 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Gender Lost In Translation: How Bridging The Gap Between Languages Affects Gender Bias in Zero-Shot Multilingual Translation
May 26, 2023
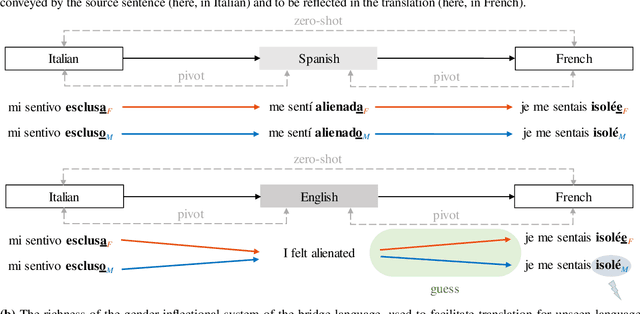
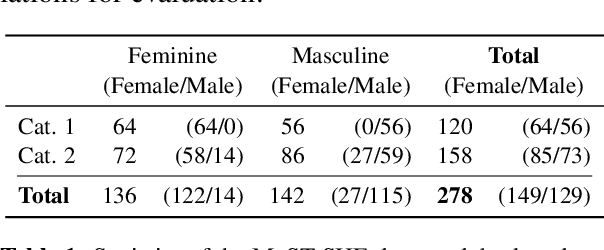
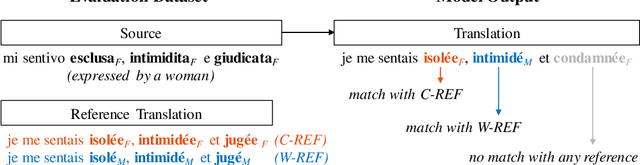
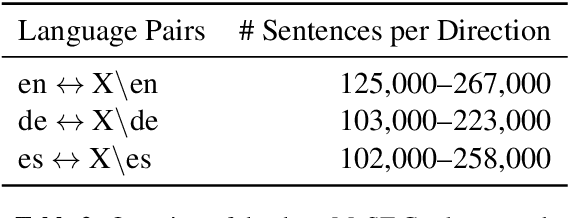
Neural machine translation (NMT) models often suffer from gender biases that harm users and society at large. In this work, we explore how bridging the gap between languages for which parallel data is not available affects gender bias in multilingual NMT, specifically for zero-shot directions. We evaluate translation between grammatical gender languages which requires preserving the inherent gender information from the source in the target language. We study the effect of encouraging language-agnostic hidden representations on models' ability to preserve gender and compare pivot-based and zero-shot translation regarding the influence of the bridge language (participating in all language pairs during training) on gender preservation. We find that language-agnostic representations mitigate zero-shot models' masculine bias, and with increased levels of gender inflection in the bridge language, pivoting surpasses zero-shot translation regarding fairer gender preservation for speaker-related gender agreement.
Uncertain Pose Estimation during Contact Tasks using Differentiable Contact Features
May 26, 2023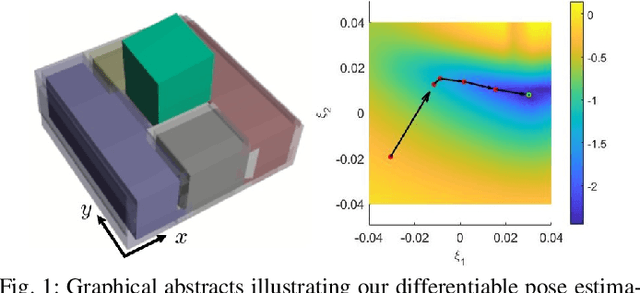
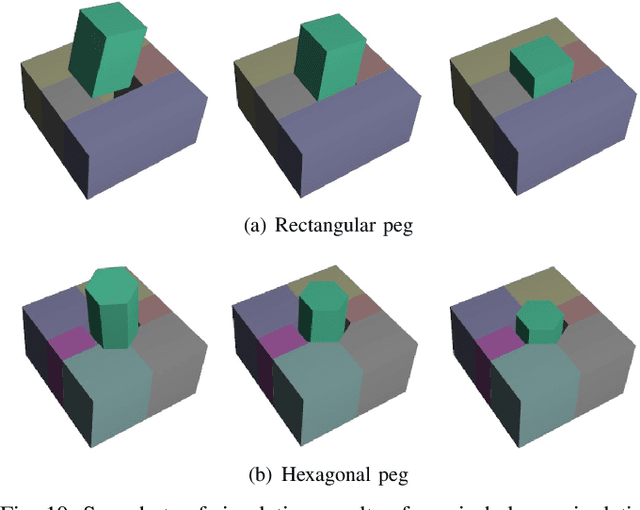
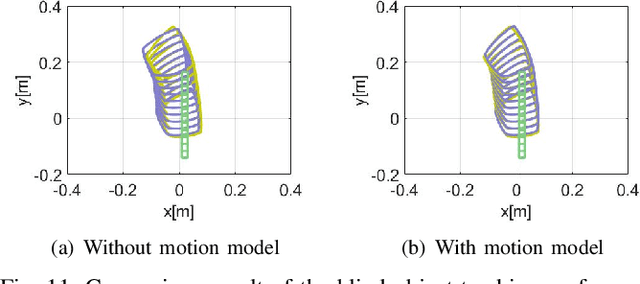

