 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OxfordTVG-HIC: Can Machine Make Humorous Captions from Images?
Jul 21, 2023

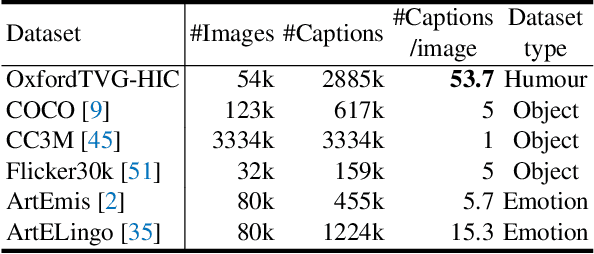
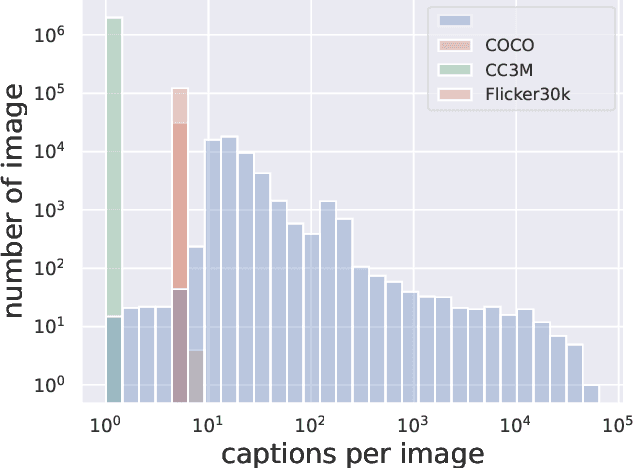
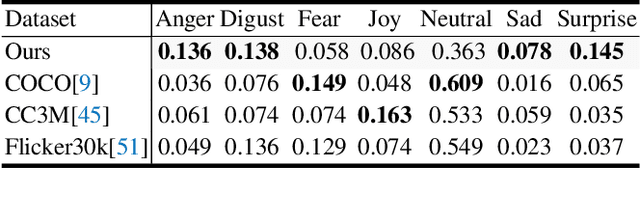
This paper presents OxfordTVG-HIC (Humorous Image Captions), a large-scale dataset for humour generation and understanding. Humour is an abstract, subjective, and context-dependent cognitive construct involving several cognitive factors, making it a challenging task to generate and interpret. Hence, humour generation and understanding can serve as a new task for evaluating the ability of deep-learning methods to process abstract and subjective information. Due to the scarcity of data, humour-related generation tasks such as captioning remain under-explored. To address this gap, OxfordTVG-HIC offers approximately 2.9M image-text pairs with humour scores to train a generalizable humour captioning model. Contrary to existing captioning datasets, OxfordTVG-HIC features a wide range of emotional and semantic diversity resulting in out-of-context examples that are particularly conducive to generating humour. Moreover, OxfordTVG-HIC is curated devoid of offensive content. We also show how OxfordTVG-HIC can be leveraged for evaluating the humour of a generated text. Through explainability analysis of the trained models, we identify the visual and linguistic cues influential for evoking humour prediction (and generation). We observe qualitatively that these cues are aligned with the benign violation theory of humour in cognitive psychology.
Seismic Data Interpolation based on Denoising Diffusion Implicit Models with Resampling
Jul 13, 2023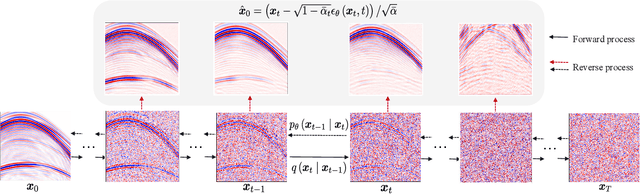
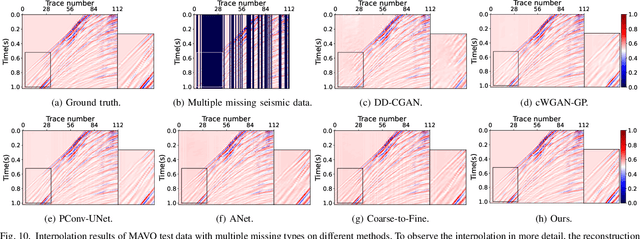


The incompleteness of the seismic data caused by missing traces along the spatial extension is a common issue in seismic acquisition due to the existence of obstacles and economic constraints, which severely impairs the imaging quality of subsurface geological structures. Recently, deep learningbased seismic interpolation methods have attained promising progress, while achieving stable training of generative adversarial networks is not easy, and performance degradation is usually notable if the missing patterns in the testing and training do not match. In this paper, we propose a novel seismic denoising diffusion implicit model with resampling. The model training is established on the denoising diffusion probabilistic model, where U-Net is equipped with the multi-head self-attention to match the noise in each step. The cosine noise schedule, serving as the global noise configuration, promotes the high utilization of known trace information by accelerating the passage of the excessive noise stages. The model inference utilizes the denoising diffusion implicit model, conditioning on the known traces, to enable high-quality interpolation with fewer diffusion steps. To enhance the coherency between the known traces and the missing traces within each reverse step, the inference process integrates a resampling strategy to achieve an information recap on the former interpolated traces. Extensive experiments conducted on synthetic and field seismic data validate the superiority of our model and its robustness to various missing patterns. In addition, uncertainty quantification and ablation studies are also investigated.
