 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
I-SPLIT: Deep Network Interpretability for Split Computing
Sep 23, 2022
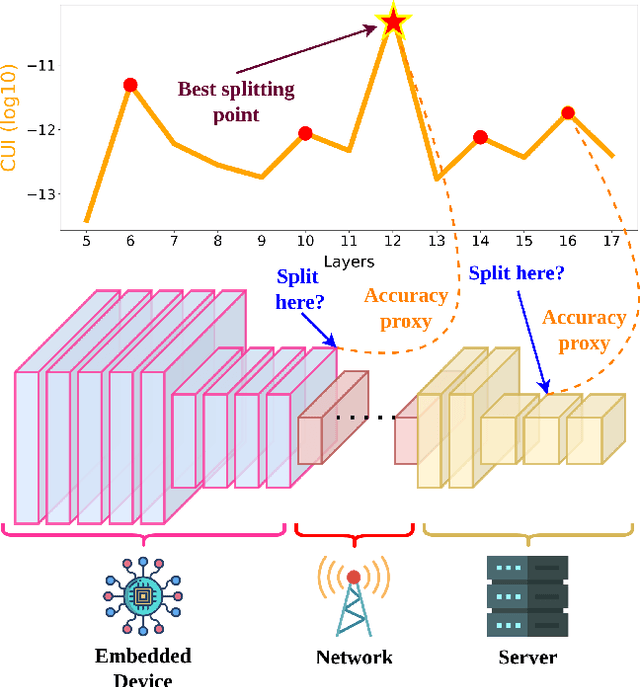
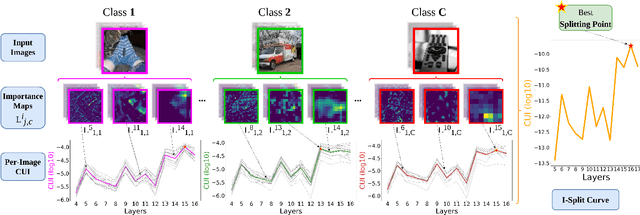
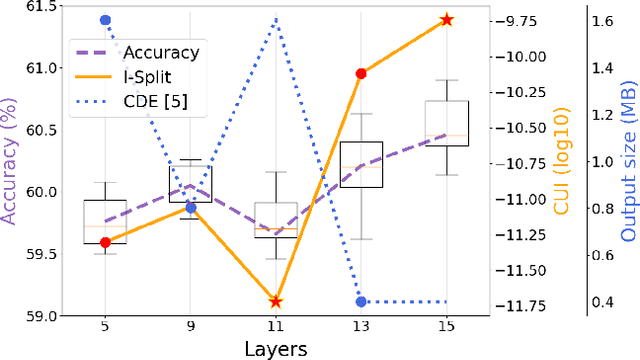
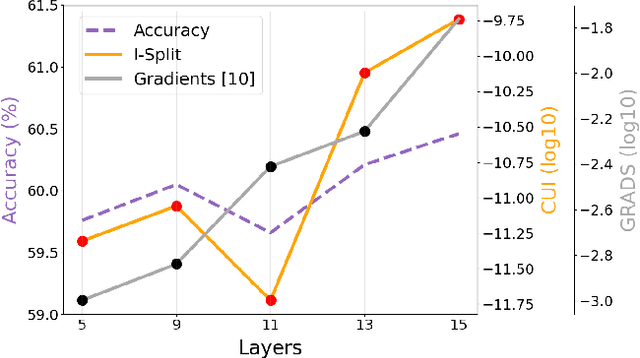
This work makes a substantial step in the field of split computing, i.e., how to split a deep neural network to host its early part on an embedded device and the rest on a server. So far, potential split locations have been identified exploiting uniquely architectural aspects, i.e., based on the layer sizes. Under this paradigm, the efficacy of the split in terms of accuracy can be evaluated only after having performed the split and retrained the entire pipeline, making an exhaustive evaluation of all the plausible splitting points prohibitive in terms of time. Here we show that not only the architecture of the layers does matter, but the importance of the neurons contained therein too. A neuron is important if its gradient with respect to the correct class decision is high. It follows that a split should be applied right after a layer with a high density of important neurons, in order to preserve the information flowing until then. Upon this idea, we propose Interpretable Split (I-SPLIT): a procedure that identifies the most suitable splitting points by providing a reliable prediction on how well this split will perform in terms of classification accuracy, beforehand of its effective implementation. As a further major contribution of I-SPLIT, we show that the best choice for the splitting point on a multiclass categorization problem depends also on which specific classes the network has to deal with. Exhaustive experiments have been carried out on two networks, VGG16 and ResNet-50, and three datasets, Tiny-Imagenet-200, notMNIST, and Chest X-Ray Pneumonia. The source code is available at https://github.com/vips4/I-Split.