For many robotic manipulation and contact tasks, it is crucial to accurately estimate uncertain object poses, for which certain geometry and sensor information are fused in some optimal fashion. Previous results for this problem primarily adopt sampling-based or end-to-end learning methods, which yet often suffer from the issues of efficiency and generalizability. In this paper, we propose a novel differentiable framework for this uncertain pose estimation during contact, so that it can be solved in an efficient and accurate manner with gradient-based solver. To achieve this, we introduce a new geometric definition that is highly adaptable and capable of providing differentiable contact features. Then we approach the problem from a bi-level perspective and utilize the gradient of these contact features along with differentiable optimization to efficiently solve for the uncertain pose. Several scenarios are implemented to demonstrate how the proposed framework can improve existing methods.
People and Places of Historical Europe: Bootstrapping Annotation Pipeline and a New Corpus of Named Entities in Late Medieval Texts
May 26, 2023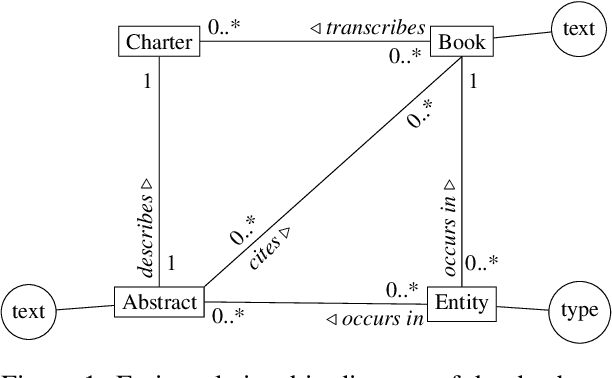
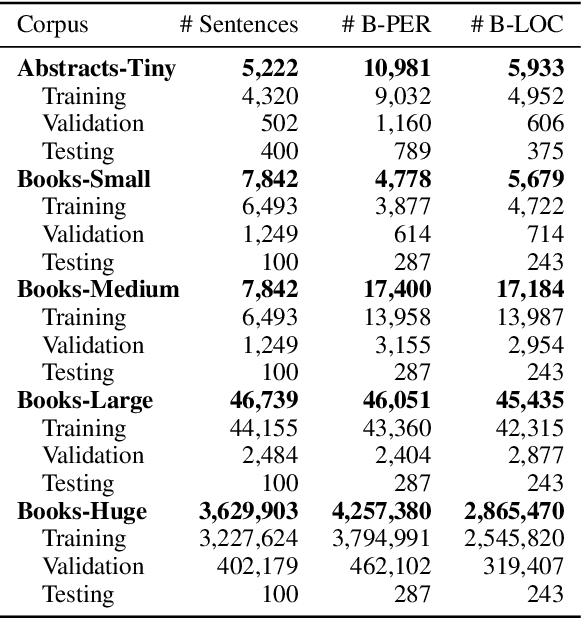
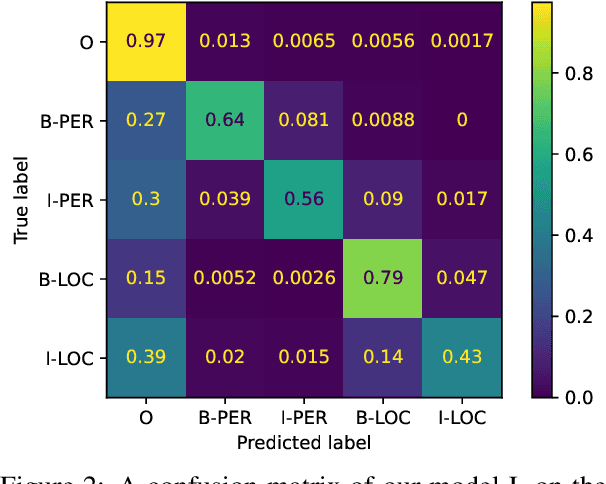
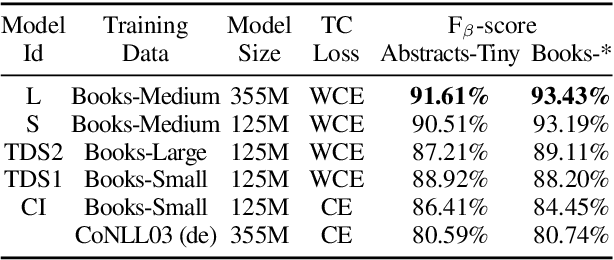
Although pre-trained named entity recognition (NER) models are highly accurate on modern corpora, they underperform on historical texts due to differences in language OCR errors. In this work, we develop a new NER corpus of 3.6M sentences from late medieval charters written mainly in Czech, Latin, and German. We show that we can start with a list of known historical figures and locations and an unannotated corpus of historical texts, and use information retrieval techniques to automatically bootstrap a NER-annotated corpus. Using