 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Diffusion Guidance via Stochastic Optimal Control
May 25, 2025Guidance is a cornerstone of modern diffusion models, playing a pivotal role in conditional generation and enhancing the quality of unconditional samples. However, current approaches to guidance scheduling--determining the appropriate guidance weight--are largely heuristic and lack a solid theoretical foundation. This work addresses these limitations on two fronts. First, we provide a theoretical formalization that precisely characterizes the relationship between guidance strength and classifier confidence. Second, building on this insight, we introduce a stochastic optimal control framework that casts guidance scheduling as an adaptive optimization problem. In this formulation, guidance strength is not fixed but dynamically selected based on time, the current sample, and the conditioning class, either independently or in combination. By solving the resulting control problem, we establish a principled foundation for more effective guidance in diffusion models.
NoProp: Training Neural Networks without Back-propagation or Forward-propagation
Mar 31, 2025



The canonical deep learning approach for learning requires computing a gradient term at each layer by back-propagating the error signal from the output towards each learnable parameter. Given the stacked structure of neural networks, where each layer builds on the representation of the layer below, this approach leads to hierarchical representations. More abstract features live on the top layers of the model, while features on lower layers are expected to be less abstract. In contrast to this, we introduce a new learning method named NoProp, which does not rely on either forward or backwards propagation. Instead, NoProp takes inspiration from diffusion and flow matching methods, where each layer independently learns to denoise a noisy target. We believe this work takes a first step towards introducing a new family of gradient-free learning methods, that does not learn hierarchical representations -- at least not in the usual sense. NoProp needs to fix the representation at each layer beforehand to a noised version of the target, learning a local denoising process that can then be exploited at inference. We demonstrate the effectiveness of our method on MNIST, CIFAR-10, and CIFAR-100 image classification benchmarks. Our results show that NoProp is a viable learning algorithm which achieves superior accuracy, is easier to use and computationally more efficient compared to other existing back-propagation-free methods. By departing from the traditional gradient based learning paradigm, NoProp alters how credit assignment is done within the network, enabling more efficient distributed learning as well as potentially impacting other characteristics of the learning process.
Building Footprint Extraction with Graph Convolutional Network
May 08, 2023


Building footprint information is an essential ingredient for 3-D reconstruction of urban models. The automatic generation of building footprints from satellite images presents a considerable challenge due to the complexity of building shapes. Recent developments in deep convolutional neural networks (DCNNs) have enabled accurate pixel-level labeling tasks. One central issue remains, which is the precise delineation of boundaries. Deep architectures generally fail to produce fine-grained segmentation with accurate boundaries due to progressive downsampling. In this work, we have proposed a end-to-end framework to overcome this issue, which uses the graph convolutional network (GCN) for building footprint extraction task. Our proposed framework outperforms state-of-the-art methods.
Playing Technique Detection by Fusing Note Onset Information in Guzheng Performance
Sep 19, 2022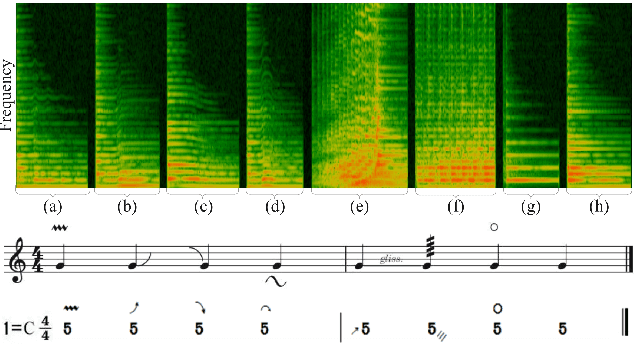
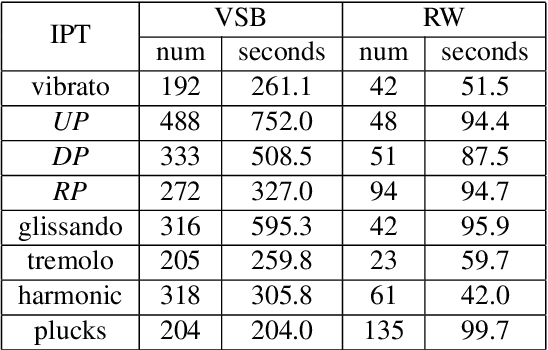
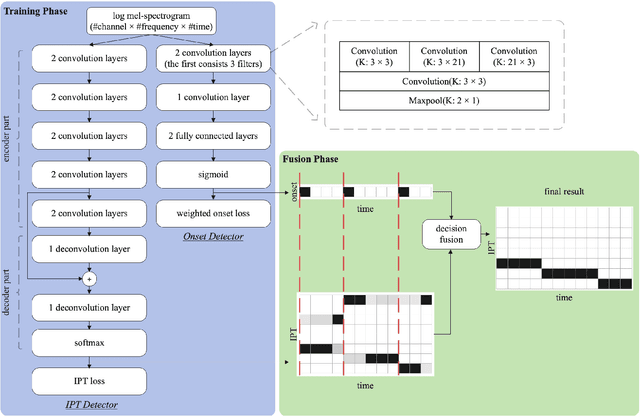

