 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CoGANPPIS: Coevolution-enhanced Global Attention Neural Network for Protein-Protein Interaction Site Prediction
Apr 03, 2023

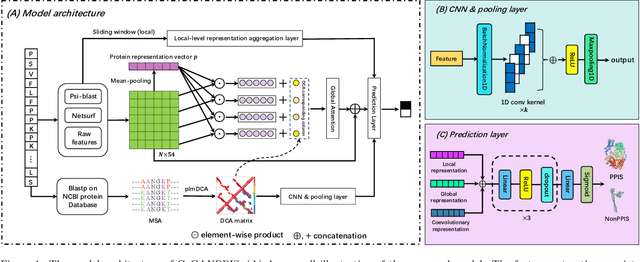
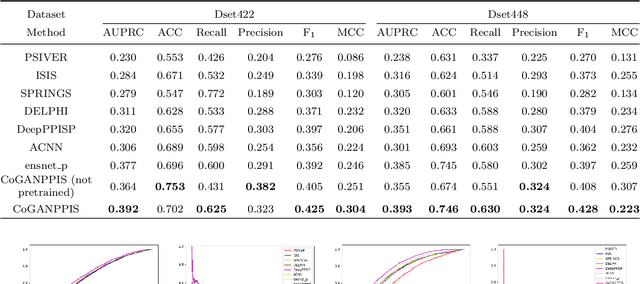
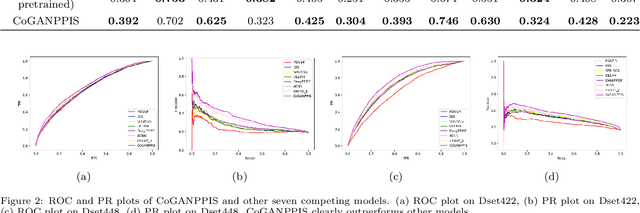
Protein-protein interactions are essential in biochemical processes. Accurate prediction of the protein-protein interaction sites (PPIs) deepens our understanding of biological mechanism and is crucial for new drug design. However, conventional experimental methods for PPIs prediction are costly and time-consuming so that many computational approaches, especially ML-based methods, have been developed recently. Although these approaches have achieved gratifying results, there are still two limitations: (1) Most models have excavated some useful input features, but failed to take coevolutionary features into account, which could provide clues for inter-residue relationships; (2) The attention-based models only allocate attention weights for neighboring residues, instead of doing it globally, neglecting that some residues being far away from the target residues might also matter. We propose a coevolution-enhanced global attention neural network, a sequence-based deep learning model for PPIs prediction, called CoGANPPIS. It utilizes three layers in parallel for feature extraction: (1) Local-level representation aggregation layer, which aggregates the neighboring residues' features; (2) Global-level representation learning layer, which employs a novel coevolution-enhanced global attention mechanism to allocate attention weights to all the residues on the same protein sequences; (3) Coevolutionary information learning layer, which applies CNN & pooling to coevolutionary information to obtain the coevolutionary profile representation. Then, the three outputs are concatenated and passed into several fully connected layers for the final prediction. Application on two benchmark datasets demonstrated a state-of-the-art performance of our model. The source code is publicly available at https://github.com/Slam1423/CoGANPPIS_source_code.
Audio Visual Language Maps for Robot Navigation
Mar 27, 2023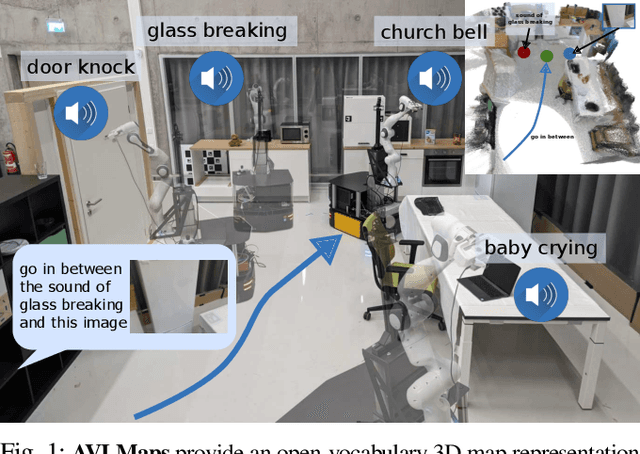
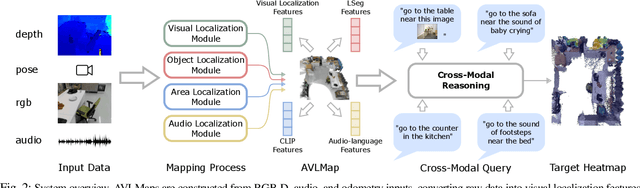
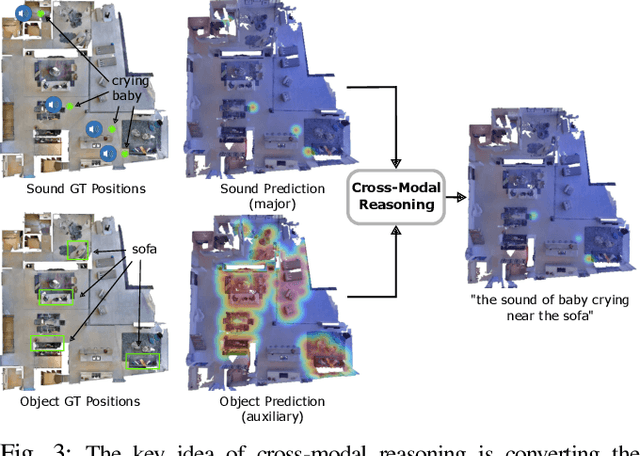