our corpus, we train a NER model that achieves entity-level Precision of 72.81-93.98% with 58.14-81.77% Recall on a manually-annotated test dataset. Furthermore, we show that using a weighted loss function helps to combat class imbalance in token classification tasks. To make it easy for others to reproduce and build upon our work, we publicly release our corpus, models, and experimental code.
Exploiting Abstract Meaning Representation for Open-Domain Question Answering
May 26, 2023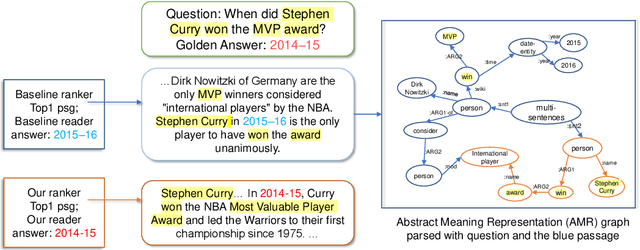
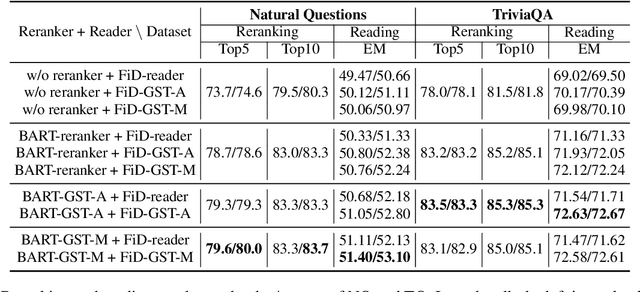
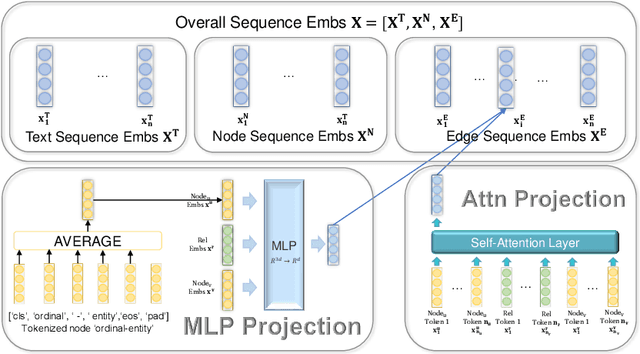
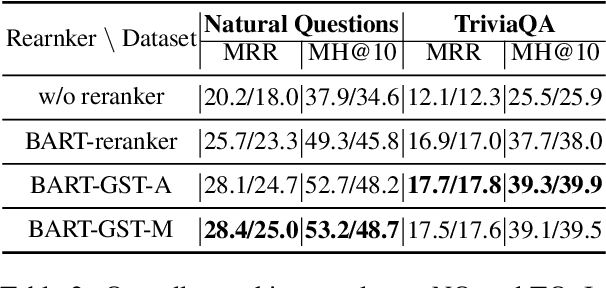
The Open-Domain Question Answering (ODQA) task involves retrieving and subsequently generating answers from fine-grained relevant passages within a database. Current systems leverage Pretrained Language Models (PLMs) to model the relationship between questions and passages. However, the diversity in surface form expressions can hinder the model's ability to capture accurate correlations, especially within complex contexts. Therefore, we utilize Abstract Meaning Representation (AMR) graphs to assist the model in understanding complex semantic information. We introduce a method known as Graph-as-Token (GST) to incorporate AMRs into PLMs. Results from Natural Questions (NQ) and TriviaQA (TQ) demonstrate that our GST method can significantly improve performance, resulting in up to 2.44/3.17 Exact Match score improvements on NQ/TQ respectively. Furthermore, our method enhances robustness and outperforms alternative Graph Neural Network (GNN) methods for integrating AMRs. To the best of our knowledge, we are the first to employ semantic graphs in ODQA.