Beyond Geo-localization: Fine-grained Orientation of Street-view Images by Cross-view Matching with Satellite Imagery with Supplementary Materials
Jul 13, 2023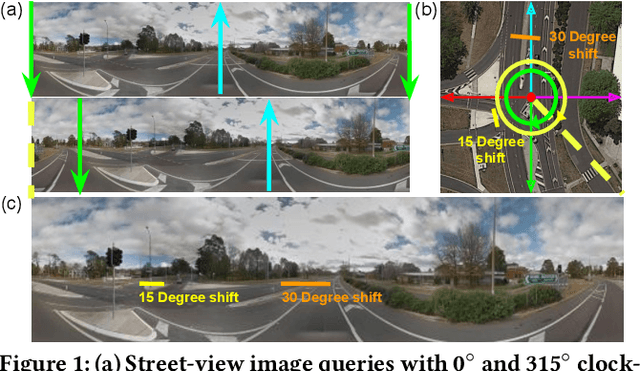
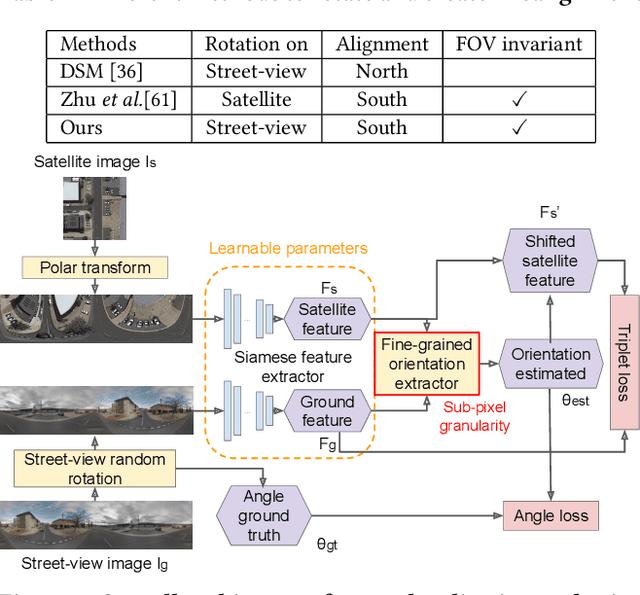
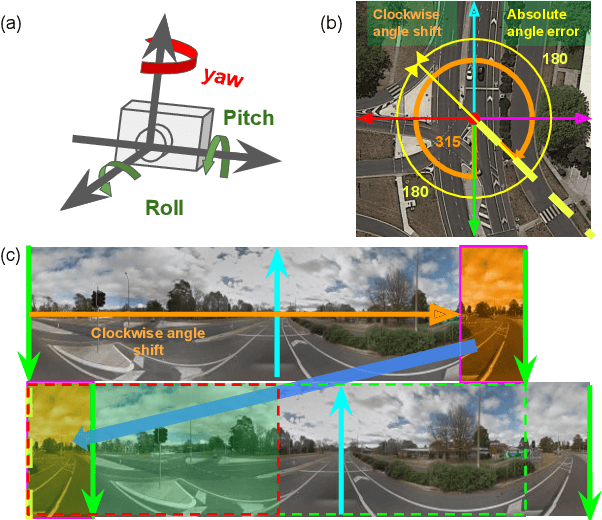
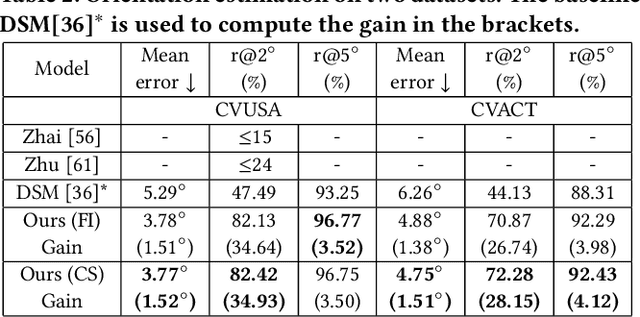
Street-view imagery provides us with novel experiences to explore different places remotely. Carefully calibrated street-view images (e.g. Google Street View) can be used for different downstream tasks, e.g. navigation, map features extraction. As personal high-quality cameras have become much more affordable and portable, an enormous amount of crowdsourced street-view images are uploaded to the internet, but commonly with missing or noisy sensor information. To prepare this hidden treasure for "ready-to-use" status, determining missing location information and camera orientation angles are two equally important tasks. Recent methods have achieved high performance on geo-localization of street-view images by cross-view matching with a pool of geo-referenced satellite imagery. However, most of the existing works focus more on geo-localization than estimating the image orientation. In this work, we re-state the importance of finding fine-grained orientation for street-view images, formally define the problem and provide a set of evaluation metrics to assess the quality of the orientation estimation. We propose two methods to improve the granularity of the orientation estimation, achieving 82.4% and 72.3% accuracy for images with estimated angle errors below 2 degrees for CVUSA and CVACT datasets, corresponding to 34.9% and 28.2% absolute improvement compared to previous works. Integrating fine-grained orientation estimation in training also improves the performance on geo-localization, giving top 1 recall 95.5%/85.5% and 86.8%/80.4% for orientation known/unknown tests on the two datasets.
* This paper has been accepted by ACM Multimedia 2022. This version contains additional supplementary materials
