 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Speech Enhancement: Architectural Design and Deployment Strategies
Aug 11, 2025This paper introduces a new AI-based Audio-Visual Speech Enhancement (AVSE) system and presents a comparative performance analysis of different deployment architectures. The proposed AVSE system employs convolutional neural networks (CNNs) for spectral feature extraction and long short-term memory (LSTM) networks for temporal modeling, enabling robust speech enhancement through multimodal fusion of audio and visual cues. Multiple deployment scenarios are investigated, including cloud-based, edge-assisted, and standalone device implementations. Their performance is evaluated in terms of speech quality improvement, latency, and computational overhead. Real-world experiments are conducted across various network conditions, including Ethernet, Wi-Fi, 4G, and 5G, to analyze the trade-offs between processing delay, communication latency, and perceptual speech quality. The results show that while cloud deployment achieves the highest enhancement quality, edge-assisted architectures offer the best balance between latency and intelligibility, meeting real-time requirements under 5G and Wi-Fi 6 conditions. These findings provide practical guidelines for selecting and optimizing AVSE deployment architectures in diverse applications, including assistive hearing devices, telepresence, and industrial communications.
Antenna Health-Aware Selective Beamforming for Hardware-Constrained DFRC Systems II
Dec 23, 2024This study introduces an innovative beamforming design approach that incorporates the reliability of antenna array elements into the optimization process, termed "antenna health-aware selective beamforming". This method strategically focuses transmission power on more reliable antenna elements, thus enhancing system resilience and operational integrity. By integrating antenna health information and individual power constraints, our research leverages advanced optimization techniques such as the Group Proximal-Gradient Dual Ascent (GPGDA) to efficiently address nonconvex challenges in sparse array selection. Applying the proposed technique to a Dual-Functional Radar-Communication (DFRC) system, our findings highlight that increasing the sparsity promotion weight ($\rho_s$) generally boosts spectral efficiency and communication data rate, achieving perfect system reliability at higher $\rho_s$ values but also revealing a performance threshold beyond which further sparsity is detrimental. This underscores the importance of balanced sparsity in beamforming for optimizing performance, particularly in critical communication and defense applications where uninterrupted operation is crucial. Additionally, our analysis of the time complexity and power consumption associated with GPGDA underscores the need for optimizing computational resources in practical implementations.
Efficient Dual-Blind Deconvolution for Joint Radar-Communication Systems Using ADMM: Enhancing Channel Estimation and Signal Recovery in 5G mmWave Networks
Sep 28, 2024This paper introduces an innovative framework to address the dual-blind deconvolution challenge within joint radar-communication (JRC) systems, leveraging the Alternating Direction Method of Multipliers (ADMM) to estimate unknown radar channels G (or communication channel H) and transmitted signals X under convex constraints. The approach iteratively refines G (or H) and X estimates alongside auxiliary and dual variables, employing proximal operators to manage potential non-smoothness in the constraint functions. This method stands out for its computational efficiency and adaptability to a wide array of signal processing and communication problems where blind deconvolution is pivotal. Performance analysis reveals a notable reduction in communication mismatch and demonstrates significant improvements in key system metrics such as the Signal-to-Interference-plus-Noise Ratio (SINR), spectrum efficiency, and radar mutual information, particularly within the context of 5G millimeter-wave (mmWave) systems. These results underscore the proposed framework's potential to enhance the synergy between radar and communication functions, promoting more effective spectrum utilisation and environmental sensing capabilities in next-generation wireless technologies.
Trade-offs in Reliability and Performance Using Selective Beamforming for Ultra-Massive MIMO
Jul 29, 2024



This paper addresses the optimisation challenges in Ultra-Massive MIMO communication systems, focusing on array selection and beamforming in dynamic and diverse operational contexts. We introduce a novel array selection criterion that incorporates antenna health information into the optimisation process, distinguishing our approach from traditional methods. Our methodology employs dual proximal-gradient ascent to effectively tackle the constrained non-convex and non-smooth nature of sparse array selection problems. A central feature of our strategy is the implementation of proportional fairness among communication users, aligning with system resource limitations while ensuring minimum rate requirements for all users. This approach not only enhances system efficiency and responsiveness but also ensures equitable resource distribution. Extensive simulations validate the effectiveness of the proposed solutions in optimising Ultra-Massive MIMO system performance, demonstrating their applicability in complex communication scenarios. Our findings reveal key trade-offs influenced by the sparsity promotion weight ({\gamma}). As {\gamma} increases, spectral efficiency (SE) and communication rate (Ri) decrease, while beamforming matrix density (BMD) reduces and antenna reliability (RL) significantly improves. These results highlight the critical balance between performance and reliability, essential for the practical deployment of Ultra-Massive MIMO systems. This work advances the field by providing innovative solutions and new insights into array selection and beamforming optimization, setting a foundation for future research in Ultra-Massive MIMO communication systems.
