 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Spike Depth Estimation via Cross-modality Cross-domain Knowledge Transfer
Aug 26, 2022
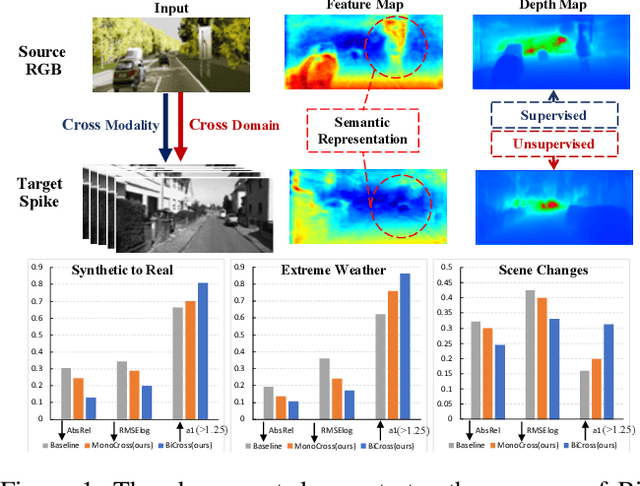

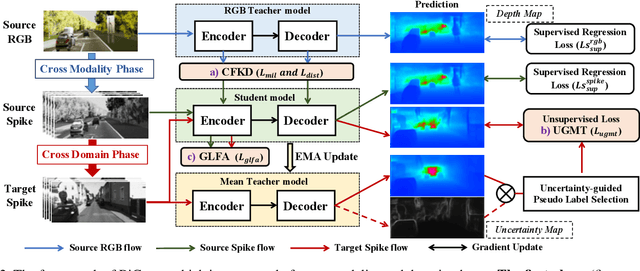
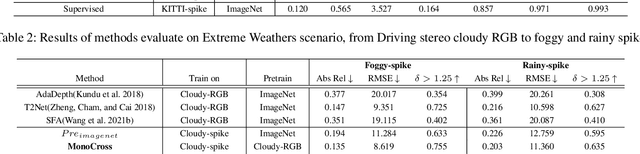
The neuromorphic spike camera generates data streams with high temporal resolution in a bio-inspired way, which has vast potential in the real-world applications such as autonomous driving. In contrast to RGB streams, spike streams have an inherent advantage to overcome motion blur, leading to more accurate depth estimation for high-velocity objects. However, training the spike depth estimation network in a supervised manner is almost impossible since it is extremely laborious and challenging to obtain paired depth labels for temporally intensive spike streams. In this paper, instead of building a spike stream dataset with full depth labels, we transfer knowledge from the open-source RGB datasets (e.g., KITTI) and estimate spike depth in an unsupervised manner. The key challenges for such problem lie in the modality gap between RGB and spike modalities, and the domain gap between labeled source RGB and unlabeled target spike domains. To overcome these challenges, we introduce a cross-modality cross-domain (BiCross) framework for unsupervised spike depth estimation. Our method narrows the enormous gap between source RGB and target spike by introducing the mediate simulated source spike domain. To be specific, for the cross-modality phase, we propose a novel Coarse-to-Fine Knowledge Distillation (CFKD), which transfers the image and pixel level knowledge from source RGB to source spike. Such design leverages the abundant semantic and dense temporal information of RGB and spike modalities respectively. For the cross-domain phase, we introduce the Uncertainty Guided Mean-Teacher (UGMT) to generate reliable pseudo labels with uncertainty estimation, alleviating the shift between the source spike and target spike domains. Besides, we propose a Global-Level Feature Alignment method (GLFA) to align the feature between two domains and generate more reliable pseudo labels.
Rapid Flow Behavior Modeling of Thermal Interface Materials Using Deep Neural Networks
Aug 08, 2022


Thermal Interface Materials (TIMs) are widely used in electronic packaging. Increasing power density and limited assembly space pose high demands on thermal management. Large cooling surfaces need to be covered efficiently. When joining the heatsink, previously dispensed TIM spreads over the cooling surface. Recommendations on the dispensing pattern exist only for simple surface geometries such as rectangles. For more complex geometries, Computational Fluid Dynamics (CFD) simulations are used in combination with manual experiments. While CFD simulations offer a high accuracy, they involve simulation experts and are rather expensive to set up. We propose a lightweight heuristic to model the spreading behavior of TIM. We further speed up the calculation by training an Artificial Neural Network (ANN) on data from this model. This offers rapid computation times and further supplies gradient information. This ANN can not only be used to aid manual pattern design of TIM, but also enables an automated pattern optimization. We compare this approach against the state-of-the-art and use real product samples for validation.