Right to be Forgotten in the Era of Large Language Models: Implications, Challenges, and Solutions
Jul 08, 2023


The Right to be Forgotten (RTBF) was first established as the result of the ruling of Google Spain SL, Google Inc. v AEPD, Mario Costeja Gonz\'alez, and was later included as the Right to Erasure under the General Data Protection Regulation (GDPR) of European Union to allow individuals the right to request personal data be deleted by organizations. Specifically for search engines, individuals can send requests to organizations to exclude their information from the query results. With the recent development of Large Language Models (LLMs) and their use in chatbots, LLM-enabled software systems have become popular. But they are not excluded from the RTBF. Compared with the indexing approach used by search engines, LLMs store, and process information in a completely different way. This poses new challenges for compliance with the RTBF. In this paper, we explore these challenges and provide our insights on how to implement technical solutions for the RTBF, including the use of machine unlearning, model editing, and prompting engineering.
PID-Inspired Inductive Biases for Deep Reinforcement Learning in Partially Observable Control Tasks
Jul 12, 2023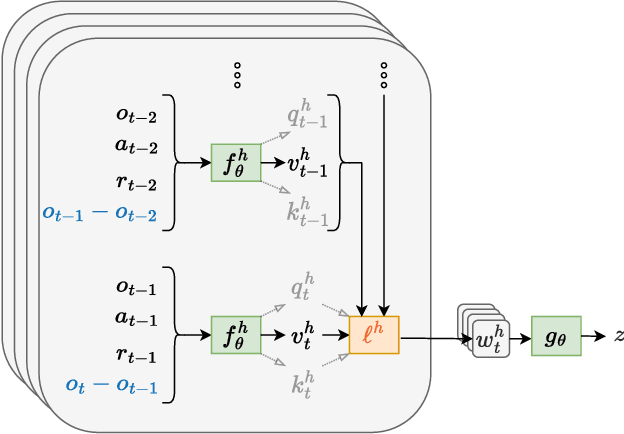
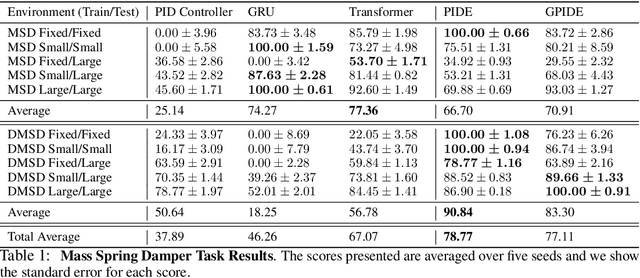
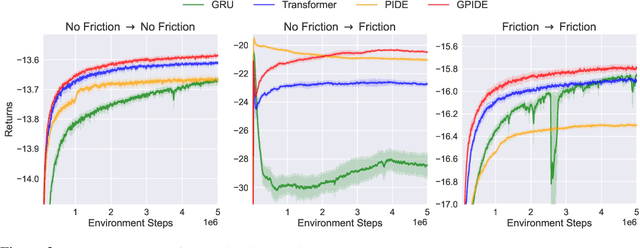
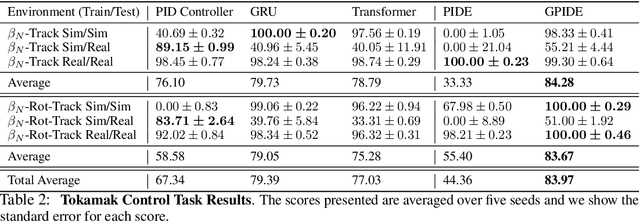
Deep reinforcement learning (RL) has shown immense potential for learning to control systems through data alone. However, one challenge deep RL faces is that the full state of the system is often not observable. When this is the case, the policy needs to leverage the history of observations to infer the current state. At the same time, differences between the training and testing environments makes it critical for the policy not to overfit to the sequence of observations it sees at training time. As such, there is an important balancing