 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRight Is Not Enough: The Pitfalls of Outcome Supervision in Training LLMs for Math Reasoning
Jun 07, 2025Outcome-rewarded Large Language Models (LLMs) have demonstrated remarkable success in mathematical problem-solving. However, this success often masks a critical issue: models frequently achieve correct answers through fundamentally unsound reasoning processes, a phenomenon indicative of reward hacking. We introduce MathOlympiadEval, a new dataset with fine-grained annotations, which reveals a significant gap between LLMs' answer correctness and their low process correctness. Existing automated methods like LLM-as-a-judge struggle to reliably detect these reasoning flaws. To address this, we propose ParaStepVerifier, a novel methodology for meticulous, step-by-step verification of mathematical solutions. ParaStepVerifier identifies incorrect reasoning steps. Empirical results demonstrate that ParaStepVerifier substantially improves the accuracy of identifying flawed solutions compared to baselines, especially for complex, multi-step problems. This offers a more robust path towards evaluating and training LLMs with genuine mathematical reasoning.
Your Graph Recommender is Provably a Single-view Graph Contrastive Learning
Jul 25, 2024



Graph recommender (GR) is a type of graph neural network (GNNs) encoder that is customized for extracting information from the user-item interaction graph. Due to its strong performance on the recommendation task, GR has gained significant attention recently. Graph contrastive learning (GCL) is also a popular research direction that aims to learn, often unsupervised, GNNs with certain contrastive objectives. As a general graph representation learning method, GCLs have been widely adopted with the supervised recommendation loss for joint training of GRs. Despite the intersection of GR and GCL research, theoretical understanding of the relationship between the two fields is surprisingly sparse. This vacancy inevitably leads to inefficient scientific research. In this paper, we aim to bridge the gap between the field of GR and GCL from the perspective of encoders and loss functions. With mild assumptions, we theoretically show an astonishing fact that graph recommender is equivalent to a commonly-used single-view graph contrastive model. Specifically, we find that (1) the classic encoder in GR is essentially a linear graph convolutional network with one-hot inputs, and (2) the loss function in GR is well bounded by a single-view GCL loss with certain hyperparameters. The first observation enables us to explain crucial designs of GR models, e.g., the removal of self-loop and nonlinearity. And the second finding can easily prompt many cross-field research directions. We empirically show a remarkable result that the recommendation loss and the GCL loss can be used interchangeably. The fact that we can train GR models solely with the GCL loss is particularly insightful, since before this work, GCLs were typically viewed as unsupervised methods that need fine-tuning. We also discuss some potential future works inspired by our theory.
CoGANPPIS: Coevolution-enhanced Global Attention Neural Network for Protein-Protein Interaction Site Prediction
Apr 03, 2023