SPACE-2: Tree-Structured Semi-Supervised Contrastive Pre-training for Task-Oriented Dialog Understanding
Sep 14, 2022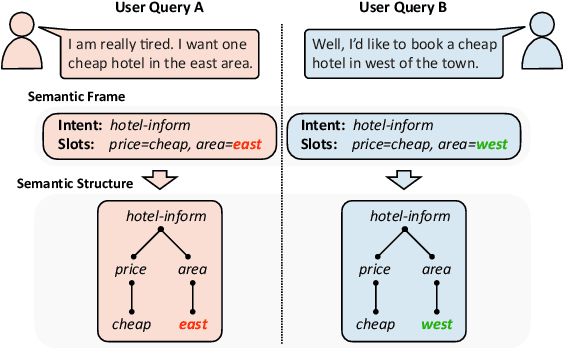
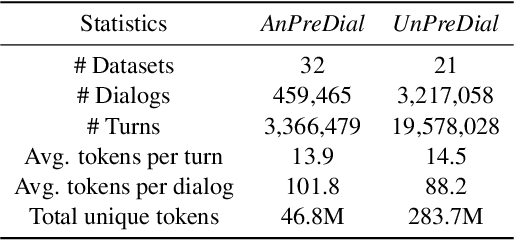
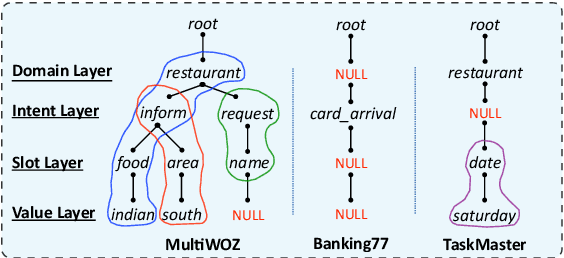
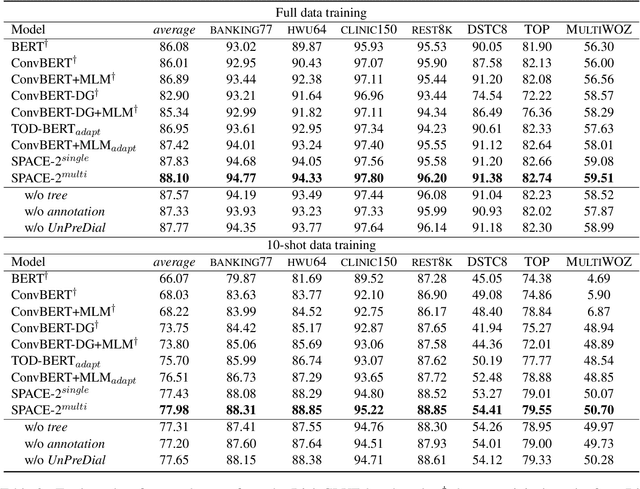
Pre-training methods with contrastive learning objectives have shown remarkable success in dialog understanding tasks. However, current contrastive learning solely considers the self-augmented dialog samples as positive samples and treats all other dialog samples as negative ones, which enforces dissimilar representations even for dialogs that are semantically related. In this paper, we propose SPACE-2, a tree-structured pre-trained conversation model, which learns dialog representations from limited labeled dialogs and large-scale unlabeled dialog corpora via semi-supervised contrastive pre-training. Concretely, we first define a general semantic tree structure (STS) to unify the inconsistent annotation schema across different dialog datasets, so that the rich structural information stored in all labeled data can be exploited. Then we propose a novel multi-view score function to increase the relevance of all possible dialogs that share similar STSs and only push away other completely different dialogs during supervised contrastive pre-training. To fully exploit unlabeled dialogs, a basic self-supervised contrastive loss is also added to refine the learned representations. Experiments show that our method can achieve new state-of-the-art results on the DialoGLUE benchmark consisting of seven datasets and four popular dialog understanding tasks. For reproducibility, we release the code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/space-2.