Diagnostic Spatio-temporal Transformer with Faithful Encoding
May 26, 2023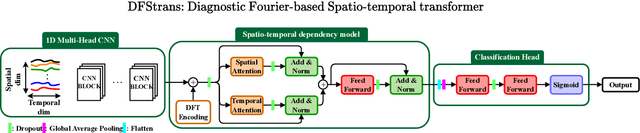
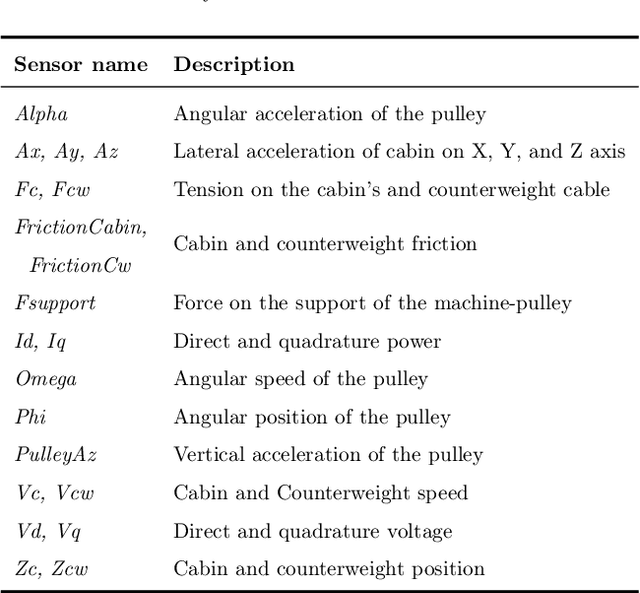
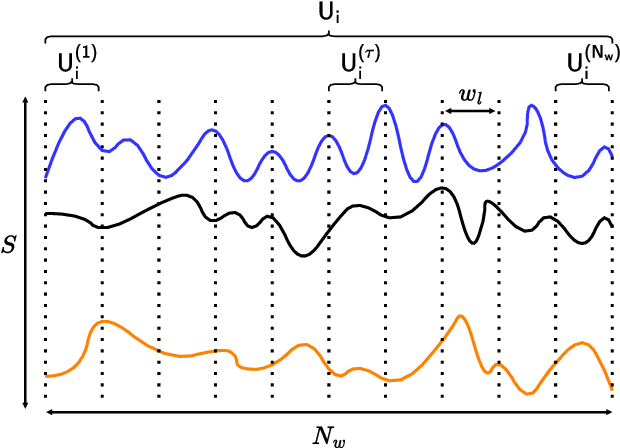
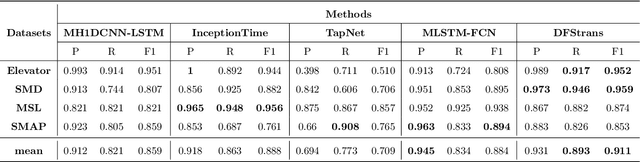
This paper addresses the task of anomaly diagnosis when the underlying data generation process has a complex spatio-temporal (ST) dependency. The key technical challenge is to extract actionable insights from the dependency tensor characterizing high-order interactions among temporal and spatial indices. We formalize the problem as supervised dependency discovery, where the ST dependency is learned as a side product of multivariate time-series classification. We show that temporal positional encoding used in existing ST transformer works has a serious limitation in capturing higher frequencies (short time scales). We propose a new positional encoding with a theoretical guarantee, based on discrete Fourier transform. We also propose a new ST dependency discovery framework, which can provide readily consumable diagnostic information in both spatial and temporal directions. Finally, we demonstrate the utility of the proposed model, DFStrans (Diagnostic Fourier-based Spatio-temporal Transformer), in a real industrial application of building elevator control.
