 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Metric Learning and Attention Heads For Accurate and Efficient Multilabel Image Classification
Sep 14, 2022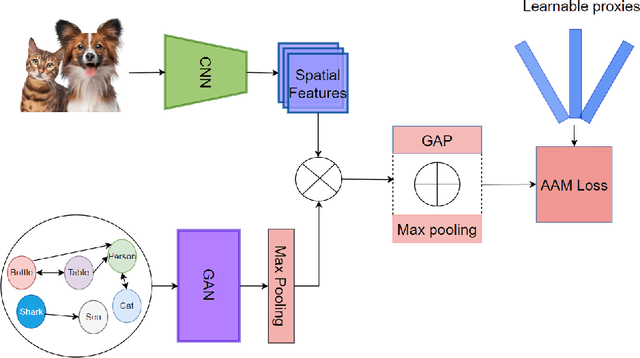
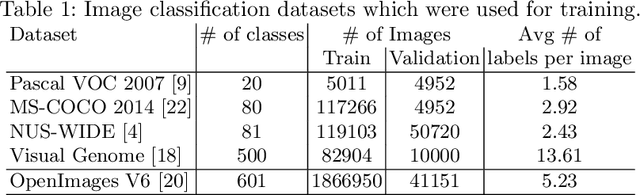
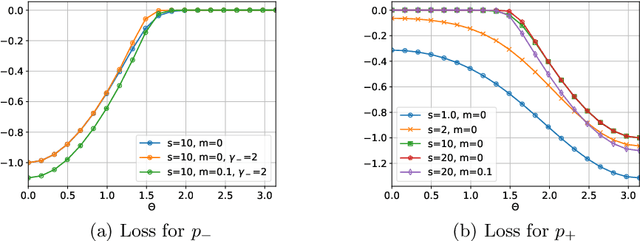
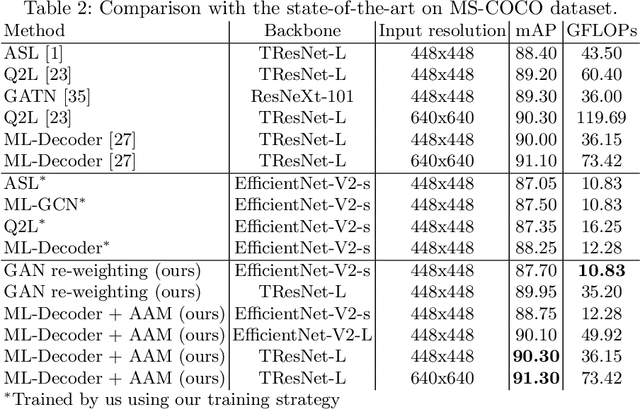
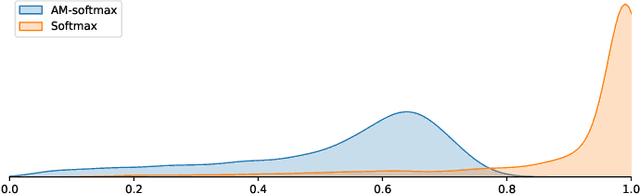
Multi-label image classification allows predicting a set of labels from a given image. Unlike multiclass classification, where only one label per image is assigned, such setup is applicable for a broader range of applications. In this work we revisit two popular approaches to multilabel classification: transformer-based heads and labels relations information graph processing branches. Although transformer-based heads are considered to achieve better results than graph-based branches, we argue that with the proper training strategy graph-based methods can demonstrate just a small accuracy drop, while spending less computational resources on inference. In our training strategy, instead of Asymmetric Loss (ASL), which is the de-facto standard for multilabel classification, we introduce its modification acting in the angle space. It implicitly learns a proxy feature vector on the unit hypersphere for each class, providing a better discrimination ability, than binary cross entropy loss does on unnormalized features. With the proposed loss and training strategy, we obtain SOTA results among single modality methods on widespread multilabel classification benchmarks such as MS-COCO, PASCAL-VOC, NUS-Wide and Visual Genome 500. Source code of our method is available as a part of the OpenVINO Training Extensions https://github.com/openvinotoolkit/deep-object-reid/tree/multilabel
Towards Efficient and Data Agnostic Image Classification Training Pipeline for Embedded Systems
Aug 16, 2021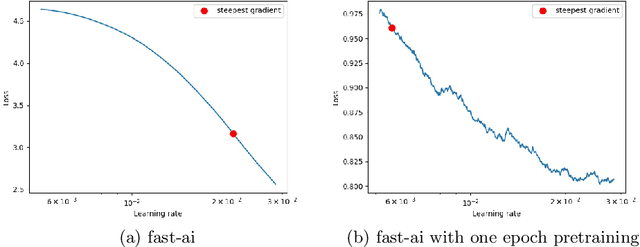
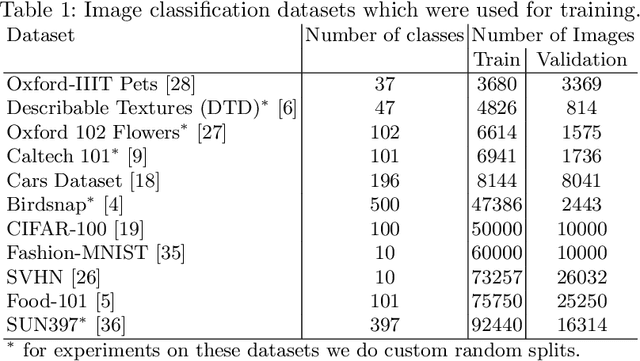
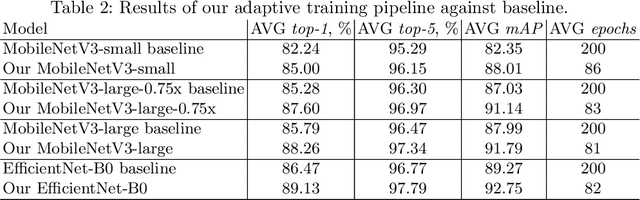
Nowadays deep learning-based methods have achieved a remarkable progress at the image classification task among a wide range of commonly used datasets (ImageNet, CIFAR, SVHN, Caltech 101, SUN397, etc.). SOTA performance on each of the mentioned datasets is obtained by careful tuning of the model architecture and training tricks according to the properties of the target data. Although this approach allows setting academic records, it is unrealistic that an average data scientist would have enough resources to build a sophisticated training pipeline for every image classification task he meets in practice. This work is focusing on reviewing the latest augmentation and regularization methods for the image classification and exploring ways to automatically choose some of the most important hyperparameters: total number of epochs, initial learning rate value and it's schedule. Having a training procedure equipped with a lightweight modern CNN architecture (like bileNetV3 or EfficientNet), sufficient level of regularization and adaptive to data learning rate schedule, we can achieve a reasonable performance on a variety of downstream image classification tasks without manual tuning of parameters to each particular task. Resulting models are computationally efficient and can be deployed to CPU using the OpenVINO toolkit. Source code is available as a part of the OpenVINO Training Extensions (https://github.com/openvinotoolkit/training_extensions).