A Nonlinear PID-Enhanced Adaptive Latent Factor Analysis Model
Aug 04, 2022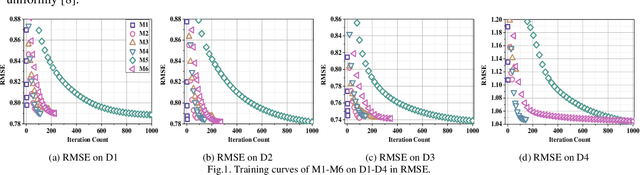
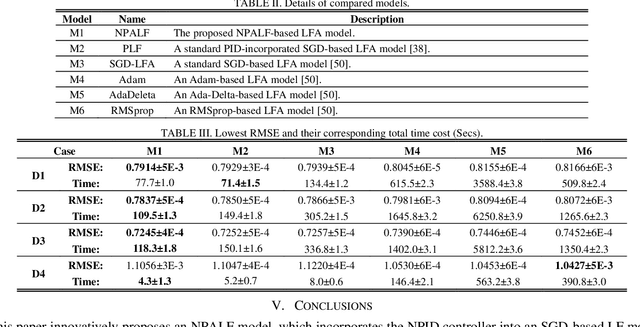
High-dimensional and incomplete (HDI) data holds tremendous interactive information in various industrial applications. A latent factor (LF) model is remarkably effective in extracting valuable information from HDI data with stochastic gradient decent (SGD) algorithm. However, an SGD-based LFA model suffers from slow convergence since it only considers the current learning error. To address this critical issue, this paper proposes a Nonlinear PID-enhanced Adaptive Latent Factor (NPALF) model with two-fold ideas: 1) rebuilding the learning error via considering the past learning errors following the principle of a nonlinear PID controller; b) implementing all parameters adaptation effectively following the principle of a particle swarm optimization (PSO) algorithm. Experience results on four representative HDI datasets indicate that compared with five state-of-the-art LFA models, the NPALF model achieves better convergence rate and prediction accuracy for missing data of an HDI data.
Computer Vision Aided mmWave Beam Alignment in V2X Communications
Jul 23, 2022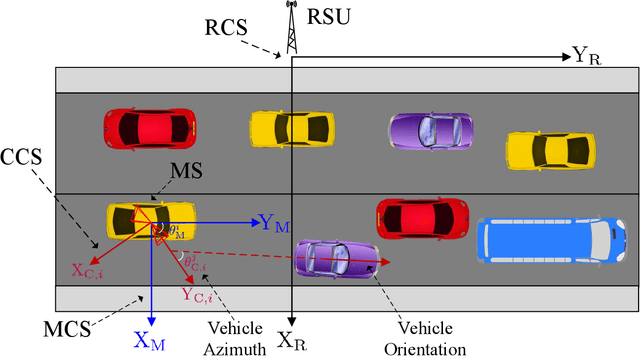

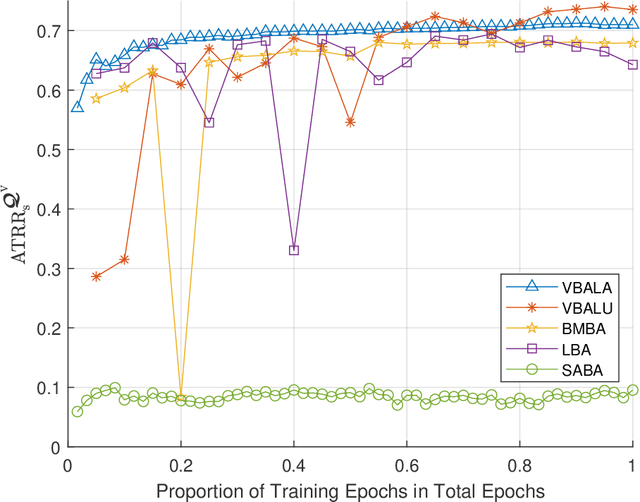
Visual information, captured for example by cameras, can effectively reflect the sizes and locations of the environmental scattering objects, and thereby can be used to infer communications parameters like propagation directions, receiver powers, as well as the blockage status. In this paper, we propose a novel beam alignment framework that leverages images taken by cameras installed at the mobile user. Specifically, we utilize 3D object detection techniques to extract the size and location information of the dynamic vehicles around the mobile user, and design a deep neural network (DNN) to infer the optimal beam pair for transceivers without any pilot signal overhead. Moreover, to avoid performing beam alignment too frequently or too slowly, a beam coherence time (BCT) prediction method is developed based on the vision information. This can effectively improve the transmission rate compared with the beam alignment approach with the fixed BCT. Simulation results show that the proposed vision based beam alignment methods outperform the existing LIDAR and vision based solutions, and demand for much lower hardware cost and communication overhead.
