 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
StruBERT: Structure-aware BERT for Table Search and Matching
Mar 27, 2022
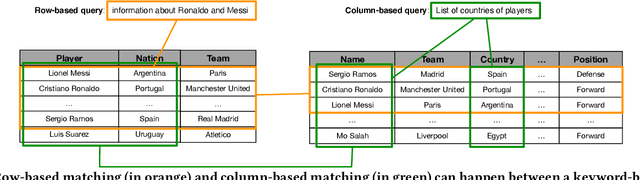
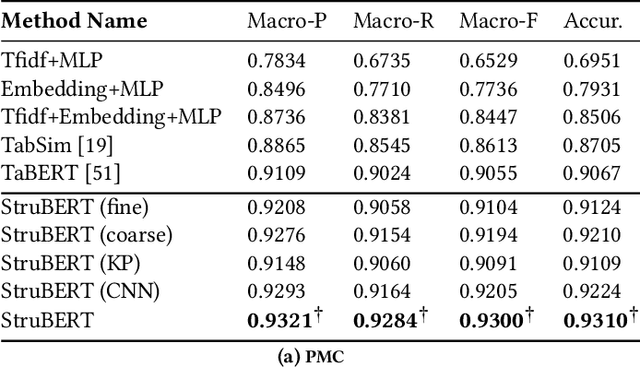
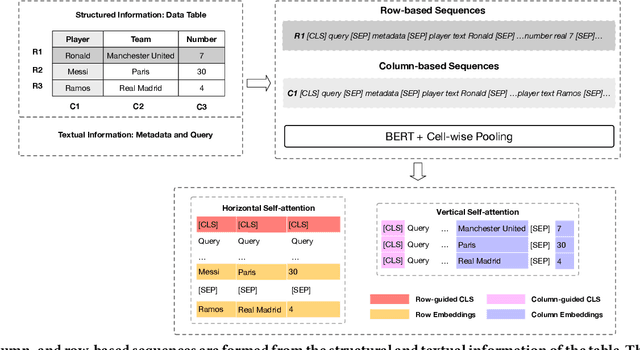
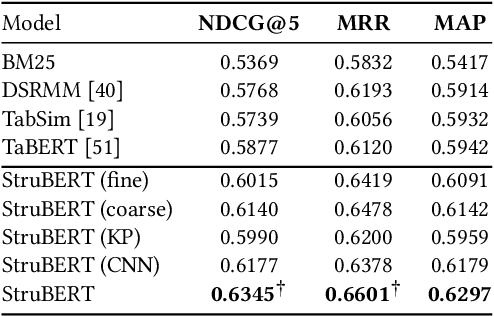
A large amount of information is stored in data tables. Users can search for data tables using a keyword-based query. A table is composed primarily of data values that are organized in rows and columns providing implicit structural information. A table is usually accompanied by secondary information such as the caption, page title, etc., that form the textual information. Understanding the connection between the textual and structural information is an important yet neglected aspect in table retrieval as previous methods treat each source of information independently. In addition, users can search for data tables that are similar to an existing table, and this setting can be seen as a content-based table retrieval. In this paper, we propose StruBERT, a structure-aware BERT model that fuses the textual and structural information of a data table to produce context-aware representations for both textual and tabular content of a data table. StruBERT features are integrated in a new end-to-end neural ranking model to solve three table-related downstream tasks: keyword- and content-based table retrieval, and table similarity. We evaluate our approach using three datasets, and we demonstrate substantial improvements in terms of retrieval and classification metrics over state-of-the-art methods.
