 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified continuous-time q-learning for mean-field game and mean-field control problems
Jul 05, 2024This paper studies the continuous-time q-learning in the mean-field jump-diffusion models from the representative agent's perspective. To overcome the challenge when the population distribution may not be directly observable, we introduce the integrated q-function in decoupled form (decoupled Iq-function) and establish its martingale characterization together with the value function, which provides a unified policy evaluation rule for both mean-field game (MFG) and mean-field control (MFC) problems. Moreover, depending on the task to solve the MFG or MFC problem, we can employ the decoupled Iq-function by different means to learn the mean-field equilibrium policy or the mean-field optimal policy respectively. As a result, we devise a unified q-learning algorithm for both MFG and MFC problems by utilizing all test policies stemming from the mean-field interactions. For several examples in the jump-diffusion setting, within and beyond the LQ framework, we can obtain the exact parameterization of the decoupled Iq-functions and the value functions, and illustrate our algorithm from the representative agent's perspective with satisfactory performance.
Training-Free Robust Interactive Video Object Segmentation
Jun 08, 2024



Interactive video object segmentation is a crucial video task, having various applications from video editing to data annotating. However, current approaches struggle to accurately segment objects across diverse domains. Recently, Segment Anything Model (SAM) introduces interactive visual prompts and demonstrates impressive performance across different domains. In this paper, we propose a training-free prompt tracking framework for interactive video object segmentation (I-PT), leveraging the powerful generalization of SAM. Although point tracking efficiently captures the pixel-wise information of objects in a video, points tend to be unstable when tracked over a long period, resulting in incorrect segmentation. Towards fast and robust interaction, we jointly adopt sparse points and boxes tracking, filtering out unstable points and capturing object-wise information. To better integrate reference information from multiple interactions, we introduce a cross-round space-time module (CRSTM), which adaptively aggregates mask features from previous rounds and frames, enhancing the segmentation stability. Our framework has demonstrated robust zero-shot video segmentation results on popular VOS datasets with interaction types, including DAVIS 2017, YouTube-VOS 2018, and MOSE 2023, maintaining a good tradeoff between performance and interaction time.
Seismic First Break Picking in a Higher Dimension Using Deep Graph Learning
Apr 12, 2024


Contemporary automatic first break (FB) picking methods typically analyze 1D signals, 2D source gathers, or 3D source-receiver gathers. Utilizing higher-dimensional data, such as 2D or 3D, incorporates global features, improving the stability of local picking. Despite the benefits, high-dimensional data requires structured input and increases computational demands. Addressing this, we propose a novel approach using deep graph learning called DGL-FB, constructing a large graph to efficiently extract information. In this graph, each seismic trace is represented as a node, connected by edges that reflect similarities. To manage the size of the graph, we develop a subgraph sampling technique to streamline model training and inference. Our proposed framework, DGL-FB, leverages deep graph learning for FB picking. It encodes subgraphs into global features using a deep graph encoder. Subsequently, the encoded global features are combined with local node signals and fed into a ResUNet-based 1D segmentation network for FB detection. Field survey evaluations of DGL-FB show superior accuracy and stability compared to a 2D U-Net-based benchmark method.
From Bandits Model to Deep Deterministic Policy Gradient, Reinforcement Learning with Contextual Information
Oct 01, 2023