The Guzheng is a kind of traditional Chinese instruments with diverse playing techniques. Instrument playing techniques (IPT) play an important role in musical performance. However, most of the existing works for IPT detection show low efficiency for variable-length audio and provide no assurance in the generalization as they rely on a single sound bank for training and testing. In this study, we propose an end-to-end Guzheng playing technique detection system using Fully Convolutional Networks that can be applied to variable-length audio. Because each Guzheng playing technique is applied to a note, a dedicated onset detector is trained to divide an audio into several notes and its predictions are fused with frame-wise IPT predictions. During fusion, we add the IPT predictions frame by frame inside each note and get the IPT with the highest probability within each note as the final output of that note. We create a new dataset named GZ_IsoTech from multiple sound banks and real-world recordings for Guzheng performance analysis. Our approach achieves 87.97% in frame-level accuracy and 80.76% in note-level F1-score, outperforming existing works by a large margin, which indicates the effectiveness of our proposed method in IPT detection.
Taking an Emotional Look at Video Paragraph Captioning
Mar 12, 2022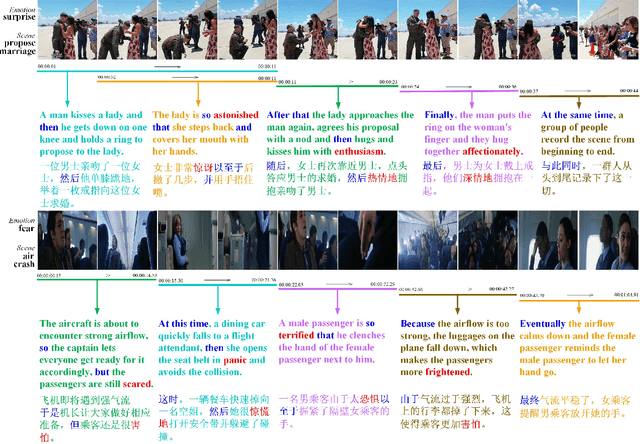
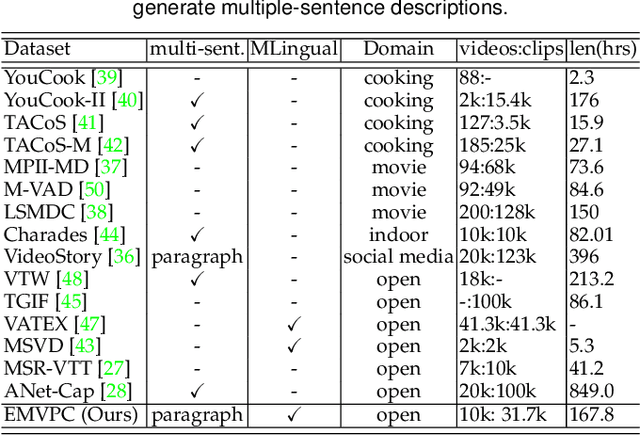
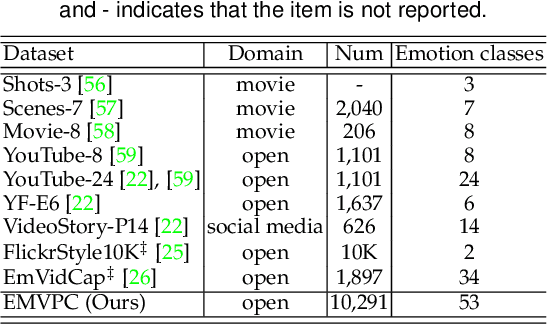
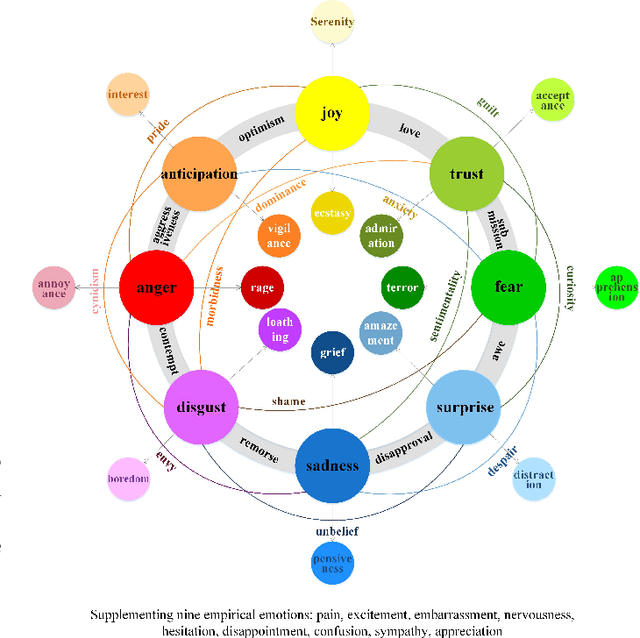
Translating visual data into natural language is essential for machines to understand the world and interact with humans. In this work, a comprehensive study is conducted on video paragraph captioning, with the goal to generate paragraph-level descriptions for a given video. However, current researches mainly focus on detecting objective facts, ignoring the needs to establish the logical associations between sentences and to discover more accurate emotions related to video contents. Such a problem impairs fluent and abundant expressions of predicted captions, which are far below human language tandards. To solve this problem, we propose to construct a large-scale emotion and logic driven multilingual dataset for this task. This dataset is named EMVPC (standing for "Emotional Video Paragraph Captioning") and contains 53 widely-used emotions in daily life, 376 common scenes corresponding to these emotions, 10,291 high-quality videos and 20,582 elaborated paragraph captions with English and Chinese versions. Relevant emotion categories, scene labels, emotion word labels and logic word labels are also provided in this new dataset. The proposed EMVPC dataset intends to provide full-fledged video paragraph captioning in terms of rich emotions, coherent logic and elaborate expressions, which can also benefit other tasks in vision-language fields. Furthermore, a comprehensive study is conducted through experiments on existing benchmark video paragraph captioning datasets and the proposed EMVPC. The stateof-the-art schemes from different visual captioning tasks are compared in terms of 15 popular metrics, and their detailed objective as well as subjective results are summarized. Finally, remaining problems and future directions of video paragraph captioning are also discussed. The unique perspective of this work is expected to boost further development in video paragraph captioning research.