Context-Aware CSI Tracking and Path Loss Prediction Using Machine Learning and Dynamical Systems
Jul 29, 2024



In this paper, we present an advanced model for Channel State Information (CSI) tracking, leveraging a dynamical system approach to adapt CSI dynamically based on exogenous contextual information. This methodology allows for continuous updates to the Channel Knowledge Map (CKM), enhancing communication reliability and responsiveness in dynamic environments. To generate realistic and comprehensive datasets for training and evaluation, we developed a new MATLAB simulator that models radio wave propagation in urban environments. We address the challenge of real-time CKM adaptation using online learning of the Koopman operator, a technique that forecasts channel behaviour by exploiting dynamical system properties. Our approach supports real-time updates with high accuracy and efficiency, as demonstrated by experiments with varying window sizes for the Koopman Autoencoder model. A window size of 100 was found to offer the best balance between prediction accuracy (RMSE: 1.8323 +- 1.1071, MAE: 0.3780 +- 0.2221) and computational efficiency (training time: 231.1 +- 82.5 ms, prediction time: 109.0 +- 55.7 ms). Additionally, we introduce a moving window mechanism to address privacy and security concerns by updating the Koopman operator within the window and purging input data thereafter, minimising data retention and storage risks. This ensures the CKM remains accurate and relevant while maintaining stringent data privacy standards. Our findings suggest that this approach can significantly improve the resilience and security of communication systems, making them highly adaptable to environmental changes without compromising user privacy.
Reconfigurable FPGA-Based Solvers For Sparse Satellite Control
Jun 01, 2024



This paper introduces a novel reconfigurable and power-efficient FPGA (Field-Programmable Gate Array) implementation of an operator splitting algorithm for Non-Terrestial Network's (NTN) relay satellites model predictive orientation control (MPC). Our approach ensures system stability and introduces an innovative reconfigurable bit-width FPGA-based optimization solver. To demonstrate its efficacy, we employ a real FPGA-In-the-Loop hardware setup to control simulated satellite dynamics. Furthermore, we conduct an in-depth comparative analysis, examining various fixed-point configurations to evaluate the combined system's closed-loop performance and power efficiency, providing a holistic understanding of the proposed implementation's advantages.
Interference and noise cancellation for joint communication radar (JCR) system based on contextual information
Feb 14, 2023



This paper examines the separation of wireless communication and radar signals, thereby guaranteeing cohabitation and acting as a panacea to spectrum sensing. First, considering that the channel impulse response was known by the receivers (communication and radar), we showed that the optimizing beamforming weights mitigate the interference caused by signals and improve the physical layer security (PLS) of the system. Furthermore, when the channel responses were unknown, we designed an interference filter as a low-complex noise and interference cancellation autoencoder. By mitigating the interference on the legitimate users, the PLS was guaranteed. Results showed that even for a low signal-to-noise ratio, the autoencoder produces low root-mean-square error (RMSE) values.
A Novel Frame Structure for Cloud-Based Audio-Visual Speech Enhancement in Multimodal Hearing-aids
Oct 24, 2022



In this paper, we design a first of its kind transceiver (PHY layer) prototype for cloud-based audio-visual (AV) speech enhancement (SE) complying with high data rate and low latency requirements of future multimodal hearing assistive technology. The innovative design needs to meet multiple challenging constraints including up/down link communications, delay of transmission and signal processing, and real-time AV SE models processing. The transceiver includes device detection, frame detection, frequency offset estimation, and channel estimation capabilities. We develop both uplink (hearing aid to the cloud) and downlink (cloud to hearing aid) frame structures based on the data rate and latency requirements. Due to the varying nature of uplink information (audio and lip-reading), the uplink channel supports multiple data rate frame structure, while the downlink channel has a fixed data rate frame structure. In addition, we evaluate the latency of different PHY layer blocks of the transceiver for developed frame structures using LabVIEW NXG. This can be used with software defined radio (such as Universal Software Radio Peripheral) for real-time demonstration scenarios.