Learning to Refactor Action and Co-occurrence Features for Temporal Action Localization
Jun 23, 2022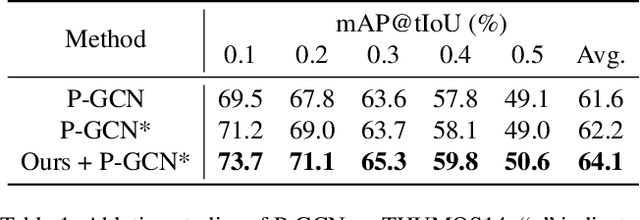
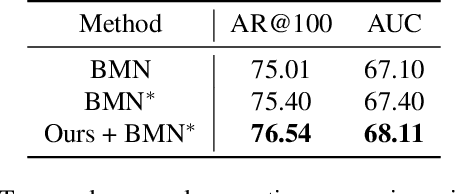
The main challenge of Temporal Action Localization is to retrieve subtle human actions from various co-occurring ingredients, e.g., context and background, in an untrimmed video. While prior approaches have achieved substantial progress through devising advanced action detectors, they still suffer from these co-occurring ingredients which often dominate the actual action content in videos. In this paper, we explore two orthogonal but complementary aspects of a video snippet, i.e., the action features and the co-occurrence features. Especially, we develop a novel auxiliary task by decoupling these two types of features within a video snippet and recombining them to generate a new feature representation with more salient action information for accurate action localization. We term our method RefactorNet, which first explicitly factorizes the action content and regularizes its co-occurrence features, and then synthesizes a new action-dominated video representation. Extensive experimental results and ablation studies on THUMOS14 and ActivityNet v1.3 demonstrate that our new representation, combined with a simple action detector, can significantly improve the action localization performance.
Benchmarking the Robustness of LiDAR-Camera Fusion for 3D Object Detection
May 30, 2022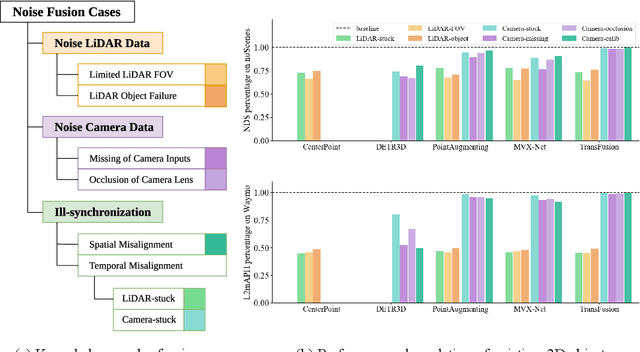
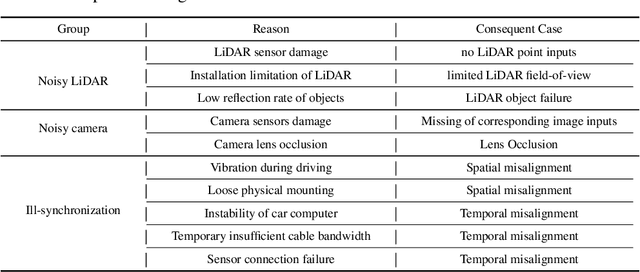
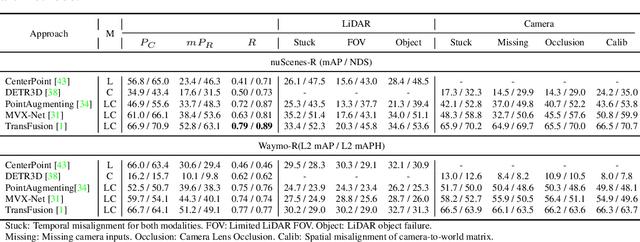
There are two critical sensors for 3D perception in autonomous driving, the camera and the LiDAR. The camera provides rich semantic information such as color, texture, and the LiDAR reflects the 3D shape and locations of surrounding objects. People discover that fusing these two modalities can significantly boost the performance of 3D perception models as each modality has complementary information to the other. However, we observe that current datasets are captured from expensive vehicles that are explicitly designed for data collection purposes, and cannot truly reflect the realistic data distribution due to various reasons. To this end, we collect a series of real-world cases with noisy data distribution, and