 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Tokens to Faces: Investigating Discrete Speech Representations for 3D Facial Animation
Jun 11, 2026The choice of speech representation is critical in speech-driven 3D facial animation. Representations differ in what they encode: SSL features emphasize segmental and semantic cues, neural codecs yield latents optimized for acoustic reconstruction, and ASR-style objectives produce label-based spaces. We evaluate four speech representation families for 3D facial synthesis, comparing their facial reconstruction quality across two facial decoders using objective metrics and a perceptual evaluation. We additionally conduct probing analyses that relate tokenized representations to phonetic units and to articulatory deformations. We found that encoding phonetic classes is beneficial for accurate facial animation prediction on both semantic and label-based representations with comparable facial animation quality. From the latter, we introduce an Audio Visual Text-to-Speech (AVTTS) pipeline that leverages, as a shared space, discrete representations to decode speech and 3D facial motion.
MauBERT: Universal Phonetic Inductive Biases for Few-Shot Acoustic Units Discovery
Dec 22, 2025This paper introduces MauBERT, a multilingual extension of HuBERT that leverages articulatory features for robust cross-lingual phonetic representation learning. We continue HuBERT pre-training with supervision based on a phonetic-to-articulatory feature mapping in 55 languages. Our models learn from multilingual data to predict articulatory features or phones, resulting in language-independent representations that capture multilingual phonetic properties. Through comprehensive ABX discriminability testing, we show MauBERT models produce more context-invariant representations than state-of-the-art multilingual self-supervised learning models. Additionally, the models effectively adapt to unseen languages and casual speech with minimal self-supervised fine-tuning (10 hours of speech). This establishes an effective approach for instilling linguistic inductive biases in self-supervised speech models.
Cued Speech Generation Leveraging a Pre-trained Audiovisual Text-to-Speech Model
Jan 08, 2025


This paper presents a novel approach for the automatic generation of Cued Speech (ACSG), a visual communication system used by people with hearing impairment to better elicit the spoken language. We explore transfer learning strategies by leveraging a pre-trained audiovisual autoregressive text-to-speech model (AVTacotron2). This model is reprogrammed to infer Cued Speech (CS) hand and lip movements from text input. Experiments are conducted on two publicly available datasets, including one recorded specifically for this study. Performance is assessed using an automatic CS recognition system. With a decoding accuracy at the phonetic level reaching approximately 77%, the results demonstrate the effectiveness of our approach.
Simulating Articulatory Trajectories with Phonological Feature Interpolation
Aug 08, 2024



As a first step towards a complete computational model of speech learning involving perception-production loops, we investigate the forward mapping between pseudo-motor commands and articulatory trajectories. Two phonological feature sets, based respectively on generative and articulatory phonology, are used to encode a phonetic target sequence. Different interpolation techniques are compared to generate smooth trajectories in these feature spaces, with a potential optimisation of the target value and timing to capture co-articulation effects. We report the Pearson correlation between a linear projection of the generated trajectories and articulatory data derived from a multi-speaker dataset of electromagnetic articulography (EMA) recordings. A correlation of 0.67 is obtained with an extended feature set based on generative phonology and a linear interpolation technique. We discuss the implications of our results for our understanding of the dynamics of biological motion.
Fill in the Gap! Combining Self-supervised Representation Learning with Neural Audio Synthesis for Speech Inpainting
May 30, 2024



Most speech self-supervised learning (SSL) models are trained with a pretext task which consists in predicting missing parts of the input signal, either future segments (causal prediction) or segments masked anywhere within the input (non-causal prediction). Learned speech representations can then be efficiently transferred to downstream tasks (e.g., automatic speech or speaker recognition). In the present study, we investigate the use of a speech SSL model for speech inpainting, that is reconstructing a missing portion of a speech signal from its surrounding context, i.e., fulfilling a downstream task that is very similar to the pretext task. To that purpose, we combine an SSL encoder, namely HuBERT, with a neural vocoder, namely HiFiGAN, playing the role of a decoder. In particular, we propose two solutions to match the HuBERT output with the HiFiGAN input, by freezing one and fine-tuning the other, and vice versa. Performance of both approaches was assessed in single- and multi-speaker settings, for both informed and blind inpainting configurations (i.e., the position of the mask is known or unknown, respectively), with different objective metrics and a perceptual evaluation. Performances show that if both solutions allow to correctly reconstruct signal portions up to the size of 200ms (and even 400ms in some cases), fine-tuning the SSL encoder provides a more accurate signal reconstruction in the single-speaker setting case, while freezing it (and training the neural vocoder instead) is a better strategy when dealing with multi-speaker data.
