 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Semantic Matching through Dependency-Enhanced Pre-trained Model with Adaptive Fusion
Oct 16, 2022
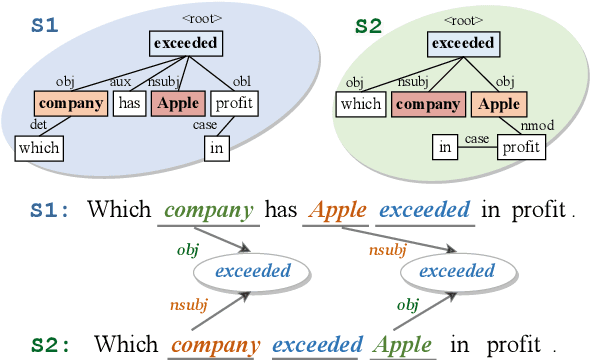
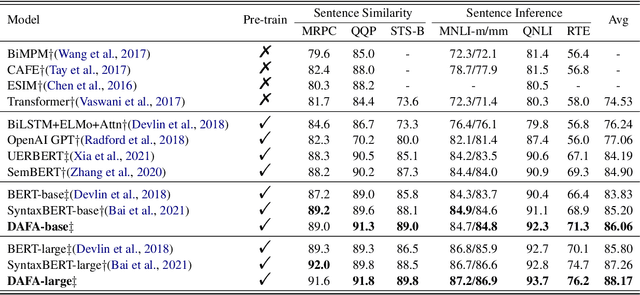
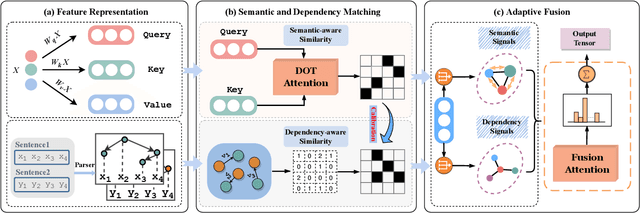
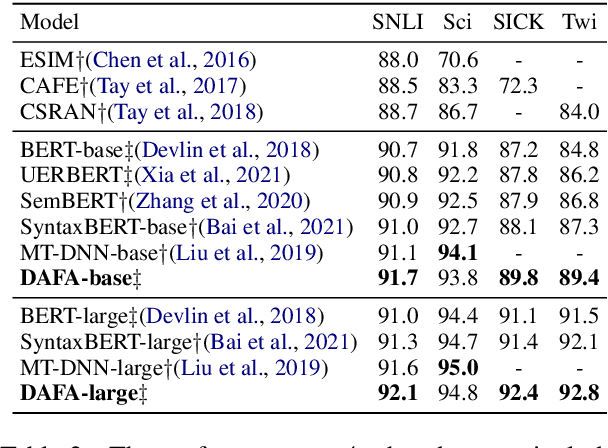
Transformer-based pre-trained models like BERT have achieved great progress on Semantic Sentence Matching. Meanwhile, dependency prior knowledge has also shown general benefits in multiple NLP tasks. However, how to efficiently integrate dependency prior structure into pre-trained models to better model complex semantic matching relations is still unsettled. In this paper, we propose the \textbf{D}ependency-Enhanced \textbf{A}daptive \textbf{F}usion \textbf{A}ttention (\textbf{DAFA}), which explicitly introduces dependency structure into pre-trained models and adaptively fuses it with semantic information. Specifically, \textbf{\emph{(i)}} DAFA first proposes a structure-sensitive paradigm to construct a dependency matrix for calibrating attention weights. It adopts an adaptive fusion module to integrate the obtained dependency information and the original semantic signals. Moreover, DAFA reconstructs the attention calculation flow and provides better interpretability. By applying it on BERT, our method achieves state-of-the-art or competitive performance on 10 public datasets, demonstrating the benefits of adaptively fusing dependency structure in semantic matching task.