act between having the history encoder be flexible enough to extract relevant information, yet be robust to changes in the environment. To strike this balance, we look to the PID controller for inspiration. We assert the PID controller's success shows that only summing and differencing are needed to accumulate information over time for many control tasks. Following this principle, we propose two architectures for encoding history: one that directly uses PID features and another that extends these core ideas and can be used in arbitrary control tasks. When compared with prior approaches, our encoders produce policies that are often more robust and achieve better performance on a variety of tracking tasks. Going beyond tracking tasks, our policies achieve 1.7x better performance on average over previous state-of-the-art methods on a suite of high dimensional control tasks.
Learning Kernel-Modulated Neural Representation for Efficient Light Field Compression
Jul 12, 2023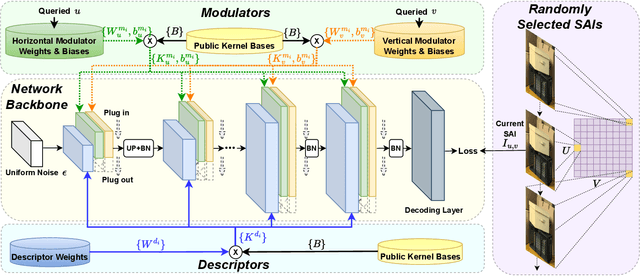
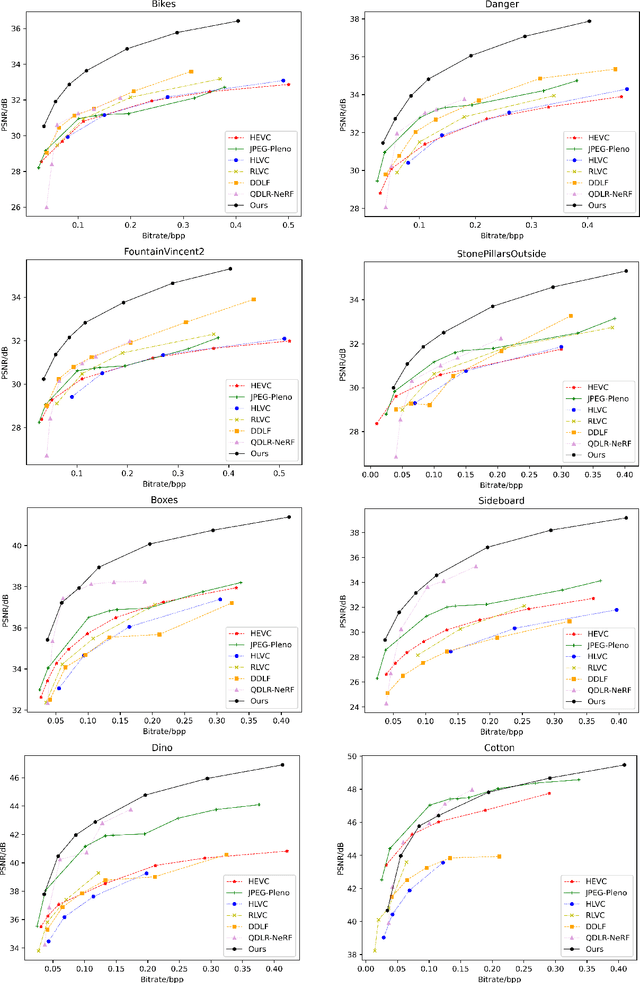

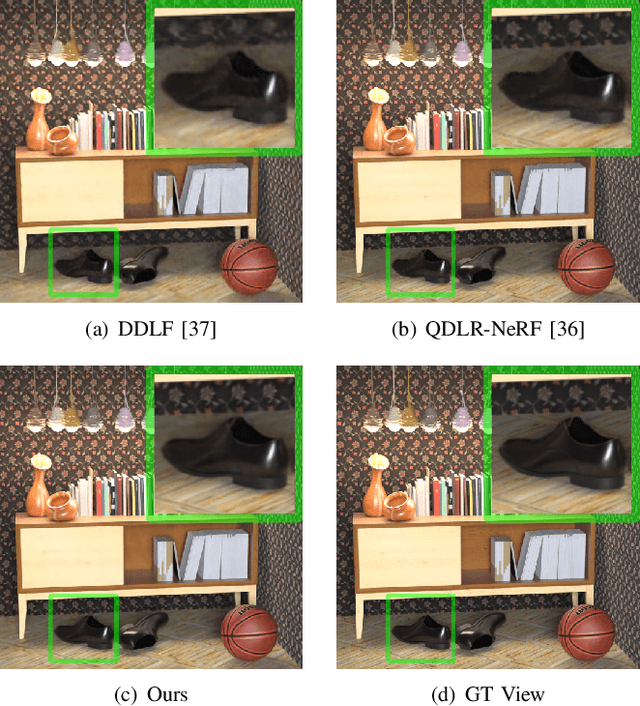
Light field is a type of image data that captures the 3D scene information by recording light rays emitted from a scene at various orientations. It offers a more immersive perception than classic 2D images but at the cost of huge data volume. In this paper, we draw inspiration from the visual characteristics of Sub-Aperture Images (SAIs) of light field and design a compact neural network representation for the light field compression task. The network backbone takes randomly initialized noise as input and is supervised on the SAIs of the target light field. It is composed of two types of complementary kernels: descriptive kernels (descriptors) that store scene description information learned during training, and modulatory kernels (modulators) that control the rendering of different SAIs from the queried perspectives. To further enhance compactness of the network meanwhile retain high quality