 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TRBoost: A Generic Gradient Boosting Machine based on Trust-region Method
Oct 08, 2022
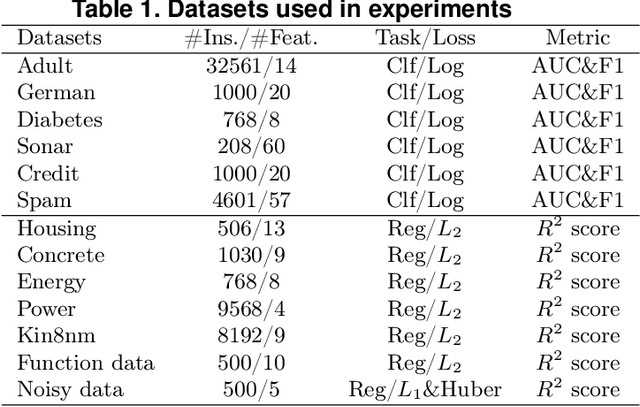
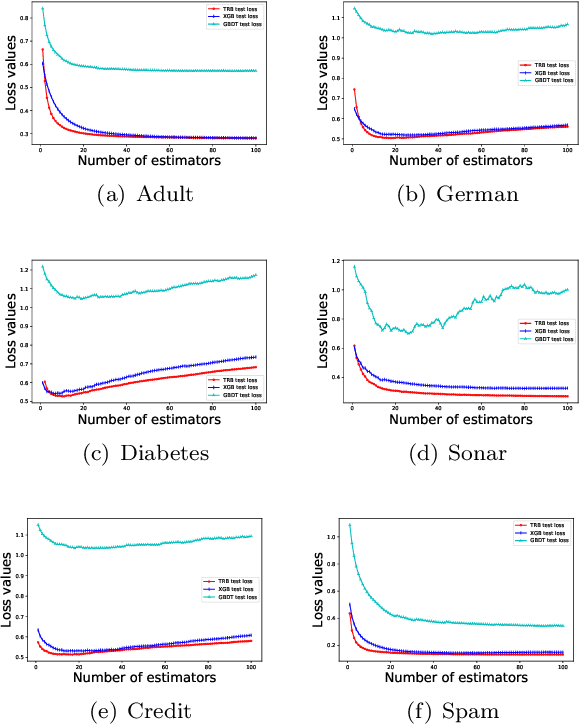
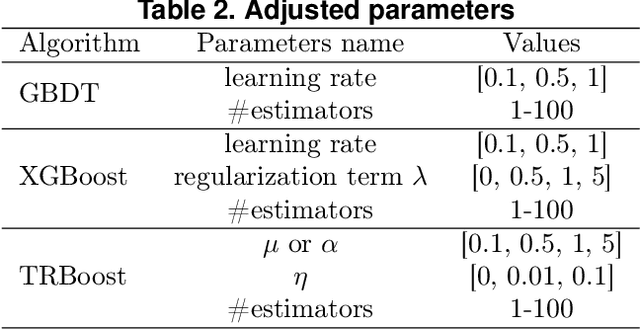
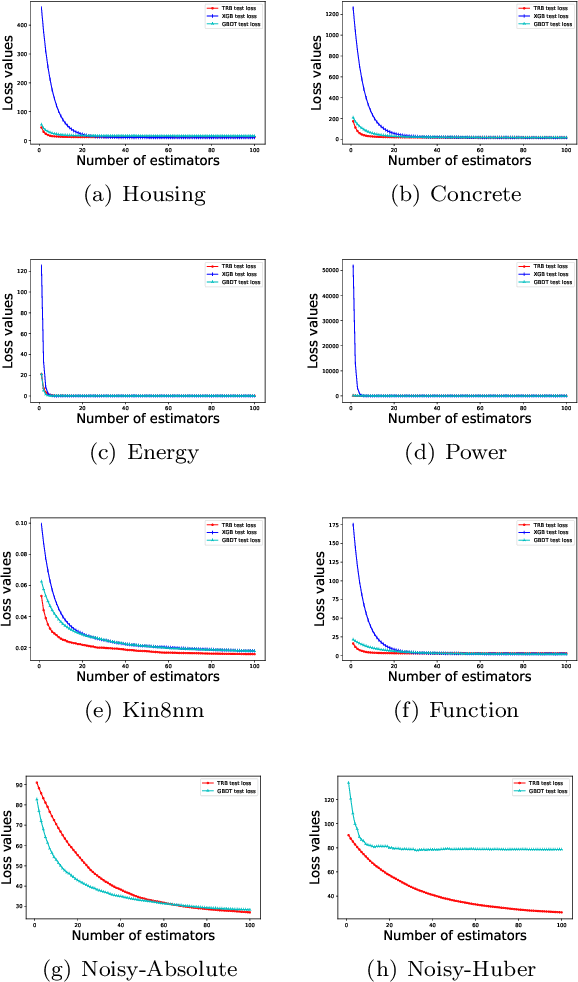
Gradient Boosting Machines (GBMs) are derived from Taylor expansion in functional space and have achieved state-of-the-art results on a variety of problems. However, there is a dilemma for GBMs to maintain a balance between performance and generality. Specifically, gradient descent-based GBMs employ the first-order Taylor expansion to make them appropriate for all loss functions. And Newton's method-based GBMs use the positive hessian information to achieve better performance at the expense of generality. In this paper, a generic Gradient Boosting Machine called Trust-region Boosting (TRBoost) is presented to maintain this balance. In each iteration, we apply a constrained quadratic model to approximate the objective and solve it by the Trust-region algorithm to obtain a new learner. TRBoost offers the benefit that we do not need the hessian to be positive definite, which generalizes GBMs to suit arbitrary loss functions while keeping up the good performance as the second-order algorithm. Several numerical experiments are conducted to confirm that TRBoost is not only as general as the first-order GBMs but also able to get competitive results with the second-order GBMs.
Bottleneck Analysis of Dynamic Graph Neural Network Inference on CPU and GPU
