 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU-based Private Information Retrieval for On-Device Machine Learning Inference
Jan 27, 2023



On-device machine learning (ML) inference can enable the use of private user data on user devices without remote servers. However, a pure on-device solution to private ML inference is impractical for many applications that rely on embedding tables that are too large to be stored on-device. To overcome this barrier, we propose the use of private information retrieval (PIR) to efficiently and privately retrieve embeddings from servers without sharing any private information during on-device ML inference. As off-the-shelf PIR algorithms are usually too computationally intensive to directly use for latency-sensitive inference tasks, we 1) develop a novel algorithm for accelerating PIR on GPUs, and 2) co-design PIR with the downstream ML application to obtain further speedup. Our GPU acceleration strategy improves system throughput by more than $20 \times$ over an optimized CPU PIR implementation, and our co-design techniques obtain over $5 \times$ additional throughput improvement at fixed model quality. Together, on various on-device ML applications such as recommendation and language modeling, our system on a single V100 GPU can serve up to $100,000$ queries per second -- a $>100 \times$ throughput improvement over a naively implemented system -- while maintaining model accuracy, and limiting inference communication and response latency to within $300$KB and $<100$ms respectively.
Tabula: Efficiently Computing Nonlinear Activation Functions for Secure Neural Network Inference
Mar 05, 2022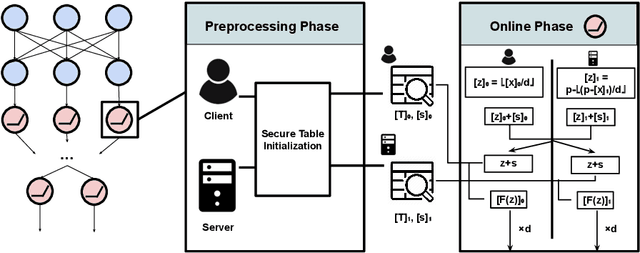

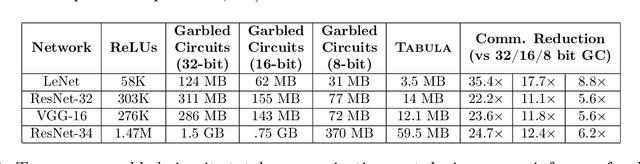
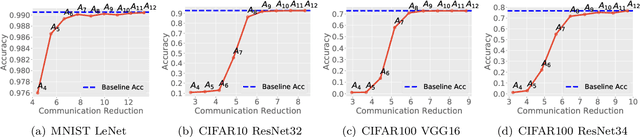
Multiparty computation approaches to secure neural network inference traditionally rely on garbled circuits for securely executing nonlinear activation functions. However, garbled circuits require excessive communication between server and client, impose significant storage overheads, and incur large runtime penalties. To eliminate these costs, we propose an alternative to garbled circuits: Tabula, an algorithm based on secure lookup tables. Tabula leverages neural networks' ability to be quantized and employs a secure lookup table approach to efficiently, securely, and accurately compute neural network nonlinear activation functions. Compared to garbled circuits with quantized inputs, when computing individual nonlinear functions, our experiments show Tabula uses between $35 \times$-$70 \times$ less communication, is over $100\times$ faster, and uses a comparable amount of storage. This leads to significant performance gains over garbled circuits with quantized inputs during secure inference on neural networks: Tabula reduces overall communication by up to $9 \times$ and achieves a speedup of up to $50 \times$, while imposing comparable storage costs.