U-HRNet: Delving into Improving Semantic Representation of High Resolution Network for Dense Prediction
Oct 13, 2022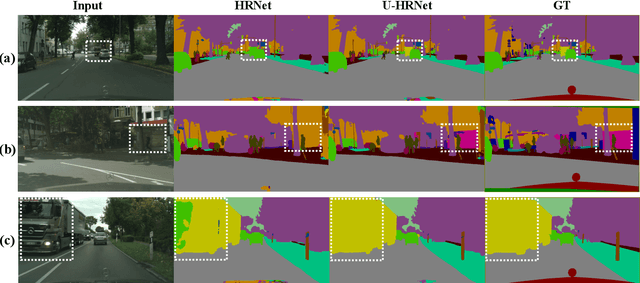

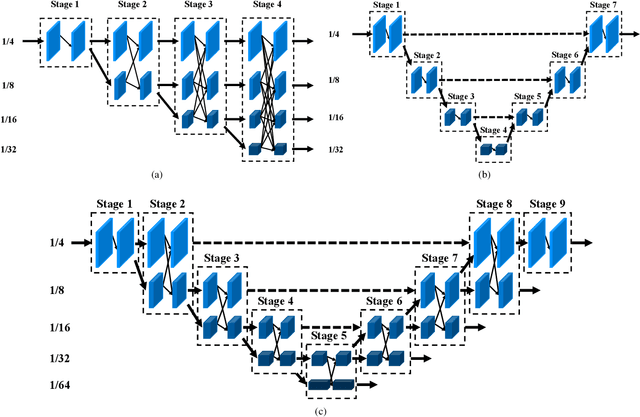
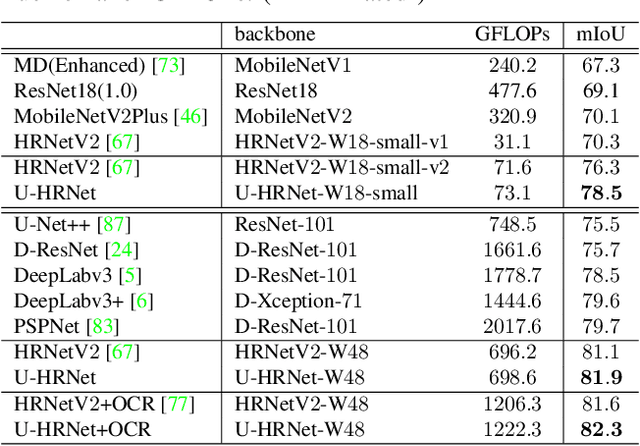
High resolution and advanced semantic representation are both vital for dense prediction. Empirically, low-resolution feature maps often achieve stronger semantic representation, and high-resolution feature maps generally can better identify local features such as edges, but contains weaker semantic information. Existing state-of-the-art frameworks such as HRNet has kept low-resolution and high-resolution feature maps in parallel, and repeatedly exchange the information across different resolutions. However, we believe that the lowest-resolution feature map often contains the strongest semantic information, and it is necessary to go through more layers to merge with high-resolution feature maps, while for high-resolution feature maps, the computational cost of each convolutional layer is very large, and there is no need to go through so many layers. Therefore, we designed a U-shaped High-Resolution Network (U-HRNet), which adds more stages after the feature map with strongest semantic representation and relaxes the constraint in HRNet that all resolutions need to be calculated parallel for a newly added stage. More calculations are allocated to low-resolution feature maps, which significantly improves the overall semantic representation. U-HRNet is a substitute for the HRNet backbone and can achieve significant improvement on multiple semantic segmentation and depth prediction datasets, under the exactly same training and inference setting, with almost no increasing in the amount of calculation. Code is available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
Unsupervised 3D Pose Transfer with Cross Consistency and Dual Reconstruction
Nov 18, 2022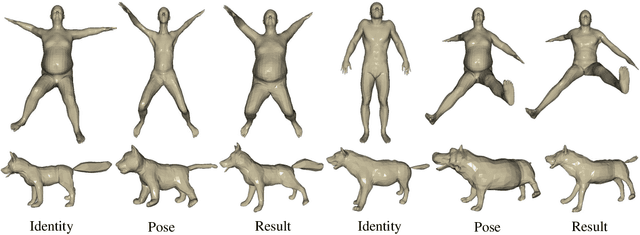
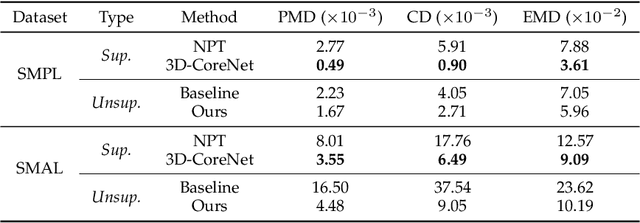
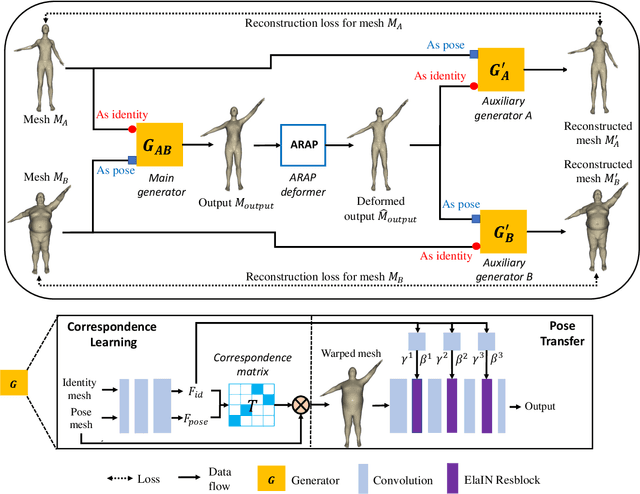
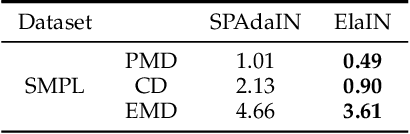