Self-supervised speech unit discovery from articulatory and acoustic features using VQ-VAE
Jun 17, 2022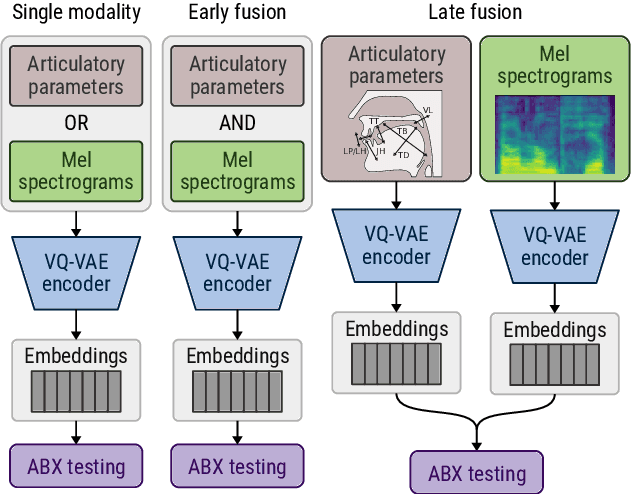
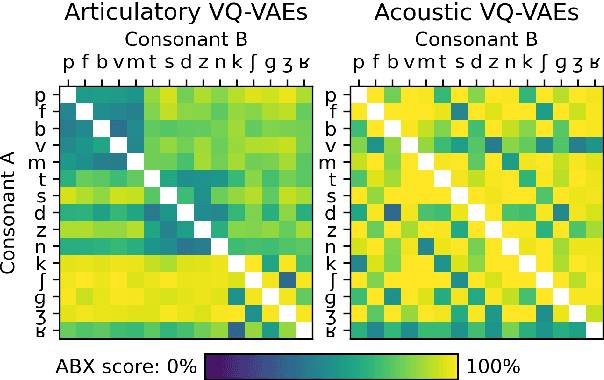
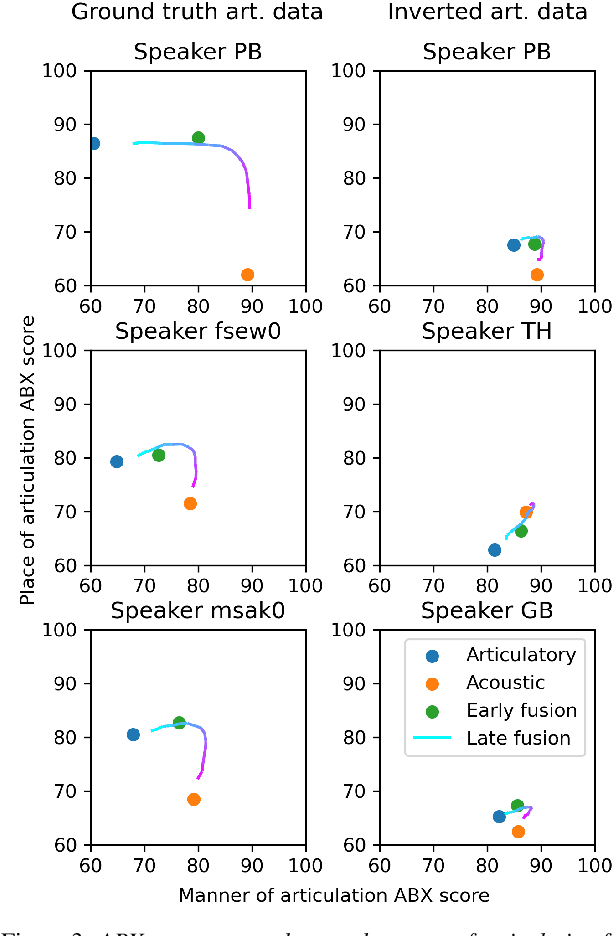
The human perception system is often assumed to recruit motor knowledge when processing auditory speech inputs. Using articulatory modeling and deep learning, this study examines how this articulatory information can be used for discovering speech units in a self-supervised setting. We used vector-quantized variational autoencoders (VQ-VAE) to learn discrete representations from articulatory and acoustic speech data. In line with the zero-resource paradigm, an ABX test was then used to investigate how the extracted representations encode phonetically relevant properties. Experiments were conducted on three different corpora in English and French. We found that articulatory information rather organises the latent representations in terms of place of articulation whereas the speech acoustics mainly structure the latent space in terms of manner of articulation. We show that an optimal fusion of the two modalities can lead to a joint representation of these phonetic dimensions more accurate than each modality considered individually. Since articulatory information is usually not available in a practical situation, we finally investigate the benefit it provides when inferred from the speech acoustics in a self-supervised manner.