Oct 08, 2022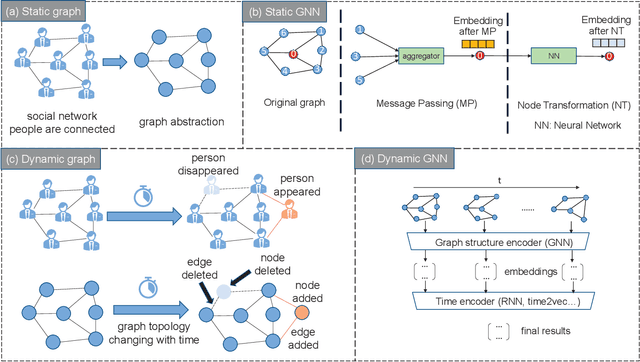
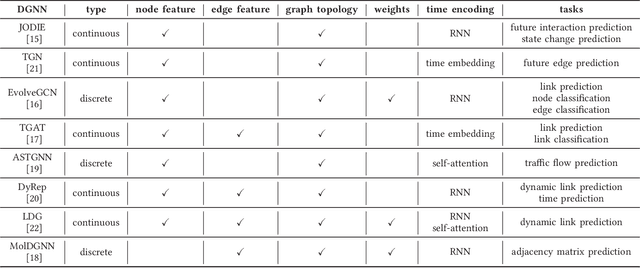
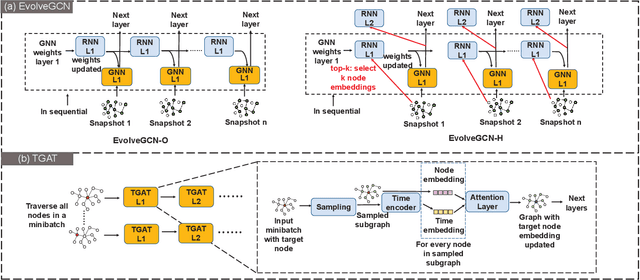
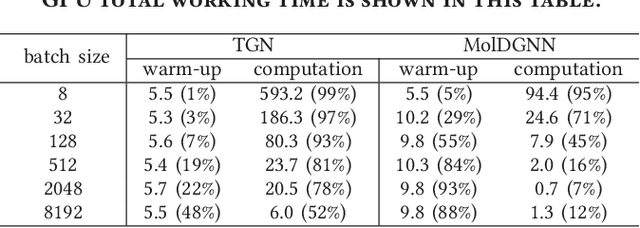
Dynamic graph neural network (DGNN) is becoming increasingly popular because of its widespread use in capturing dynamic features in the real world. A variety of dynamic graph neural networks designed from algorithmic perspectives have succeeded in incorporating temporal information into graph processing. Despite the promising algorithmic performance, deploying DGNNs on hardware presents additional challenges due to the model complexity, diversity, and the nature of the time dependency. Meanwhile, the differences between DGNNs and static graph neural networks make hardware-related optimizations for static graph neural networks unsuitable for DGNNs. In this paper, we select eight prevailing DGNNs with different characteristics and profile them on both CPU and GPU. The profiling results are summarized and analyzed, providing in-depth insights into the bottlenecks of DGNNs on hardware and identifying potential optimization opportunities for future DGNN acceleration. Followed by a comprehensive survey, we provide a detailed analysis of DGNN performance bottlenecks on hardware, including temporal data dependency, workload imbalance, data movement, and GPU warm-up. We suggest several optimizations from both software and hardware perspectives. This paper is the first to provide an in-depth analysis of the hardware performance of DGNN Code is available at https://github.com/sharc-lab/DGNN_analysis.
