 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decoupled Cross-Scale Cross-View Interaction for Stereo Image Enhancement in The Dark
Nov 12, 2022
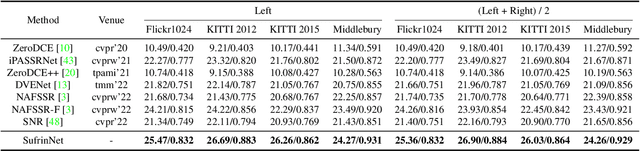
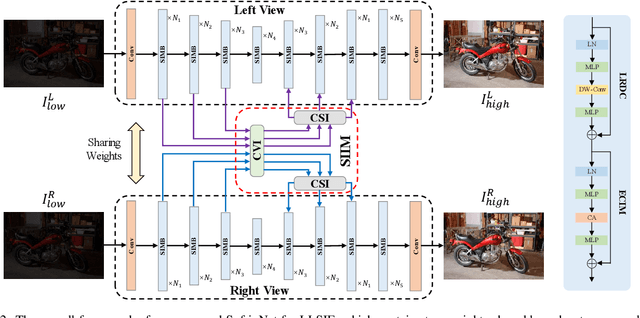
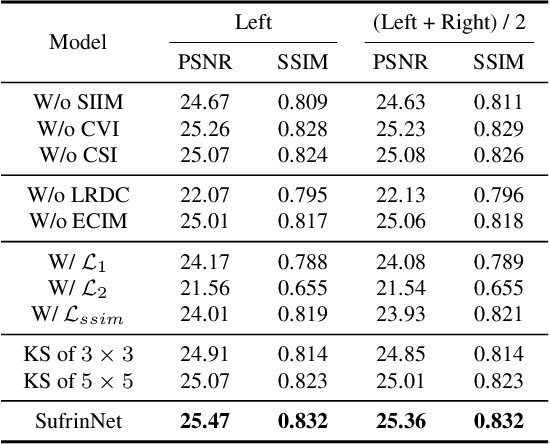
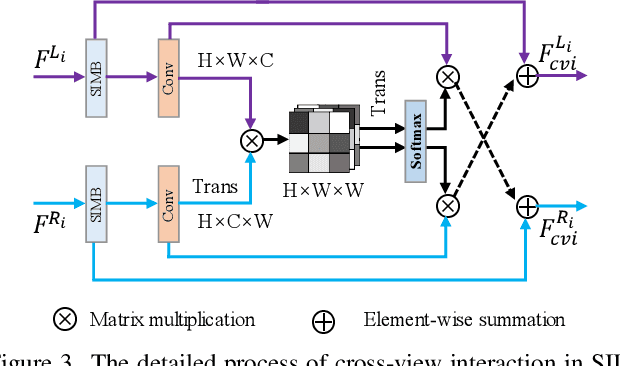
Low-light stereo image enhancement (LLSIE) is a relatively new task to enhance the quality of visually unpleasant stereo images captured in dark condition. However, current methods achieve inferior performance on detail recovery and illumination adjustment. We find it is because: 1) the insufficient single-scale inter-view interaction makes the cross-view cues unable to be fully exploited; 2) lacking long-range dependency leads to the inability to deal with the spatial long-range effects caused by illumination degradation. To alleviate such limitations, we propose a LLSIE model termed Decoupled Cross-scale Cross-view Interaction Network (DCI-Net). Specifically, we present a decoupled interaction module (DIM) that aims for sufficient dual-view information interaction. DIM decouples the dual-view information exchange into discovering multi-scale cross-view correlations and further exploring cross-scale information flow. Besides, we present a spatial-channel information mining block (SIMB) for intra-view feature extraction, and the benefits are twofold. One is the long-range dependency capture to build spatial long-range relationship, and the other is expanded channel information refinement that enhances information flow in channel dimension. Extensive experiments on Flickr1024, KITTI 2012, KITTI 2015 and Middlebury datasets show that our method obtains better illumination adjustment and detail recovery, and achieves SOTA performance compared to other related methods. Our codes, datasets and models will be publicly available.