While interacting in the world is a multi-sensory experience, many robots continue to predominantly rely on visual perception to map and navigate in their environments. In this work, we propose Audio-Visual-Language Maps (AVLMaps), a unified 3D spatial map representation for storing cross-modal information from audio, visual, and language cues. AVLMaps integrate the open-vocabulary capabilities of multimodal foundation models pre-trained on Internet-scale data by fusing their features into a centralized 3D voxel grid. In the context of navigation, we show that AVLMaps enable robot systems to index goals in the map based on multimodal queries, e.g., textual descriptions, images, or audio snippets of landmarks. In particular, the addition of audio information enables robots to more reliably disambiguate goal locations. Extensive experiments in simulation show that AVLMaps enable zero-shot multimodal goal navigation from multimodal prompts and provide 50% better recall in ambiguous scenarios. These capabilities extend to mobile robots in the real world - navigating to landmarks referring to visual, audio, and spatial concepts. Videos and code are available at: https://avlmaps.github.io.
Multi-contrast MRI Super-resolution via Implicit Neural Representations
Mar 27, 2023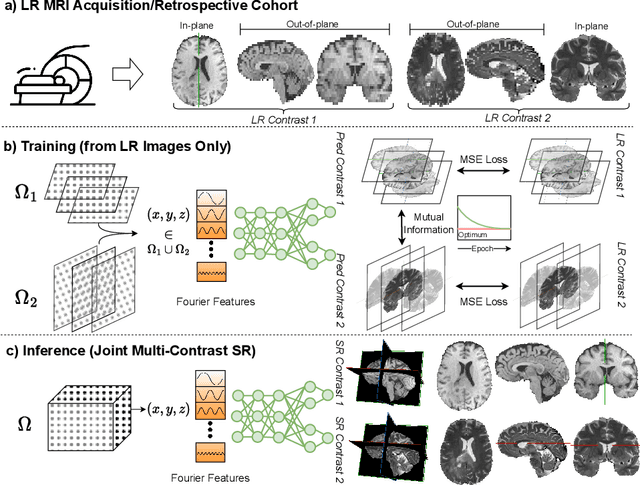
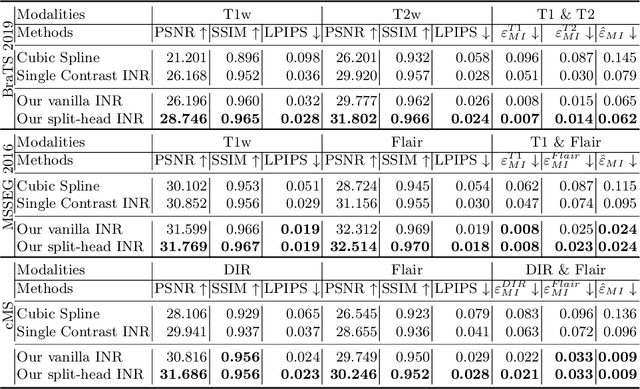
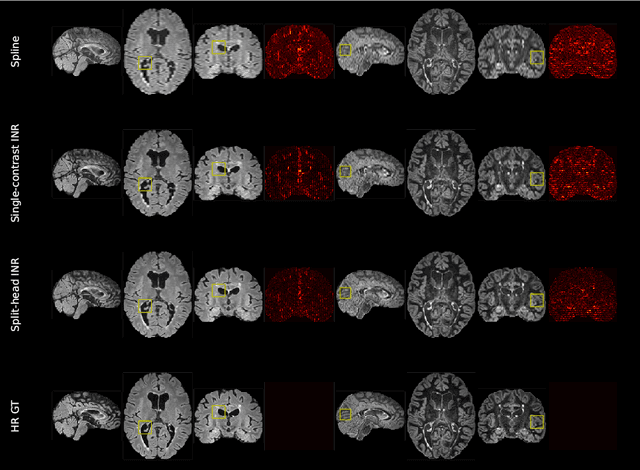

Clinical routine and retrospective cohorts commonly include multi-parametric Magnetic Resonance Imaging; however, they are mostly acquired in different anisotropic 2D views due to signal-to-noise-ratio and scan-time constraints. Thus acquired views suffer from poor out-of-plane resolution and affect downstream volumetric image analysis that typically requires isotropic 3D scans. Combining different views of multi-contrast scans into high-resolution isotropic 3D scans is challenging due to the lack of a large training cohort, which calls for a subject-specific framework.This work proposes a novel solution to this problem leveraging Implicit Neural Representations (INR). Our proposed INR jointly learns two different contrasts of complementary views in a continuous spatial function and benefits from exchanging anatomical information between them. Trained within minutes on a single commodity GPU, our model provides realistic super-resolution across different pairs of contrasts in our experiments with three datasets. Using Mutual Information (MI) as a metric, we find that our model converges to an optimum MI amongst sequences, achieving anatomically faithful reconstruction. Code is available at: https://github.com/jqmcginnis/multi_contrast_inr.
DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents
Mar 30, 2023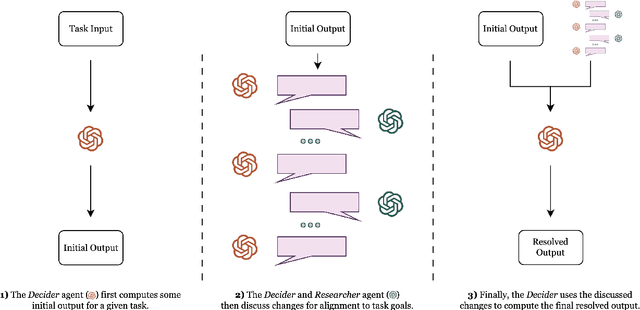
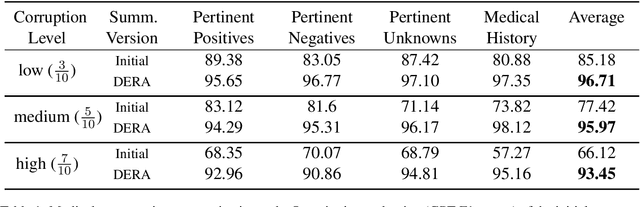
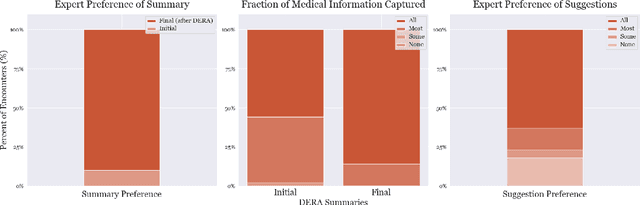

Large language models (LLMs) have emerged as valuable tools for many natural language understanding tasks. In safety-critical applications such as healthcare, the utility of these models is governed by their ability to generate outputs that are factually accurate and complete. In this work, we present dialog-enabled resolving agents (DERA). DERA is a paradigm made possible by the increased conversational abilities of LLMs, namely GPT-4. It provides a simple, interpretable forum for models to communicate feedback and iteratively improve output. We frame our dialog as a discussion between two agent types - a Researcher, who processes information and identifies crucial problem components, and a Decider, who has the autonomy to integrate the Researcher's information and makes judgments on the final output. We test DERA against three clinically-focused tasks. For medical conversation summarization and care plan generation, DERA shows significant improvement over the base GPT-4 performance in both human expert preference evaluations and quantitative metrics. In a new finding, we also show that GPT-4's performance (70%) on an open-ended version of the MedQA question-answering (QA) dataset (Jin et al. 2021, USMLE) is well above the passing level (60%), with DERA showing similar performance. We release the open-ended MEDQA dataset at https://github.com/curai/curai-research/tree/main/DERA.
Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information
Nov 21, 2022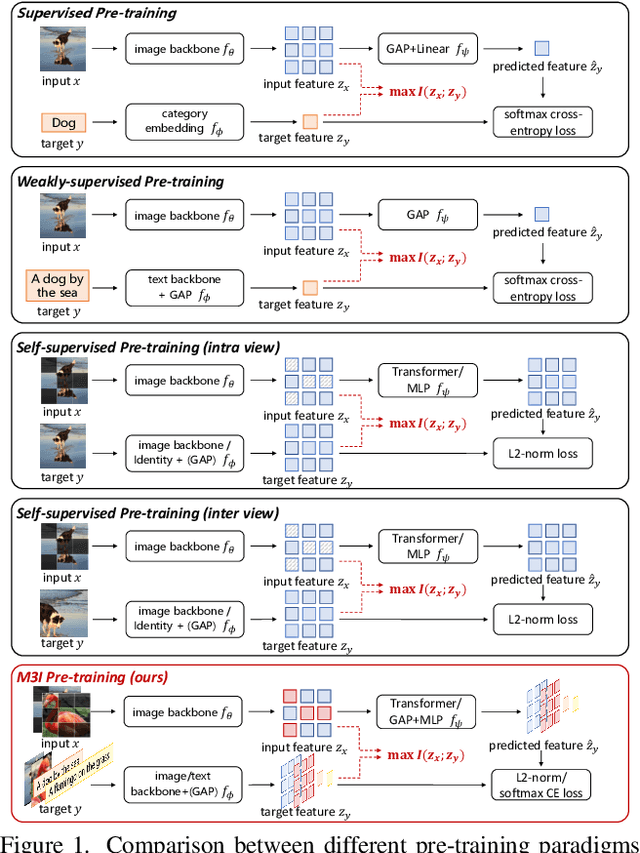
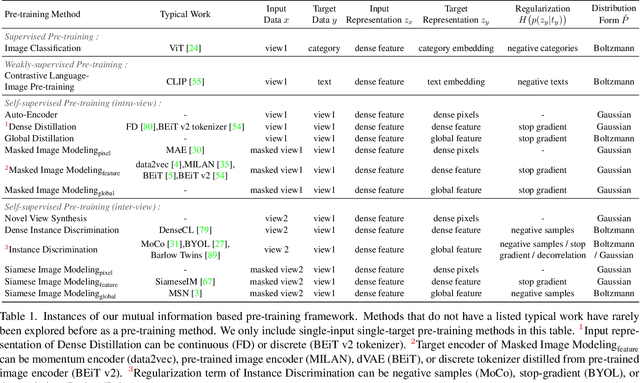
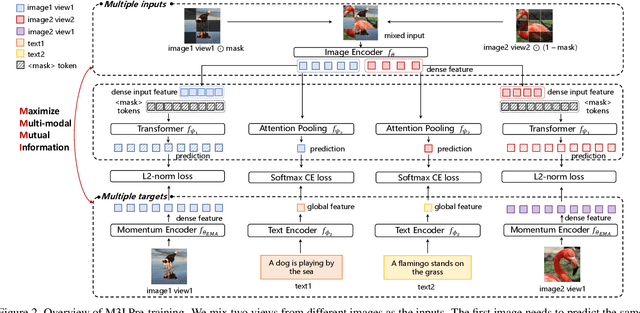
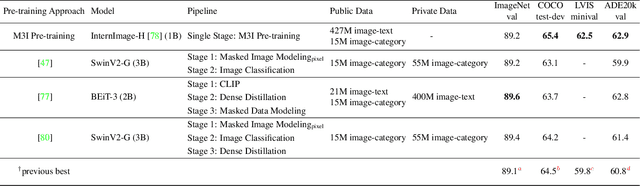
To effectively exploit the potential of large-scale models, various pre-training strategies supported by massive data from different sources are proposed, including supervised pre-training, weakly-supervised pre-training, and self-supervised pre-training. It has been proved that combining multiple pre-training strategies and data from various modalities/sources can greatly boost the training of large-scale models. However, current works adopt a multi-stage pre-training system, where the complex pipeline may increase the uncertainty and instability of the pre-training. It is thus desirable that these strategies can be integrated in a single-stage manner. In this paper, we first propose a general multi-modal mutual information formula as a unified optimization target and demonstrate that all existing approaches are special cases of our framework. Under this unified perspective, we propose an all-in-one single-stage pre-training approach, named Maximizing Multi-modal Mutual Information Pre-training (M3I Pre-training). Our approach achieves better performance than previous pre-training methods on various vision benchmarks, including ImageNet classification, COCO object detection, LVIS long-tailed object detection, and ADE20k semantic segmentation. Notably, we successfully pre-train a billion-level parameter image backbone and achieve state-of-the-art performance on various benchmarks. Code shall be released at https://github.com/OpenGVLab/M3I-Pretraining.