Multi S-graphs: A Collaborative Semantic SLAM architecture
May 05, 2023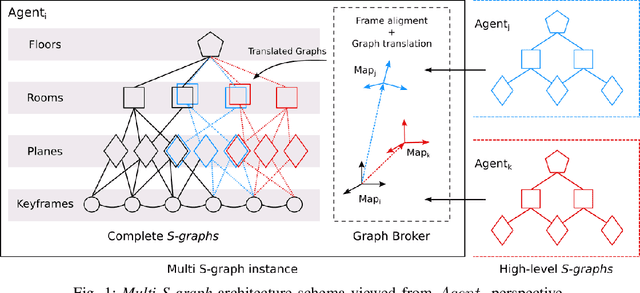
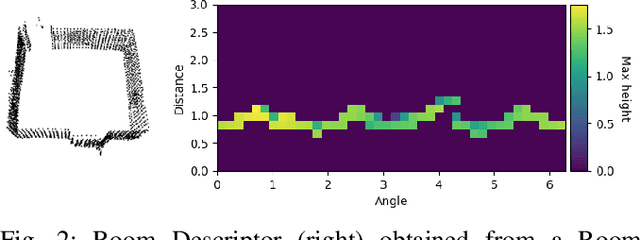
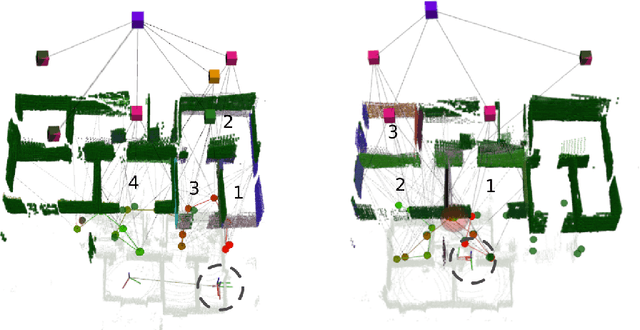

Collaborative Simultaneous Localization and Mapping (CSLAM) is a critical capability for enabling multiple robots to operate in complex environments. Most CSLAM techniques rely on the transmission of low-level features for visual and LiDAR-based approaches, which are used for pose graph optimization. However, these low-level features can lead to incorrect loop closures, negatively impacting map generation.Recent approaches have proposed the use of high-level semantic information in the form of Hierarchical Semantic Graphs to improve the loop closure procedures and overall precision of SLAM algorithms. In this work, we present Multi S-Graphs, an S-graphs [1] based distributed CSLAM algorithm that utilizes high-level semantic information for cooperative map generation while minimizing the amount of information exchanged between robots. Experimental results demonstrate the promising performance of the proposed algorithm in map generation tasks.
Characterizing information loss in a chaotic double pendulum with the Information Bottleneck
Oct 25, 2022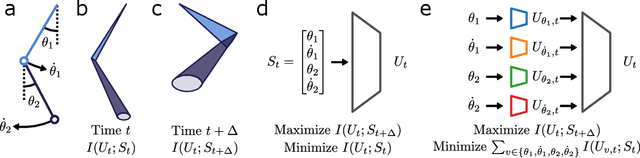

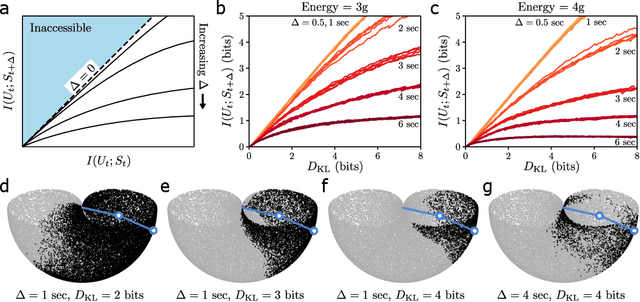
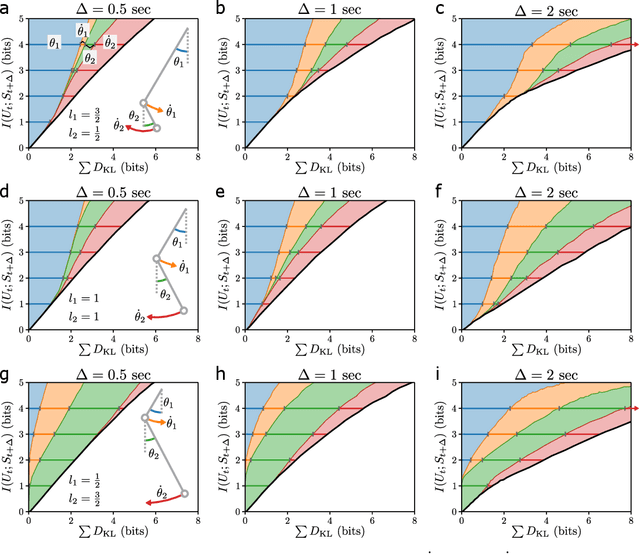
A hallmark of chaotic dynamics is the loss of information with time. Although information loss is often expressed through a connection to Lyapunov exponents -- valid in the limit of high information about the system state -- this picture misses the rich spectrum of information decay across different levels of granularity. Here we show how machine learning presents new opportunities for the study of information loss in chaotic dynamics, with a double pendulum serving as a model system. We use the Information Bottleneck as a training objective for a neural network to extract information from the state of the system that is optimally predictive of the future state