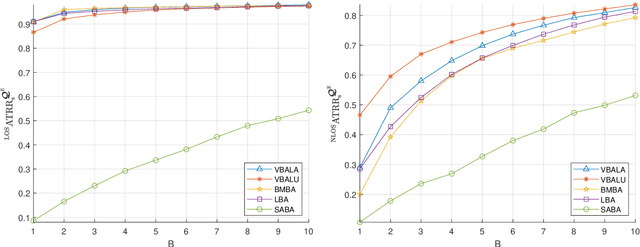
Subclass Knowledge Distillation with Known Subclass Labels
Jul 17, 2022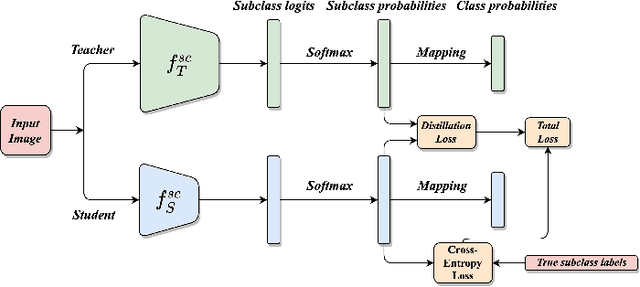
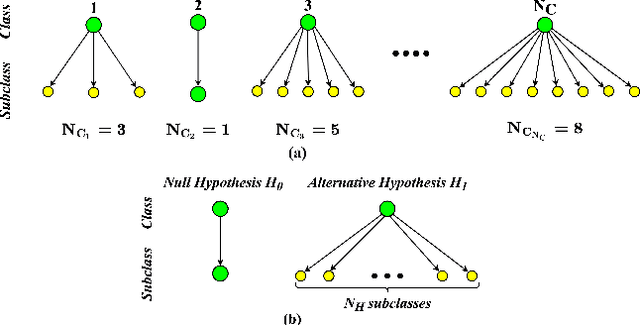
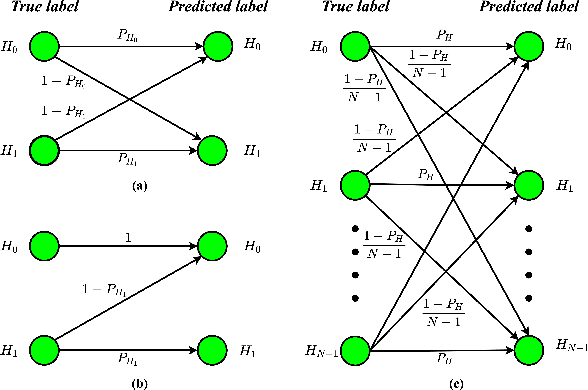
This work introduces a novel knowledge distillation framework for classification tasks where information on existing subclasses is available and taken into consideration. In classification tasks with a small number of classes or binary detection, the amount of information transferred from the teacher to the student is restricted, thus limiting the utility of knowledge distillation. Performance can be improved by leveraging information of possible subclasses within the classes. To that end, we propose the so-called Subclass Knowledge Distillation (SKD), a process of transferring the knowledge of predicted subclasses from a teacher to a smaller student. Meaningful information that is not in the teacher's class logits but exists in subclass logits (e.g., similarities within classes) will be conveyed to the student through the SKD, which will then boost the student's performance. Analytically, we measure how much extra information the teacher can provide the student via the SKD to demonstrate the efficacy of our work. The framework developed is evaluated in clinical application, namely colorectal polyp binary classification. It is a practical problem with two classes and a number of subclasses per class. In this application, clinician-provided annotations are used to define subclasses based on the annotation label's variability in a curriculum style of learning. A lightweight, low-complexity student trained with the SKD framework achieves an F1-score of 85.05%, an improvement of 1.47%, and a 2.10% gain over the student that is trained with and without conventional knowledge distillation, respectively. The 2.10% F1-score gap between students trained with and without the SKD can be explained by the extra subclass knowledge, i.e., the extra 0.4656 label bits per sample that the teacher can transfer in our experiment.
Combining Metric Learning and Attention Heads For Accurate and Efficient Multilabel Image Classification
Sep 14, 2022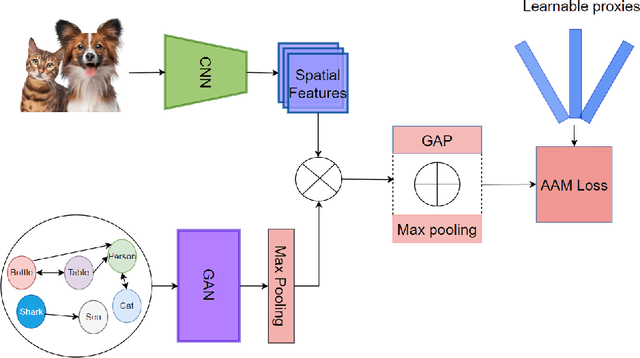
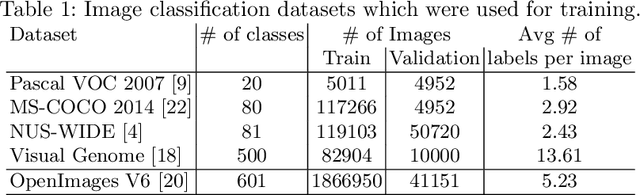
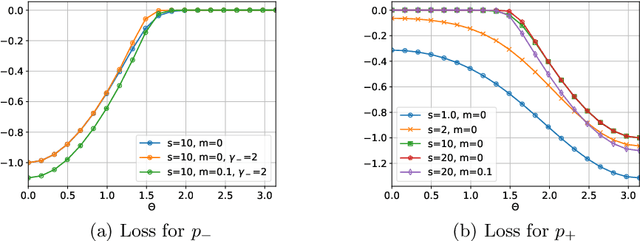
