the WAWEnet architecture to be more efficient and effective. Here we present a single WAWEnet that closely tracks seven different quality and intelligibility values. We create a second network that additionally tracks four subjective speech quality dimensions. We offer a third network that focuses on just subjective quality scores and achieves very high levels of agreement. This work has leveraged 334 hours of speech in 13 languages, over two million full-reference target values and over 93,000 subjective mean opinion scores. We also interpret the operation of WAWEnets and identify the key to their operation using the language of signal processing: ReLUs strategically move spectral information from non-DC components into the DC component. The DC values of 96 output signals define a vector in a 96-D latent space and this vector is then mapped to a quality or intelligibility value for the input waveform.