 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BiVRec: Bidirectional View-based Multimodal Sequential Recommendation
Mar 05, 2024
The integration of multimodal information into sequential recommender systems has attracted significant attention in recent research. In the initial stages of multimodal sequential recommendation models, the mainstream paradigm was ID-dominant recommendations, wherein multimodal information was fused as side information. However, due to their limitations in terms of transferability and information intrusion, another paradigm emerged, wherein multimodal features were employed directly for recommendation, enabling recommendation across datasets. Nonetheless, it overlooked user ID information, resulting in low information utilization and high training costs. To this end, we propose an innovative framework, BivRec, that jointly trains the recommendation tasks in both ID and multimodal views, leveraging their synergistic relationship to enhance recommendation performance bidirectionally. To tackle the information heterogeneity issue, we first construct structured user interest representations and then learn the synergistic relationship between them. Specifically, BivRec comprises three modules: Multi-scale Interest Embedding, comprehensively modeling user interests by expanding user interaction sequences with multi-scale patching; Intra-View Interest Decomposition, constructing highly structured interest representations using carefully designed Gaussian attention and Cluster attention; and Cross-View Interest Learning, learning the synergistic relationship between the two recommendation views through coarse-grained overall semantic similarity and fine-grained interest allocation similarity BiVRec achieves state-of-the-art performance on five datasets and showcases various practical advantages.
XPSR: Cross-modal Priors for Diffusion-based Image Super-Resolution
Mar 08, 2024
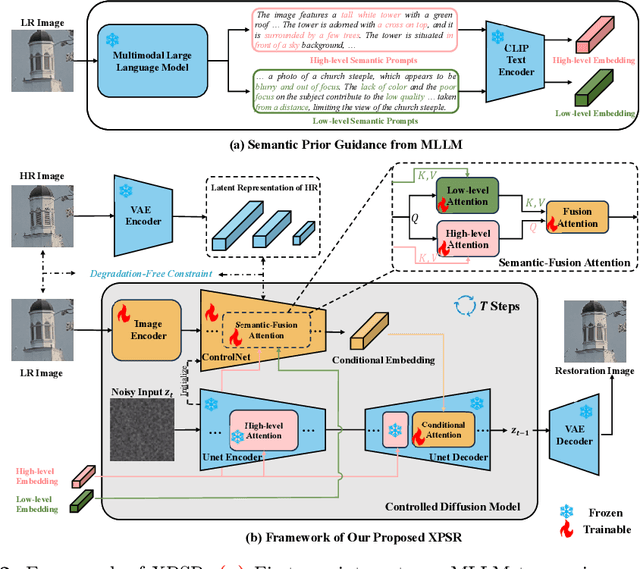
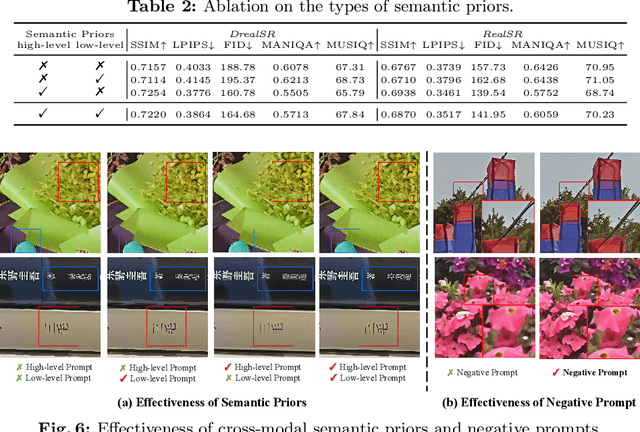
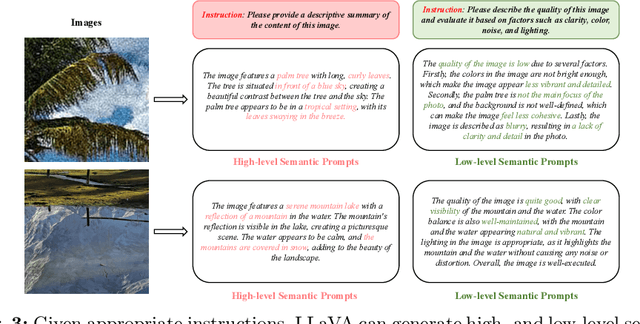