Multi-label image classification allows predicting a set of labels from a given image. Unlike multiclass classification, where only one label per image is assigned, such setup is applicable for a broader range of applications. In this work we revisit two popular approaches to multilabel classification: transformer-based heads and labels relations information graph processing branches. Although transformer-based heads are considered to achieve better results than graph-based branches, we argue that with the proper training strategy graph-based methods can demonstrate just a small accuracy drop, while spending less computational resources on inference. In our training strategy, instead of Asymmetric Loss (ASL), which is the de-facto standard for multilabel classification, we introduce its modification acting in the angle space. It implicitly learns a proxy feature vector on the unit hypersphere for each class, providing a better discrimination ability, than binary cross entropy loss does on unnormalized features. With the proposed loss and training strategy, we obtain SOTA results among single modality methods on widespread multilabel classification benchmarks such as MS-COCO, PASCAL-VOC, NUS-Wide and Visual Genome 500. Source code of our method is available as a part of the OpenVINO Training Extensions https://github.com/openvinotoolkit/deep-object-reid/tree/multilabel
Literature on Hand GESTURE Recognition using Graph based methods
Jul 01, 2022


Skeleton based recognition systems are gaining popularity and machine learning models focusing on points or joints in a skeleton have proved to be computationally effective and application in many areas like Robotics. It is easy to track points and thereby preserving spatial and temporal information, which plays an important role in abstracting the required information, classification becomes an easy task. In this paper, we aim to study these points but using a cloud mechanism, where we define a cloud as collection of points. However, when we add temporal information, it may not be possible to retrieve the coordinates of a point in each frame and hence instead of focusing on a single point, we can use k-neighbors to retrieve the state of the point under discussion. Our focus is to gather such information using weight sharing but making sure that when we try to retrieve the information from neighbors, we do not carry noise with it. LSTM which has capability of long-term modelling and can carry both temporal and spatial information. In this article we tried to summarise graph based gesture recognition method.