systematically formulate a robustness benchmark toolkit, that simulates these cases on any clean autonomous driving datasets. We showcase the effectiveness of our toolkit by establishing the robustness benchmark on two widely-adopted autonomous driving datasets, nuScenes and Waymo, then, to the best of our knowledge, holistically benchmark the state-of-the-art fusion methods for the first time. We observe that: i) most fusion methods, when solely developed on these data, tend to fail inevitably when there is a disruption to the LiDAR input; ii) the improvement of the camera input is significantly inferior to the LiDAR one. We further propose an efficient robust training strategy to improve the robustness of the current fusion method. The benchmark and code are available at https://github.com/kcyu2014/lidar-camera-robust-benchmark
Propagation with Adaptive Mask then Training for Node Classification on Attributed Networks
Jun 23, 2022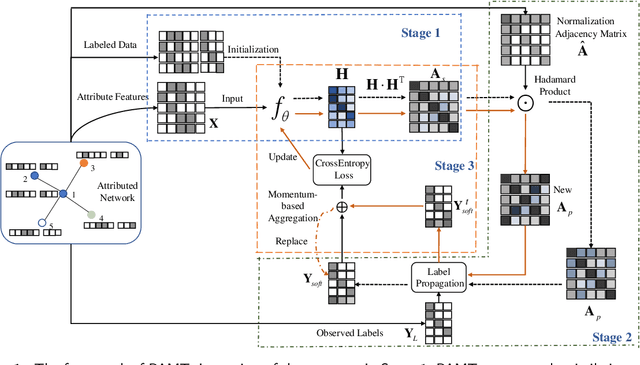
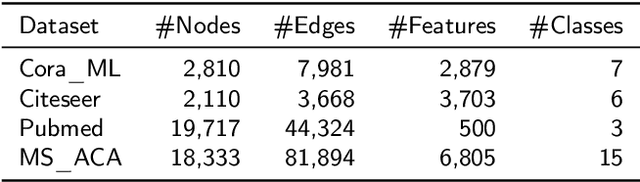
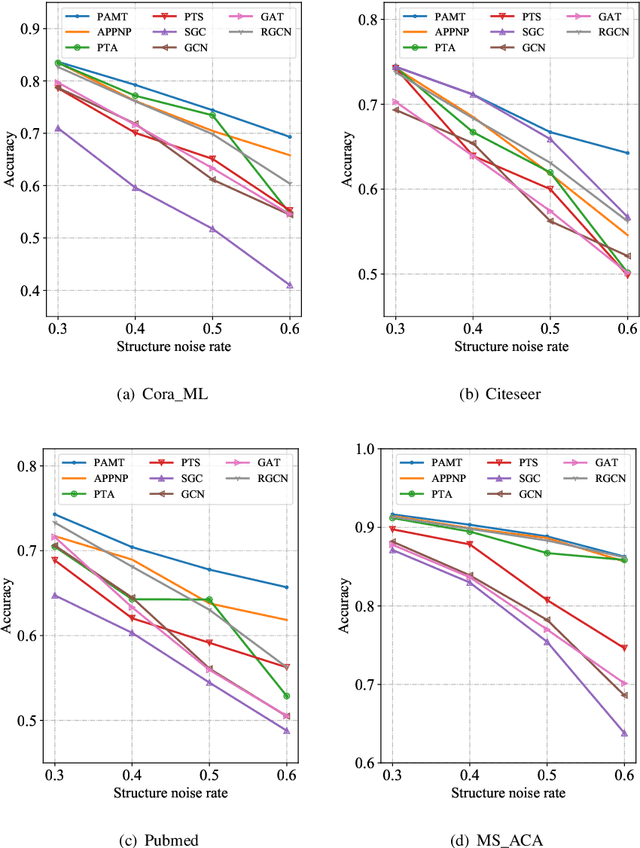
Node classification on attributed networks is a semi-supervised task that is crucial for network analysis. By decoupling two critical operations in Graph Convolutional Networks (GCNs), namely feature transformation and neighborhood aggregation, some recent works of decoupled GCNs could support the information to propagate deeper and achieve advanced performance. However, they follow the traditional structure-aware propagation strategy of GCNs, making it hard to capture the attribute correlation of nodes and sensitive to the structure noise described by edges whose two endpoints belong to different categories. To address these issues, we propose a new method called the itshape Propagation with Adaptive Mask then Training (PAMT). The key idea is to integrate the attribute similarity mask into the structure-aware propagation process. In this way, PAMT could preserve the attribute correlation of adjacent nodes during the propagation and effectively reduce the influence of structure noise. Moreover, we develop an iterative refinement mechanism to update the similarity mask during the training process for improving the training performance. Extensive experiments on four real-world datasets demonstrate the superior performance and robustness of PAMT.