ViewNet: Unsupervised Viewpoint Estimation from Conditional Generation
Dec 01, 2022
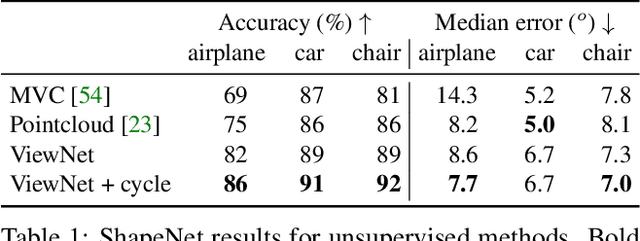
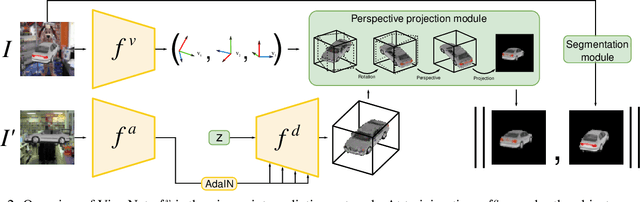
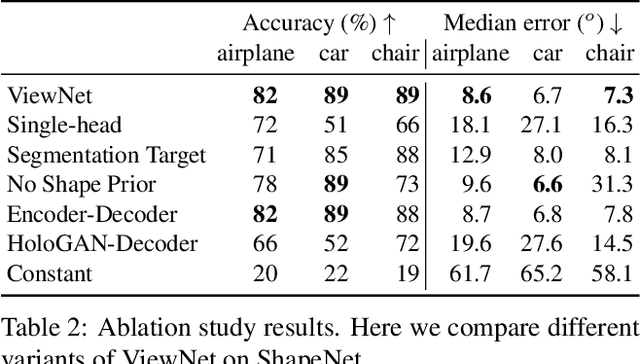
Understanding the 3D world without supervision is currently a major challenge in computer vision as the annotations required to supervise deep networks for tasks in this domain are expensive to obtain on a large scale. In this paper, we address the problem of unsupervised viewpoint estimation. We formulate this as a self-supervised learning task, where image reconstruction provides the supervision needed to predict the camera viewpoint. Specifically, we make use of pairs of images of the same object at training time, from unknown viewpoints, to self-supervise training by combining the viewpoint information from one image with the appearance information from the other. We demonstrate that using a perspective spatial transformer allows efficient viewpoint learning, outperforming existing unsupervised approaches on synthetic data, and obtains competitive results on the challenging PASCAL3D+ dataset.