Enhance Sample Efficiency and Robustness of End-to-end Urban Autonomous Driving via Semantic Masked World Model
Oct 08, 2022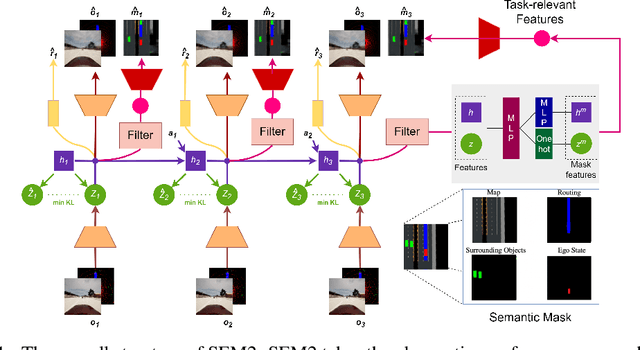

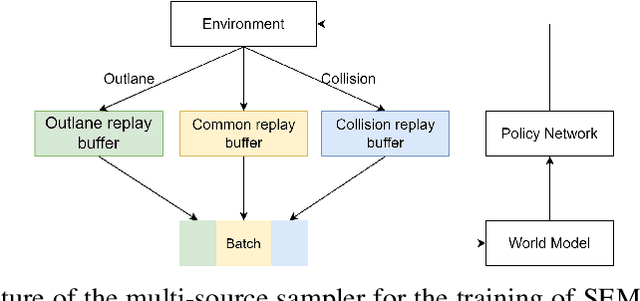
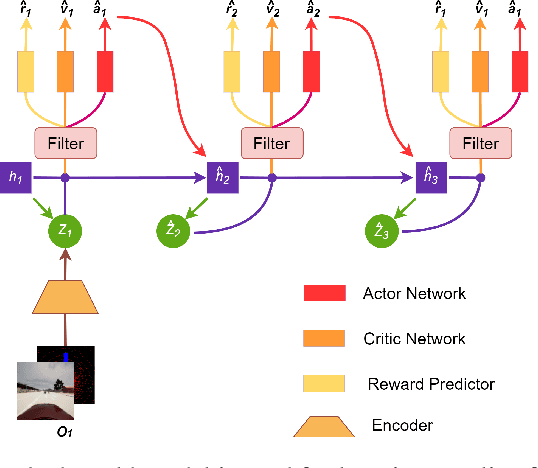
End-to-end autonomous driving provides a feasible way to automatically maximize overall driving system performance by directly mapping the raw pixels from a front-facing camera to control signals. Recent advanced methods construct a latent world model to map the high dimensional observations into compact latent space. However, the latent states embedded by the world model proposed in previous works may contain a large amount of task-irrelevant information, resulting in low sampling efficiency and poor robustness to input perturbations. Meanwhile, the training data distribution is usually unbalanced, and the learned policy is hard to cope with the corner cases during the driving process. To solve the above challenges, we present a semantic masked recurrent world model (SEM2), which introduces a latent filter to extract key task-relevant features and reconstruct a semantic mask via the filtered features, and is trained with a multi-source data sampler, which aggregates common data and multiple corner case data in a single batch, to balance the data distribution. Extensive experiments on CARLA show that our method outperforms the state-of-the-art approaches in terms of sample efficiency and robustness to input permutations.