Improving Item Cold-start Recommendation via Model-agnostic Conditional Variational Autoencoder
May 27, 2022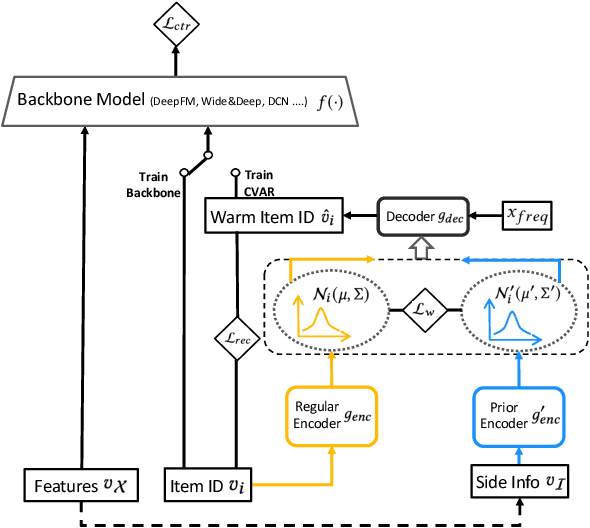
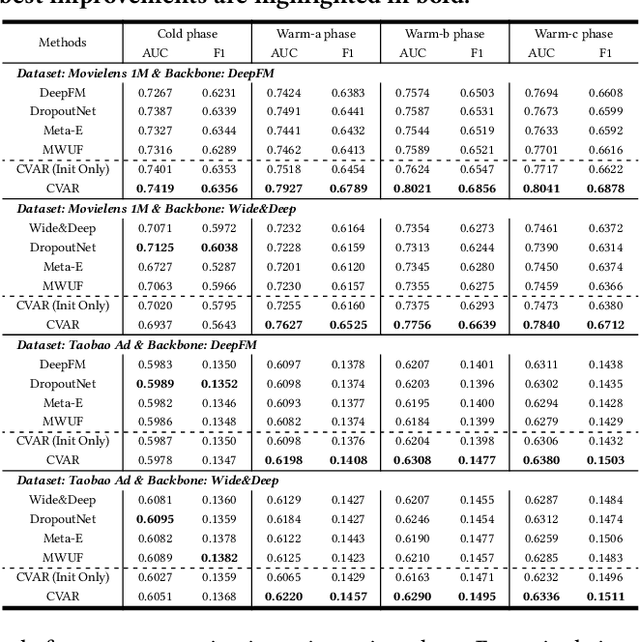
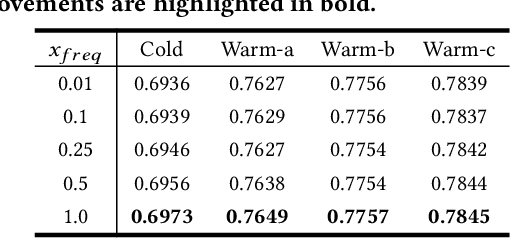
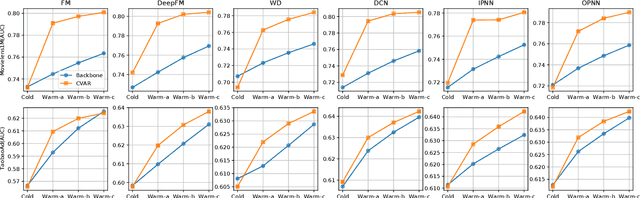
Embedding & MLP has become a paradigm for modern large-scale recommendation system. However, this paradigm suffers from the cold-start problem which will seriously compromise the ecological health of recommendation systems. This paper attempts to tackle the item cold-start problem by generating enhanced warmed-up ID embeddings for cold items with historical data and limited interaction records. From the aspect of industrial practice, we mainly focus on the following three points of item cold-start: 1) How to conduct cold-start without additional data requirements and make strategy easy to be deployed in online recommendation scenarios. 2) How to leverage both historical records and constantly emerging interaction data of new items. 3) How to model the relationship between item ID and side information stably from interaction data. To address these problems, we propose a model-agnostic Conditional Variational Autoencoder based Recommendation(CVAR) framework with some advantages including compatibility on various backbones, no extra requirements for data, utilization of both historical data and recent emerging interactions. CVAR uses latent variables to learn a distribution over item side information and generates desirable item ID embeddings using a conditional decoder. The proposed method is evaluated by extensive offline experiments on public datasets and online A/B tests on Tencent News recommendation platform, which further illustrate the advantages and robustness of CVAR.