Applications of Lattice Gauge Equivariant Neural Networks
Dec 01, 2022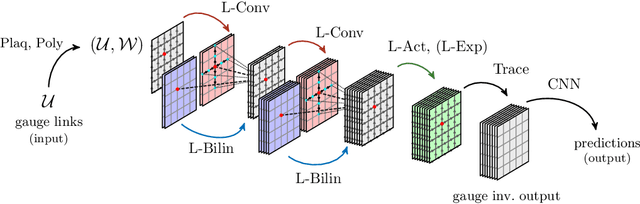
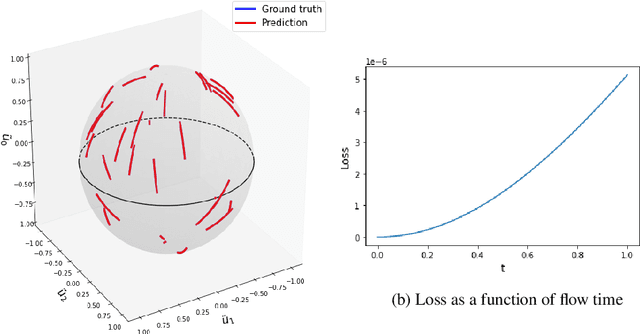
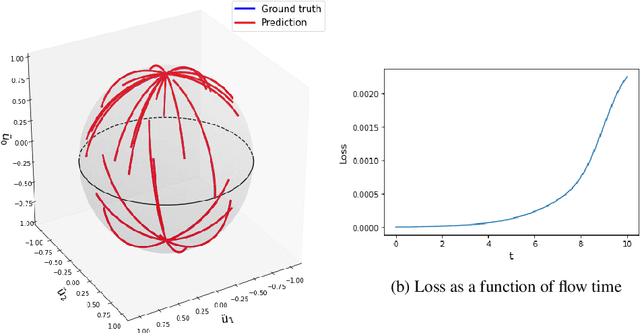
The introduction of relevant physical information into neural network architectures has become a widely used and successful strategy for improving their performance. In lattice gauge theories, such information can be identified with gauge symmetries, which are incorporated into the network layers of our recently proposed Lattice Gauge Equivariant Convolutional Neural Networks (L-CNNs). L-CNNs can generalize better to differently sized lattices than traditional neural networks and are by construction equivariant under lattice gauge transformations. In these proceedings, we present our progress on possible applications of L-CNNs to Wilson flow or continuous normalizing flow. Our methods are based on neural ordinary differential equations which allow us to modify link configurations in a gauge equivariant manner. For simplicity, we focus on simple toy models to test these ideas in practice.
On the Effect of Pre-training for Transformer in Different Modality on Offline Reinforcement Learning
Nov 17, 2022
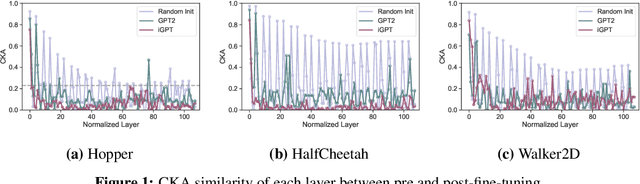
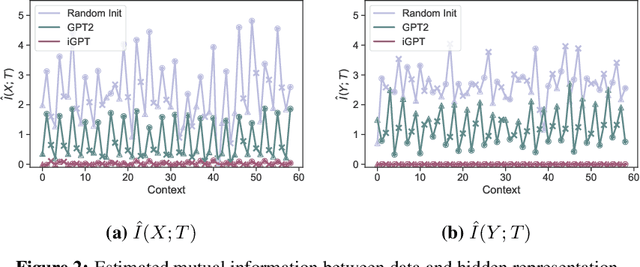
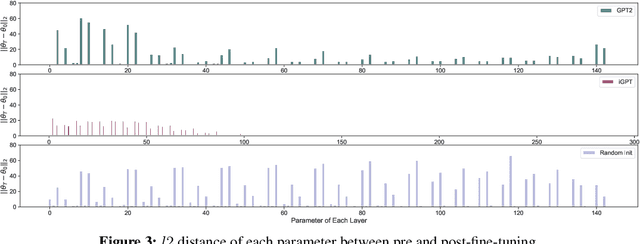
We empirically investigate how pre-training on data of different modalities, such as language and vision, affects fine-tuning of Transformer-based models to Mujoco offline reinforcement learning tasks. Analysis of the internal representation reveals that the pre-trained Transformers acquire largely different representations before and after pre-training, but acquire less information of data in fine-tuning than the randomly initialized one. A closer look at the parameter changes of the pre-trained Transformers reveals that their parameters do not change that much and that the bad performance of the model pre-trained with image data could partially come from large gradients and gradient clipping. To study what information the Transformer pre-trained with language data utilizes, we fine-tune this model with no context provided, finding that the model learns efficiently even without context information. Subsequent follow-up analysis supports the hypothesis that pre-training with language data is likely to make the Transformer get context-like information and utilize it to solve the downstream task.