Investigating the dynamics of hand and lips in French Cued Speech using attention mechanisms and CTC-based decoding
Jun 14, 2023



Hard of hearing or profoundly deaf people make use of cued speech (CS) as a communication tool to understand spoken language. By delivering cues that are relevant to the phonetic information, CS offers a way to enhance lipreading. In literature, there have been several studies on the dynamics between the hand and the lips in the context of human production. This article proposes a way to investigate how a neural network learns this relation for a single speaker while performing a recognition task using attention mechanisms. Further, an analysis of the learnt dynamics is utilized to establish the relationship between the two modalities and extract automatic segments. For the purpose of this study, a new dataset has been recorded for French CS. Along with the release of this dataset, a benchmark will be reported for word-level recognition, a novelty in the automatic recognition of French CS.
BERT, can HE predict contrastive focus? Predicting and controlling prominence in neural TTS using a language model
Jul 04, 2022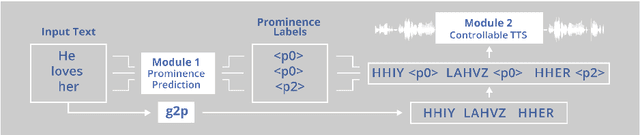

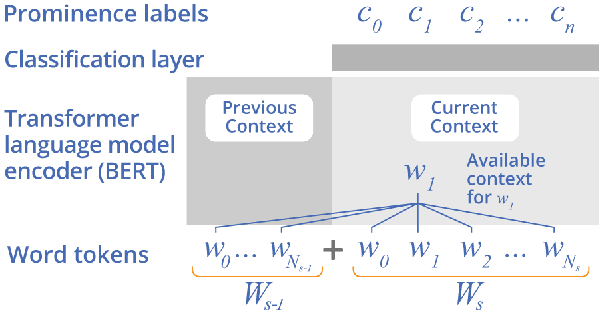
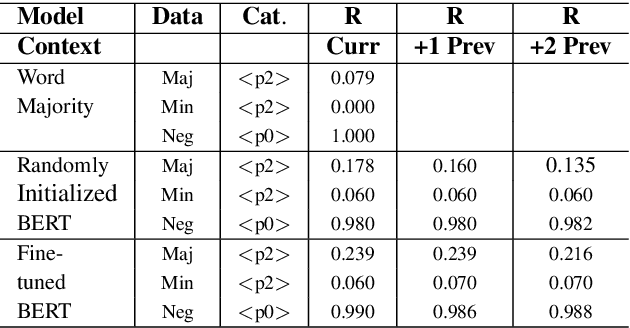
Several recent studies have tested the use of transformer language model representations to infer prosodic features for text-to-speech synthesis (TTS). While these studies have explored prosody in general, in this work, we look specifically at the prediction of contrastive focus on personal pronouns. This is a particularly challenging task as it often requires semantic, discursive and/or pragmatic knowledge to predict correctly. We collect a corpus of utterances containing contrastive focus and we evaluate the accuracy of a BERT model, finetuned to predict quantized acoustic prominence features, on these samples. We also investigate how past utterances can provide relevant information for this prediction. Furthermore, we evaluate the controllability of pronoun prominence in a TTS model conditioned on acoustic prominence features.
Self-supervised speech unit discovery from articulatory and acoustic features using VQ-VAE
Jun 17, 2022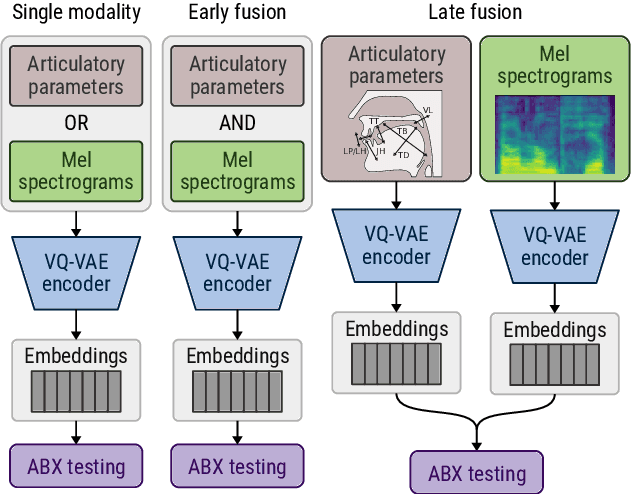
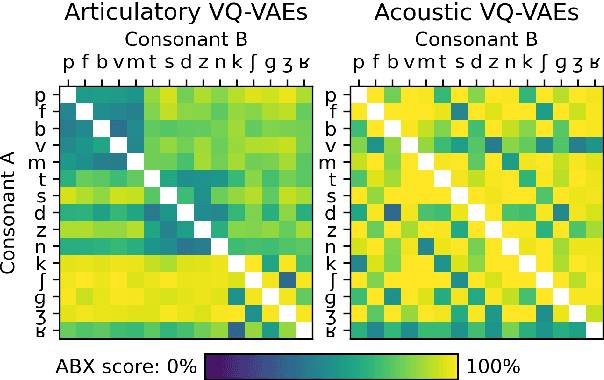
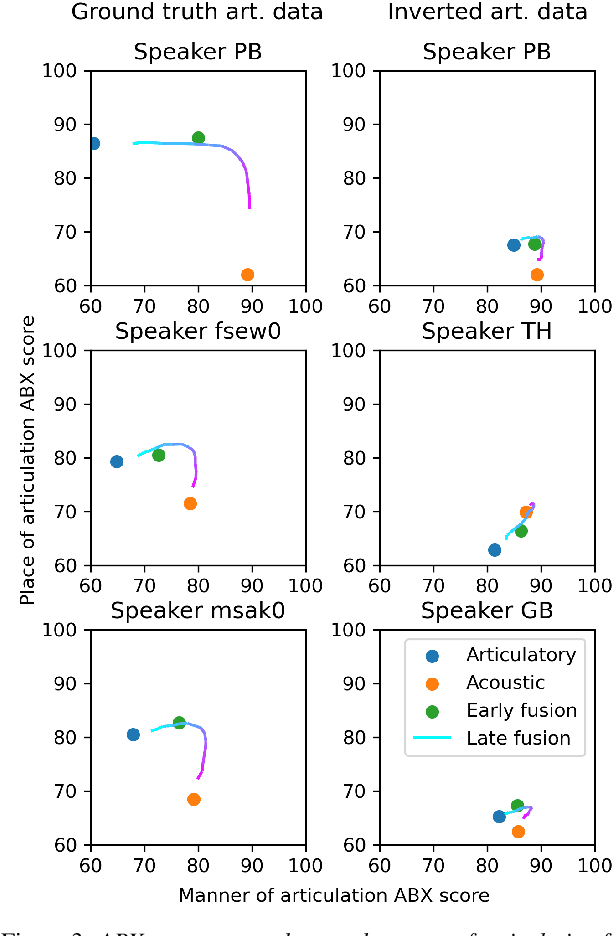