of the decoded light field, we accordingly introduce modulator allocation and kernel tensor decomposition mechanisms, followed by non-uniform quantization and lossless entropy coding techniques, to finally form an efficient compression pipeline. Extensive experiments demonstrate that our method outperforms other state-of-the-art (SOTA) methods by a significant margin in the light field compression task. Moreover, after aligning descriptors, the modulators learned from one light field can be transferred to new light fields for rendering dense views, indicating a potential solution for view synthesis task.
Local Conditional Neural Fields for Versatile and Generalizable Large-Scale Reconstructions in Computational Imaging
Jul 12, 2023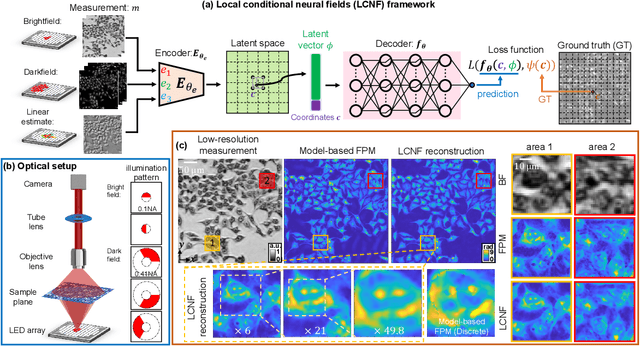
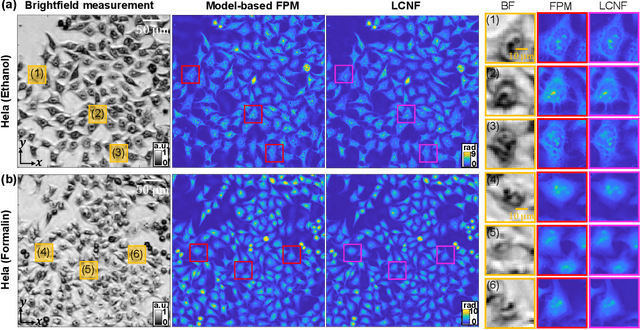
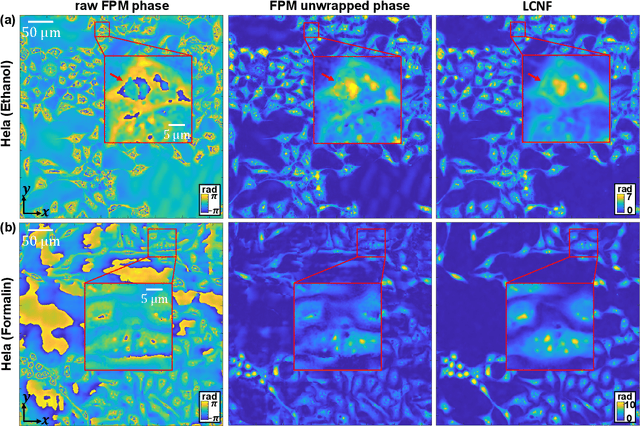
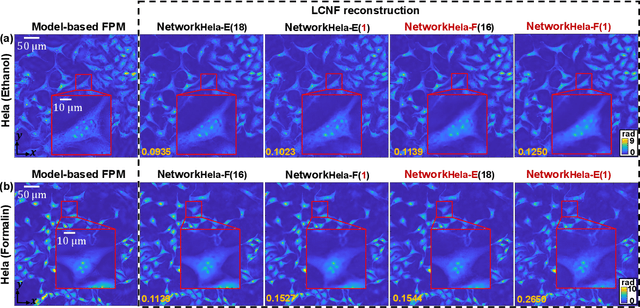
Deep learning has transformed computational imaging, but traditional pixel-based representations limit their ability to capture continuous, multiscale details of objects. Here we introduce a novel Local Conditional Neural Fields (LCNF) framework, leveraging a continuous implicit neural representation to address this limitation. LCNF enables flexible object representation and facilitates the reconstruction of multiscale information. We demonstrate the capabilities of LCNF in solving the highly ill-posed inverse problem in Fourier ptychographic microscopy (FPM) with multiplexed measurements, achieving robust, scalable, and generalizable large-scale phase retrieval. Unlike traditional neural fields frameworks, LCNF incorporates a local conditional representation that promotes model generalization, learning multiscale information, and efficient processing of large-scale imaging data. By combining an encoder and a decoder conditioned on a learned latent vector, LCNF achieves versatile continuous-domain super-resolution image reconstruction. We demonstrate accurate reconstruction of wide