after a prescribed time horizon. We then decompose the optimally predictive information by distributing a bottleneck to each state variable, recovering the relative importance of the variables in determining future evolution. The framework we develop is broadly applicable to chaotic systems and pragmatic to apply, leveraging data and machine learning to monitor the limits of predictability and map out the loss of information.
GPU-based Private Information Retrieval for On-Device Machine Learning Inference
Jan 26, 2023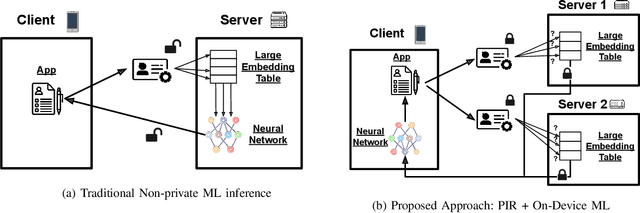
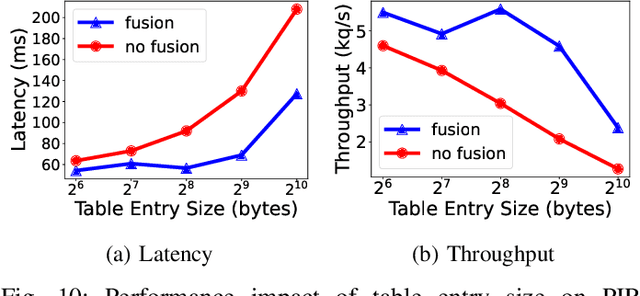
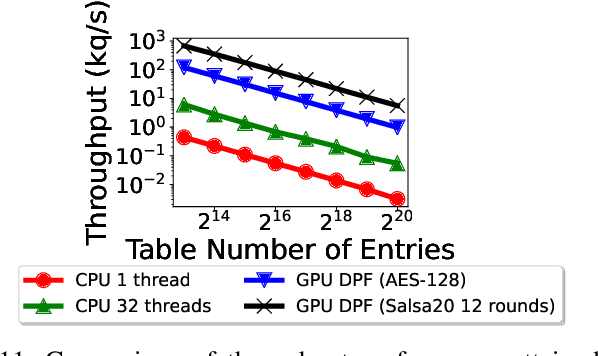

On-device machine learning (ML) inference can enable the use of private user data on user devices without remote servers. However, a pure on-device solution to private ML inference is impractical for many applications that rely on embedding tables that are too large to be stored on-device. To overcome this barrier, we propose the use of private information retrieval (PIR) to efficiently and privately retrieve embeddings from servers without sharing any private information during on-device ML inference. As off-the-shelf PIR algorithms are usually too computationally intensive to directly use for latency-sensitive inference tasks, we 1) develop a novel algorithm for accelerating PIR on GPUs, and 2) co-design PIR with the downstream ML application to obtain further speedup. Our GPU acceleration strategy improves system throughput by more than $20 \times$ over an optimized CPU PIR implementation, and our co-design techniques obtain over $5 \times$ additional throughput improvement at fixed model quality. Together, on various on-device ML applications such as recommendation and language modeling, our system on a single V100 GPU can serve up to $100,000$ queries per second -- a $>100 \times$ throughput improvement over a naively implemented system -- while maintaining model accuracy, and limiting inference communication and response latency to within $300$KB and $<100$ms respectively.