Diffusion-based methods, endowed with a formidable generative prior, have received increasing attention in Image Super-Resolution (ISR) recently. However, as low-resolution (LR) images often undergo severe degradation, it is challenging for ISR models to perceive the semantic and degradation information, resulting in restoration images with incorrect content or unrealistic artifacts. To address these issues, we propose a \textit{Cross-modal Priors for Super-Resolution (XPSR)} framework. Within XPSR, to acquire precise and comprehensive semantic conditions for the diffusion model, cutting-edge Multimodal Large Language Models (MLLMs) are utilized. To facilitate better fusion of cross-modal priors, a \textit{Semantic-Fusion Attention} is raised. To distill semantic-preserved information instead of undesired degradations, a \textit{Degradation-Free Constraint} is attached between LR and its high-resolution (HR) counterpart. Quantitative and qualitative results show that XPSR is capable of generating high-fidelity and high-realism images across synthetic and real-world datasets. Codes will be released at \url{https://github.com/qyp2000/XPSR}.
Rethinking Information Structures in RLHF: Reward Generalization from a Graph Theory Perspective
Feb 20, 2024There is a trilemma in reinforcement learning from human feedback (RLHF): the incompatibility between highly diverse contexts, low labeling cost, and reliable alignment performance. Here we aim to mitigate such incompatibility through the design of dataset information structures during reward modeling, and meanwhile propose new, generalizable methods of analysis that have wider applications, including potentially shedding light on goal misgeneralization. Specifically, we first reexamine the RLHF process and propose a theoretical framework portraying it as an autoencoding process over text distributions. Our framework formalizes the RLHF objective of ensuring distributional consistency between human preference and large language model (LLM) behavior. Based on this framework, we introduce a new method to model generalization in the reward modeling stage of RLHF, the induced Bayesian network (IBN). Drawing from random graph theory and causal analysis, it enables empirically grounded derivation of generalization error bounds, a key improvement over classical methods of generalization analysis. An insight from our analysis is the superiority of the tree-based information