The goal of 3D pose transfer is to transfer the pose from the source mesh to the target mesh while preserving the identity information (e.g., face, body shape) of the target mesh. Deep learning-based methods improved the efficiency and performance of 3D pose transfer. However, most of them are trained under the supervision of the ground truth, whose availability is limited in real-world scenarios. In this work, we present X-DualNet, a simple yet effective approach that enables unsupervised 3D pose transfer. In X-DualNet, we introduce a generator $G$ which contains correspondence learning and pose transfer modules to achieve 3D pose transfer. We learn the shape correspondence by solving an optimal transport problem without any key point annotations and generate high-quality meshes with our elastic instance normalization (ElaIN) in the pose transfer module. With $G$ as the basic component, we propose a cross consistency learning scheme and a dual reconstruction objective to learn the pose transfer without supervision. Besides that, we also adopt an as-rigid-as-possible deformer in the training process to fine-tune the body shape of the generated results. Extensive experiments on human and animal data demonstrate that our framework can successfully achieve comparable performance as the state-of-the-art supervised approaches.
Where is my Wallet? Modeling Object Proposal Sets for Egocentric Visual Query Localization
Nov 18, 2022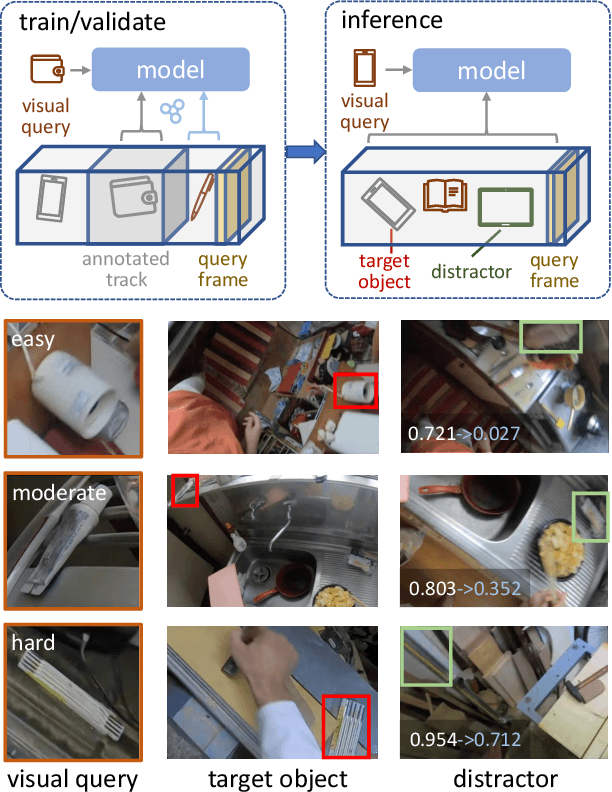
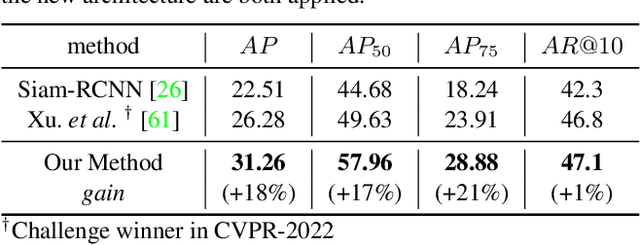
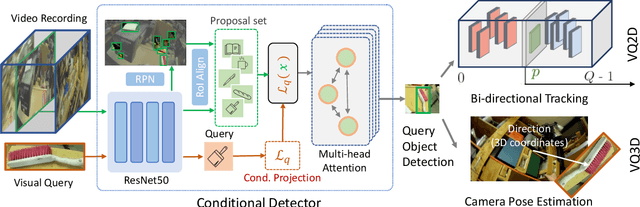
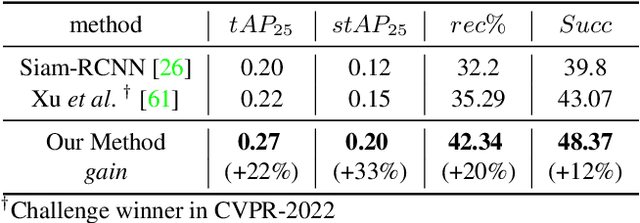
This paper deals with the problem of localizing objects in image and video datasets from visual exemplars. In particular, we focus on the challenging problem of egocentric visual query localization. We first identify grave implicit biases in current query-conditioned model design and visual query datasets. Then, we directly tackle such biases at both frame and object set levels. Concretely, our method solves these issues by expanding limited annotations and dynamically dropping object proposals during training. Additionally, we propose a novel transformer-based module that allows for object-proposal set context to be considered while incorporating query information. We name our module Conditioned Contextual Transformer or CocoFormer. Our experiments show the proposed adaptations improve egocentric query detection, leading to a better