Interference and noise cancellation for joint communication radar (JCR) system based on contextual information
Feb 14, 2023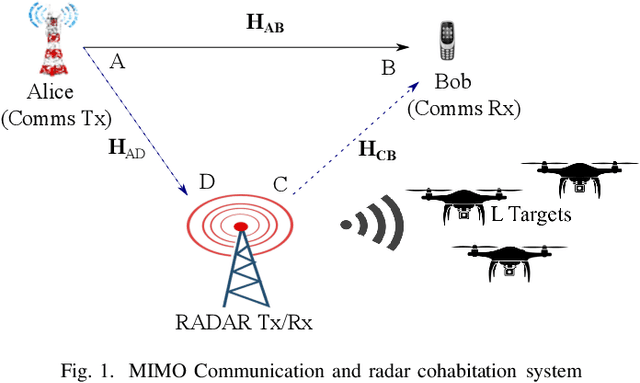
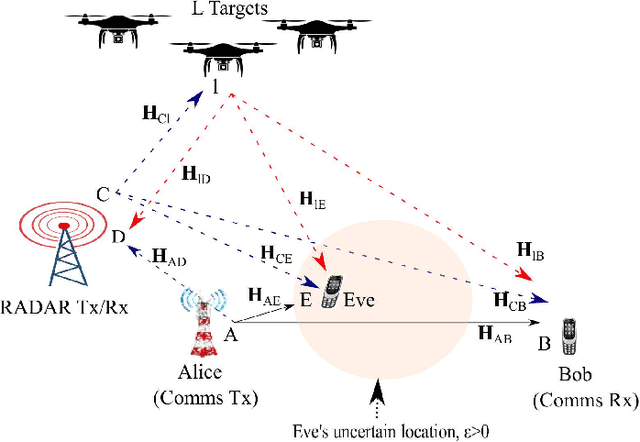
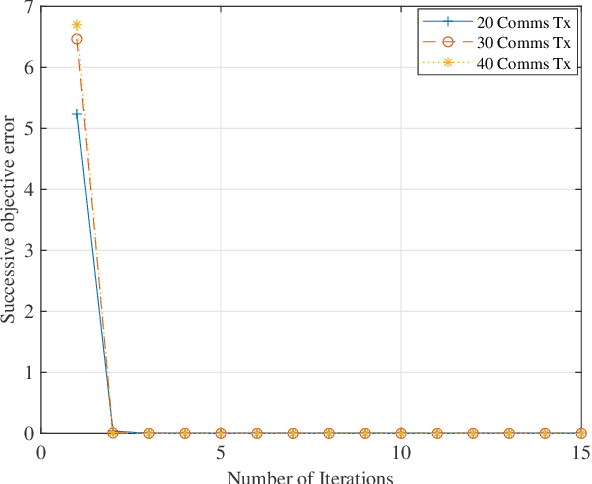
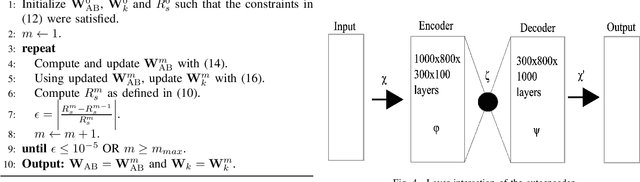
This paper examines the separation of wireless communication and radar signals, thereby guaranteeing cohabitation and acting as a panacea to spectrum sensing. First, considering that the channel impulse response was known by the receivers (communication and radar), we showed that the optimizing beamforming weights mitigate the interference caused by signals and improve the physical layer security (PLS) of the system. Furthermore, when the channel responses were unknown, we designed an interference filter as a low-complex noise and interference cancellation autoencoder. By mitigating the interference on the legitimate users, the PLS was guaranteed. Results showed that even for a low signal-to-noise ratio, the autoencoder produces low root-mean-square error (RMSE) values.