structure in reward modeling, compared to chain-based baselines in conventional RLHF methods. We derive that in complex contexts with limited data, the tree-based reward model (RM) induces up to $\Theta(\log n/\log\log n)$ times less variance than chain-based RM where $n$ is the dataset size. As validation, we demonstrate that on three NLP tasks, the tree-based RM achieves 65% win rate on average against chain-based baselines. Looking ahead, we hope to extend the IBN analysis to help understand the phenomenon of goal misgeneralization.
Forest Inspection Dataset for Aerial Semantic Segmentation and Depth Estimation
Mar 11, 2024

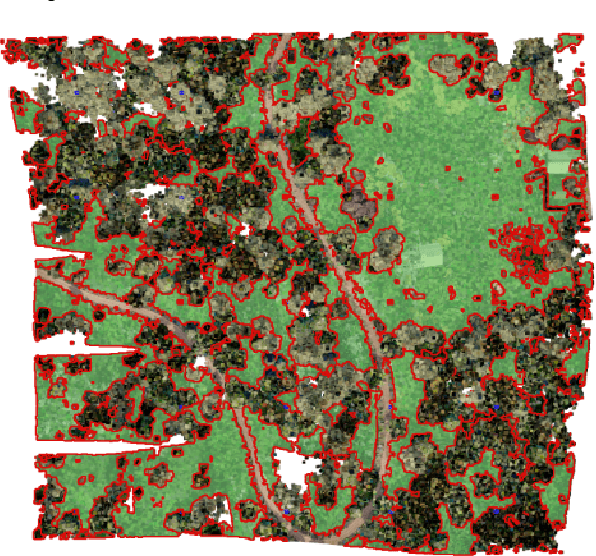
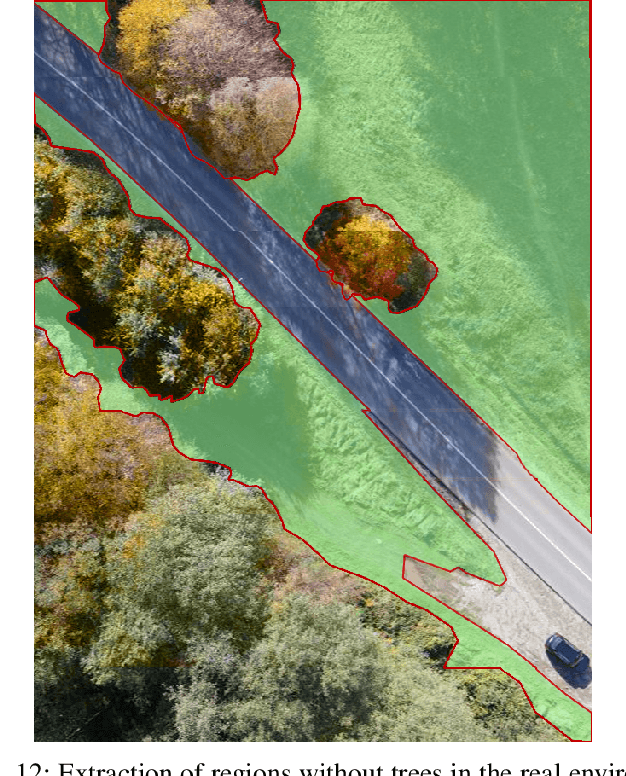
Humans use UAVs to monitor changes in forest environments since they are lightweight and provide a large variety of surveillance data. However, their information does not present enough details for understanding the scene which is needed to assess the degree of deforestation. Deep learning algorithms must be trained on large amounts of data to output accurate interpretations, but ground truth recordings of annotated forest imagery are not available. To solve this problem, we introduce a new large aerial dataset for forest inspection which contains both real-world and virtual recordings of natural environments, with densely annotated semantic segmentation labels and depth maps, taken in different illumination conditions, at various altitudes and recording angles. We test the performance of two multi-scale neural networks for solving the semantic segmentation task (HRNet and PointFlow network), studying the impact of the various acquisition conditions and the capabilities of transfer learning from virtual to real data. Our results showcase that the best results are obtained when the training is done on a dataset containing a large variety of scenarios, rather than separating the data into specific categories. We also develop a framework to assess the deforestation degree of an area.
Efficient LoFTR: Semi-Dense Local Feature Matching with Sparse-Like Speed
Mar 11, 2024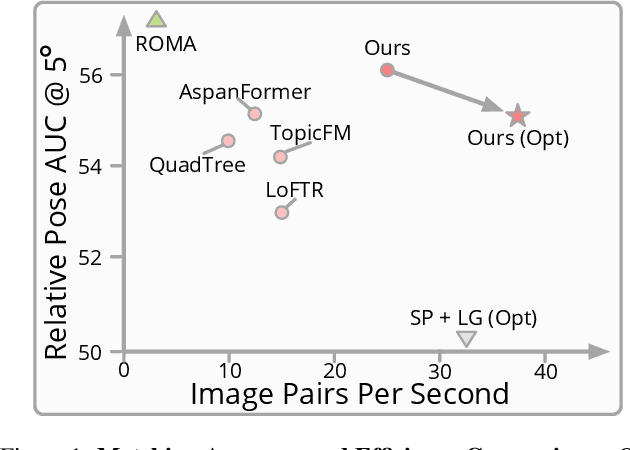
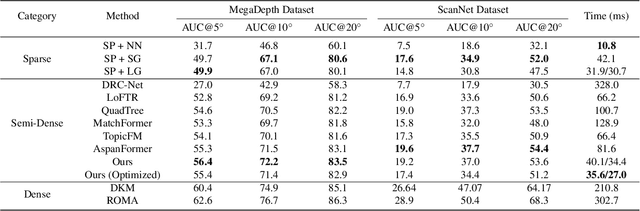
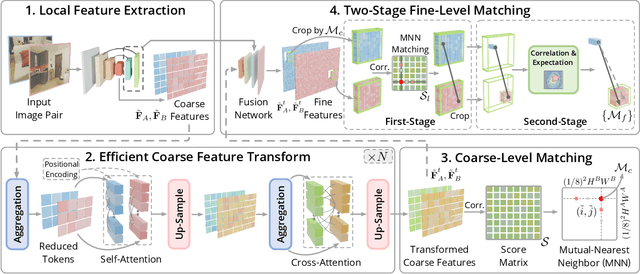