visual query localization system in both 2D and 3D configurations. Thus, we are able to improve frame-level detection performance from 26.28% to 31.26 in AP, which correspondingly improves the VQ2D and VQ3D localization scores by significant margins. Our improved context-aware query object detector ranked first and second in the VQ2D and VQ3D tasks in the 2nd Ego4D challenge. In addition to this, we showcase the relevance of our proposed model in the Few-Shot Detection (FSD) task, where we also achieve SOTA results. Our code is available at https://github.com/facebookresearch/vq2d_cvpr.
Beurling-Selberg Extremization for Dual-Blind Deconvolution Recovery in Joint Radar-Communications
Nov 18, 2022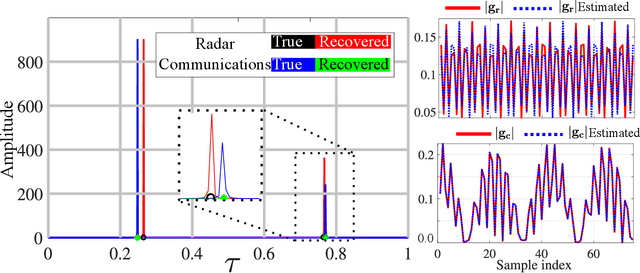

Recent interest in integrated sensing and communications has led to the design of novel signal processing techniques to recover information from an overlaid radar-communications signal. Here, we focus on a spectral coexistence scenario, wherein the channels and transmit signals of both radar and communications systems are unknown to the common receiver. In this dual-blind deconvolution (DBD) problem, the receiver admits a multi-carrier wireless communications signal that is overlaid with the radar signal reflected off multiple targets. The communications and radar channels are represented by continuous-valued range-times or delays corresponding to multiple transmission paths and targets, respectively. Prior works addressed recovery of unknown channels and signals in this ill-posed DBD problem through atomic norm minimization but contingent on individual minimum separation conditions for radar and communications channels. In this paper, we provide an optimal joint separation condition using extremal functions from the Beurling-Selberg interpolation theory. Thereafter, we formulate DBD as a low-rank modified Hankel matrix retrieval and solve it via nuclear norm minimization. We estimate the unknown target and communications parameters from the recovered low-rank matrix using multiple signal classification (MUSIC) method. We show that the joint separation condition also guarantees that the underlying Vandermonde matrix for MUSIC is well-conditioned. Numerical experiments validate our theoretical findings.