The human perception system is often assumed to recruit motor knowledge when processing auditory speech inputs. Using articulatory modeling and deep learning, this study examines how this articulatory information can be used for discovering speech units in a self-supervised setting. We used vector-quantized variational autoencoders (VQ-VAE) to learn discrete representations from articulatory and acoustic speech data. In line with the zero-resource paradigm, an ABX test was then used to investigate how the extracted representations encode phonetically relevant properties. Experiments were conducted on three different corpora in English and French. We found that articulatory information rather organises the latent representations in terms of place of articulation whereas the speech acoustics mainly structure the latent space in terms of manner of articulation. We show that an optimal fusion of the two modalities can lead to a joint representation of these phonetic dimensions more accurate than each modality considered individually. Since articulatory information is usually not available in a practical situation, we finally investigate the benefit it provides when inferred from the speech acoustics in a self-supervised manner.
Multistream neural architectures for cued-speech recognition using a pre-trained visual feature extractor and constrained CTC decoding
Apr 11, 2022
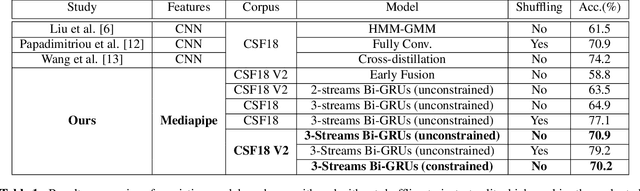
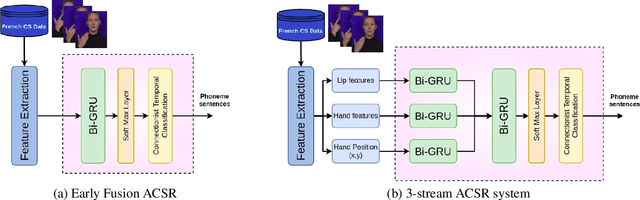
This paper proposes a simple and effective approach for automatic recognition of Cued Speech (CS), a visual communication tool that helps people with hearing impairment to understand spoken language with the help of hand gestures that can uniquely identify the uttered phonemes in complement to lipreading. The proposed approach is based on a pre-trained hand and lips tracker used for visual feature extraction and a phonetic decoder based on a multistream recurrent neural network trained with connectionist temporal classification loss and combined with a pronunciation lexicon. The proposed system is evaluated on an updated version of the French CS dataset CSF18 for which the phonetic transcription has been manually checked and corrected. With a decoding accuracy at the phonetic level of 70.88%, the proposed system outperforms our previous CNN-HMM decoder and competes with more complex baselines.