* 48 pages. Published in NeurIPS 2022
An experimental study on Synthetic Tabular Data Evaluation
Dec 15, 2022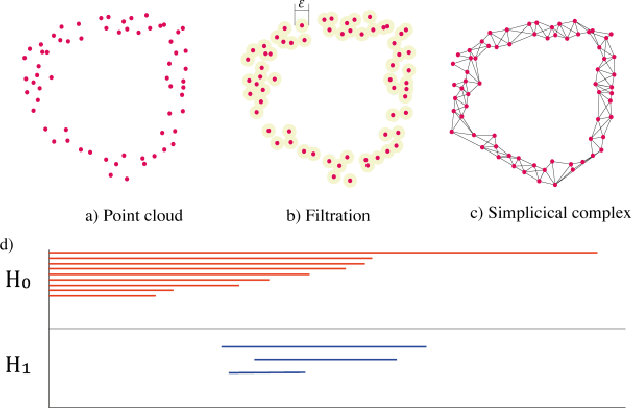

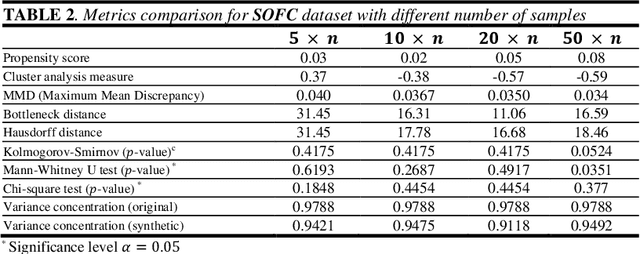
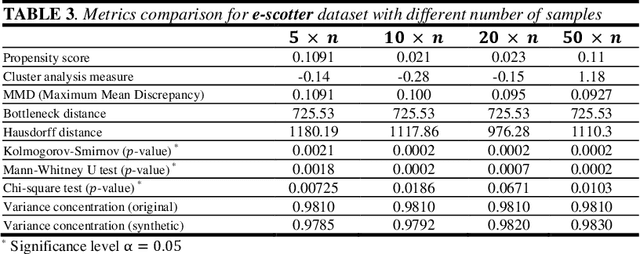
In this paper, we present the findings of various methodologies for measuring the similarity of synthetic data generated from tabular data samples. We particularly apply our research to the case where the synthetic data has many more samples than the real data. This task has a special complexity: validating the reliability of this synthetically generated data with a much higher number of samples than the original. We evaluated the most commonly used global metrics found in the literature. We introduced a novel approach based on the data's topological signature analysis. Topological data analysis has several advantages in addressing this latter challenge. The study of qualitative geometric information focuses on geometric properties while neglecting quantitative distance function values. This is especially useful with high-dimensional synthetic data where the sample size has been significantly increased. It is comparable to introducing new data points into the data space within the limits set by the original data. Then, in large synthetic data spaces, points will be much more concentrated than in the original space, and their analysis will become much more sensitive to both the metrics used and noise. Instead, the concept of "closeness" between points is used for qualitative geometric information. Finally, we suggest an approach based on data Eigen vectors for evaluating the level of noise in synthetic data. This approach can also be used to assess the similarity of original and synthetic data.
Is Self-Attention Powerful to Learn Code Syntax and Semantics?