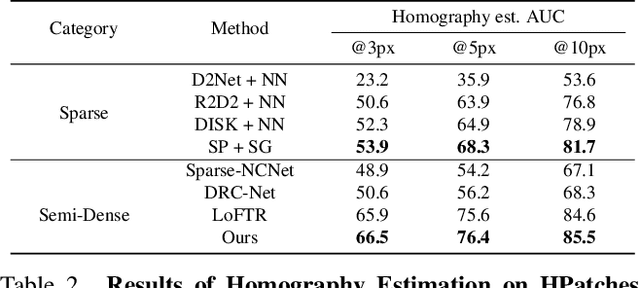
We present a novel method for efficiently producing semi-dense matches across images. Previous detector-free matcher LoFTR has shown remarkable matching capability in handling large-viewpoint change and texture-poor scenarios but suffers from low efficiency. We revisit its design choices and derive multiple improvements for both efficiency and accuracy. One key observation is that performing the transformer over the entire feature map is redundant due to shared local information, therefore we propose an aggregated attention mechanism with adaptive token selection for efficiency. Furthermore, we find spatial variance exists in LoFTR's fine correlation module, which is adverse to matching accuracy. A novel two-stage correlation layer is proposed to achieve accurate subpixel correspondences for accuracy improvement. Our efficiency optimized model is $\sim 2.5\times$ faster than LoFTR which can even surpass state-of-the-art efficient sparse matching pipeline SuperPoint + LightGlue. Moreover, extensive experiments show that our method can achieve higher accuracy compared with competitive semi-dense matchers, with considerable efficiency benefits. This opens up exciting prospects for large-scale or latency-sensitive applications such as image retrieval and 3D reconstruction. Project page: https://zju3dv.github.io/efficientloftr.
Stochastic Cortical Self-Reconstruction
Mar 11, 2024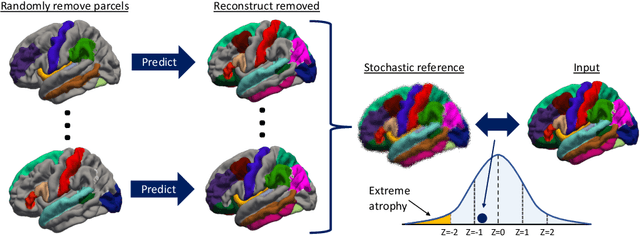
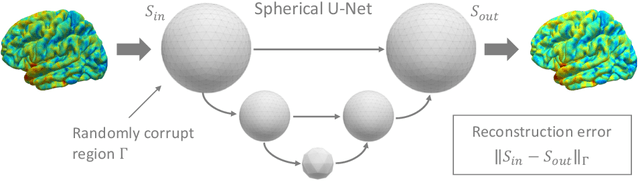
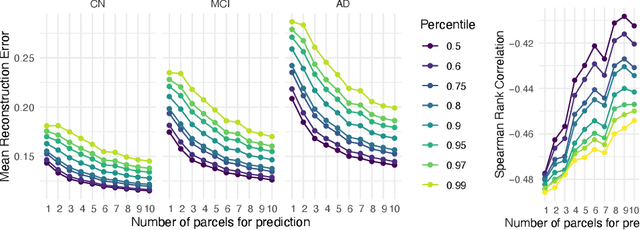
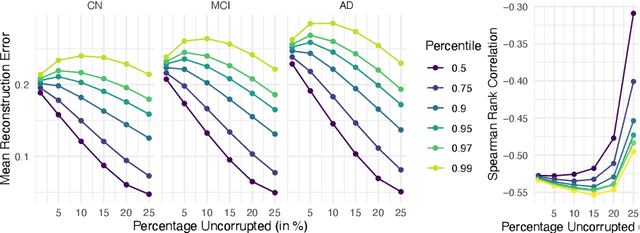
Magnetic resonance imaging (MRI) is critical for diagnosing neurodegenerative diseases, yet accurately assessing mild cortical atrophy remains a challenge due to its subtlety. Automated cortex reconstruction, paired with healthy reference ranges, aids in pinpointing pathological atrophy, yet their generalization is limited by biases from image acquisition and processing. We introduce the concept of stochastic cortical self-reconstruction (SCSR) that creates a subject-specific healthy reference by taking MRI-derived thicknesses as input and, therefore, implicitly accounting for potential confounders. SCSR randomly corrupts parts of the cortex and self-reconstructs