Machine Learning-based Urban Canyon Path Loss Prediction using 28 GHz Manhattan Measurements
Feb 10, 2022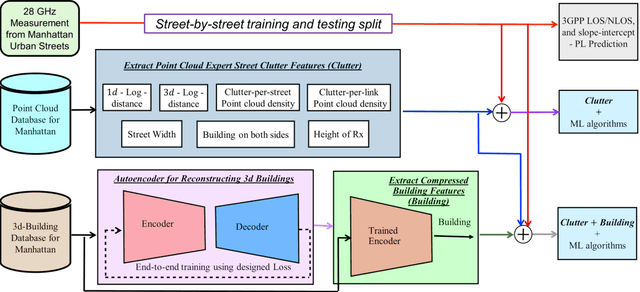
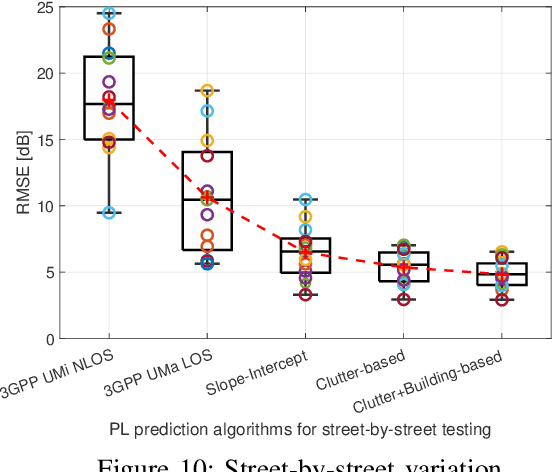
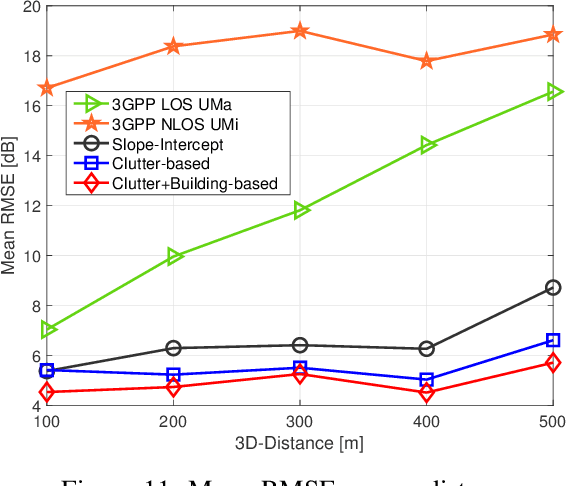
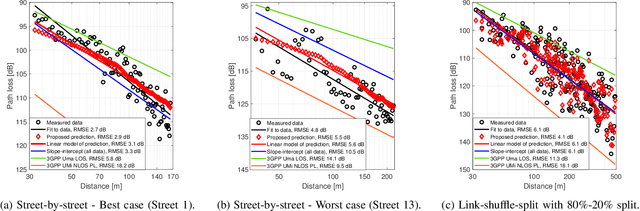
Large bandwidth at mm-wave is crucial for 5G and beyond but the high path loss (PL) requires highly accurate PL prediction for network planning and optimization. Statistical models with slope-intercept fit fall short in capturing large variations seen in urban canyons, whereas ray-tracing, capable of characterizing site-specific features, faces challenges in describing foliage and street clutter and associated reflection/diffraction ray calculation. Machine learning (ML) is promising but faces three key challenges in PL prediction: 1) insufficient measurement data; 2) lack of extrapolation to new streets; 3) overwhelmingly complex features/models. We propose an ML-based urban canyon PL prediction model based on extensive 28 GHz measurements from Manhattan where street clutters are modeled via a LiDAR point cloud dataset and buildings by a mesh-grid building dataset. We extract expert knowledge-driven street clutter features from the point cloud and aggressively compress 3D-building information using convolutional-autoencoder. Using a new street-by-street training and testing procedure to improve generalizability, the proposed model using both clutter and building features achieves a prediction error (RMSE) of $4.8 \pm 1.1$ dB compared to $10.6 \pm 4.4$ dB and $6.5 \pm 2.0$ dB for 3GPP LOS and slope-intercept prediction, respectively, where the standard deviation indicates street-by-street variation. By only using four most influential clutter features, RMSE of $5.5\pm 1.1$ dB is achieved.