The People's Speech: A Large-Scale Diverse English Speech Recognition Dataset for Commercial Usage
Nov 17, 2021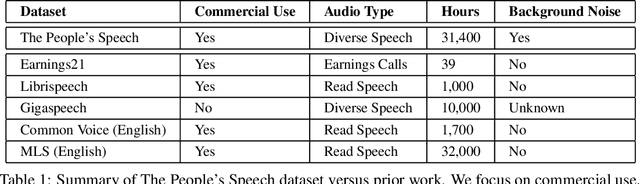
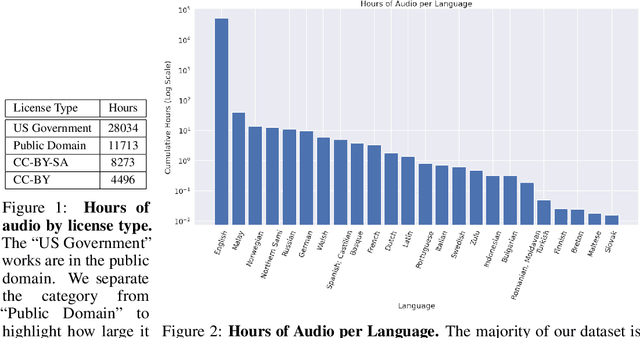

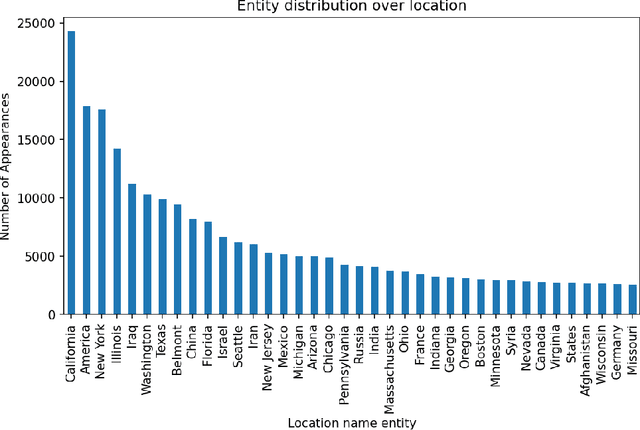
The People's Speech is a free-to-download 30,000-hour and growing supervised conversational English speech recognition dataset licensed for academic and commercial usage under CC-BY-SA (with a CC-BY subset). The data is collected via searching the Internet for appropriately licensed audio data with existing transcriptions. We describe our data collection methodology and release our data collection system under the Apache 2.0 license. We show that a model trained on this dataset achieves a 9.98% word error rate on Librispeech's test-clean test set.Finally, we discuss the legal and ethical issues surrounding the creation of a sizable machine learning corpora and plans for continued maintenance of the project under MLCommons's sponsorship.
Gradient Disaggregation: Breaking Privacy in Federated Learning by Reconstructing the User Participant Matrix
Jun 10, 2021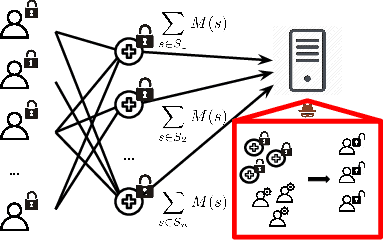
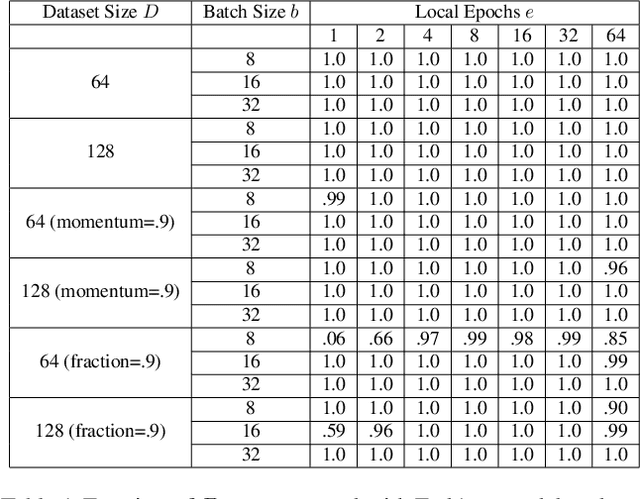
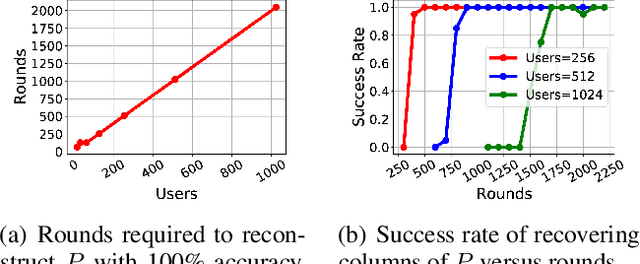

We show that aggregated model updates in federated learning may be insecure. An untrusted central server may disaggregate user updates from sums of updates across participants given repeated observations, enabling the server to recover privileged information about individual users' private training data via traditional gradient inference attacks. Our method revolves around reconstructing participant information (e.g: which rounds of training users participated in) from aggregated model updates by leveraging summary information from device analytics commonly used to monitor, debug, and manage federated learning systems. Our attack is parallelizable and we successfully disaggregate user updates on settings with up to thousands of participants. We quantitatively and qualitatively demonstrate significant improvements in the capability of various inference attacks on the disaggregated updates. Our attack enables the attribution of learned properties to individual users, violating anonymity, and shows that a determined central server may undermine the secure aggregation protocol to break individual users' data privacy in federated learning.