Wasserstein Graph Distance based on $L_1$-Approximated Tree Edit Distance between Weisfeiler-Lehman Subtrees
Jul 09, 2022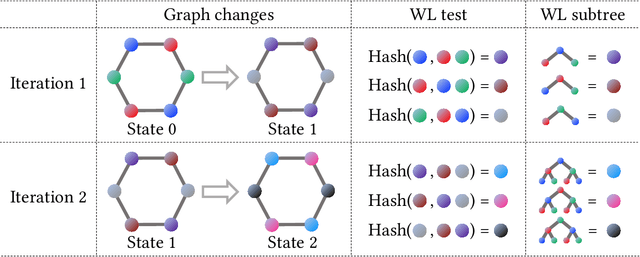
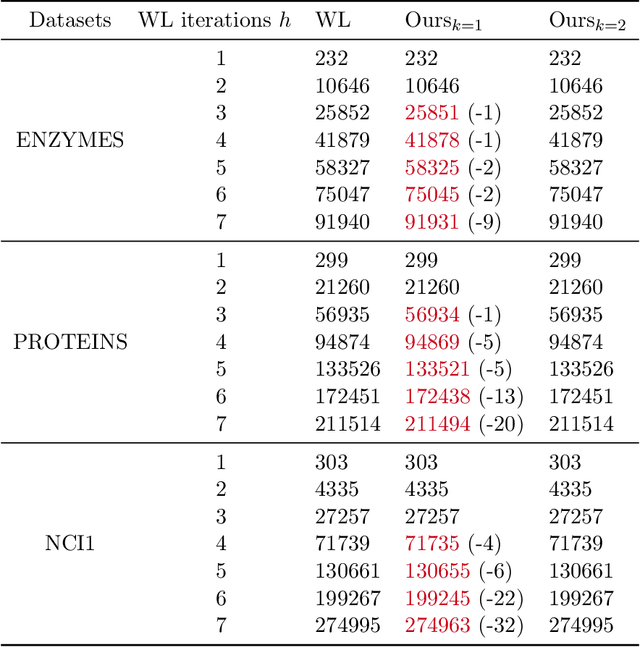
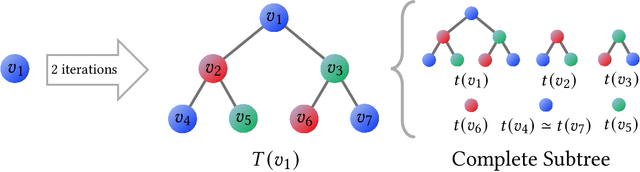
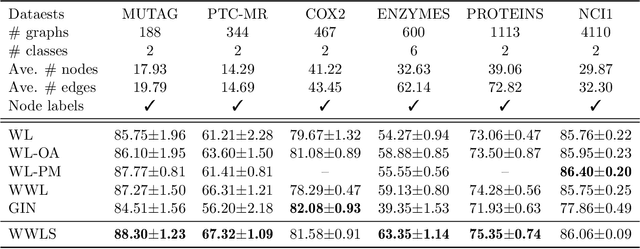
The Weisfeiler-Lehman (WL) test has been widely applied to graph kernels, metrics, and neural networks. However, it considers only the graph consistency, resulting in the weak descriptive power of structural information. Thus, it limits the performance improvement of applied methods. In addition, the similarity and distance between graphs defined by the WL test are in coarse measurements. To the best of our knowledge, this paper clarifies these facts for the first time and defines a metric we call the Wasserstein WL subtree (WWLS) distance. We introduce the WL subtree as the structural information in the neighborhood of nodes and assign it to each node. Then we define a new graph embedding space based on $L_1$-approximated tree edit distance ($L_1$-TED): the $L_1$ norm of the difference between node feature vectors on the space is the $L_1$-TED between these nodes. We further propose a fast algorithm for graph embedding. Finally, we use the Wasserstein distance to reflect the $L_1$-TED to the graph level. The WWLS can capture small changes in structure that are difficult with traditional metrics. We demonstrate its performance in several graph classification and metric validation experiments.