SO(3)-Pose: SO(3)-Equivariance Learning for 6D Object Pose Estimation
Aug 17, 2022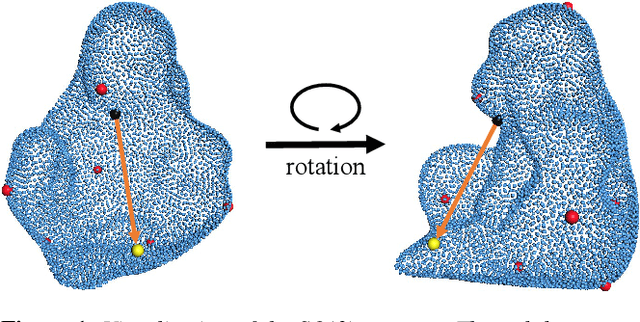
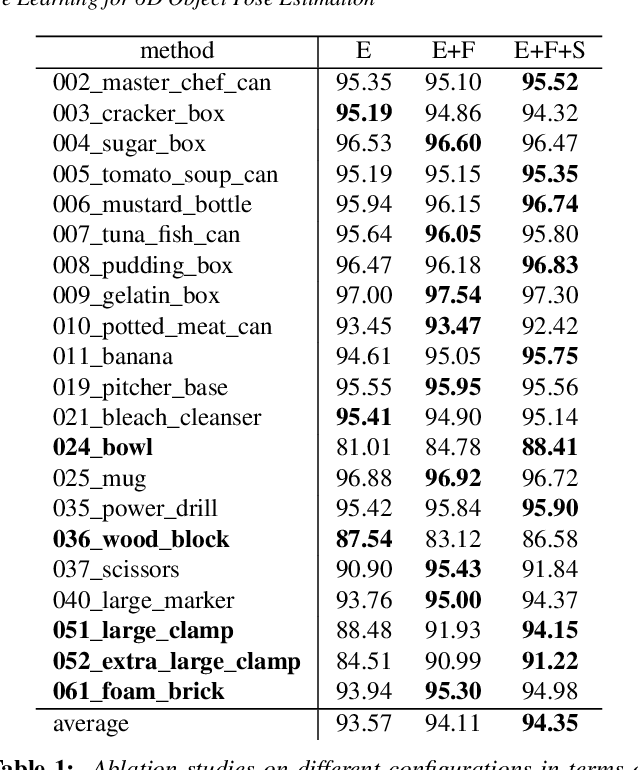

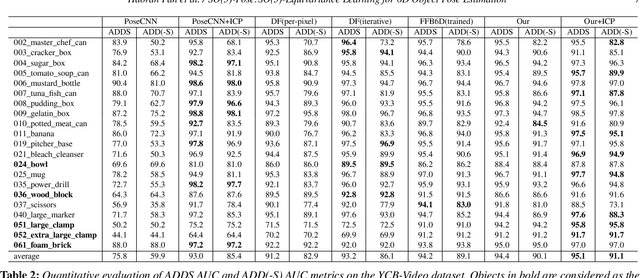
6D pose estimation of rigid objects from RGB-D images is crucial for object grasping and manipulation in robotics. Although RGB channels and the depth (D) channel are often complementary, providing respectively the appearance and geometry information, it is still non-trivial how to fully benefit from the two cross-modal data. From the simple yet new observation, when an object rotates, its semantic label is invariant to the pose while its keypoint offset direction is variant to the pose. To this end, we present SO(3)-Pose, a new representation learning network to explore SO(3)-equivariant and SO(3)-invariant features from the depth channel for pose estimation. The SO(3)-invariant features facilitate to learn more distinctive representations for segmenting objects with similar appearance from RGB channels. The SO(3)-equivariant features communicate with RGB features to deduce the (missed) geometry for detecting keypoints of an object with the reflective surface from the depth channel. Unlike most of existing pose estimation methods, our SO(3)-Pose not only implements the information communication between the RGB and depth channels, but also naturally absorbs the SO(3)-equivariance geometry knowledge from depth images, leading to better appearance and geometry representation learning. Comprehensive experiments show that our method achieves the state-of-the-art performance on three benchmarks.