Widening Access to Applied Machine Learning with TinyML
Jun 09, 2021
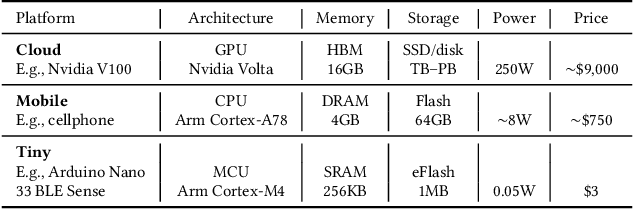

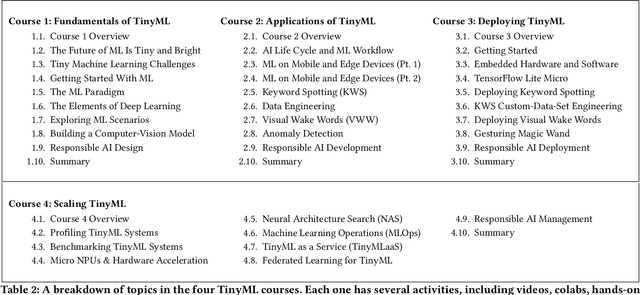
Broadening access to both computational and educational resources is critical to diffusing machine-learning (ML) innovation. However, today, most ML resources and experts are siloed in a few countries and organizations. In this paper, we describe our pedagogical approach to increasing access to applied ML through a massive open online course (MOOC) on Tiny Machine Learning (TinyML). We suggest that TinyML, ML on resource-constrained embedded devices, is an attractive means to widen access because TinyML both leverages low-cost and globally accessible hardware, and encourages the development of complete, self-contained applications, from data collection to deployment. To this end, a collaboration between academia (Harvard University) and industry (Google) produced a four-part MOOC that provides application-oriented instruction on how to develop solutions using TinyML. The series is openly available on the edX MOOC platform, has no prerequisites beyond basic programming, and is designed for learners from a global variety of backgrounds. It introduces pupils to real-world applications, ML algorithms, data-set engineering, and the ethical considerations of these technologies via hands-on programming and deployment of TinyML applications in both the cloud and their own microcontrollers. To facilitate continued learning, community building, and collaboration beyond the courses, we launched a standalone website, a forum, a chat, and an optional course-project competition. We also released the course materials publicly, hoping they will inspire the next generation of ML practitioners and educators and further broaden access to cutting-edge ML technologies.
Quantized Neural Network Inference with Precision Batching
Feb 26, 2020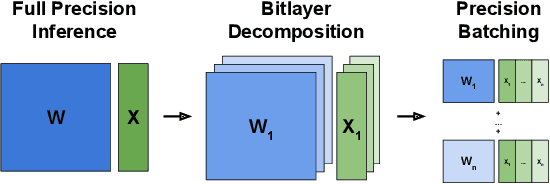
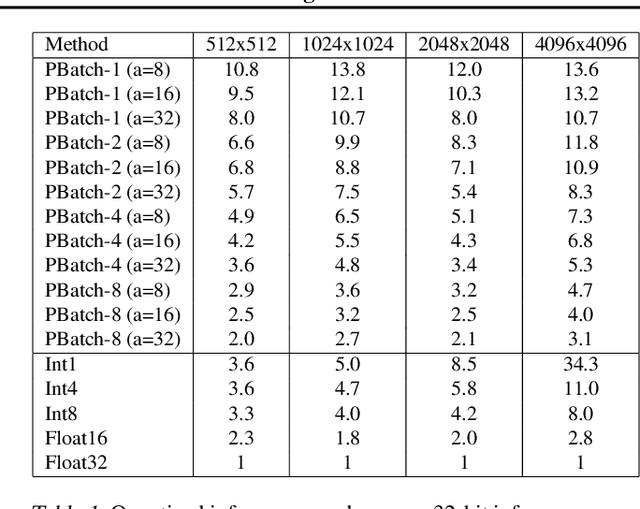
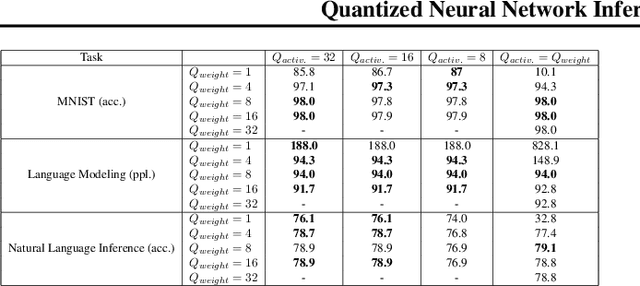
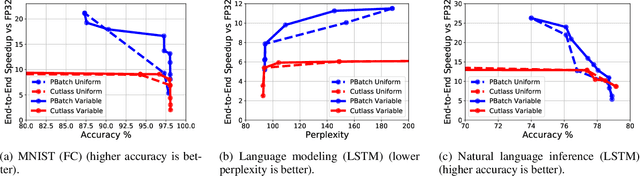
We present PrecisionBatching, a quantized inference algorithm for speeding up neural network execution on traditional hardware platforms at low bitwidths without the need for retraining or recalibration. PrecisionBatching decomposes a neural network into individual bitlayers and accumulates them using fast 1-bit operations while maintaining activations in full precision. PrecisionBatching not only facilitates quantized inference at low bitwidths (< 8 bits) without the need for retraining/recalibration, but