LAD: A Hybrid Deep Learning System for Benign Paroxysmal Positional Vertigo Disorders Diagnostic
Oct 15, 2022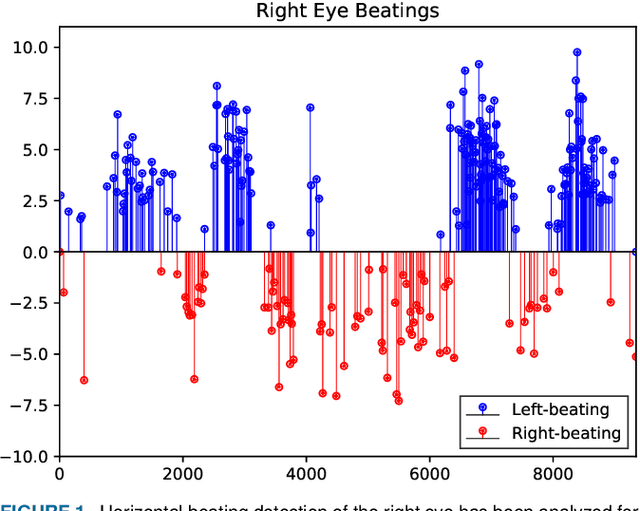
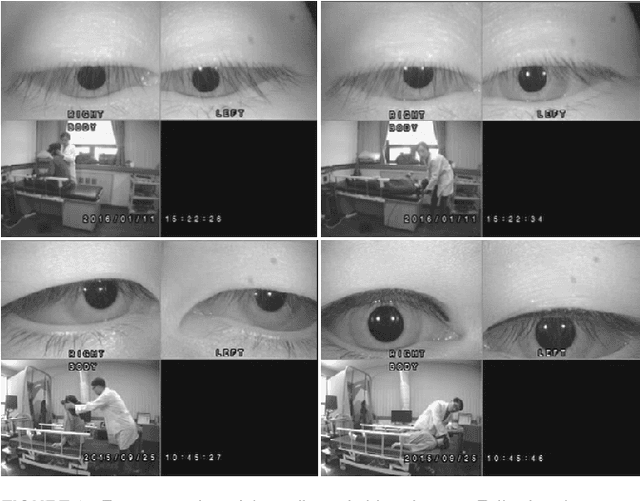
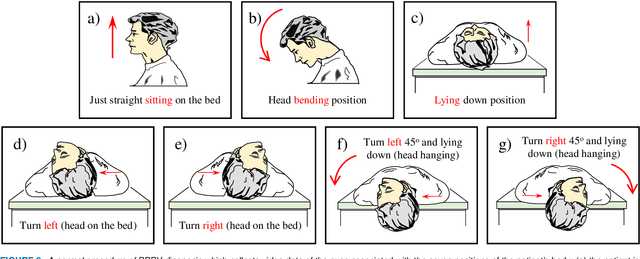

Herein, we introduce "Look and Diagnose" (LAD), a hybrid deep learning-based system that aims to support doctors in the medical field in diagnosing effectively the Benign Paroxysmal Positional Vertigo (BPPV) disorder. Given the body postures of the patient in the Dix-Hallpike and lateral head turns test, the visual information of both eyes is captured and fed into LAD for analyzing and classifying into one of six possible disorders the patient might be suffering from. The proposed system consists of two streams: (1) an RNN-based stream that takes raw RGB images of both eyes to extract visual features and optical flow of each eye followed by ternary classification to determine left/right posterior canal (PC) or other; and (2) pupil detector stream that detects the pupil when it is classified as Non-PC and classifies the direction and strength of the beating to categorize the Non-PC types into the remaining four classes: Geotropic BPPV (left and right) and Apogeotropic BPPV (left and right). Experimental results show that with the patient's body postures, the system can accurately classify given BPPV disorder into the six types of disorders with an accuracy of 91% on the validation set. The proposed method can successfully classify disorders with an accuracy of 93% for the Posterior Canal disorder and 95% for the Geotropic and Apogeotropic disorder, paving a potential direction for research with the medical data.