Protein-protein interactions are essential in biochemical processes. Accurate prediction of the protein-protein interaction sites (PPIs) deepens our understanding of biological mechanism and is crucial for new drug design. However, conventional experimental methods for PPIs prediction are costly and time-consuming so that many computational approaches, especially ML-based methods, have been developed recently. Although these approaches have achieved gratifying results, there are still two limitations: (1) Most models have excavated some useful input features, but failed to take coevolutionary features into account, which could provide clues for inter-residue relationships; (2) The attention-based models only allocate attention weights for neighboring residues, instead of doing it globally, neglecting that some residues being far away from the target residues might also matter. We propose a coevolution-enhanced global attention neural network, a sequence-based deep learning model for PPIs prediction, called CoGANPPIS. It utilizes three layers in parallel for feature extraction: (1) Local-level representation aggregation layer, which aggregates the neighboring residues' features; (2) Global-level representation learning layer, which employs a novel coevolution-enhanced global attention mechanism to allocate attention weights to all the residues on the same protein sequences; (3) Coevolutionary information learning layer, which applies CNN & pooling to coevolutionary information to obtain the coevolutionary profile representation. Then, the three outputs are concatenated and passed into several fully connected layers for the final prediction. Application on two benchmark datasets demonstrated a state-of-the-art performance of our model. The source code is publicly available at https://github.com/Slam1423/CoGANPPIS_source_code.
A Multi-Task Learning Framework for Overcoming the Catastrophic Forgetting in Automatic Speech Recognition
Apr 17, 2019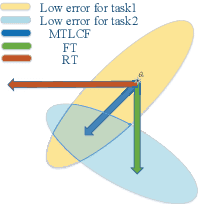
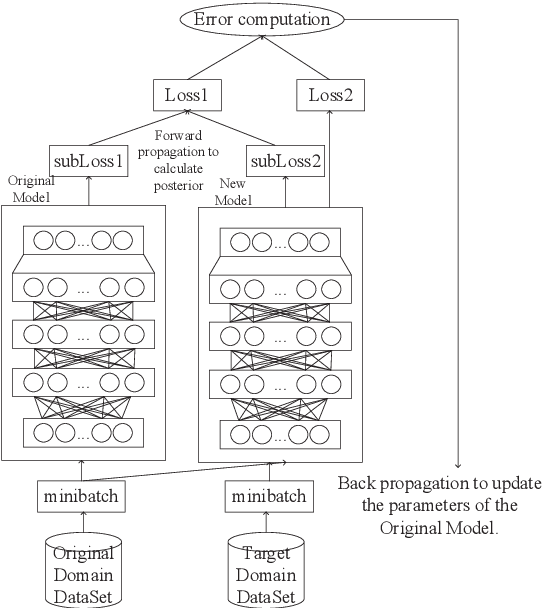
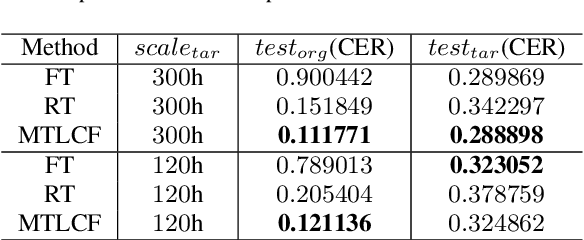
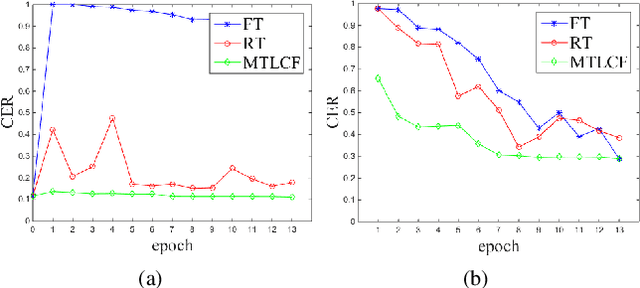
Recently, data-driven based Automatic Speech Recognition (ASR) systems have achieved state-of-the-art results. And transfer learning is often used when those existing systems are adapted to the target domain, e.g., fine-tuning, retraining. However, in the processes, the system parameters may well deviate too much from the previously learned parameters. Thus, it is difficult for the system training process to learn knowledge from target domains meanwhile not forgetting knowledge from the previous learning process, which is called as catastrophic forgetting (CF). In this paper, we attempt to solve the CF problem with the lifelong learning and propose a novel multi-task learning (MTL) training framework for ASR. It considers reserving original knowledge and learning new knowledge as two independent tasks, respectively. On the one hand, we constrain the new parameters not to deviate too far from the original parameters and punish the new system when forgetting original knowledge. On the other hand, we force the new system to solve new knowledge quickly. Then, a MTL mechanism is employed to get the balance between the two tasks. We applied our method to an End2End ASR task and obtained the best performance in both target and original datasets.
Hard Sample Mining for the Improved Retraining of Automatic Speech Recognition
Apr 17, 2019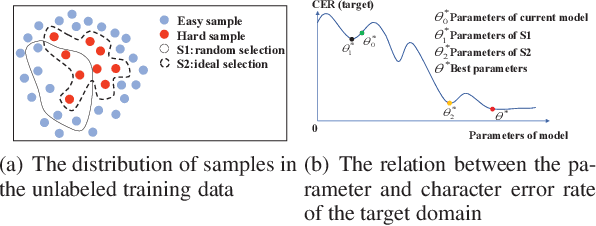
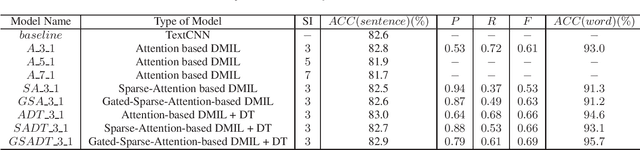
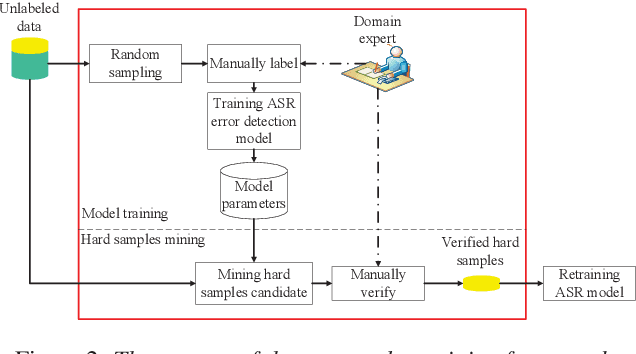

It is an effective way that improves the performance of the existing Automatic Speech Recognition (ASR) systems by retraining with more and more new training data in the target domain. Recently, Deep Neural Network (DNN) has become a successful model in the ASR field. In the training process of the DNN based methods, a back propagation of error between the transcription and the corresponding annotated text is used to update and optimize the parameters. Thus, the parameters are more influenced by the training samples with a big propagation error than the samples with a small one. In this paper, we define the samples with significant error as the hard samples and try to improve the performance of the ASR system by adding many of them. Unfortunately, the hard samples are sparse in the training data of the target domain, and manually label them is expensive. Therefore, we propose a hard samples mining method based on an enhanced deep multiple instance learning, which can find the hard samples from unlabeled training data by using a small subset of the dataset with manual labeling in the target domain. We applied our method to an End2End ASR task and obtained the best performance.