field-of-view, high-resolution phase images using only a few multiplexed measurements. LCNF robustly captures the continuous object priors and eliminates various phase artifacts, even when it is trained on imperfect datasets. The framework exhibits strong generalization, reconstructing diverse objects even with limited training data. Furthermore, LCNF can be trained on a physics simulator using natural images and successfully applied to experimental measurements on biological samples. Our results highlight the potential of LCNF for solving large-scale inverse problems in computational imaging, with broad applicability in various deep-learning-based techniques.
FILM: How can Few-Shot Image Classification Benefit from Pre-Trained Language Models?
Jul 09, 2023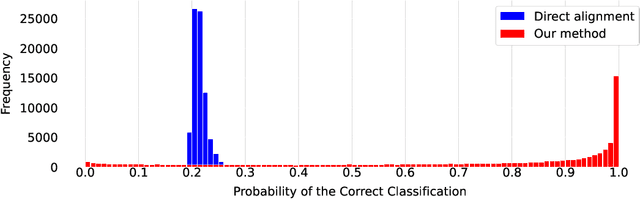
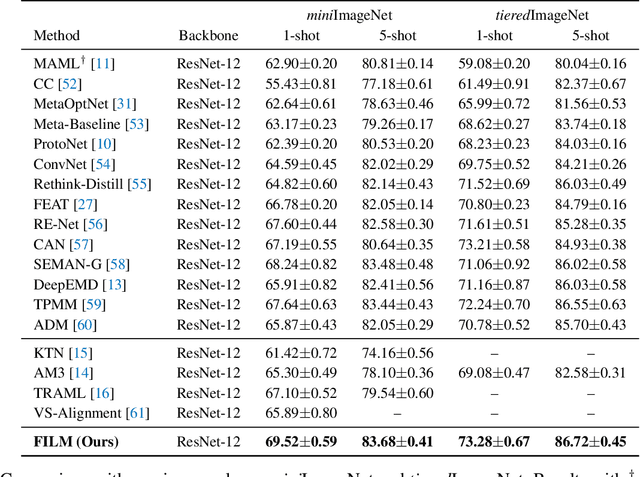
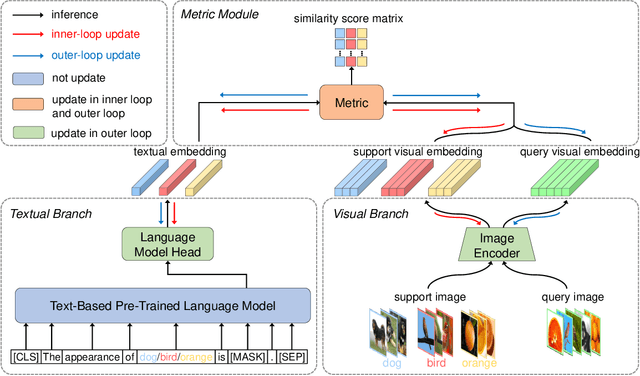
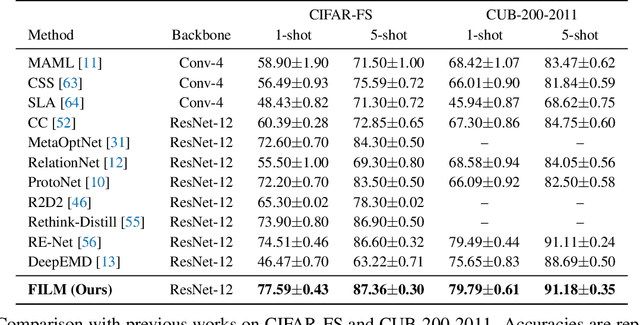
Few-shot learning aims to train models that can be generalized to novel classes with only a few samples. Recently, a line of works are proposed to enhance few-shot learning with accessible semantic information from class names. However, these works focus on improving existing modules such as visual prototypes and feature extractors of the standard few-shot learning framework. This limits the full potential use of semantic information. In this paper, we propose a novel few-shot learning framework that uses pre-trained language models based on contrastive learning. To address the challenge of alignment between visual features and textual embeddings obtained from text-based pre-trained language model, we carefully design the textual branch of our framework and introduce a metric module to generalize the cosine similarity. For better transferability, we let the metric module adapt to different few-shot tasks and adopt MAML to train the model via bi-level optimization. Moreover, we conduct extensive experiments on multiple benchmarks to demonstrate the effectiveness of our method.