SeaTurtleID: A novel long-span dataset highlighting the importance of timestamps in wildlife re-identification
Nov 18, 2022
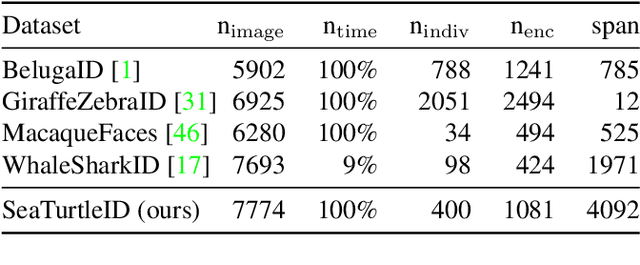

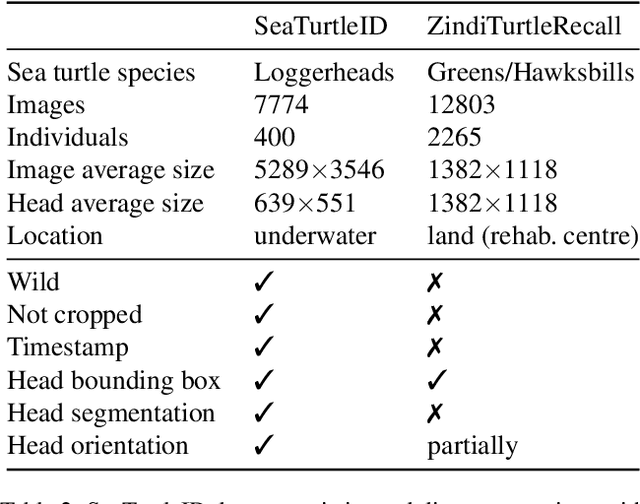
This paper introduces SeaTurtleID, the first public large-scale, long-span dataset with sea turtle photographs captured in the wild. The dataset is suitable for benchmarking re-identification methods and evaluating several other computer vision tasks. The dataset consists of 7774 high-resolution photographs of 400 unique individuals collected within 12 years in 1081 encounters. Each photograph is accompanied by rich metadata, e.g., identity label, head segmentation mask, and encounter timestamp. The 12-year span of the dataset makes it the longest-spanned public wild animal dataset with timestamps. By exploiting this unique property, we show that timestamps are necessary for an unbiased evaluation of animal re-identification methods because they allow time-aware splits of the dataset into reference and query sets. We show that time-unaware splits can lead to performance overestimation of more than 100% compared to the time-aware splits for both feature- and CNN-based re-identification methods. We also argue that time-aware splits correspond to more realistic re-identification pipelines than the time-unaware ones. We recommend that animal re-identification methods should only be tested on datasets with timestamps using time-aware splits, and we encourage dataset curators to include such information in the associated metadata.