Locality Guidance for Improving Vision Transformers on Tiny Datasets
Jul 20, 2022
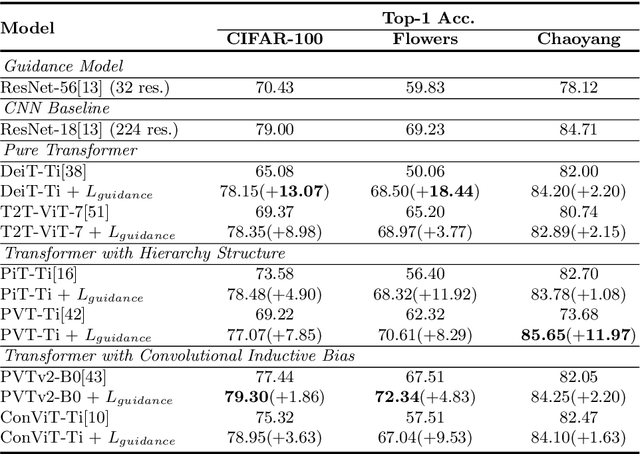
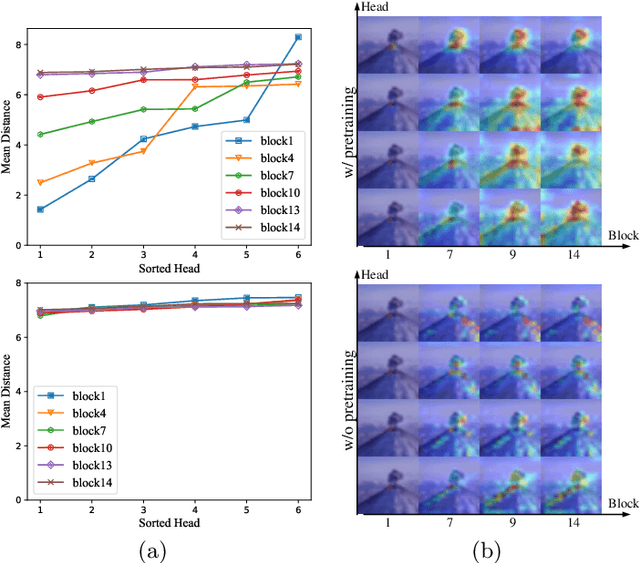
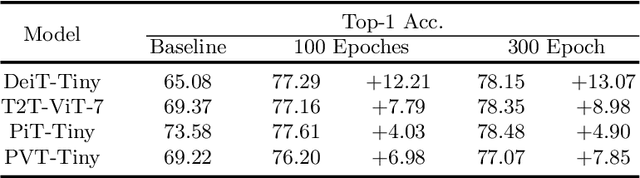
While the Vision Transformer (VT) architecture is becoming trendy in computer vision, pure VT models perform poorly on tiny datasets. To address this issue, this paper proposes the locality guidance for improving the performance of VTs on tiny datasets. We first analyze that the local information, which is of great importance for understanding images, is hard to be learned with limited data due to the high flexibility and intrinsic globality of the self-attention mechanism in VTs. To facilitate local information, we realize the locality guidance for VTs by imitating the features of an already trained convolutional neural network (CNN), inspired by the built-in local-to-global hierarchy of CNN. Under our dual-task learning paradigm, the locality guidance provided by a lightweight CNN trained on low-resolution images is adequate to accelerate the convergence and improve the performance of VTs to a large extent. Therefore, our locality guidance approach is very simple and efficient, and can serve as a basic performance enhancement method for VTs on tiny datasets. Extensive experiments demonstrate that our method can significantly improve VTs when training from scratch on tiny datasets and is compatible with different kinds of VTs and datasets. For example, our proposed method can boost the performance of various VTs on tiny datasets (e.g., 13.07% for DeiT, 8.98% for T2T and 7.85% for PVT), and enhance even stronger baseline PVTv2 by 1.86% to 79.30%, showing the potential of VTs on tiny datasets. The code is available at https://github.com/lkhl/tiny-transformers.