Self-Supervised Image Denoising for Real-World Images with Context-aware Transformer
Apr 04, 2023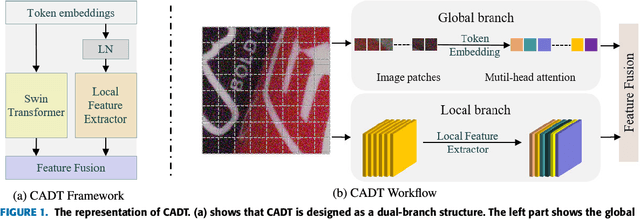

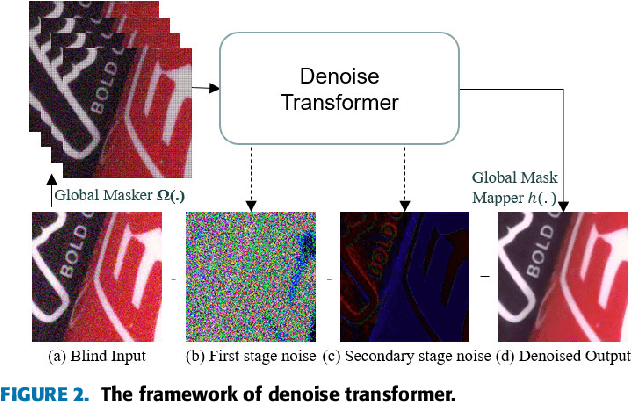
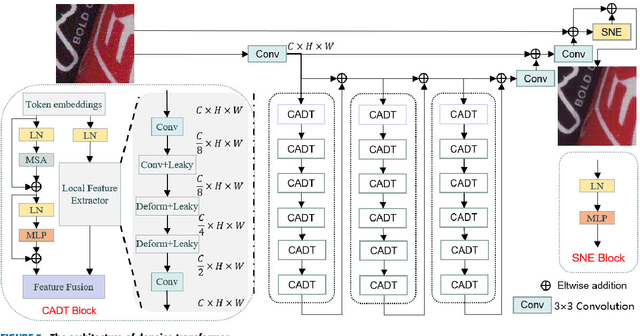
In recent years, the development of deep learning has been pushing image denoising to a new level. Among them, self-supervised denoising is increasingly popular because it does not require any prior knowledge. Most of the existing self-supervised methods are based on convolutional neural networks (CNN), which are restricted by the locality of the receptive field and would cause color shifts or textures loss. In this paper, we propose a novel Denoise Transformer for real-world image denoising, which is mainly constructed with Context-aware Denoise Transformer (CADT) units and Secondary Noise Extractor (SNE) block. CADT is designed as a dual-branch structure, where the global branch uses a window-based Transformer encoder to extract the global information, while the local branch focuses on the extraction of local features with small receptive field. By incorporating CADT as basic components, we build a hierarchical network to directly learn the noise distribution information through residual learning and obtain the first stage denoised output. Then, we design SNE in low computation for secondary global noise extraction. Finally the blind spots are collected from the Denoise Transformer output and reconstructed, forming the final denoised image. Extensive experiments on the real-world SIDD benchmark achieve 50.62/0.990 for PSNR/SSIM, which is competitive with the current state-of-the-art method and only 0.17/0.001 lower. Visual comparisons on public sRGB, Raw-RGB and greyscale datasets prove that our proposed Denoise Transformer has a competitive performance, especially on blurred textures and low-light images, without using additional knowledge, e.g., noise level or noise type, regarding the underlying unknown noise.
* 10 pages, 9 figures
Optimizing the Age of Information in Mixed-Critical Wireless Communication Networks
Nov 10, 2022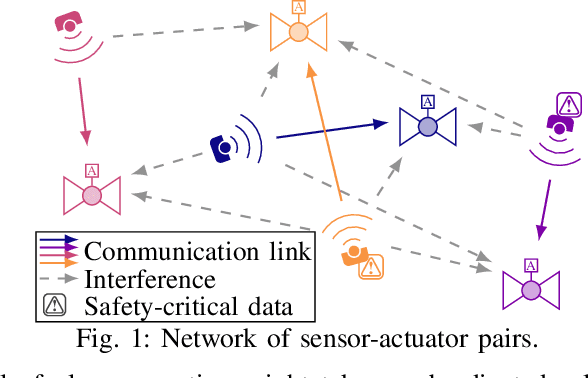
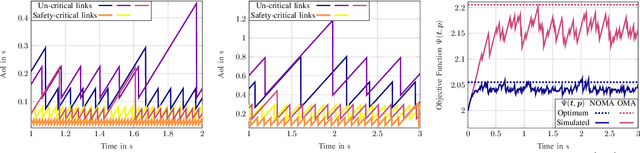
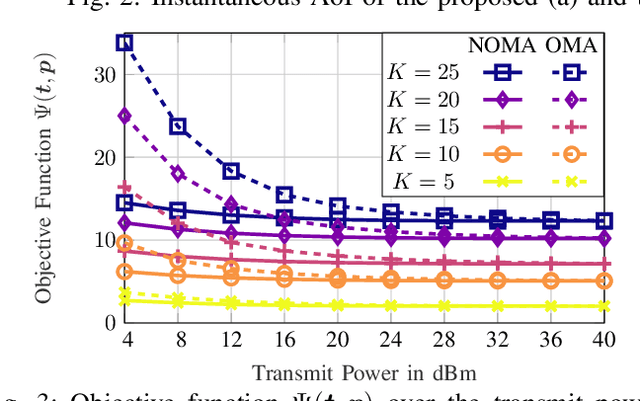
Beyond fifth generation wireless communication networks (B5G) are applied in many use-cases, such as industrial control systems, smart public transport, and power grids. Those applications require innovative techniques for timely transmission and increased wireless network capacities. Hence, this paper proposes optimizing the data freshness measured by the age of information (AoI) in dense internet of things (IoT) sensor-actuator networks. Given different priorities of data-streams, i.e., different sensitivities to outdated information, mixed-criticality is introduced by analyzing different functions of the age, i.e., we consider linear and exponential aging functions. An intricate non-convex optimization problem managing the physical transmission time and packet outage probability is derived. Such problem is tackled using stochastic reformulations, successive convex approximations, and fractional programming, resulting in an efficient iterative algorithm for AoI optimization. Simulation results validate the proposed scheme's performance in terms of AoI, mixed-criticality, and scalability. The proposed non-orthogonal transmission is shown to outperform an orthogonal access scheme in various deployment cases. Results emphasize the potential gains for dense B5G empowered IoT networks in minimizing the AoI.