Adaptive De-noising of Photoacoustic Signal and Image based on Modified Kalman Filter
Nov 18, 2022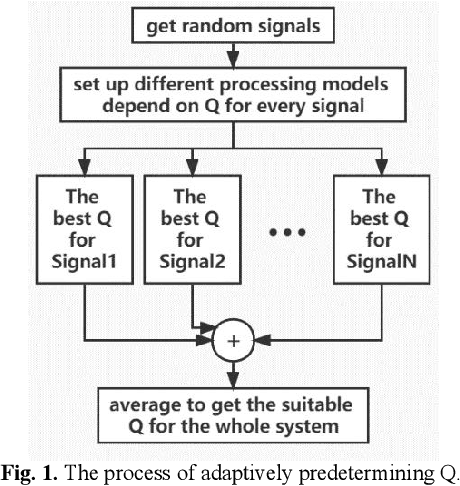
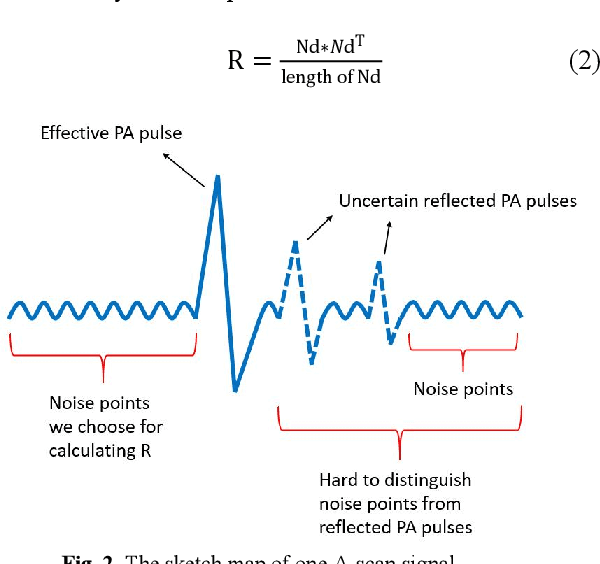
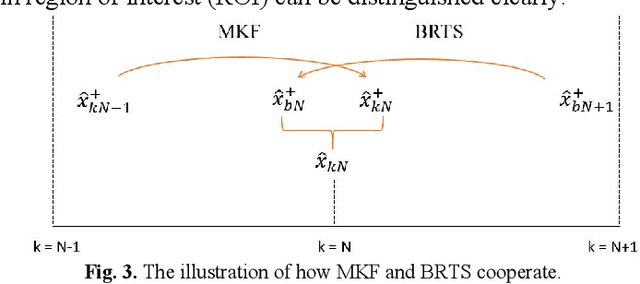
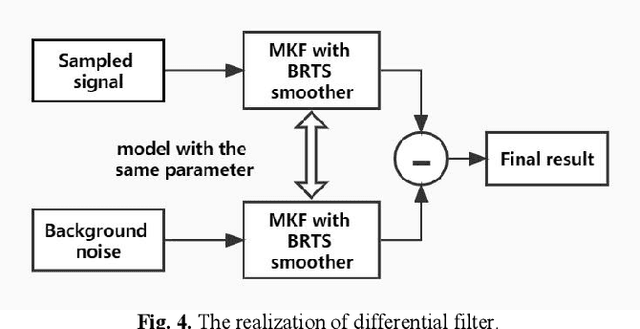
As a burgeoning medical imaging method based on hybrid fusion of light and ultrasound, photoacoustic imaging (PAI) has demonstrated high potential in various biomedical applications recently, especially in revealing the functional and molecular information to improve diagnostic accuracy. However, stemming from weak amplitude and unavoidable random noise, caused by limited laser power and severe attenuation in deep tissue imaging, PA signals are usually of low signal-to-noise ratio (SNR), and reconstructed PA images are of low quality. Despite that conventional Kalman Filter (KF) can remove Gaussian noise in time domain, it lacks adaptability in real-time estimating condition due to its fixed model. Moreover, KF-based de-noising algorithm has not been applied in PAI before. In this paper, we propose an adaptive Modified Kalman Filter (MKF) targeted at PAI de-noising by tuning system noise matrix Q and measurement noise matrix R in the conventional KF model. Additionally, in order to compensate the signal skewing caused by KF, we cascade the backward part of Rauch-Tung-Striebel smoother (BRTS), which also utilizes the newly determined Q. Finally, as a supplement, we add a commonly used differential filter to remove in-band reflection artifacts. Experimental results using phantom and ex vivo colorectal tissue are provided to prove the validity of the algorithm.