Dec 20, 2022

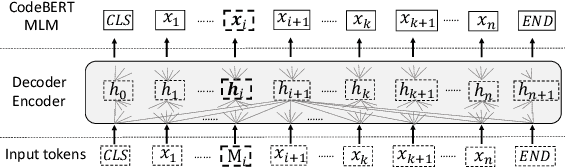
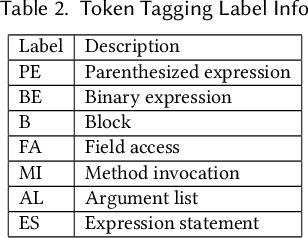
Pre-trained language models for programming languages have shown a powerful ability on processing many Software Engineering (SE) tasks, e.g., program synthesis, code completion, and code search. However, it remains to be seen what is behind their success. Recent studies have examined how pre-trained models can effectively learn syntax information based on Abstract Syntax Trees. In this paper, we figure out what role the self-attention mechanism plays in understanding code syntax and semantics based on AST and static analysis. We focus on a well-known representative code model, CodeBERT, and study how it can learn code syntax and semantics by the self-attention mechanism and Masked Language Modelling (MLM) at the token level. We propose a group of probing tasks to analyze CodeBERT. Based on AST and static analysis, we establish the relationships among the code tokens. First, Our results show that CodeBERT can acquire syntax and semantics knowledge through self-attention and MLM. Second, we demonstrate that the self-attention mechanism pays more attention to dependence-relationship tokens than to other tokens. Different attention heads play different roles in learning code semantics; we show that some of them are weak at encoding code semantics. Different layers have different competencies to represent different code properties. Deep CodeBERT layers can encode the semantic information that requires some complex inference in the code context. More importantly, we show that our analysis is helpful and leverage our conclusions to improve CodeBERT. We show an alternative approach for pre-training models, which makes fully use of the current pre-training strategy, i.e, MLM, to learn code syntax and semantics, instead of combining features from different code data formats, e.g., data-flow, running-time states, and program outputs.
FECAM: Frequency Enhanced Channel Attention Mechanism for Time Series Forecasting
Dec 02, 2022

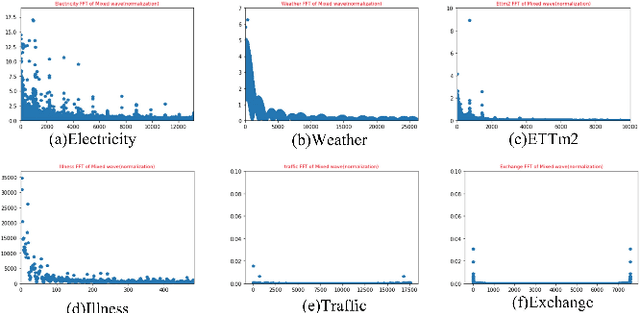
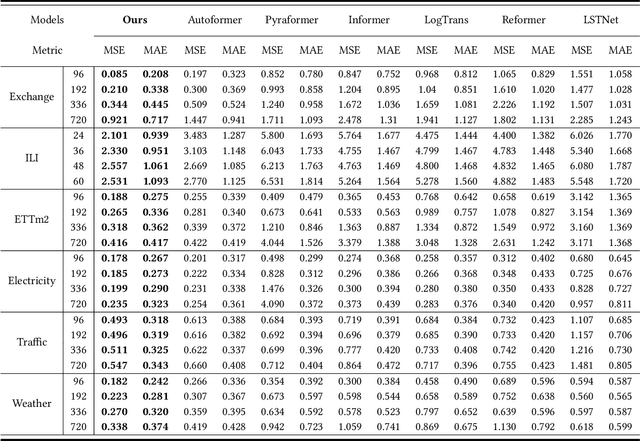
Time series forecasting is a long-standing challenge due to the real-world information is in various scenario (e.g., energy, weather, traffic, economics, earthquake warning). However some mainstream forecasting model forecasting result is derailed dramatically from ground truth. We believe it's the reason that model's lacking ability of capturing frequency information which richly contains in real world datasets. At present, the mainstream frequency information extraction methods are Fourier transform(FT) based. However, use of FT is problematic due to Gibbs phenomenon. If the values on both sides of sequences differ significantly, oscillatory approximations are observed around both sides and high frequency noise will be introduced. Therefore We propose a novel frequency enhanced channel attention that adaptively modelling frequency interdependencies between channels based on Discrete Cosine Transform which would intrinsically avoid high frequency noise caused by problematic periodity during Fourier Transform, which is defined as Gibbs Phenomenon. We show that this network generalize extremely effectively across six real-world datasets and achieve state-of-the-art performance, we further demonstrate that frequency enhanced channel attention mechanism module can be flexibly applied to different networks. This module can improve the prediction ability of existing mainstream networks, which reduces 35.99% MSE on LSTM, 10.01% on Reformer, 8.71% on Informer, 8.29% on Autoformer, 8.06% on Transformer, etc., at a slight computational cost ,with just a few line of code. Our codes and data are available at https://github.com/Zero-coder/FECAM.