Information Theory in Density Destructors
Dec 02, 2020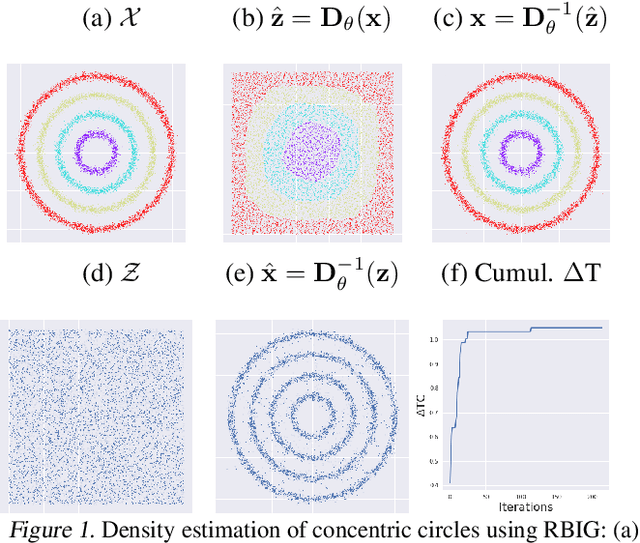
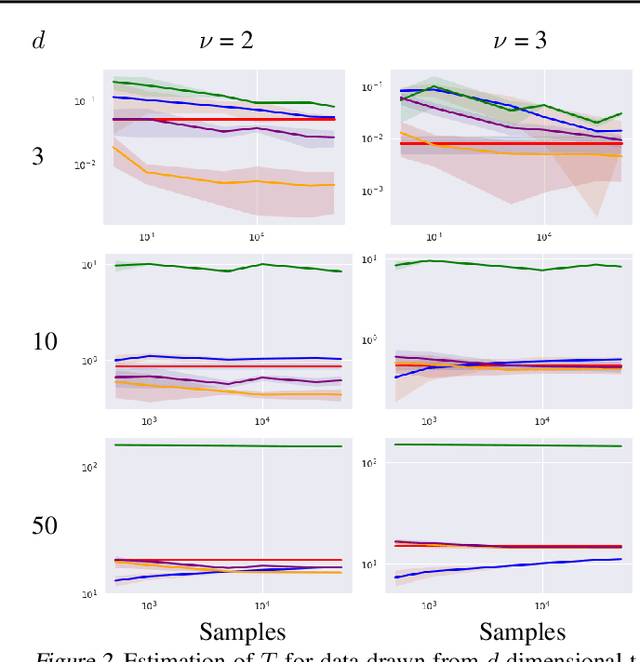
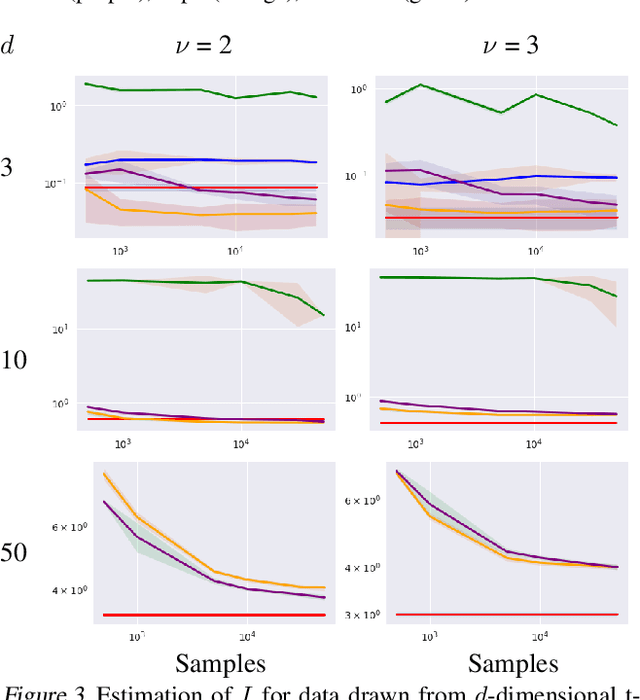
Density destructors are differentiable and invertible transforms that map multivariate PDFs of arbitrary structure (low entropy) into non-structured PDFs (maximum entropy). Multivariate Gaussianization and multivariate equalization are specific examples of this family, which break down the complexity of the original PDF through a set of elementary transforms that progressively remove the structure of the data. We demonstrate how this property of density destructive flows is connected to classical information theory, and how density destructors can be used to get more accurate estimates of information theoretic quantities. Experiments with total correlation and mutual information inmultivariate sets illustrate the ability of density destructors compared to competing methods. These results suggest that information theoretic measures may be an alternative optimization criteria when learning density destructive flows.