Reinforcement Learning based Per-antenna Discrete Power Control for Massive MIMO Systems
Jan 28, 2021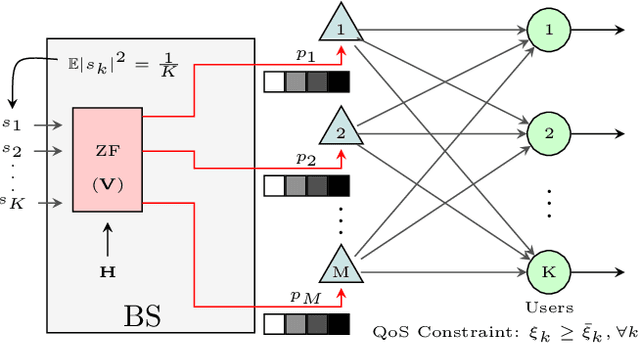
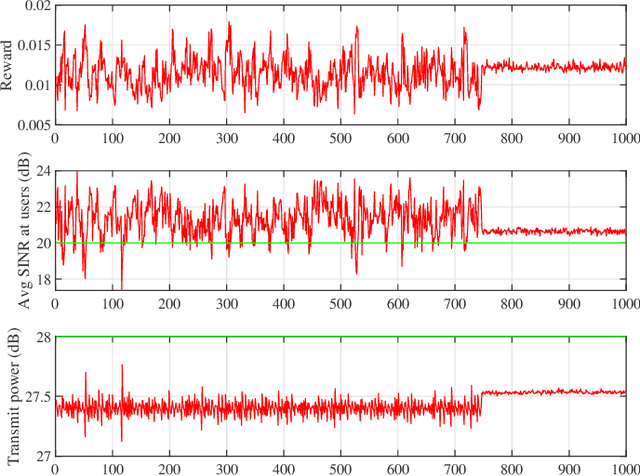
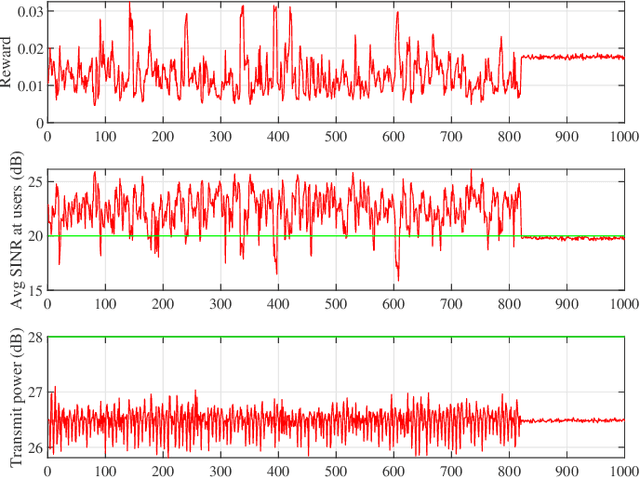
Power consumption is one of the major issues in massive MIMO (multiple input multiple output) systems, causing increased long-term operational cost and overheating issues. In this paper, we consider per-antenna power allocation with a given finite set of power levels towards maximizing the long-term energy efficiency of the multi-user systems, while satisfying the QoS (quality of service) constraints at the end users in terms of required SINRs (signal-to-interference-plus-noise ratio), which depends on channel information. Assuming channel states to vary as a Markov process, the constraint problem is modeled as an unconstraint problem, followed by the power allocation based on Q-learning algorithm. Simulation results are presented to demonstrate the successful minimization of power consumption while achieving the SINR threshold at users.