On-the-fly Object Detection using StyleGAN with CLIP Guidance
Oct 30, 2022
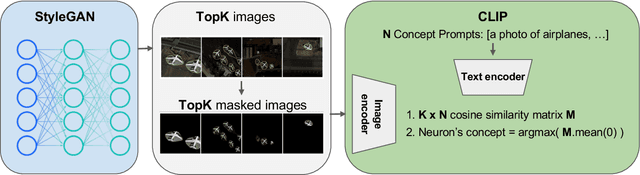

We present a fully automated framework for building object detectors on satellite imagery without requiring any human annotation or intervention. We achieve this by leveraging the combined power of modern generative models (e.g., StyleGAN) and recent advances in multi-modal learning (e.g., CLIP). While deep generative models effectively encode the key semantics pertinent to a data distribution, this information is not immediately accessible for downstream tasks, such as object detection. In this work, we exploit CLIP's ability to associate image features with text descriptions to identify neurons in the generator network, which are subsequently used to build detectors on-the-fly.
The Importance of Future Information in Credit Card Fraud Detection
Apr 11, 2022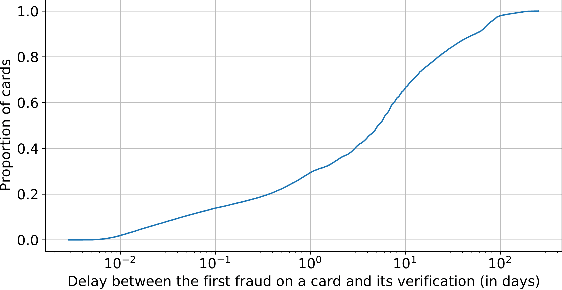
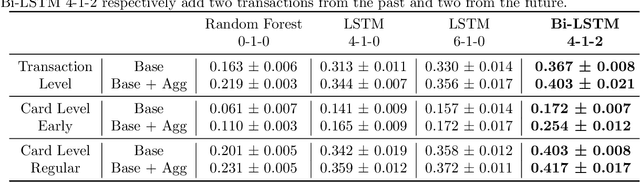
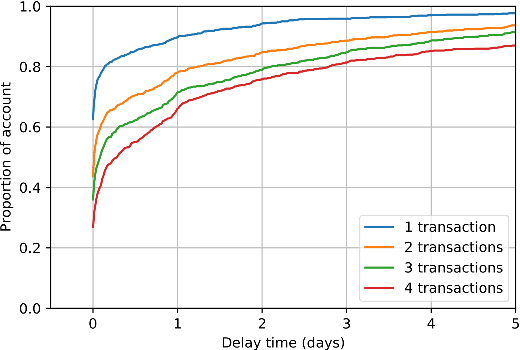
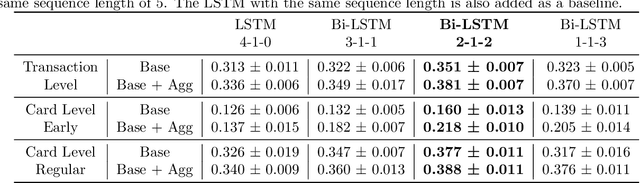
Fraud detection systems (FDS) mainly perform two tasks: (i) real-time detection while the payment is being processed and (ii) posterior detection to block the card retrospectively and avoid further frauds. Since human verification is often necessary and the payment processing time is limited, the second task manages the largest volume of transactions. In the literature, fraud detection challenges and algorithms performance are widely studied but the very formulation of the problem is never disrupted: it aims at predicting if a transaction is fraudulent based on its characteristics and the past transactions of the cardholder. Yet, in posterior detection, verification often takes days, so new payments on the card become available before a decision is taken. This is our motivation to propose a new paradigm: posterior fraud detection with "future" information. We start by providing evidence of the on-time availability of subsequent transactions, usable as extra context to improve detection. We then design a Bidirectional LSTM to make use of these transactions. On a real-world dataset with over 30 million transactions, it achieves higher performance than a regular LSTM, which is the state-of-the-art classifier for fraud detection that only uses the past context. We also introduce new metrics to show that the proposal catches more frauds, more compromised cards, and based on their earliest frauds. We believe that future works on this new paradigm will have a significant impact on the detection of compromised cards.