also 1) enables traditional hardware platforms the ability to realize inference speedups at a finer granularity of quantization (e.g: 1-16 bit execution) and 2) allows accuracy and speedup tradeoffs at runtime by exposing the number of bitlayers to accumulate as a tunable parameter. Across a variety of applications (MNIST, language modeling, natural language inference) and neural network architectures (fully connected, RNN, LSTM), PrecisionBatching yields end-to-end speedups of over 8x on a GPU within a < 1% error margin of the full precision baseline, outperforming traditional 8-bit quantized inference by over 1.5x-2x at the same error tolerance.
Quantized Reinforcement Learning (QUARL)
Oct 04, 2019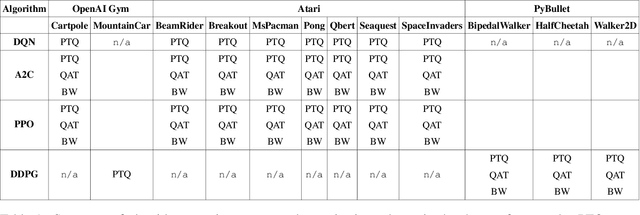
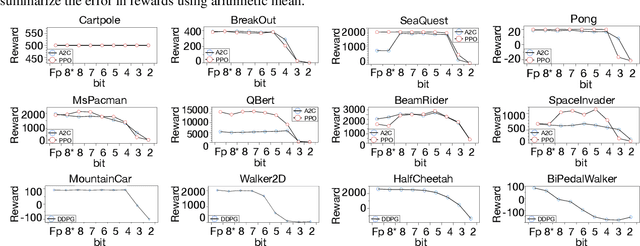
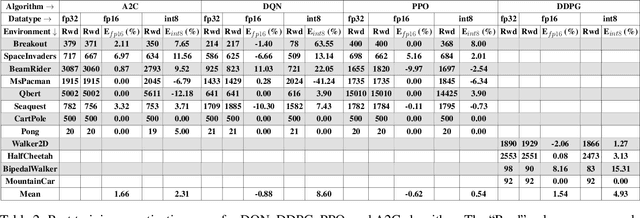
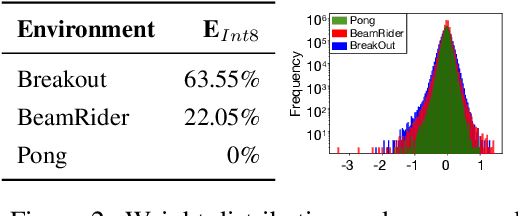
Recent work has shown that quantization can help reduce the memory, compute, and energy demands of deep neural networks without significantly harming their quality. However, whether these prior techniques, applied traditionally to image-based models, work with the same efficacy to the sequential decision making process in reinforcement learning remains an unanswered question. To address this void, we conduct the first comprehensive empirical study that quantifies the effects of quantization on various deep reinforcement learning policies with the intent to reduce their computational resource demands. We apply techniques such as post-training quantization and quantization aware training to a spectrum of reinforcement learning tasks (such as Pong, Breakout, BeamRider and more) and training algorithms (such as PPO, A2C, DDPG, and DQN). Across this spectrum of tasks and learning algorithms, we show that policies can be quantized to 6-8 bits of precision without loss of accuracy. We also show that certain tasks and reinforcement learning algorithms yield policies that are more difficult to quantize due to their effect of widening the models' distribution of weights and that quantization aware training consistently improves results over post-training quantization and oftentimes even over the full precision baseline. Finally, we demonstrate real-world applications of quantization for reinforcement learning. We use half-precision training to train a Pong model 50% faster, and we deploy a quantized reinforcement learning based navigation policy to an embedded system, achieving an 18$\times$ speedup and a 4$\times$ reduction in memory usage over an unquantized policy.