Playing Technique Detection by Fusing Note Onset Information in Guzheng Performance
Sep 19, 2022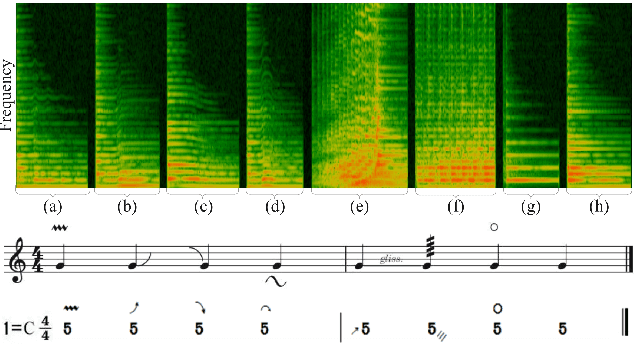
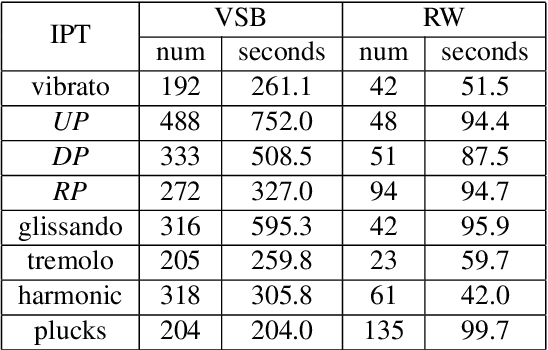
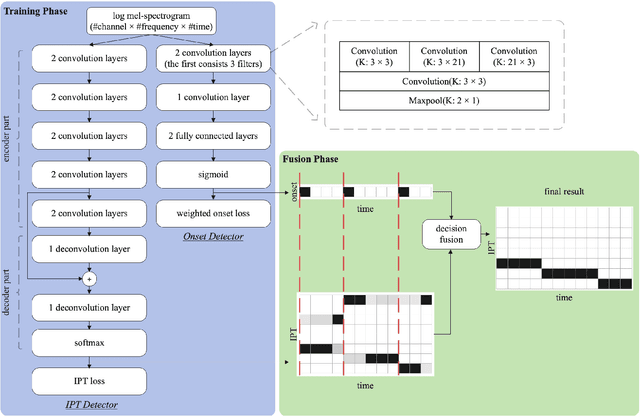

The Guzheng is a kind of traditional Chinese instruments with diverse playing techniques. Instrument playing techniques (IPT) play an important role in musical performance. However, most of the existing works for IPT detection show low efficiency for variable-length audio and provide no assurance in the generalization as they rely on a single sound bank for training and testing. In this study, we propose an end-to-end Guzheng playing technique detection system using Fully Convolutional Networks that can be applied to variable-length audio. Because each Guzheng playing technique is applied to a note, a dedicated onset detector is trained to divide an audio into several notes and its predictions are fused with frame-wise IPT predictions. During fusion, we add the IPT predictions frame by frame inside each note and get the IPT with the highest probability within each note as the final output of that note. We create a new dataset named GZ_IsoTech from multiple sound banks and real-world recordings for Guzheng performance analysis. Our approach achieves 87.97% in frame-level accuracy and 80.76% in note-level F1-score, outperforming existing works by a large margin, which indicates the effectiveness of our proposed method in IPT detection.
