 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMVIAD: Multi-view Multi-task Video Understanding for Industrial Anomaly Detection
May 11, 2026Industrial anomaly detection is critical for manufacturing quality control, yet existing datasets mainly focus on static images or sparse views, which do not fully reflect continuous inspection processes in real industrial scenarios. We introduce MMVIAD (Multi-view Multi-task Video Industrial Anomaly Detection), to the best of our knowledge the first continuous multi-view video dataset for industrial anomaly detection and understanding, together with a benchmark for multi-task evaluation. MMVIAD contains object-centric 2-second inspection clips with approximately 120 degrees of camera motion, covering 48 object categories, 14 environments, and 6 structural anomaly types. It supports anomaly detection, defect classification, object classification, and anomaly visible-time localization. Systematic evaluations on MMVIAD show that current commercial and open-source video MLLMs remain far below human performance, especially for fine-grained defect recognition and temporal grounding. To improve transferable anomaly understanding, we further develop a two-stage post-training pipeline where PS-SFT (Perception-Structured Supervised Fine-Tuning) initializes perception-structured reasoning and VISTA-GRPO (Visibility-grounded Industrial Structured Temporal Anomaly Group Relative Policy Optimization) refines the model with semantic-gated defect reward and visibility-aware temporal reward, producing the final model VISTA. On MMVIAD-Unseen, VISTA improves the base model's average score across the four tasks from 45.0 to 57.5, surpassing GPT-5.4. Source code is available at https://github.com/Georgekeepmoving/MMVIAD.
RS-WorldModel: a Unified Model for Remote Sensing Understanding and Future Sense Forecasting
Mar 16, 2026Remote sensing world models aim to both explain observed changes and forecast plausible futures, two tasks that share spatiotemporal priors. Existing methods, however, typically address them separately, limiting cross-task transfer. We present RS-WorldModel, a unified world model for remote sensing that jointly handles spatiotemporal change understanding and text-guided future scene forecasting, and we build RSWBench-1.1M, a 1.1 million sample dataset with rich language annotations covering both tasks. RS-WorldModel is trained in three stages: (1) Geo-Aware Generative Pre-training (GAGP) conditions forecasting on geographic and acquisition metadata; (2) synergistic instruction tuning (SIT) jointly trains understanding and forecasting; (3) verifiable reinforcement optimization (VRO) refines outputs with verifiable, task-specific rewards. With only 2B parameters, RS-WorldModel surpasses open-source models up to 120$ \times $ larger on most spatiotemporal change question-answering metrics. It achieves an FID of 43.13 on text-guided future scene forecasting, outperforming all open-source baselines as well as the closed-source Gemini-2.5-Flash Image (Nano Banana).
Dog nose print matching with dual global descriptor based on Contrastive Learning
Jun 01, 2022

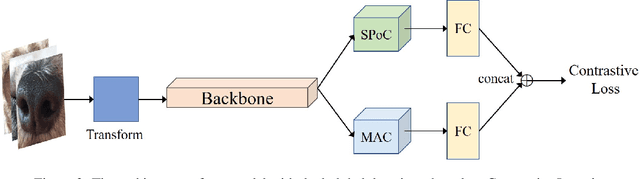

Recent studies in biometric-based identification tasks have shown that deep learning methods can achieve better performance. These methods generally extract the global features as descriptor to represent the original image. Nonetheless, it does not perform well for biometric identification under fine-grained tasks. The main reason is that the single image descriptor contains insufficient information to represent image. In this paper, we present a dual global descriptor model, which combines multiple global descriptors to exploit multi level image features. Moreover, we utilize a contrastive loss to enlarge the distance between image representations of confusing classes. The proposed framework achieves the top2 on the CVPR2022 Biometrics Workshop Pet Biometric Challenge. The source code and trained models are publicly available at: https://github.com/flyingsheepbin/pet-biometrics