 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTanDepth: Leveraging Global DEMs for Metric Monocular Depth Estimation in UAVs
Sep 08, 2024Aerial scene understanding systems face stringent payload restrictions and must often rely on monocular depth estimation for modelling scene geometry, which is an inherently ill-posed problem. Moreover, obtaining accurate ground truth data required by learning-based methods raises significant additional challenges in the aerial domain. Self-supervised approaches can bypass this problem, at the cost of providing only up-to-scale results. Similarly, recent supervised solutions which make good progress towards zero-shot generalization also provide only relative depth values. This work presents TanDepth, a practical, online scale recovery method for obtaining metric depth results from relative estimations at inference-time, irrespective of the type of model generating them. Tailored for Unmanned Aerial Vehicle (UAV) applications, our method leverages sparse measurements from Global Digital Elevation Models (GDEM) by projecting them to the camera view using extrinsic and intrinsic information. An adaptation to the Cloth Simulation Filter is presented, which allows selecting ground points from the estimated depth map to then correlate with the projected reference points. We evaluate and compare our method against alternate scaling methods adapted for UAVs, on a variety of real-world scenes. Considering the limited availability of data for this domain, we construct and release a comprehensive, depth-focused extension to the popular UAVid dataset to further research.
Forest Inspection Dataset for Aerial Semantic Segmentation and Depth Estimation
Mar 11, 2024Humans use UAVs to monitor changes in forest environments since they are lightweight and provide a large variety of surveillance data. However, their information does not present enough details for understanding the scene which is needed to assess the degree of deforestation. Deep learning algorithms must be trained on large amounts of data to output accurate interpretations, but ground truth recordings of annotated forest imagery are not available. To solve this problem, we introduce a new large aerial dataset for forest inspection which contains both real-world and virtual recordings of natural environments, with densely annotated semantic segmentation labels and depth maps, taken in different illumination conditions, at various altitudes and recording angles. We test the performance of two multi-scale neural networks for solving the semantic segmentation task (HRNet and PointFlow network), studying the impact of the various acquisition conditions and the capabilities of transfer learning from virtual to real data. Our results showcase that the best results are obtained when the training is done on a dataset containing a large variety of scenarios, rather than separating the data into specific categories. We also develop a framework to assess the deforestation degree of an area.
MonoDVPS: A Self-Supervised Monocular Depth Estimation Approach to Depth-aware Video Panoptic Segmentation
Oct 14, 2022


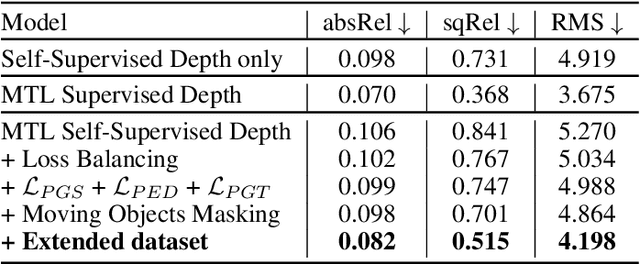
Depth-aware video panoptic segmentation tackles the inverse projection problem of restoring panoptic 3D point clouds from video sequences, where the 3D points are augmented with semantic classes and temporally consistent instance identifiers. We propose a novel solution with a multi-task network that performs monocular depth estimation and video panoptic segmentation. Since acquiring ground truth labels for both depth and image segmentation has a relatively large cost, we leverage the power of unlabeled video sequences with self-supervised monocular depth estimation and semi-supervised learning from pseudo-labels for video panoptic segmentation. To further improve the depth prediction, we introduce panoptic-guided depth losses and a novel panoptic masking scheme for moving objects to avoid corrupting the training signal. Extensive experiments on the Cityscapes-DVPS and SemKITTI-DVPS datasets demonstrate that our model with the proposed improvements achieves competitive results and fast inference speed.
Time-Space Transformers for Video Panoptic Segmentation
Oct 07, 2022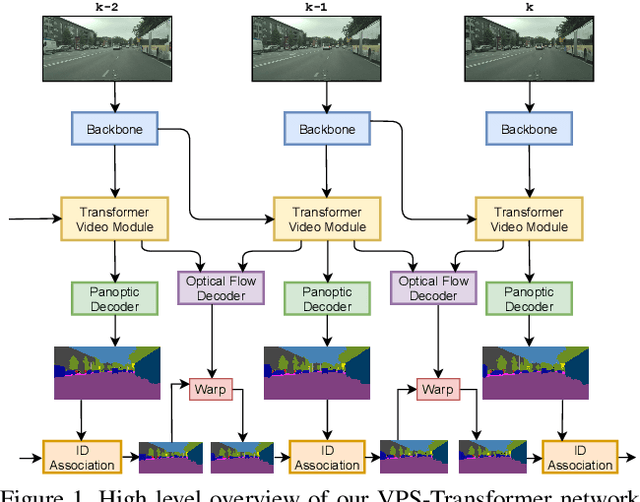
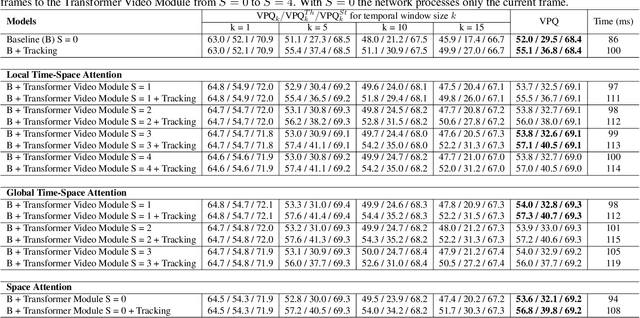
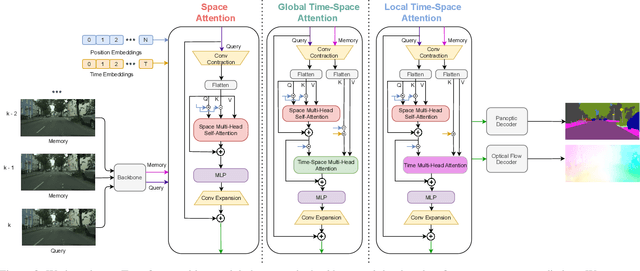
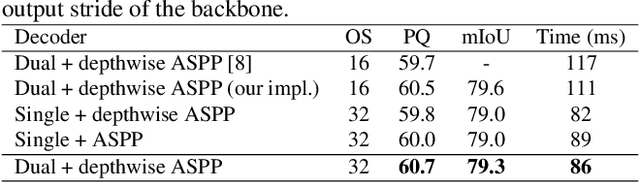
We propose a novel solution for the task of video panoptic segmentation, that simultaneously predicts pixel-level semantic and instance segmentation and generates clip-level instance tracks. Our network, named VPS-Transformer, with a hybrid architecture based on the state-of-the-art panoptic segmentation network Panoptic-DeepLab, combines a convolutional architecture for single-frame panoptic segmentation and a novel video module based on an instantiation of the pure Transformer block. The Transformer, equipped with attention mechanisms, models spatio-temporal relations between backbone output features of current and past frames for more accurate and consistent panoptic estimates. As the pure Transformer block introduces large computation overhead when processing high resolution images, we propose a few design changes for a more efficient compute. We study how to aggregate information more effectively over the space-time volume and we compare several variants of the Transformer block with different attention schemes. Extensive experiments on the Cityscapes-VPS dataset demonstrate that our best model improves the temporal consistency and video panoptic quality by a margin of 2.2%, with little extra computation.