Task-Oriented Communication for Edge Video Analytics
Nov 25, 2022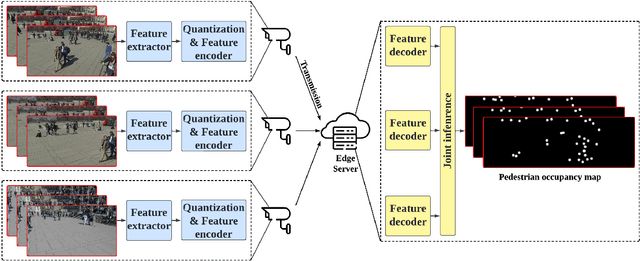
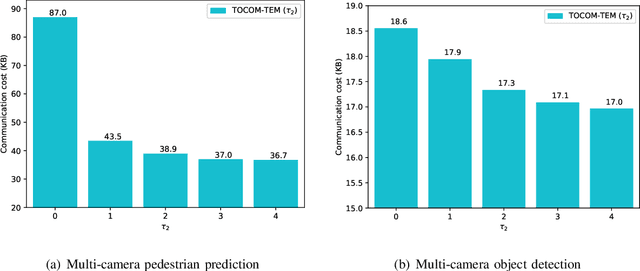
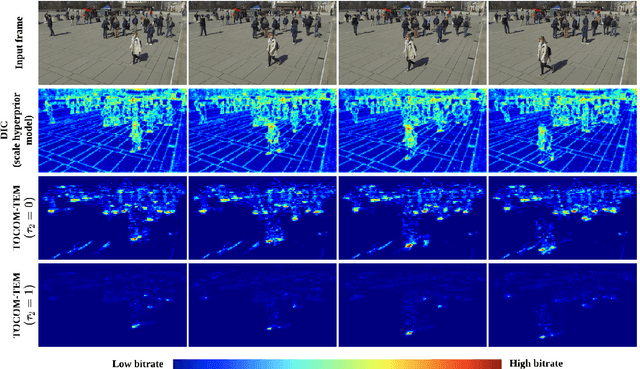
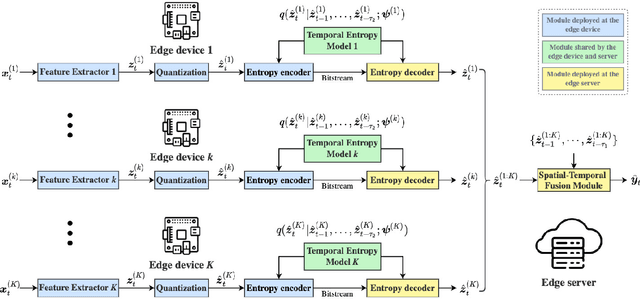
With the development of artificial intelligence (AI) techniques and the increasing popularity of camera-equipped devices, many edge video analytics applications are emerging, calling for the deployment of computation-intensive AI models at the network edge. Edge inference is a promising solution to move the computation-intensive workloads from low-end devices to a powerful edge server for video analytics, but the device-server communications will remain a bottleneck due to the limited bandwidth. This paper proposes a task-oriented communication framework for edge video analytics, where multiple devices collect the visual sensory data and transmit the informative features to an edge server for processing. To enable low-latency inference, this framework removes video redundancy in spatial and temporal domains and transmits minimal information that is essential for the downstream task, rather than reconstructing the videos at the edge server. Specifically, it extracts compact task-relevant features based on the deterministic information bottleneck (IB) principle, which characterizes a tradeoff between the informativeness of the features and the communication cost. As the features of consecutive frames are temporally correlated, we propose a temporal entropy model (TEM) to reduce the bitrate by taking the previous features as side information in feature encoding. To further improve the inference performance, we build a spatial-temporal fusion module at the server to integrate features of the current and previous frames for joint inference. Extensive experiments on video analytics tasks evidence that the proposed framework effectively encodes task-relevant information of video data and achieves a better rate-performance tradeoff than existing methods.