Joint Channel Estimation and Turbo Equalization of Single-Carrier Systems over Time-Varying Channels
May 16, 2023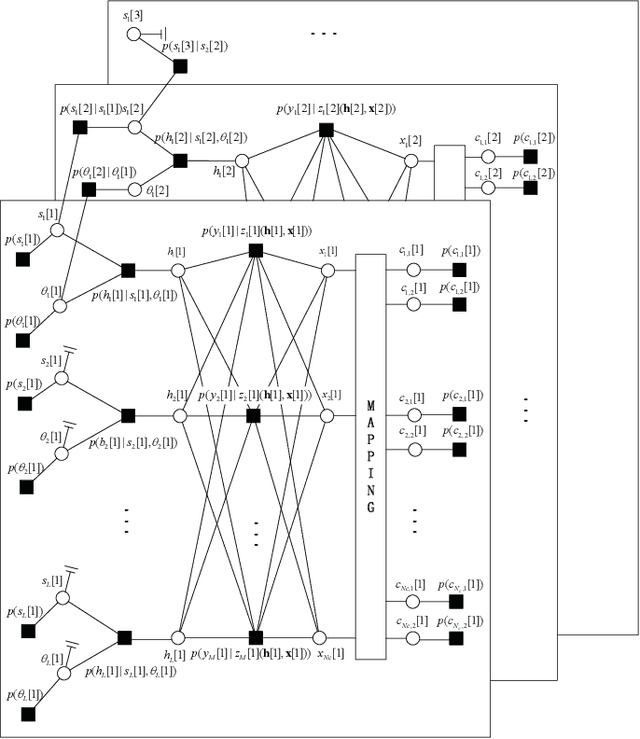
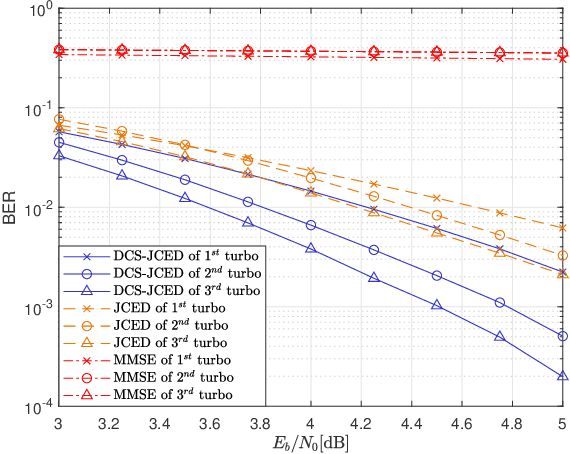
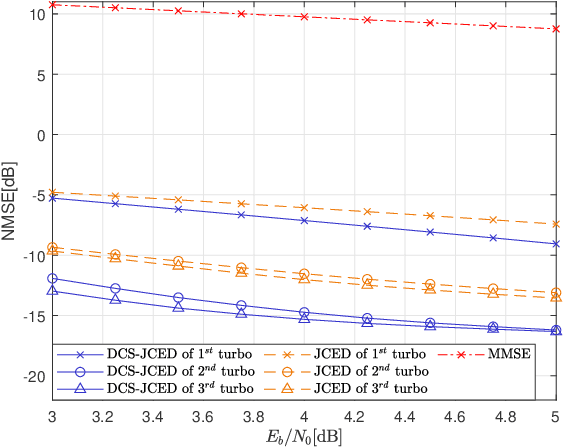
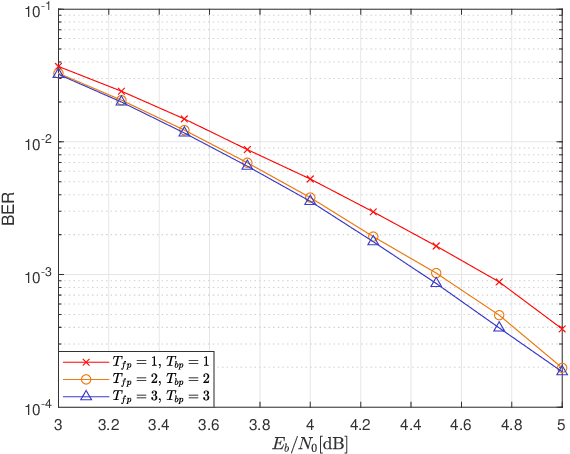
Block transmission systems have been proven successful over frequency-selective channels. For time-varying channel such as in high-speed mobile communication and underwater communication, existing equalizers assume that channels over different data frames are independent. However, the real-world channels over different data frames are correlated, thereby indicating potentials for performance improvement. In this paper, we propose a joint channel estimation and equalization/decoding algorithm for a single-carrier system that exploits temporal correlations of channel between transmitted data frames. Leveraging the concept of dynamic compressive sensing, our method can utilize the information of several data frames to achieve better performance. The information not only passes between the channel and symbol, but also the channels over different data frames. Numerical simulations using an extensively validated underwater acoustic model with a time-varying channel establish that the proposed algorithm outperforms the former bilinear generalized approximate message passing equalizer and classic minimum mean square error turbo equalizer in bit error rate and channel estimation normalized mean square error. The algorithm idea we present can also find applications in other bilinear multiple measurements vector compressive sensing problems.