Handling Heavy Occlusion in Dense Crowd Tracking by Focusing on the Heads
Apr 16, 2023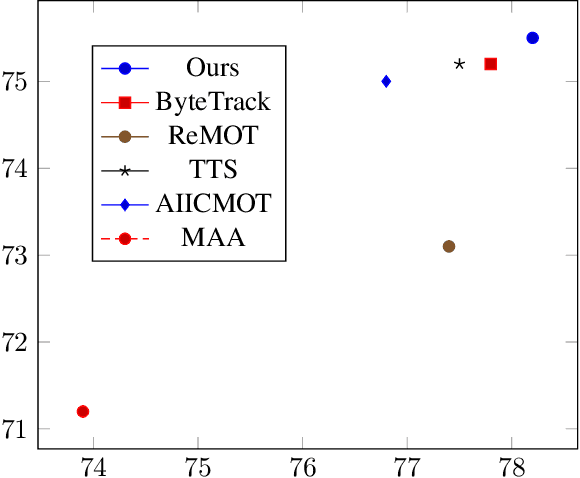

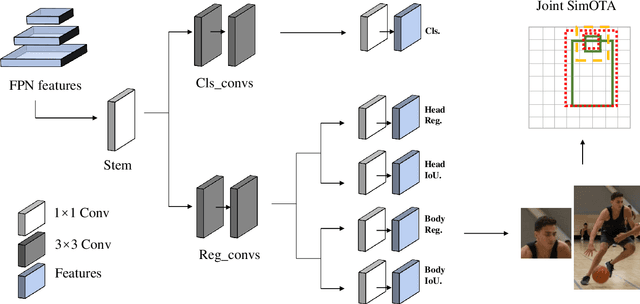
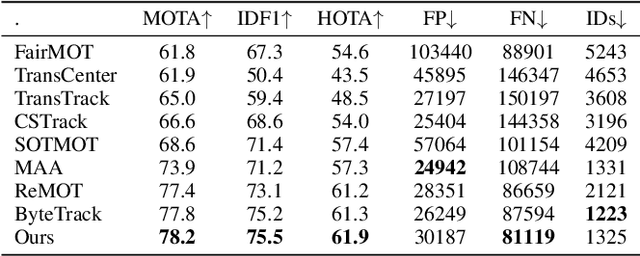
With the rapid development of deep learning, object detection and tracking play a vital role in today's society. Being able to identify and track all the pedestrians in the dense crowd scene with computer vision approaches is a typical challenge in this field, also known as the Multiple Object Tracking (MOT) challenge. Modern trackers are required to operate on more and more complicated scenes. According to the MOT20 challenge result, the pedestrian is 4 times denser than the MOT17 challenge. Hence, improving the ability to detect and track in extremely crowded scenes is the aim of this work. In light of the occlusion issue with the human body, the heads are usually easier to identify. In this work, we have designed a joint head and body detector in an anchor-free style to boost the detection recall and precision performance of pedestrians in both small and medium sizes. Innovatively, our model does not require information on the statistical head-body ratio for common pedestrians detection for training. Instead, the proposed model learns the ratio dynamically. To verify the effectiveness of the proposed model, we evaluate the model with extensive experiments on different datasets, including MOT20, Crowdhuman, and HT21 datasets. As a result, our proposed method significantly improves both the recall and precision rate on small & medium sized pedestrians and achieves state-of-the-art results in these challenging datasets.