Multi-Granularity Prediction with Learnable Fusion for Scene Text Recognition
Jul 25, 2023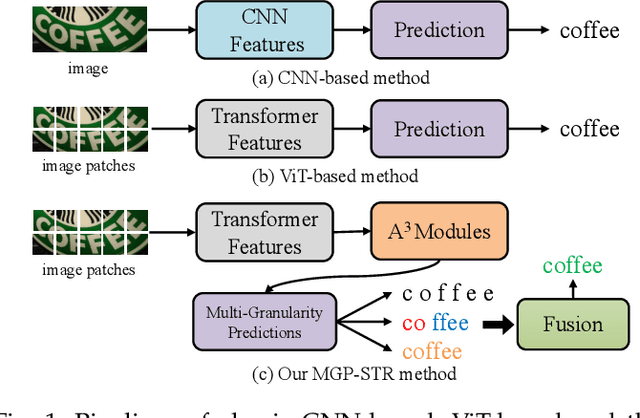
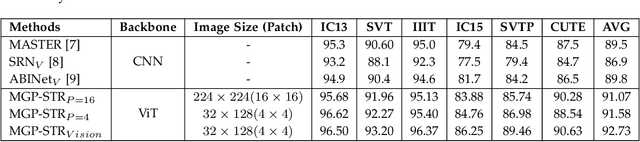
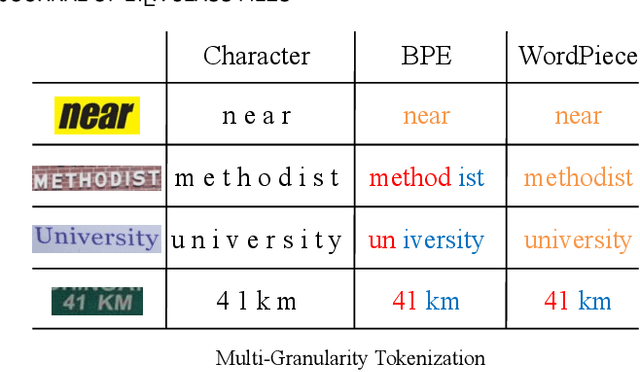
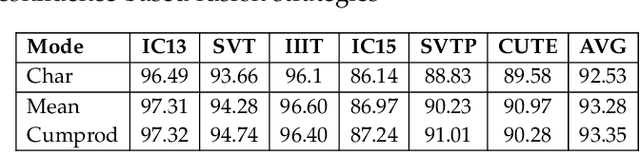
Due to the enormous technical challenges and wide range of applications, scene text recognition (STR) has been an active research topic in computer vision for years. To tackle this tough problem, numerous innovative methods have been successively proposed, and incorporating linguistic knowledge into STR models has recently become a prominent trend. In this work, we first draw inspiration from the recent progress in Vision Transformer (ViT) to construct a conceptually simple yet functionally powerful vision STR model, which is built upon ViT and a tailored Adaptive Addressing and Aggregation (A$^3$) module. It already outperforms most previous state-of-the-art models for scene text recognition, including both pure vision models and language-augmented methods. To integrate linguistic knowledge, we further propose a Multi-Granularity Prediction strategy to inject information from the language modality into the model in an implicit way, \ie, subword representations (BPE and WordPiece) widely used in NLP are introduced into the output space, in addition to the conventional character level representation, while no independent language model (LM) is adopted. To produce the final recognition results, two strategies for effectively fusing the multi-granularity predictions are devised. The resultant algorithm (termed MGP-STR) is able to push the performance envelope of STR to an even higher level. Specifically, MGP-STR achieves an average recognition accuracy of $94\%$ on standard benchmarks for scene text recognition. Moreover, it also achieves state-of-the-art results on widely-used handwritten benchmarks as well as more challenging scene text datasets, demonstrating the generality of the proposed MGP-STR algorithm. The source code and models will be available at: \url{https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR}.