Word2Bits - Quantized Word Vectors
Mar 31, 2018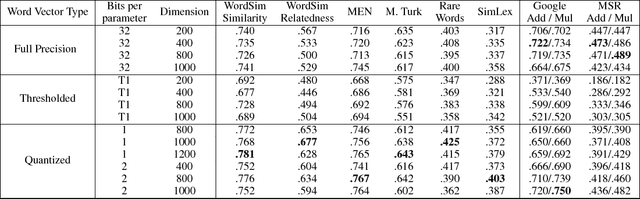
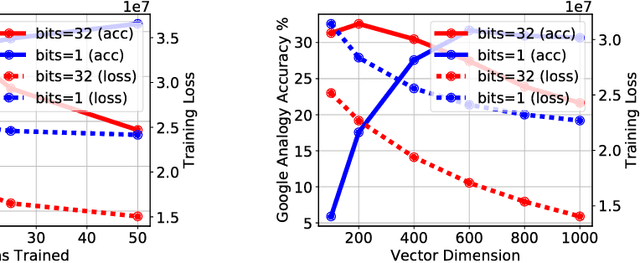
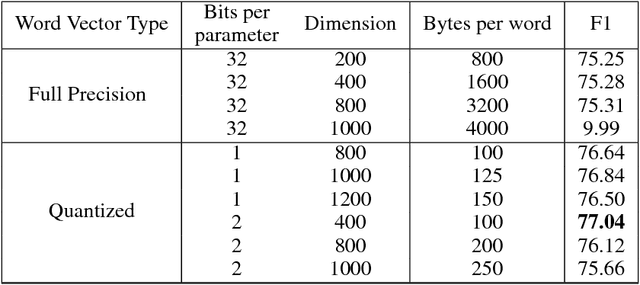
Word vectors require significant amounts of memory and storage, posing issues to resource limited devices like mobile phones and GPUs. We show that high quality quantized word vectors using 1-2 bits per parameter can be learned by introducing a quantization function into Word2Vec. We furthermore show that training with the quantization function acts as a regularizer. We train word vectors on English Wikipedia (2017) and evaluate them on standard word similarity and analogy tasks and on question answering (SQuAD). Our quantized word vectors not only take 8-16x less space than full precision (32 bit) word vectors but also outperform them on word similarity tasks and question answering.