RoS-KD: A Robust Stochastic Knowledge Distillation Approach for Noisy Medical Imaging
Oct 15, 2022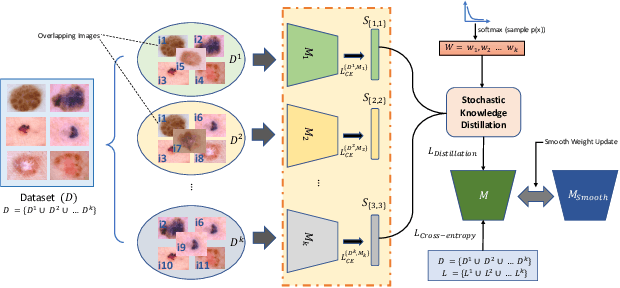
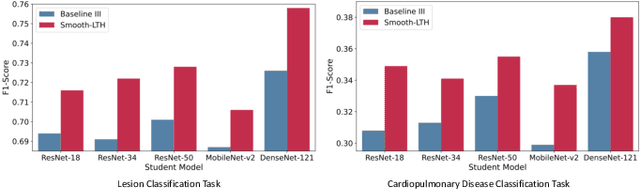
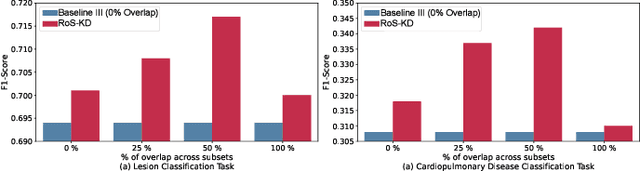
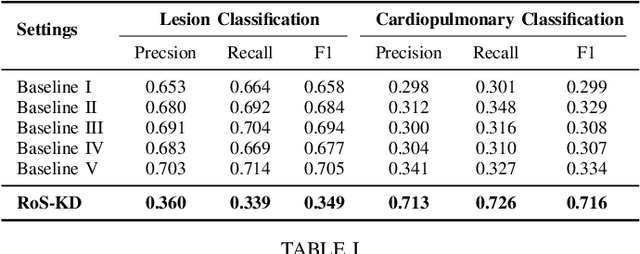
AI-powered Medical Imaging has recently achieved enormous attention due to its ability to provide fast-paced healthcare diagnoses. However, it usually suffers from a lack of high-quality datasets due to high annotation cost, inter-observer variability, human annotator error, and errors in computer-generated labels. Deep learning models trained on noisy labelled datasets are sensitive to the noise type and lead to less generalization on the unseen samples. To address this challenge, we propose a Robust Stochastic Knowledge Distillation (RoS-KD) framework which mimics the notion of learning a topic from multiple sources to ensure deterrence in learning noisy information. More specifically, RoS-KD learns a smooth, well-informed, and robust student manifold by distilling knowledge from multiple teachers trained on overlapping subsets of training data. Our extensive experiments on popular medical imaging classification tasks (cardiopulmonary disease and lesion classification) using real-world datasets, show the performance benefit of RoS-KD, its ability to distill knowledge from many popular large networks (ResNet-50, DenseNet-121, MobileNet-V2) in a comparatively small network, and its robustness to adversarial attacks (PGD, FSGM). More specifically, RoS-KD achieves >2% and >4% improvement on F1-score for lesion classification and cardiopulmonary disease classification tasks, respectively, when the underlying student is ResNet-18 against recent competitive knowledge distillation baseline. Additionally, on cardiopulmonary disease classification task, RoS-KD outperforms most of the SOTA baselines by ~1% gain in AUC score.
Combination Of Convolution Neural Networks And Deep Neural Networks For Fake News Detection
Oct 15, 2022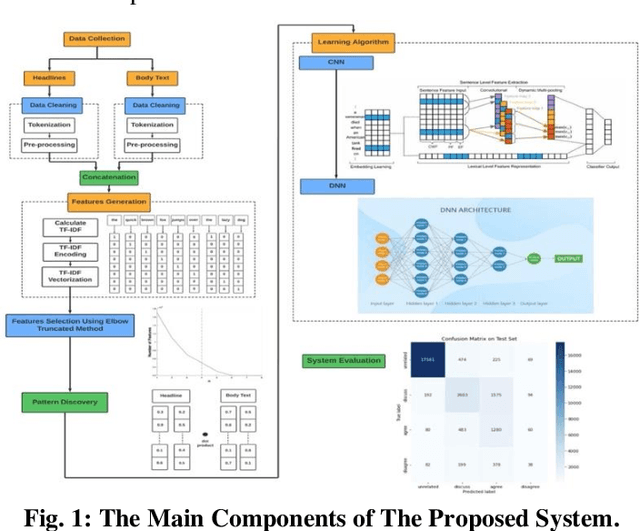
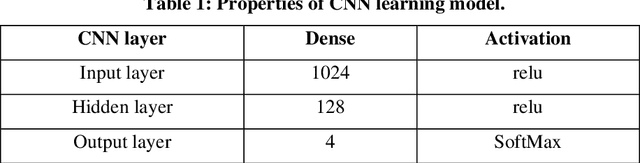

Nowadays, People prefer to follow the latest news on social media, as it is cheap, easily accessible, and quickly disseminated. However, it can spread fake or unreliable, low-quality news that intentionally contains false information. The spread of fake news can have a negative effect on people and society. Given the seriousness of such a problem, researchers did their best to identify patterns and characteristics that fake news may exhibit to design a system that can detect fake news before publishing. In this paper, we have described the Fake News Challenge stage #1 (FNC-1) dataset and given an overview of the competitive attempts to build a fake news detection system using the FNC-1 dataset. The proposed model was evaluated with the FNC-1 dataset. A competitive dataset is considered an open problem and a challenge worldwide. This system's procedure implies processing the text in the headline and body text columns with different natural language processing techniques. After that, the extracted features are reduced using the elbow truncated method, finding the similarity between each pair using the soft cosine similarity method. The new feature is entered into CNN and DNN deep learning approaches. The proposed system detects all the categories with high accuracy except the disagree category. As a result, the system achieves up to 84.6 % accuracy, classifying it as the second ranking based on other competitive studies regarding this dataset.