Photonic Quantum Computing For Polymer Classification
Nov 22, 2022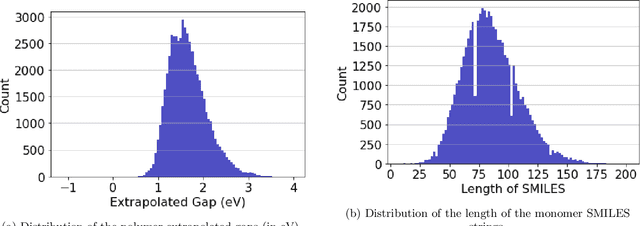
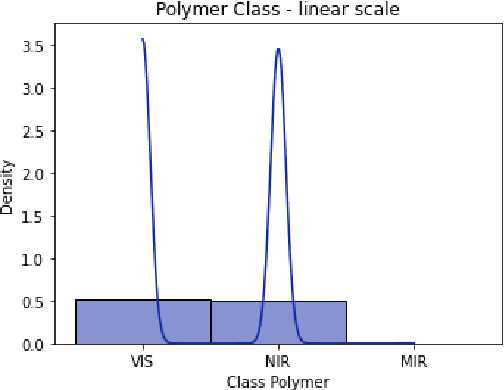
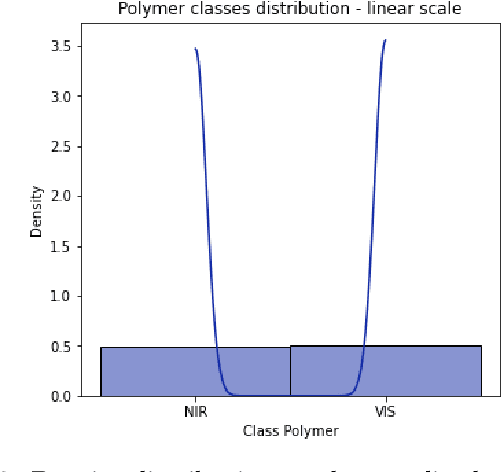
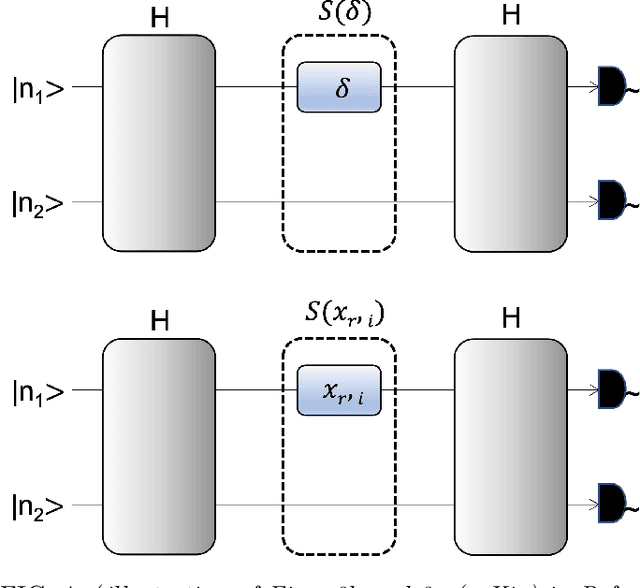
We present a hybrid classical-quantum approach to the binary classification of polymer structures. Two polymer classes visual (VIS) and near-infrared (NIR) are defined based on the size of the polymer gaps. The hybrid approach combines one of the three methods, Gaussian Kernel Method, Quantum-Enhanced Random Kitchen Sinks or Variational Quantum Classifier, implemented by linear quantum photonic circuits (LQPCs), with a classical deep neural network (DNN) feature extractor. The latter extracts from the classical data information about samples chemical structure. It also reduces the data dimensions yielding compact 2-dimensional data vectors that are then fed to the LQPCs. We adopt the photonic-based data-embedding scheme, proposed by Gan et al. [EPJ Quantum Technol. 9, 16 (2022)] to embed the classical 2-dimensional data vectors into the higher-dimensional Fock space. This hybrid classical-quantum strategy permits to obtain accurate noisy intermediate-scale quantum-compatible classifiers by leveraging Fock states with only a few photons. The models obtained using either of the three hybrid methods successfully classified the VIS and NIR polymers. Their accuracy is comparable as measured by their scores ranging from 0.86 to 0.88. These findings demonstrate that our hybrid approach that uses photonic quantum computing captures chemistry and structure-property correlation patterns in real polymer data. They also open up perspectives of employing quantum computing to complex chemical structures when a larger number of logical qubits is available.