them from the remaining information. Trained exclusively on healthy individuals, repeated self-reconstruction generates a stochastic reference cortex for assessing deviations from the norm. We present three implementations of this concept: XGBoost applied on parcels, and two autoencoders on vertex level -- one based on a multilayer perceptron and the other using a spherical U-Net. These models were trained on healthy subjects from the UK Biobank and subsequently evaluated across four public Alzheimer's datasets. Finally, we deploy the model on clinical in-house data, where deviation maps' high spatial resolution aids in discriminating between four types of dementia.
MedKP: Medical Dialogue with Knowledge Enhancement and Clinical Pathway Encoding
Mar 11, 2024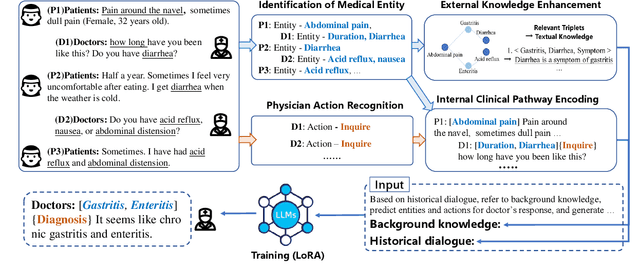
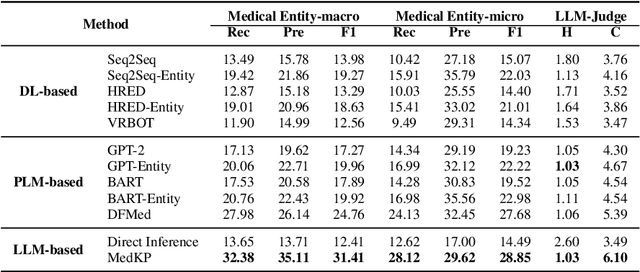

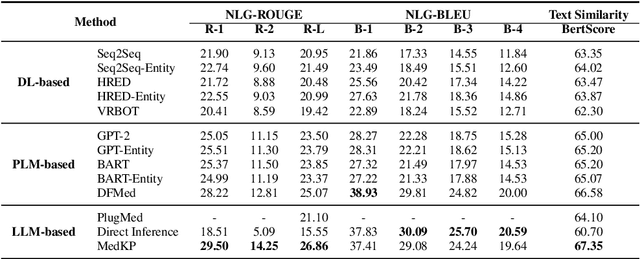
With appropriate data selection and training techniques, Large Language Models (LLMs) have demonstrated exceptional success in various medical examinations and multiple-choice questions. However, the application of LLMs in medical dialogue generation-a task more closely aligned with actual medical practice-has been less explored. This gap is attributed to the insufficient medical knowledge of LLMs, which leads to inaccuracies and hallucinated information in the generated medical responses. In this work, we introduce the Medical dialogue with Knowledge enhancement and clinical Pathway encoding (MedKP) framework, which integrates an external knowledge enhancement module through a medical knowledge graph and an internal clinical pathway encoding via medical entities and physician actions. Evaluated with comprehensive metrics, our experiments on two large-scale, real-world online medical consultation datasets (MedDG and KaMed) demonstrate that MedKP surpasses multiple baselines and mitigates the incidence of hallucinations, achieving a new state-of-the-art. Extensive ablation studies further reveal the effectiveness of each component of MedKP. This enhancement advances the development of reliable, automated medical consultation responses using LLMs, thereby broadening the potential accessibility of precise and real-time medical assistance.