Speeding Up Distributed Machine Learning Using Codes
Jan 29, 2018
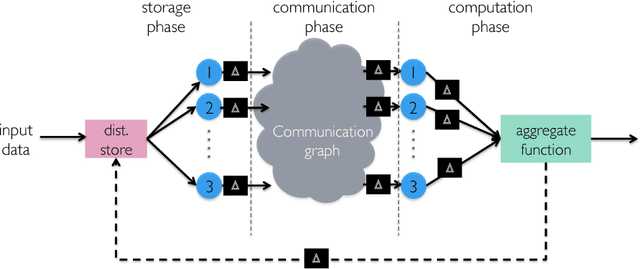
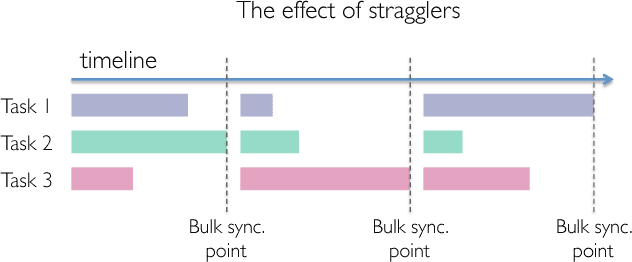
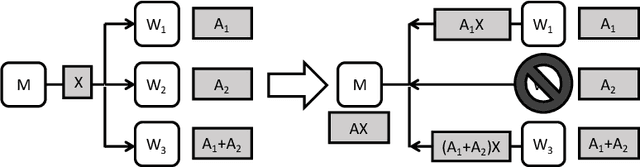
Codes are widely used in many engineering applications to offer robustness against noise. In large-scale systems there are several types of noise that can affect the performance of distributed machine learning algorithms -- straggler nodes, system failures, or communication bottlenecks -- but there has been little interaction cutting across codes, machine learning, and distributed systems. In this work, we provide theoretical insights on how coded solutions can achieve significant gains compared to uncoded ones. We focus on two of the most basic building blocks of distributed learning algorithms: matrix multiplication and data shuffling. For matrix multiplication, we use codes to alleviate the effect of stragglers, and show that if the number of homogeneous workers is $n$, and the runtime of each subtask has an exponential tail, coded computation can speed up distributed matrix multiplication by a factor of $\log n$. For data shuffling, we use codes to reduce communication bottlenecks, exploiting the excess in storage. We show that when a constant fraction $\alpha$ of the data matrix can be cached at each worker, and $n$ is the number of workers, \emph{coded shuffling} reduces the communication cost by a factor of $(\alpha + \frac{1}{n})\gamma(n)$ compared to uncoded shuffling, where $\gamma(n)$ is the ratio of the cost of unicasting $n$ messages to $n$ users to multicasting a common message (of the same size) to $n$ users. For instance, $\gamma(n) \simeq n$ if multicasting a message to $n$ users is as cheap as unicasting a message to one user. We also provide experiment results, corroborating our theoretical gains of the coded algorithms.
CYCLADES: Conflict-free Asynchronous Machine Learning
May 31, 2016
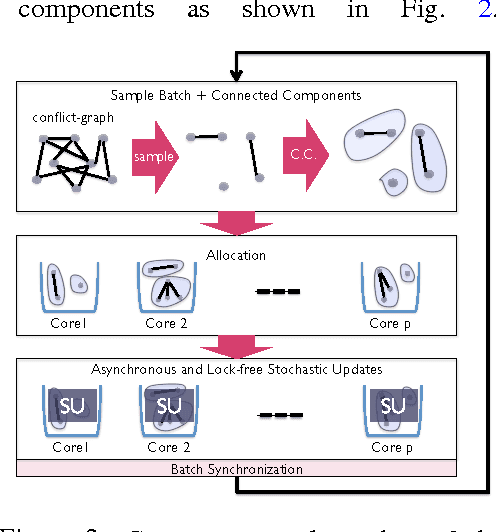

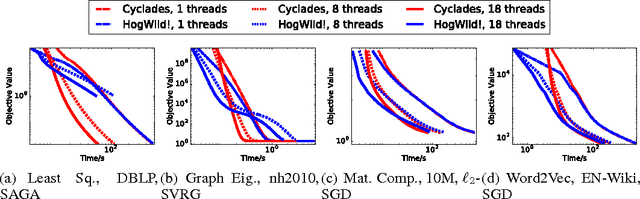
We present CYCLADES, a general framework for parallelizing stochastic optimization algorithms in a shared memory setting. CYCLADES is asynchronous during shared model updates, and requires no memory locking mechanisms, similar to HOGWILD!-type algorithms. Unlike HOGWILD!, CYCLADES introduces no conflicts during the parallel execution, and offers a black-box analysis for provable speedups across a large family of algorithms. Due to its inherent conflict-free nature and cache locality, our multi-core implementation of CYCLADES consistently outperforms HOGWILD!-type algorithms on sufficiently sparse datasets, leading to up to 40% speedup gains compared to the HOGWILD! implementation of SGD, and up to 5x gains over asynchronous implementations of variance reduction algorithms.