Adversarial Filtering Modeling on Long-term User Behavior Sequences for Click-Through Rate Prediction
Apr 26, 2022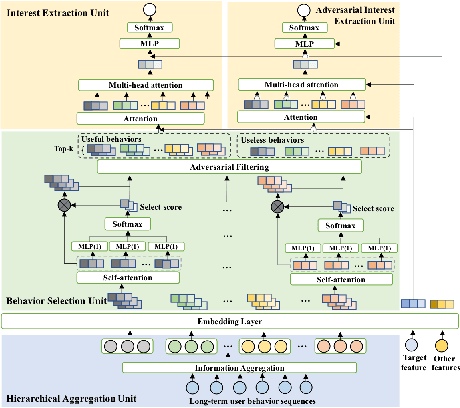
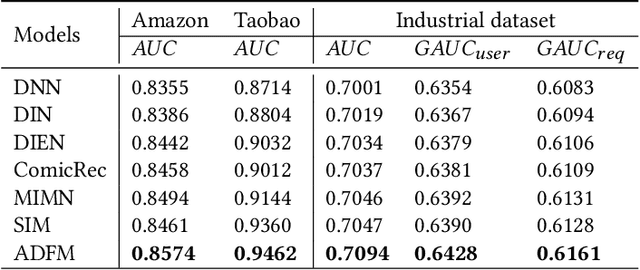

Rich user behavior information is of great importance for capturing and understanding user interest in click-through rate (CTR) prediction. To improve the richness, collecting long-term behaviors becomes a typical approach in academy and industry but at the cost of increasing online storage and latency. Recently, researchers have proposed several approaches to shorten long-term behavior sequence and then model user interests. These approaches reduce online cost efficiently but do not well handle the noisy information in long-term user behavior, which may deteriorate the performance of CTR prediction significantly. To obtain better cost/performance trade-off, we propose a novel Adversarial Filtering Model (ADFM) to model long-term user behavior. ADFM uses a hierarchical aggregation representation to compress raw behavior sequence and then learns to remove useless behavior information with an adversarial filtering mechanism. The selected user behaviors are fed into interest extraction module for CTR prediction. Experimental results on public datasets and industrial dataset demonstrate that our method achieves significant improvements over state-of-the-art models.
Channel Estimation for Delay Alignment Modulation
Jun 19, 2022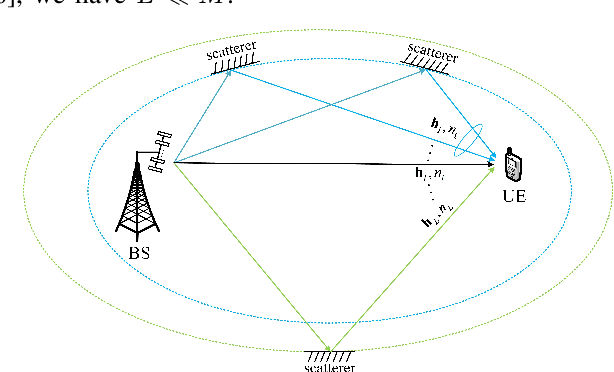
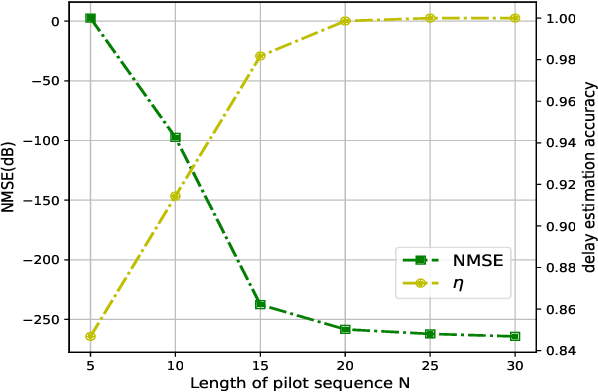
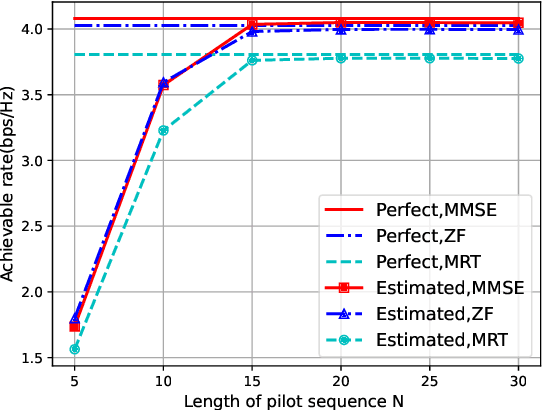
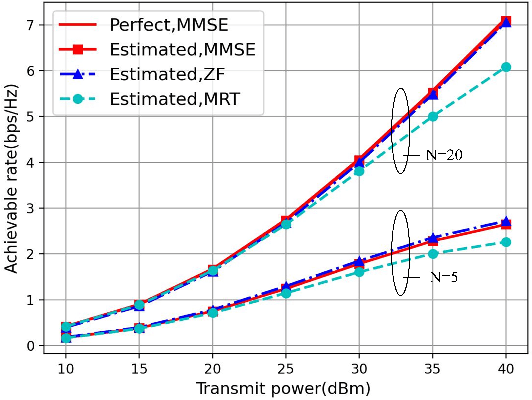