D&D: Learning Human Dynamics from Dynamic Camera
Sep 19, 2022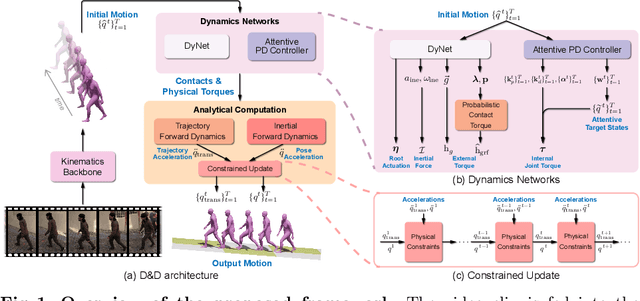
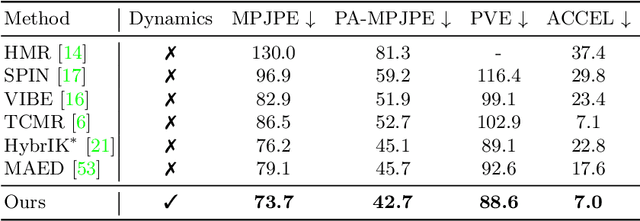
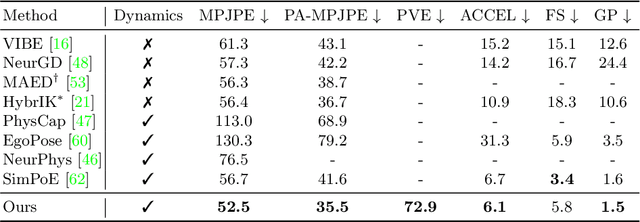
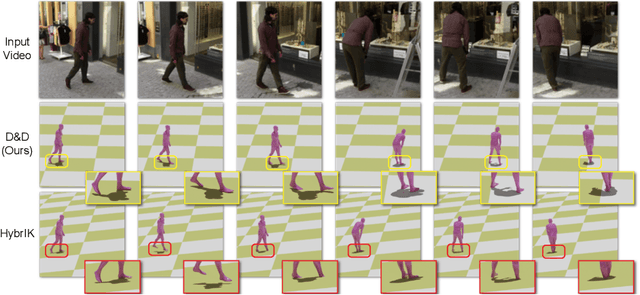
3D human pose estimation from a monocular video has recently seen significant improvements. However, most state-of-the-art methods are kinematics-based, which are prone to physically implausible motions with pronounced artifacts. Current dynamics-based methods can predict physically plausible motion but are restricted to simple scenarios with static camera view. In this work, we present D&D (Learning Human Dynamics from Dynamic Camera), which leverages the laws of physics to reconstruct 3D human motion from the in-the-wild videos with a moving camera. D&D introduces inertial force control (IFC) to explain the 3D human motion in the non-inertial local frame by considering the inertial forces of the dynamic camera. To learn the ground contact with limited annotations, we develop probabilistic contact torque (PCT), which is computed by differentiable sampling from contact probabilities and used to generate motions. The contact state can be weakly supervised by encouraging the model to generate correct motions. Furthermore, we propose an attentive PD controller that adjusts target pose states using temporal information to obtain smooth and accurate pose control. Our approach is entirely neural-based and runs without offline optimization or simulation in physics engines. Experiments