A Real-time Edge-AI System for Reef Surveys
Aug 01, 2022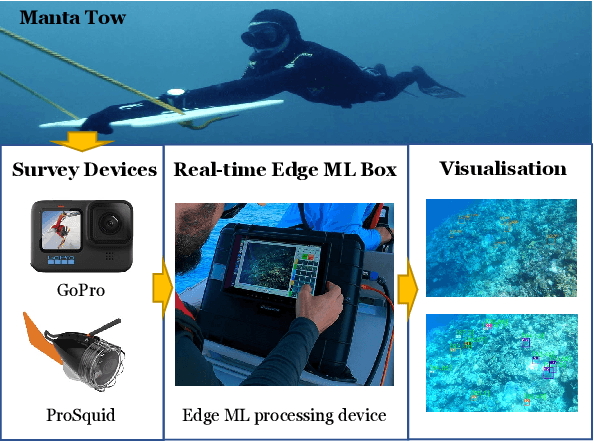
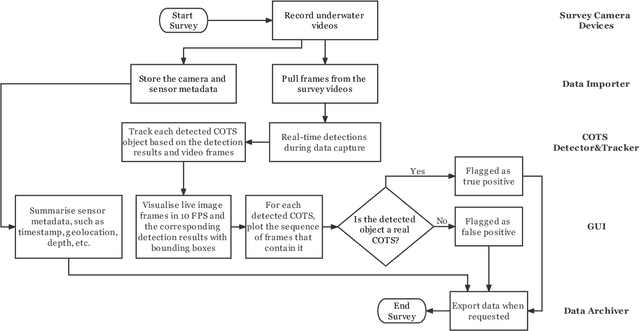
Crown-of-Thorn Starfish (COTS) outbreaks are a major cause of coral loss on the Great Barrier Reef (GBR) and substantial surveillance and control programs are ongoing to manage COTS populations to ecologically sustainable levels. In this paper, we present a comprehensive real-time machine learning-based underwater data collection and curation system on edge devices for COTS monitoring. In particular, we leverage the power of deep learning-based object detection techniques, and propose a resource-efficient COTS detector that performs detection inferences on the edge device to assist marine experts with COTS identification during the data collection phase. The preliminary results show that several strategies for improving computational efficiency (e.g., batch-wise processing, frame skipping, model input size) can be combined to run the proposed detection model on edge hardware with low resource consumption and low information loss.
Dual-path Attention is All You Need for Audio-Visual Speech Extraction
Jul 09, 2022
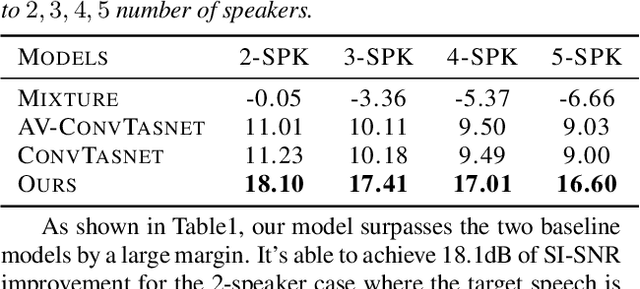
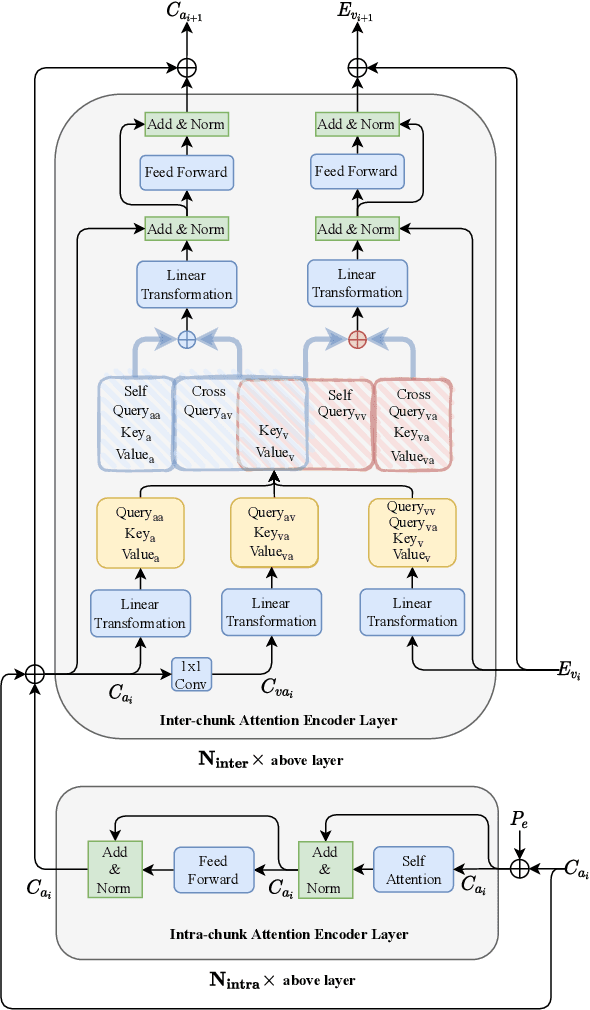
Audio-visual target speech extraction, which aims to extract a certain speaker's speech from the noisy mixture by looking at lip movements, has made significant progress combining time-domain speech separation models and visual feature extractors (CNN). One problem of fusing audio and video information is that they have different time resolutions. Most current research upsamples the visual features along the time dimension so that audio and video features are able to align in time. However, we believe that lip movement should mostly contain long-term, or phone-level information. Based on this assumption, we propose a new way to fuse audio-visual features. We observe that for DPRNN \cite{dprnn}, the interchunk dimension's time resolution could be very close to the time resolution of video frames. Like \cite{sepformer}, the LSTM in DPRNN is replaced by intra-chunk and inter-chunk self-attention, but in the proposed algorithm, inter-chunk attention incorporates the visual features as an additional feature stream. This prevents the upsampling of visual cues, resulting in more efficient audio-visual fusion. The result shows we achieve superior results compared with other time-domain based audio-visual fusion models.