A Framework for Mutual Information-based MIMO Integrated Sensing and Communication Beamforming Design
Nov 15, 2022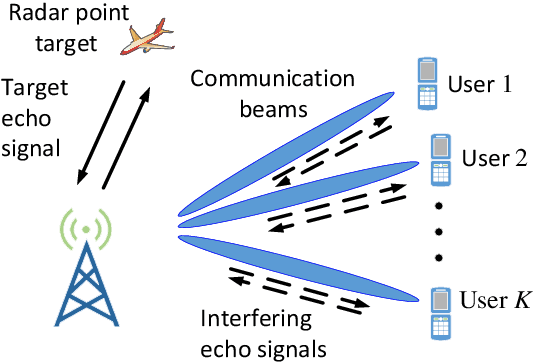
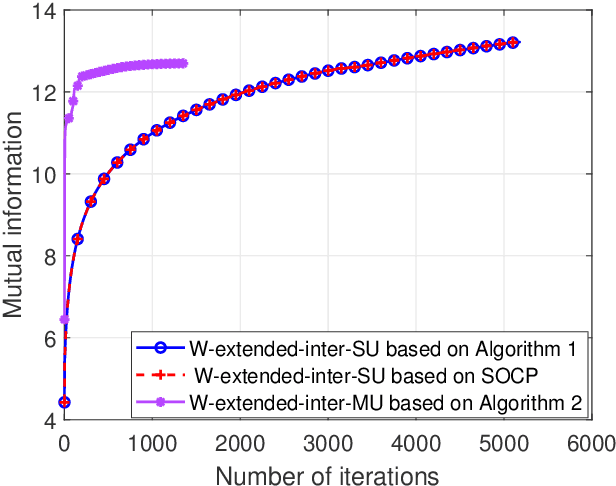
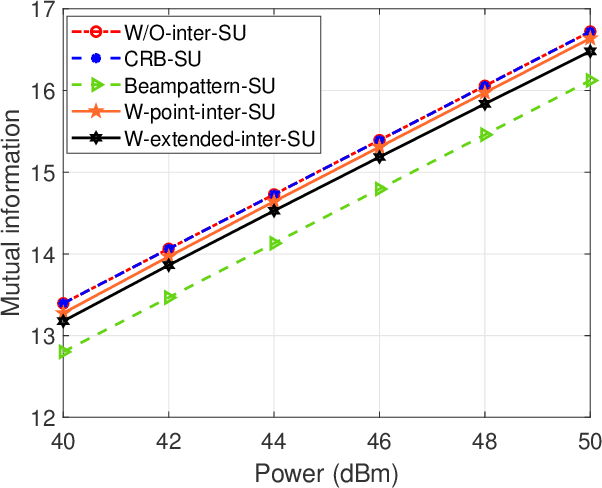
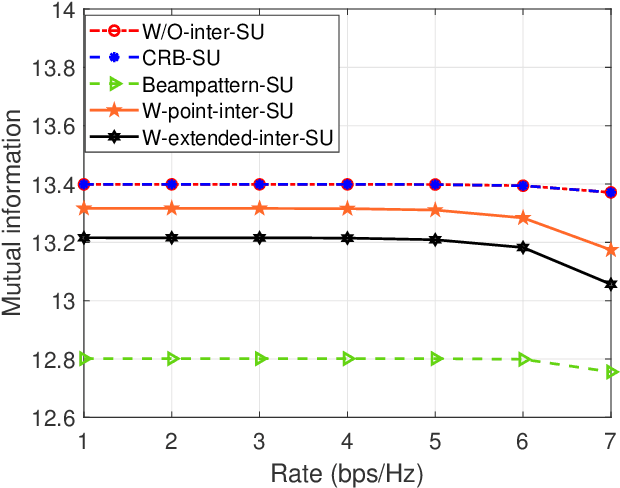
Integrated sensing and communication (ISAC) unifies sensing and communication, and improves the efficiency of the spectrum, energy, and hardware. In this work, we investigate the ISAC beamforming design to maximize the mutual information between the target response matrix of a point radar target and the echo signals, while ensuring the data rate requirements of communication users. In order to study the impact of the echo interference caused by communication users on sensing performance, we consider three types of echo interference problems caused by a single communication user, including no interference, a point interference, and an extended interference, as well as the problem of an extended interference caused by multiple communication users. To address these problems, we provide a closed-form solution with low complexiy, a semidefinite relaxation (SDR) method, a low-complexity algorithm based on the Majorization-Minimization (MM) method and the successive convex approximation (SCA) method, and an algorithm based on MM method and SCA method, respectively. Numerical results demonstrate that, compared to the ISAC beamforming schemes based on the Cram\'er-Rao bound (CRB) metric and the beampattern metric, the proposed maximizing mutual information metric can bring better beampattern and root mean square error (RMSE) of angle estimation. Apart from this, our proposed schemes based on the mutual information can suppress the echo interference from the communication users effectively.