STARFlow: Spatial Temporal Feature Re-embedding with Attentive Learning for Real-world Scene Flow
Mar 11, 2024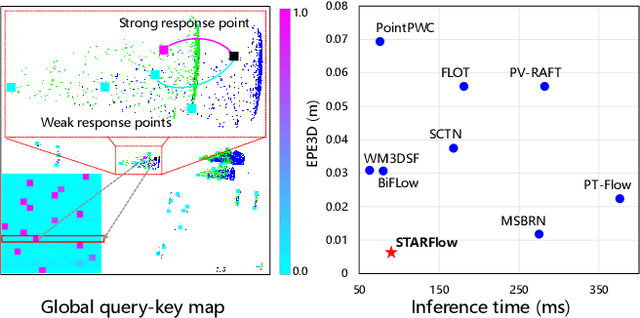
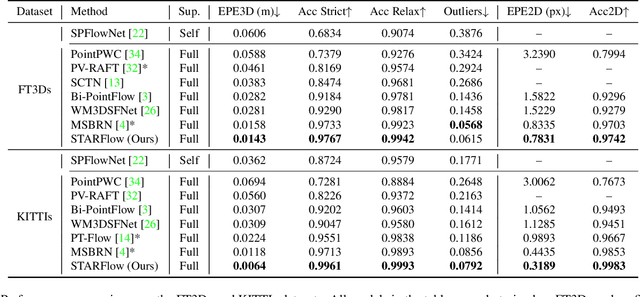
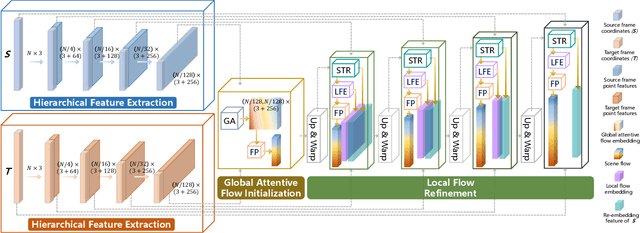
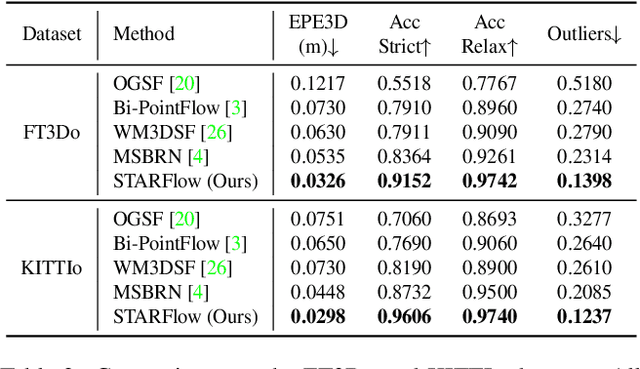
Scene flow prediction is a crucial underlying task in understanding dynamic scenes as it offers fundamental motion information. However, contemporary scene flow methods encounter three major challenges. Firstly, flow estimation solely based on local receptive fields lacks long-dependency matching of point pairs. To address this issue, we propose global attentive flow embedding to match all-to-all point pairs in both feature space and Euclidean space, providing global initialization before local refinement. Secondly, there are deformations existing in non-rigid objects after warping, which leads to variations in the spatiotemporal relation between the consecutive frames. For a more precise estimation of residual flow, a spatial temporal feature re-embedding module is devised to acquire the sequence features after deformation. Furthermore, previous methods perform poor generalization due to the significant domain gap between the synthesized and LiDAR-scanned datasets. We leverage novel domain adaptive losses to effectively bridge the gap of motion inference from synthetic to real-world. Experiments demonstrate that our approach achieves state-of-the-art performance across various datasets, with particularly outstanding results on real-world LiDAR-scanned datasets. Our code is available at https://github.com/O-VIGIA/StarFlow.