RGB-D-based Stair Detection using Deep Learning for Autonomous Stair Climbing
Dec 09, 2022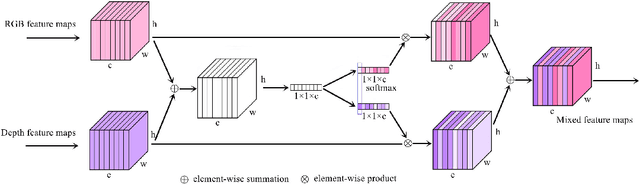
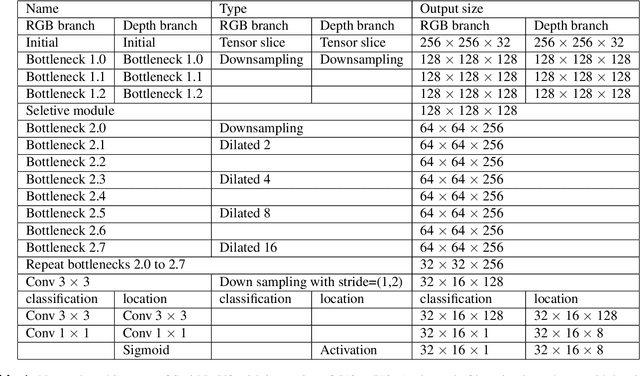
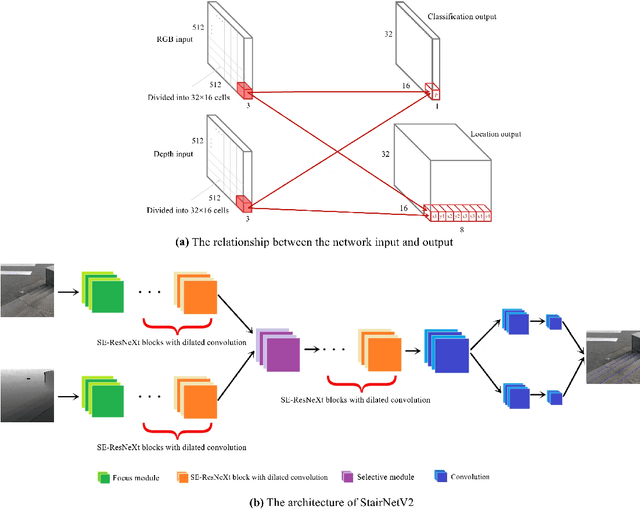
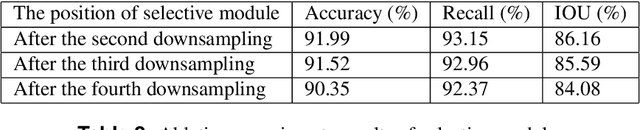
Stairs are common building structures in urban environments, and stair detection is an important part of environment perception for autonomous mobile robots. Most existing algorithms have difficulty combining the visual information from binocular sensors effectively and ensuring reliable detection at night and in the case of extremely fuzzy visual clues. To solve these problems, we propose a neural network architecture with RGB and depth map inputs. Specifically, we design a selective module, which can make the network learn the complementary relationship between the RGB map and the depth map and effectively combine the information from the RGB map and the depth map in different scenes. In addition, we design a line clustering algorithm for the postprocessing of detection results, which can make full use of the detection results to obtain the geometric stair parameters. Experiments on our dataset show that our method can achieve better accuracy and recall compared with existing state-of-the-art deep learning methods, which are 5.64% and 7.97%, respectively, and our method also has extremely fast detection speed. A lightweight version can achieve 300 + frames per second with the same resolution, which can meet the needs of most real-time detection scenes.