Delay alignment modulation (DAM) is a promising technology to eliminate inter-symbol interference (ISI) without relying on sophisticated equalization or multi-carrier transmissions. The key ideas of DAM are delay pre-compensation and path based beamforming, so that the multi-path signal components will arrive at the receiver simultaneously and constructively, rather than causing the detrimental ISI. However, the practical implementation of DAM requires channel state information (CSI) at the transmitter side. Therefore, in this letter, we propose an efficient channel estimation method for DAM based on block orthogonal matching pursuit (BOMP) algorithm, by exploiting the block sparsity of the channel impulse response (CIR) vector. Based on the imperfectly estimated CSI, the delay pre-compensations and path-based beamforming are designed for DAM, and the resulting performance is studied. Simulation results demonstrate that with the proposed channel estimation method, the CSI can be effectively acquired with low training overhead, and the performance of DAM based on estimated CSI is comparable to the ideal case with perfect CSI.
Entropy-driven Sampling and Training Scheme for Conditional Diffusion Generation
Jun 23, 2022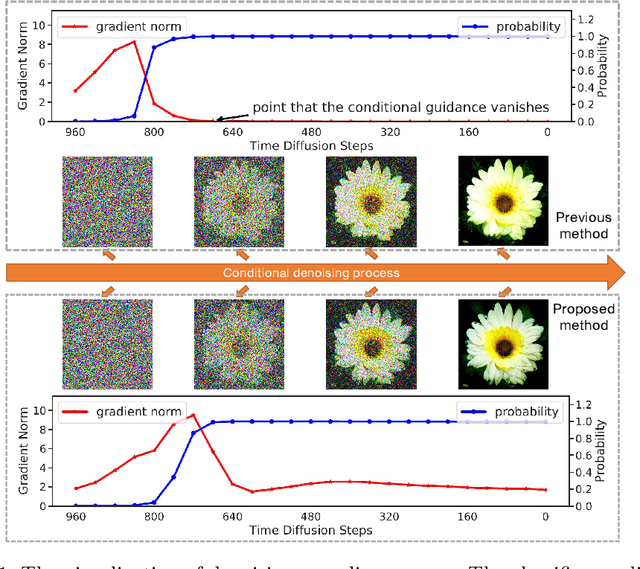
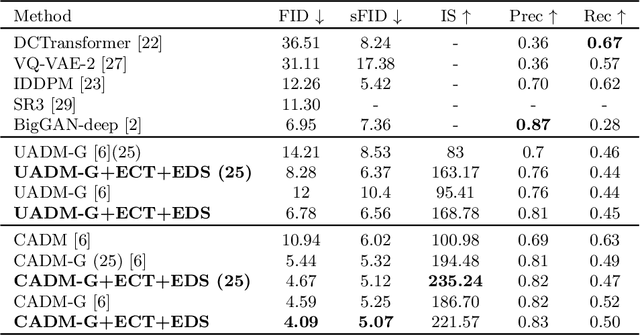
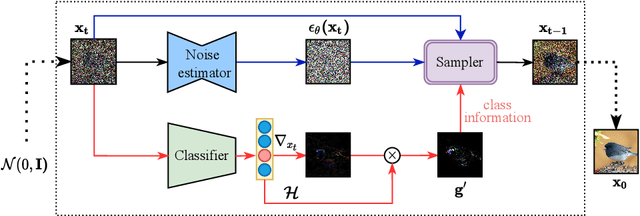
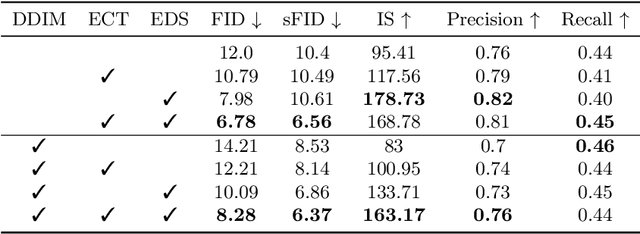
Denoising Diffusion Probabilistic Model (DDPM) is able to make flexible conditional image generation from prior noise to real data, by introducing an independent noise-aware classifier to provide conditional gradient guidance at each time step of denoising process. However, due to the ability of classifier to easily discriminate an incompletely generated image only with high-level structure, the gradient, which is a kind of class information guidance, tends to vanish early, leading to the collapse from conditional generation process into the unconditional process. To address