on large-scale 3D human motion benchmarks demonstrate the effectiveness of D&D, where we exhibit superior performance against both state-of-the-art kinematics-based and dynamics-based methods. Code is available at https://github.com/Jeffsjtu/DnD
Fast Reflexive Grasping with a Proprioceptive Teleoperation Platform
Aug 09, 2022
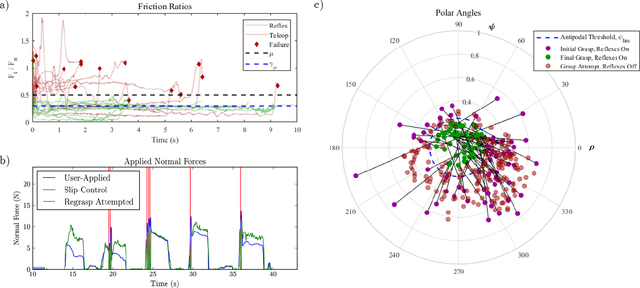
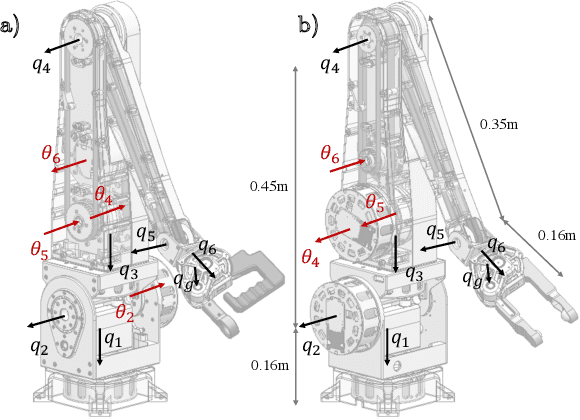
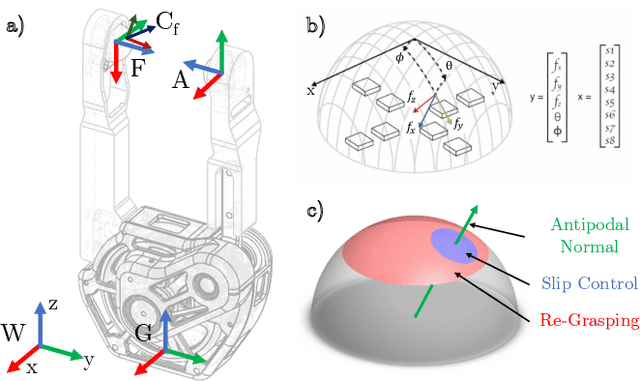
We present a proprioceptive teleoperation system that uses a reflexive grasping algorithm to enhance the speed and robustness of pick-and-place tasks. The system consists of two manipulators that use quasi-direct-drive actuation to provide highly transparent force feedback. The end-effector has bimodal force sensors that measure 3-axis force information and 2-dimensional contact location. This information is used for anti-slip and re-grasping reflexes. When the user makes contact with the desired object, the re-grasping reflex aligns the gripper fingers with antipodal points on the object to maximize the grasp stability. The reflex takes only 150ms to correct for inaccurate grasps chosen by the user, so the user's motion is only minimally disturbed by the execution of the re-grasp. Once antipodal contact is established, the anti-slip reflex ensures that the gripper applies enough normal force to prevent the object from slipping out of the grasp. The combination of proprioceptive manipulators and reflexive grasping allows the user to complete teleoperated tasks with precision at high speed.