Topical: Learning Repository Embeddings from Source Code using Attention
Aug 19, 2022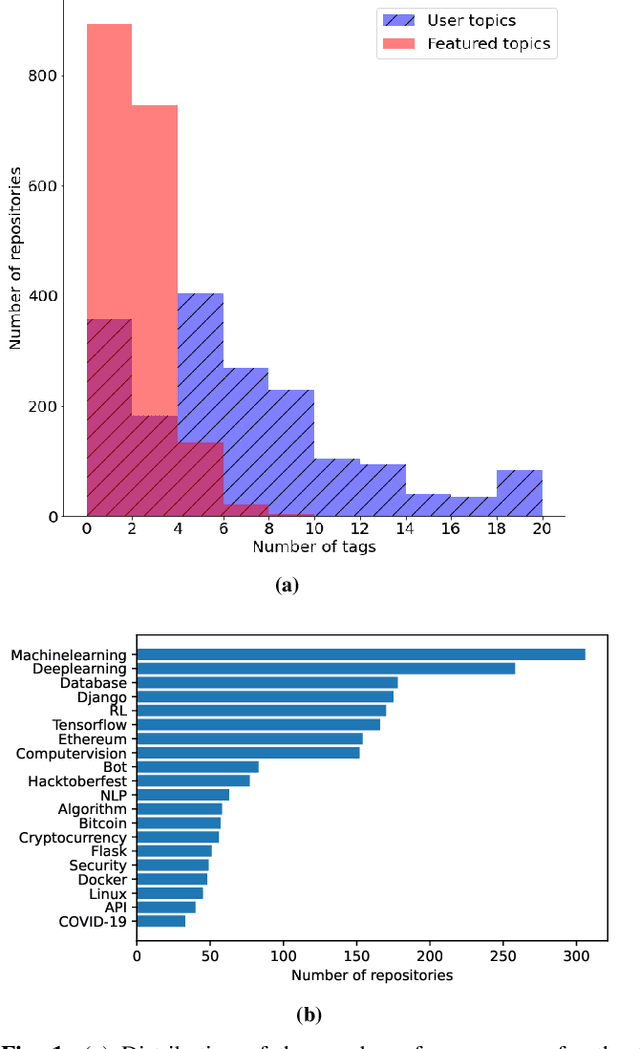
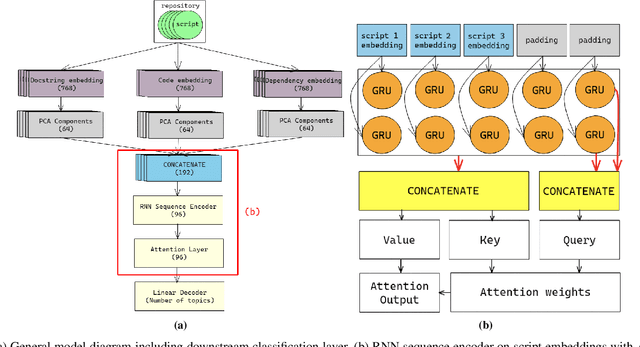

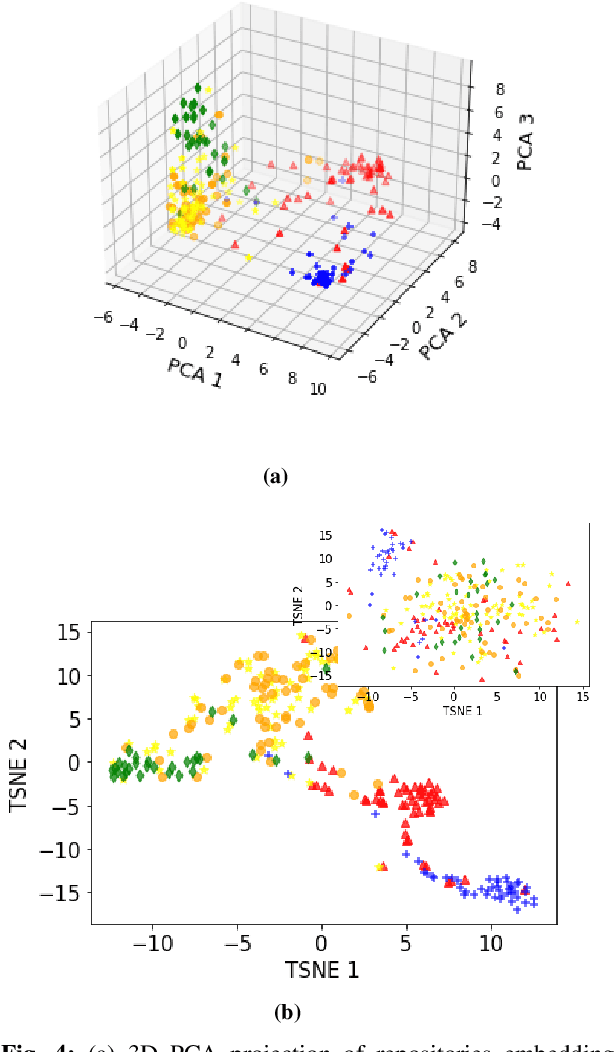
Machine learning on source code (MLOnCode) promises to transform how software is delivered. By mining the context and relationship between software artefacts, MLOnCode augments the software developers capabilities with code auto-generation, code recommendation, code auto-tagging and other data-driven enhancements. For many of these tasks a script level representation of code is sufficient, however, in many cases a repository level representation that takes into account various dependencies and repository structure is imperative, for example, auto-tagging repositories with topics or auto-documentation of repository code etc. Existing methods for computing repository level representations suffer from (a) reliance on natural language documentation of code (for example, README files) (b) naive aggregation of method/script-level representation, for example, by concatenation or averaging. This paper introduces Topical a deep neural network to generate repository level embeddings of publicly available GitHub code repositories directly from source code. Topical incorporates an attention mechanism that projects the source code, the full dependency graph and the script level textual information into a dense repository-level representation. To compute the repository-level representations, Topical is trained to predict the topics associated with a repository, on a dataset of publicly available GitHub repositories that were