this problem, we propose two simple but effective approaches from two perspectives. For sampling procedure, we introduce the entropy of predicted distribution as the measure of guidance vanishing level and propose an entropy-aware scaling method to adaptively recover the conditional semantic guidance. % for each generated sample. For training stage, we propose the entropy-aware optimization objectives to alleviate the overconfident prediction for noisy data.On ImageNet1000 256x256, with our proposed sampling scheme and trained classifier, the pretrained conditional and unconditional DDPM model can achieve 10.89% (4.59 to 4.09) and 43.5% (12 to 6.78) FID improvement respectively.
Group privacy for personalized federated learning
Jun 07, 2022
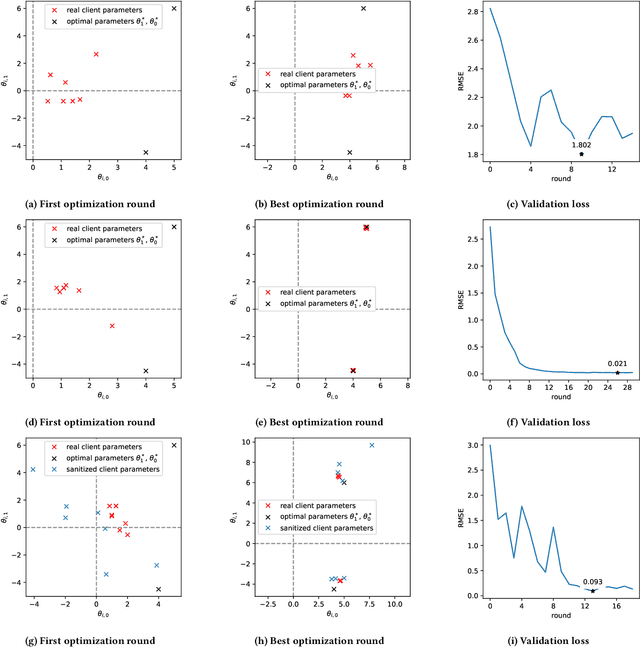
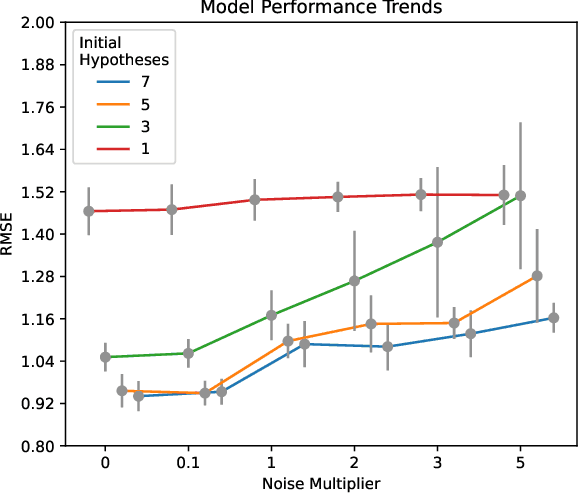
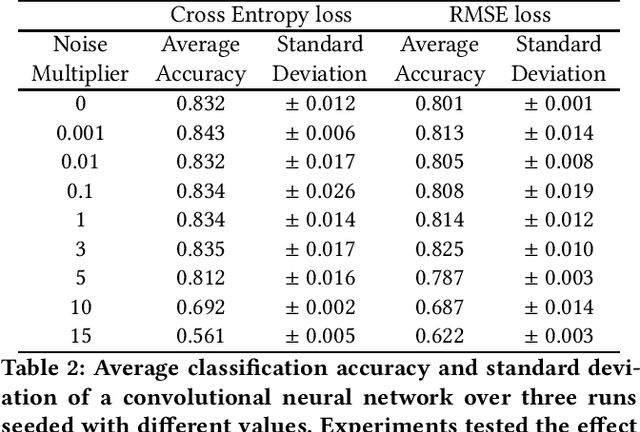
Federated learning is a type of collaborative machine learning, where participating clients process their data locally, sharing only updates to the collaborative model. This enables to build privacy-aware distributed machine learning models, among others. The goal is the optimization of a statistical model's parameters by minimizing a cost function of a collection of datasets which are stored locally by a set of clients. This process exposes the clients to two issues: leakage of private information and lack of personalization of the model. On the other hand, with the recent advancements in techniques to analyze data, there is a surge of concern for the privacy violation of the participating clients. To mitigate this, differential privacy and its variants serve as a standard for providing formal privacy guarantees. Often the clients represent very heterogeneous communities and hold data which are very