Prompt-Guided Retrieval Augmentation for Non-Knowledge-Intensive Tasks
May 28, 2023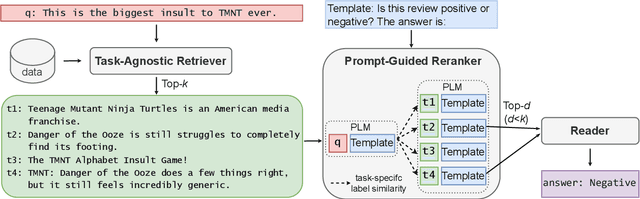

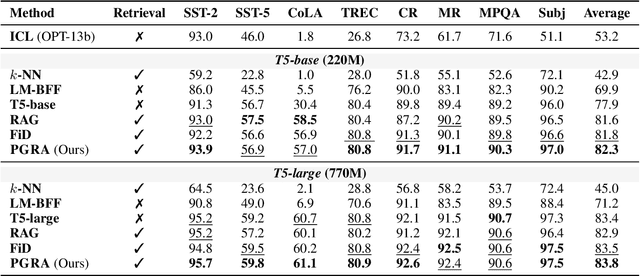
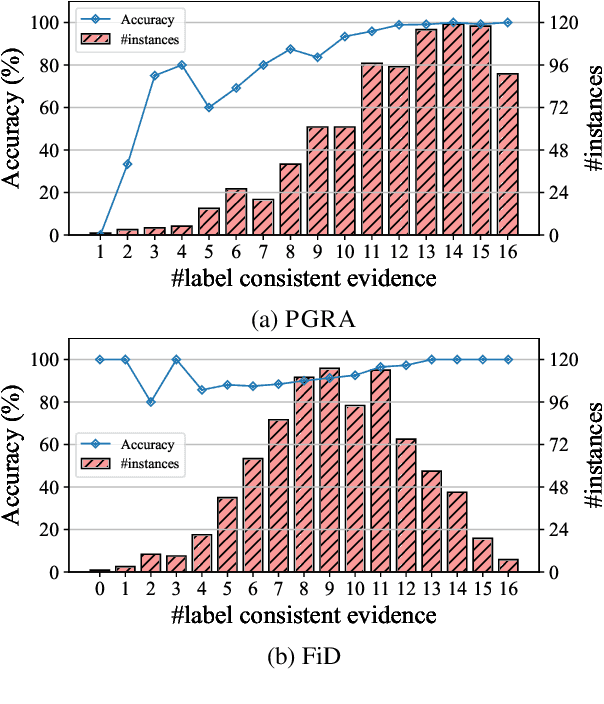
Retrieval-augmented methods have received increasing attention to support downstream tasks by leveraging useful information from external resources. Recent studies mainly focus on exploring retrieval to solve knowledge-intensive (KI) tasks. However, the potential of retrieval for most non-knowledge-intensive (NKI) tasks remains under-explored. There are two main challenges to leveraging retrieval-augmented methods for NKI tasks: 1) the demand for diverse relevance score functions and 2) the dilemma between training cost and task performance. To address these challenges, we propose a two-stage framework for NKI tasks, named PGRA. In the first stage, we adopt a task-agnostic retriever to build a shared static index and select candidate evidence efficiently. In the second stage, we design a prompt-guided reranker to rerank the nearest evidence according to task-specific relevance for the reader. Experimental results show that PGRA outperforms other state-of-the-art retrieval-augmented methods. Our analyses further investigate the influence factors to model performance and demonstrate the generality of PGRA. Codes are available at https://github.com/THUNLP-MT/PGRA.