MRL Parsing Without Tears: The Case of Hebrew
Mar 11, 2024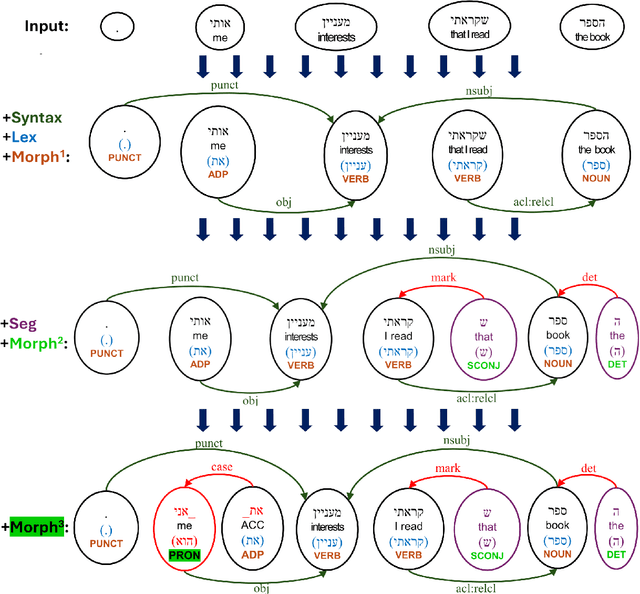
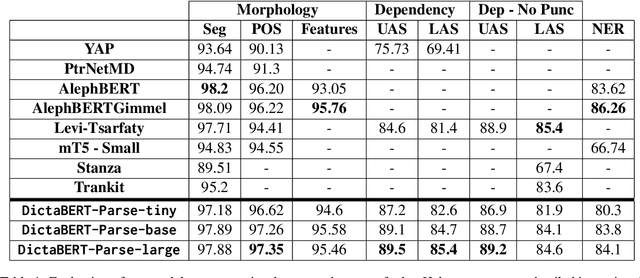
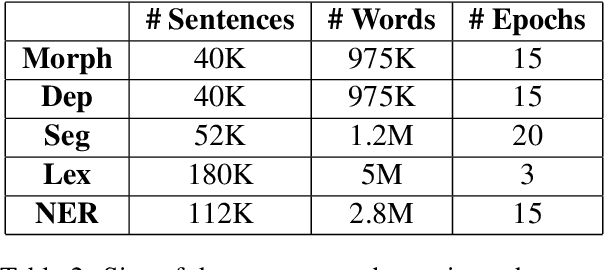
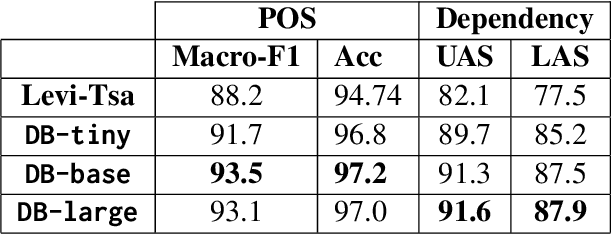
Syntactic parsing remains a critical tool for relation extraction and information extraction, especially in resource-scarce languages where LLMs are lacking. Yet in morphologically rich languages (MRLs), where parsers need to identify multiple lexical units in each token, existing systems suffer in latency and setup complexity. Some use a pipeline to peel away the layers: first segmentation, then morphology tagging, and then syntax parsing; however, errors in earlier layers are then propagated forward. Others use a joint architecture to evaluate all permutations at once; while this improves accuracy, it is notoriously slow. In contrast, and taking Hebrew as a test case, we present a new "flipped pipeline": decisions are made directly on the whole-token units by expert classifiers, each one dedicated to one specific task. The classifiers are independent of one another, and only at the end do we synthesize their predictions. This blazingly fast approach sets a new SOTA in Hebrew POS tagging and dependency parsing, while also reaching near-SOTA performance on other Hebrew NLP tasks. Because our architecture does not rely on any language-specific resources, it can serve as a model to develop similar parsers for other MRLs.