diverse. Therefore, aligned with the recent focus of the FL community to build a framework of personalized models for the users representing their diversity, it is also of utmost importance to protect against potential threats against the sensitive and personal information of the clients. $d$-privacy, which is a generalization of geo-indistinguishability, the lately popularized paradigm of location privacy, uses a metric-based obfuscation technique that preserves the spatial distribution of the original data. To address the issue of protecting the privacy of the clients and allowing for personalized model training to enhance the fairness and utility of the system, we propose a method to provide group privacy guarantees exploiting some key properties of $d$-privacy which enables personalized models under the framework of FL. We provide with theoretical justifications to the applicability and experimental validation on real-world datasets to illustrate the working of the proposed method.
A Comparative Study of Meter Detection Methods for Automated Infrastructure Inspection
Apr 24, 2022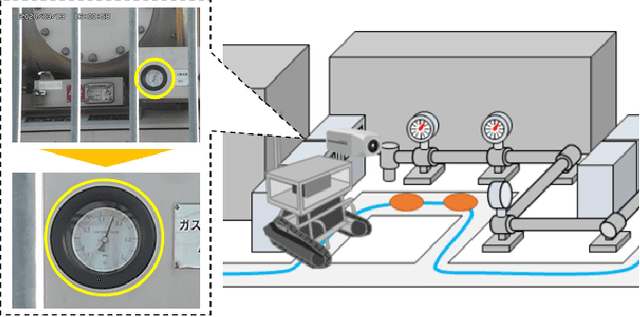

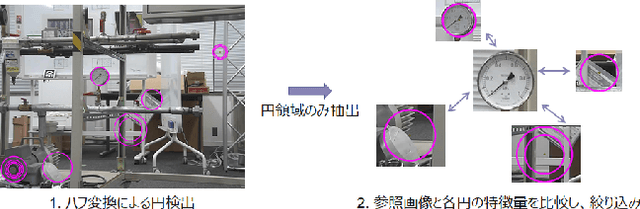
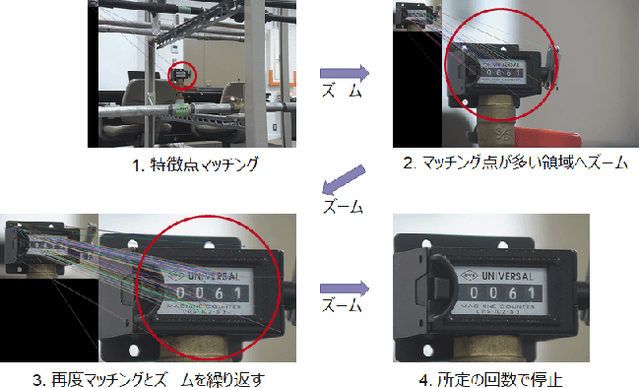
In order to read meter values from a camera on an autonomous inspection robot with positional errors, it is necessary to detect meter regions from the image. In this study, we developed shape-based, texture-based, and background information-based methods as meter area detection techniques and compared their effectiveness for meters of different shapes and sizes. As a result, we confirmed that the background information-based method can detect the farthest meters regardless of the shape and number of meters, and can stably detect meters with a diameter of 40px.