crawled along with their ground truth topic tags. Our experiments show that the embeddings computed by Topical are able to outperform multiple baselines, including baselines that naively combine the method-level representations through averaging or concatenation at the task of repository auto-tagging.
Improved post-hoc probability calibration for out-of-domain MRI segmentation
Aug 04, 2022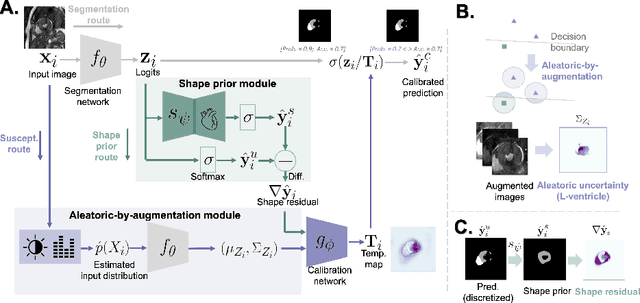
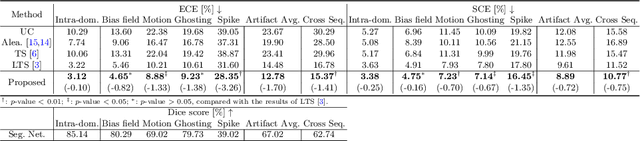

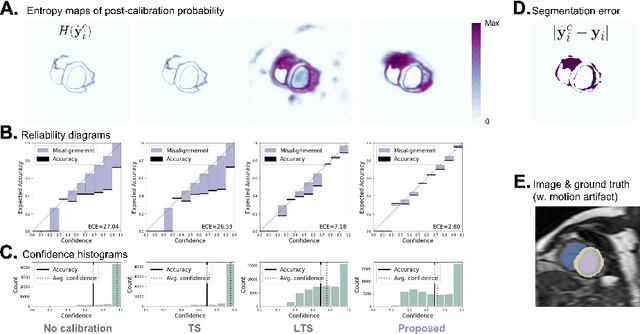
Probability calibration for deep models is highly desirable in safety-critical applications such as medical imaging. It makes output probabilities of deep networks interpretable, by aligning prediction probabilities with the actual accuracy in test data. In image segmentation, well-calibrated probabilities allow radiologists to identify regions where model-predicted segmentations are unreliable. These unreliable predictions often occur to out-of-domain (OOD) images that are caused by imaging artifacts or unseen imaging protocols. Unfortunately, most previous calibration methods for image segmentation perform sub-optimally on OOD images. To reduce the calibration error when confronted with OOD images, we propose a novel post-hoc calibration model. Our model leverages the pixel susceptibility against perturbations at the local level, and the shape prior information at the global level. The model is tested on cardiac MRI segmentation datasets that contain unseen imaging artifacts and images from an unseen imaging protocol. We demonstrate reduced calibration errors compared with the state-of-the-art calibration algorithm.