Dual-path Frequency Discriminators for Few-shot Anomaly Detection
Mar 11, 2024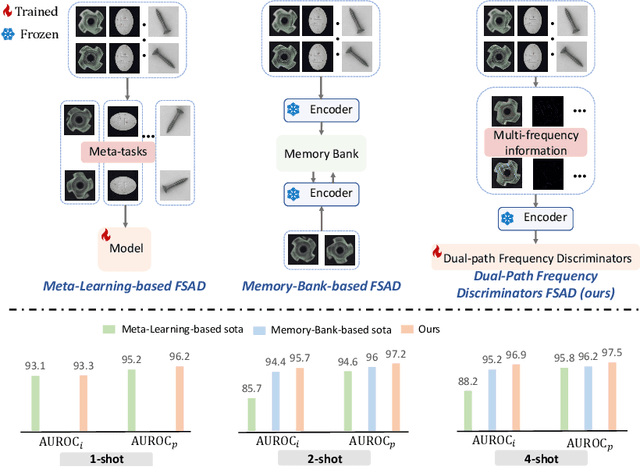
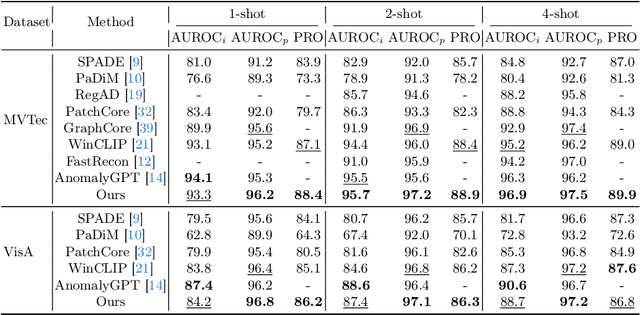
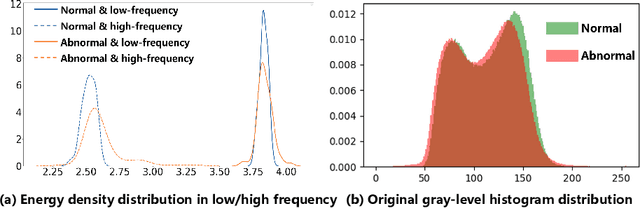
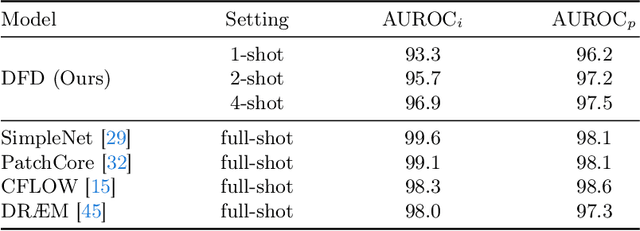
Few-shot anomaly detection (FSAD) is essential in industrial manufacturing. However, existing FSAD methods struggle to effectively leverage a limited number of normal samples, and they may fail to detect and locate inconspicuous anomalies in the spatial domain. We further discover that these subtle anomalies would be more noticeable in the frequency domain. In this paper, we propose a Dual-Path Frequency Discriminators (DFD) network from a frequency perspective to tackle these issues. Specifically, we generate anomalies at both image-level and feature-level. Differential frequency components are extracted by the multi-frequency information construction module and supplied into the fine-grained feature construction module to provide adapted features. We consider anomaly detection as a discriminative classification problem, wherefore the dual-path feature discrimination module is employed to detect and locate the image-level and feature-level anomalies in the feature space. The discriminators aim to learn a joint representation of anomalous features and normal features in the latent space. Extensive experiments conducted on MVTec AD and VisA benchmarks demonstrate that our DFD surpasses current state-of-the-art methods. Source code will be available.