Improving Molecular Pretraining with Complementary Featurizations
Sep 29, 2022
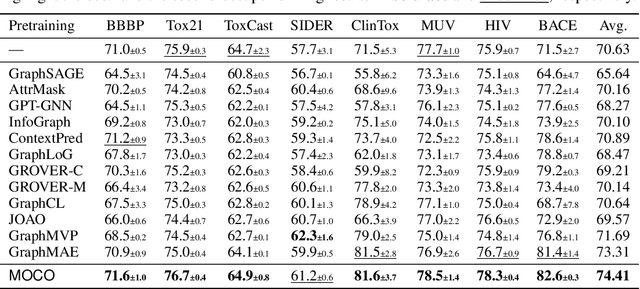
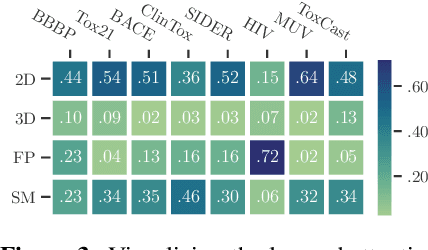
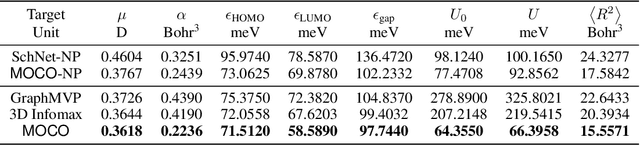
Molecular pretraining, which learns molecular representations over massive unlabeled data, has become a prominent paradigm to solve a variety of tasks in computational chemistry and drug discovery. Recently, prosperous progress has been made in molecular pretraining with different molecular featurizations, including 1D SMILES strings, 2D graphs, and 3D geometries. However, the role of molecular featurizations with their corresponding neural architectures in molecular pretraining remains largely unexamined. In this paper, through two case studies -- chirality classification and aromatic ring counting -- we first demonstrate that different featurization techniques convey chemical information differently. In light of this observation, we propose a simple and effective MOlecular pretraining framework with COmplementary featurizations (MOCO). MOCO comprehensively leverages multiple featurizations that complement each other and outperforms existing state-of-the-art models that solely relies on one or two featurizations on a wide range of molecular property prediction tasks.
Improving Conversational Recommendation Systems' Quality with Context-Aware Item Meta Information
Dec 15, 2021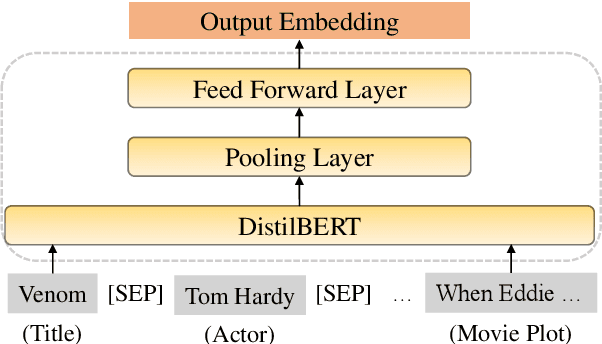
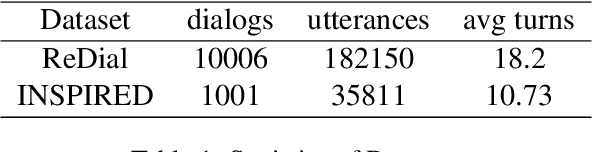
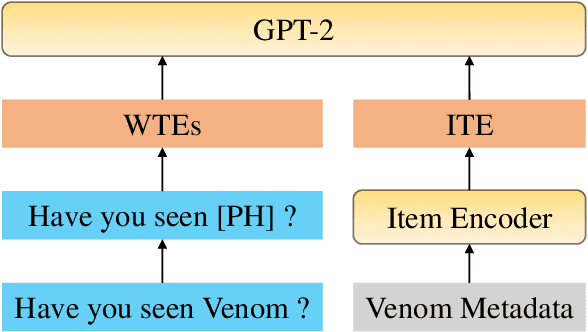
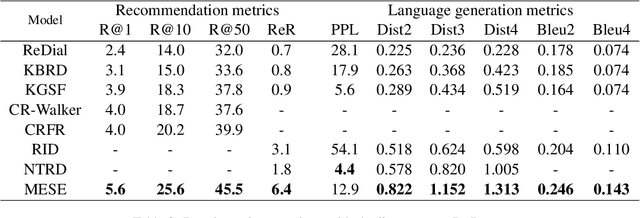
Conversational recommendation systems (CRS) engage with users by inferring user preferences from dialog history, providing accurate recommendations, and generating appropriate responses. Previous CRSs use knowledge graph (KG) based recommendation modules and integrate KG with language models for response generation. Although KG-based approaches prove effective, two issues remain to be solved. First, KG-based approaches ignore the information in the conversational context but only rely on entity relations and bag of words to recommend items. Second, it requires substantial engineering efforts to maintain KGs that model domain-specific relations, thus leading to less flexibility. In this paper, we propose