Repeat after me: Self-supervised learning of acoustic-to-articulatory mapping by vocal imitation
Apr 05, 2022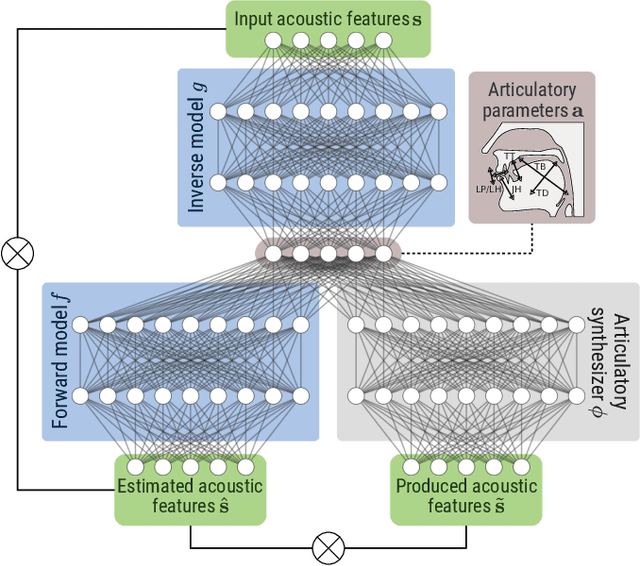
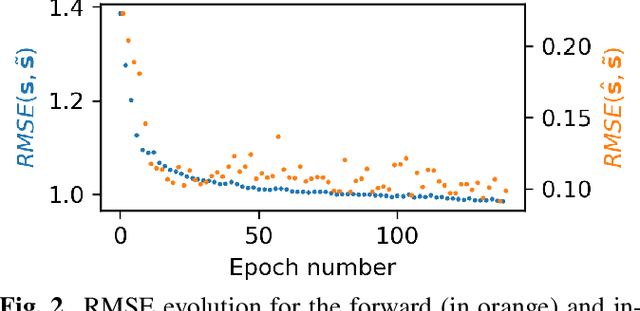
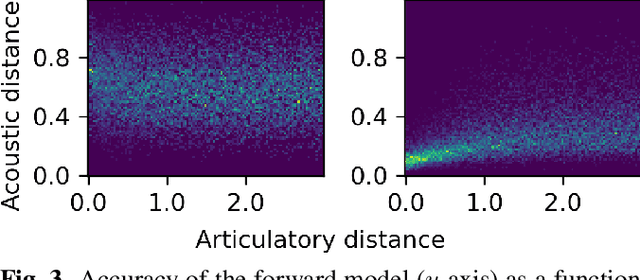
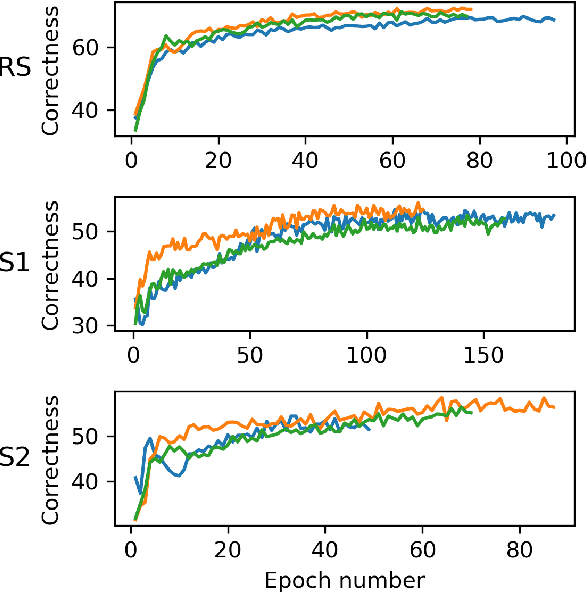
We propose a computational model of speech production combining a pre-trained neural articulatory synthesizer able to reproduce complex speech stimuli from a limited set of interpretable articulatory parameters, a DNN-based internal forward model predicting the sensory consequences of articulatory commands, and an internal inverse model based on a recurrent neural network recovering articulatory commands from the acoustic speech input. Both forward and inverse models are jointly trained in a self-supervised way from raw acoustic-only speech data from different speakers. The imitation simulations are evaluated objectively and subjectively and display quite encouraging performances.