One for Multiple: Physics-informed Synthetic Data Boosts Generalizable Deep Learning for Fast MRI Reconstruction
Jul 25, 2023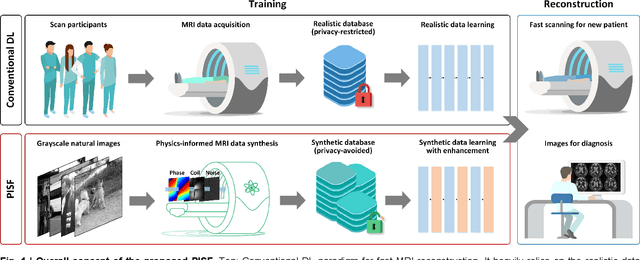
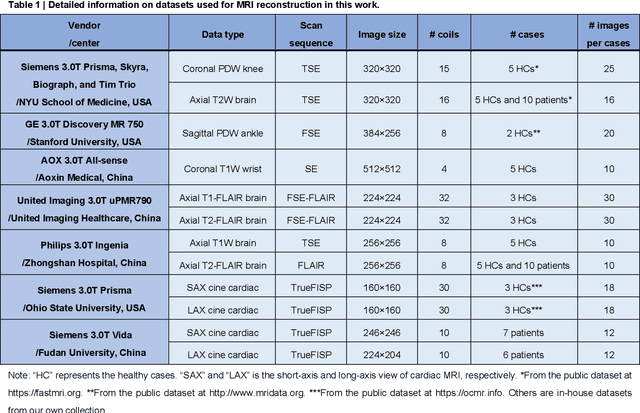

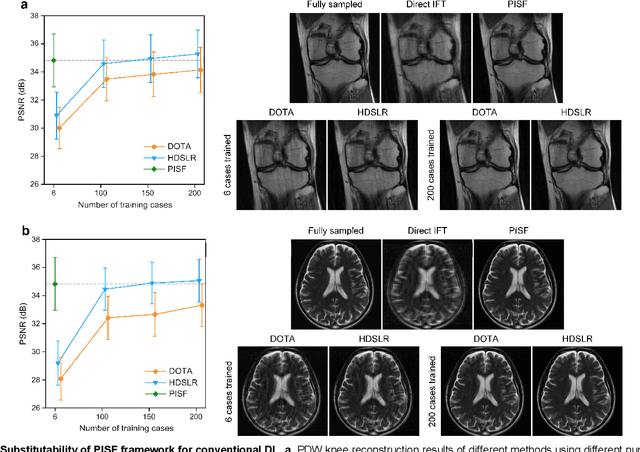
Magnetic resonance imaging (MRI) is a principal radiological modality that provides radiation-free, abundant, and diverse information about the whole human body for medical diagnosis, but suffers from prolonged scan time. The scan time can be significantly reduced through k-space undersampling but the introduced artifacts need to be removed in image reconstruction. Although deep learning (DL) has emerged as a powerful tool for image reconstruction in fast MRI, its potential in multiple imaging scenarios remains largely untapped. This is because not only collecting large-scale and diverse realistic training data is generally costly and privacy-restricted, but also existing DL methods are hard to handle the practically inevitable mismatch between training and target data. Here, we present a Physics-Informed Synthetic data learning framework for Fast MRI, called PISF, which is the first to enable generalizable DL for multi-scenario MRI reconstruction using solely one trained model. For a 2D image, the reconstruction is separated into many 1D basic problems and starts with the 1D data synthesis, to facilitate generalization. We demonstrate that training DL models on synthetic data, integrated with enhanced learning techniques, can achieve comparable or even better in vivo MRI reconstruction compared to models trained on a matched realistic dataset, reducing the demand for real-world MRI data by up to 96%. Moreover, our PISF shows impressive generalizability in multi-vendor multi-center imaging. Its excellent adaptability to patients has been verified through 10 experienced doctors' evaluations. PISF provides a feasible and cost-effective way to markedly boost the widespread usage of DL in various fast MRI applications, while freeing from the intractable ethical and practical considerations of in vivo human data acquisitions.