a simple yet effective architecture comprising a pre-trained language model (PLM) and an item metadata encoder. The encoder learns to map item metadata to embeddings that can reflect the semantic information in the dialog context. The PLM then consumes the semantic-aligned item embeddings together with dialog context to generate high-quality recommendations and responses. Instead of modeling entity relations with KGs, our model reduces engineering complexity by directly converting each item to an embedding. Experimental results on the benchmark dataset ReDial show that our model obtains state-of-the-art results on both recommendation and response generation tasks.
Stochastic Differentially Private and Fair Learning
Oct 17, 2022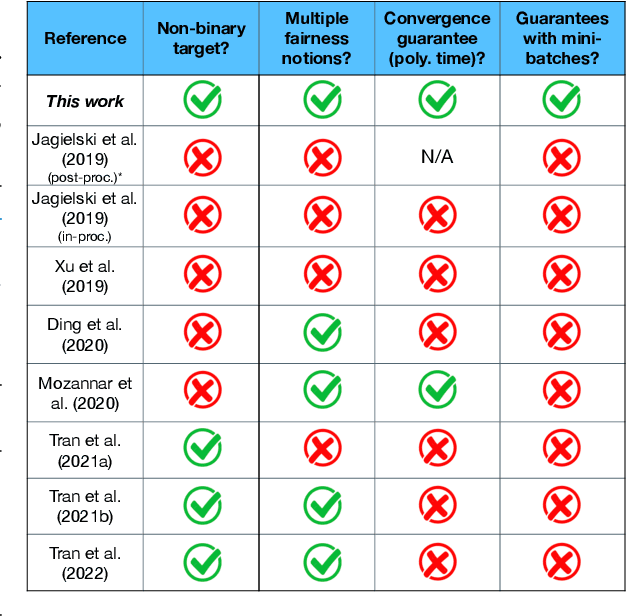
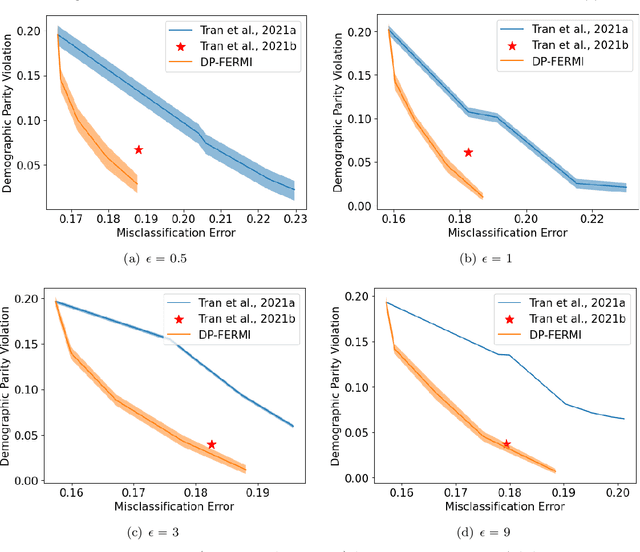
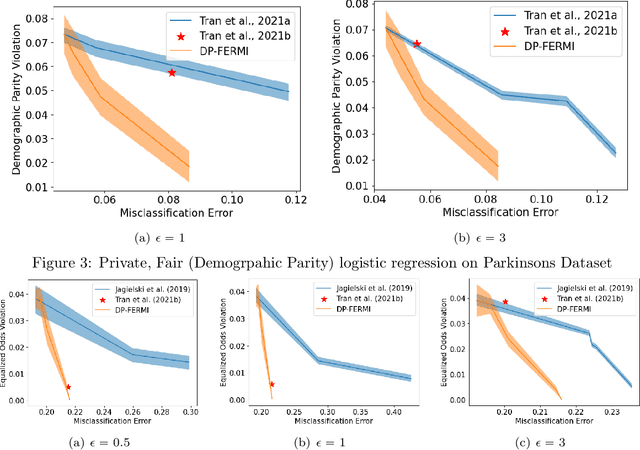
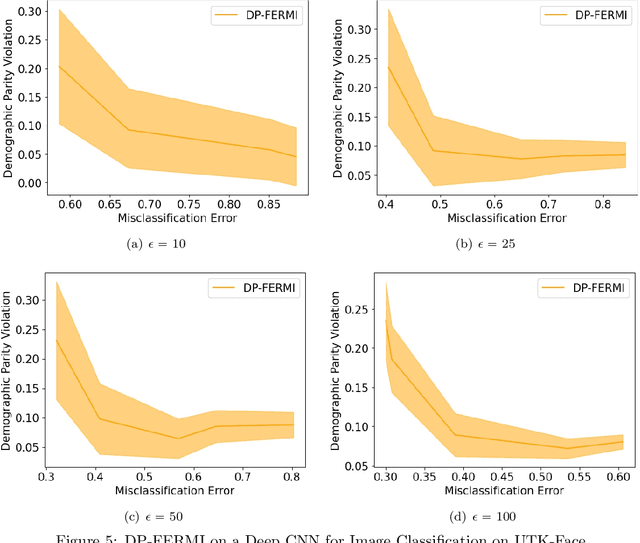
Machine learning models are increasingly used in high-stakes decision-making systems. In such applications, a major concern is that these models sometimes discriminate against certain demographic groups such as individuals with certain race, gender, or age. Another major concern in these applications is the violation of the privacy of users. While fair learning algorithms have been developed to mitigate discrimination issues, these algorithms can still leak sensitive information, such as individuals' health or financial records. Utilizing the notion of differential privacy (DP), prior works aimed at developing learning algorithms that are both private and fair. However, existing algorithms for DP fair learning are either not guaranteed to converge or require full batch of data in each iteration of the algorithm to converge. In this paper, we provide the first stochastic differentially private algorithm for fair learning that is guaranteed to converge. Here, the term "stochastic" refers to the fact that our proposed algorithm converges even when minibatches of data are used at each iteration (i.e. stochastic optimization). Our framework is flexible enough to permit different fairness notions, including demographic parity and equalized odds. In addition, our algorithm can be applied to non-binary classification tasks with multiple (non-binary) sensitive attributes. As a byproduct of our convergence analysis, we provide the first utility guarantee for a DP algorithm for solving nonconvex-strongly concave min-max problems. Our numerical experiments show that the proposed algorithm consistently offers significant performance gains over the state-of-the-art baselines, and can be applied to larger scale problems with non-binary target/sensitive attributes.
An Assessment of Safety-Based Driver Behavior Modeling in Microscopic Simulation Utilizing Real-Time Vehicle Trajectories
Oct 17, 2022



Accurate representation of observed driving behavior is critical for effectively evaluating safety and performance interventions in simulation modeling. In this study, we implement and evaluate a safety-based Optimal Velocity Model (OVM) to provide a high-fidelity replication of safety-critical behavior in microscopic simulation and showcase its implications for safety-focused assessments of traffic control strategies. A comprehensive simulation model is created for the site of study in PTV VISSIM utilizing detailed vehicle trajectory information extracted from real-time video inference, which are also used to calibrate the parameters of the safety-based OVM to replicate the observed driving behavior in the site of study. The calibrated model is then incorporated as an external driver model that overtakes VISSIM's default Wiedemann 74 model during simulated car-following episodes. The results of the preliminary analysis show the significant improvements achieved by using our model in replicating the existing safety conflicts observed at the site of the study. We then utilize this improved representation of the status quo to assess the potential impact of different scenarios of signal control and speed limit enforcement in reducing those existing conflicts by up to 23%. The results of this study showcase the considerable improvements that can be achieved by utilizing data-driven car-following behavior modeling, and the workflow presented provides an end-to-end, scalable, automated, and generalizable approach for replicating the existing driving behavior observed at a site of interest in microscopic simulation by utilizing vehicle trajectories efficiently extracted via roadside video inference.