The problem of how to take the right actions to make profits in sequential process continues to be difficult due to the quick dynamics and a significant amount of uncertainty in many application scenarios. In such complicated environments, reinforcement learning (RL), a reward-oriented strategy for optimum control, has emerged as a potential technique to address this strategic decision-making issue. However, reinforcement learning also has some shortcomings that make it unsuitable for solving many financial problems, excessive resource consumption, and inability to quickly obtain optimal solutions, making it unsuitable for quantitative trading markets. In this study, we use two methods to overcome the issue with contextual information: contextual Thompson sampling and reinforcement learning under supervision which can accelerate the iterations in search of the best answer. In order to investigate strategic trading in quantitative markets, we merged the earlier financial trading strategy known as constant proportion portfolio insurance (CPPI) into deep deterministic policy gradient (DDPG). The experimental results show that both methods can accelerate the progress of reinforcement learning to obtain the optimal solution.
Seismic Data Interpolation based on Denoising Diffusion Implicit Models with Resampling
Jul 13, 2023The incompleteness of the seismic data caused by missing traces along the spatial extension is a common issue in seismic acquisition due to the existence of obstacles and economic constraints, which severely impairs the imaging quality of subsurface geological structures. Recently, deep learningbased seismic interpolation methods have attained promising progress, while achieving stable training of generative adversarial networks is not easy, and performance degradation is usually notable if the missing patterns in the testing and training do not match. In this paper, we propose a novel seismic denoising diffusion implicit model with resampling. The model training is established on the denoising diffusion probabilistic model, where U-Net is equipped with the multi-head self-attention to match the noise in each step. The cosine noise schedule, serving as the global noise configuration, promotes the high utilization of known trace information by accelerating the passage of the excessive noise stages. The model inference utilizes the denoising diffusion implicit model, conditioning on the known traces, to enable high-quality interpolation with fewer diffusion steps. To enhance the coherency between the known traces and the missing traces within each reverse step, the inference process integrates a resampling strategy to achieve an information recap on the former interpolated traces. Extensive experiments conducted on synthetic and field seismic data validate the superiority of our model and its robustness to various missing patterns. In addition, uncertainty quantification and ablation studies are also investigated.
Continuous Time q-learning for McKean-Vlasov Control Problems
Jul 04, 2023This paper studies the q-learning, recently coined as the continuous time counterpart of Q-learning by Jia and Zhou (2023), for continuous time Mckean-Vlasov control problems in the setting of entropy-regularized reinforcement learning. In contrast to the single agent's control problem in Jia and Zhou (2023), the mean-field interaction of agents renders the definition of the q-function more subtle, for which we reveal that two distinct q-functions naturally arise: (i) the integrated q-function (denoted by $q$) as the first-order approximation of the integrated Q-function introduced in Gu, Guo, Wei and Xu (2023), which can be learnt by a weak martingale condition involving test policies; and (ii) the essential q-function (denoted by $q_e$) that is employed in the policy improvement iterations. We show that two q-functions are related via an integral representation under all test policies. Based on the weak martingale condition and our proposed searching method of test policies, some model-free learning algorithms are devised. In two examples, one in LQ control framework and one beyond LQ control framework, we can obtain the exact parameterization of the optimal value function and q-functions and illustrate our algorithms with simulation experiments.
Leveraging Uncertainty Quantification for Picking Robust First Break Times
May 23, 2023



In seismic exploration, the selection of first break times is a crucial aspect in the determination of subsurface velocity models, which in turn significantly influences the placement of wells. Many deep neural network (DNN)-based automatic first break picking methods have been proposed to speed up this picking processing. However, there has been no work on the uncertainty of the first picking results of the output of DNN. In this paper, we propose a new framework for first break picking based on a Bayesian neural network to further explain the uncertainty of the output. In a large number of experiments, we evaluate that the proposed method has better accuracy and robustness than the deterministic DNN-based model. In addition, we also verify that the uncertainty of measurement is meaningful, which can provide a reference for human decision-making.
MSSPN: Automatic First Arrival Picking using Multi-Stage Segmentation Picking Network
Sep 07, 2022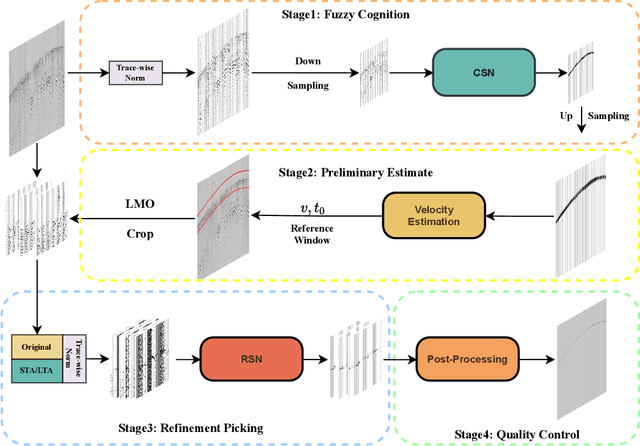

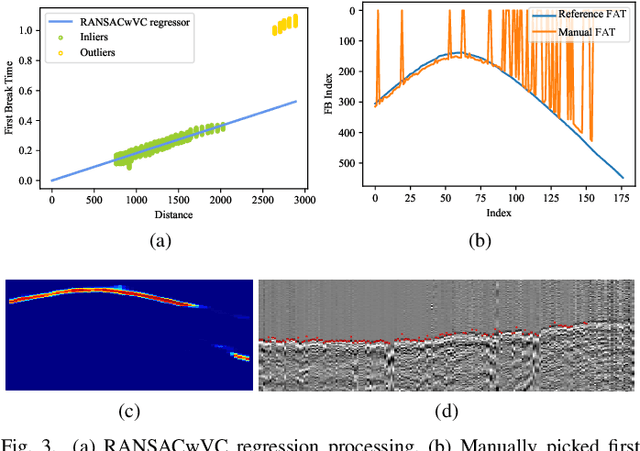
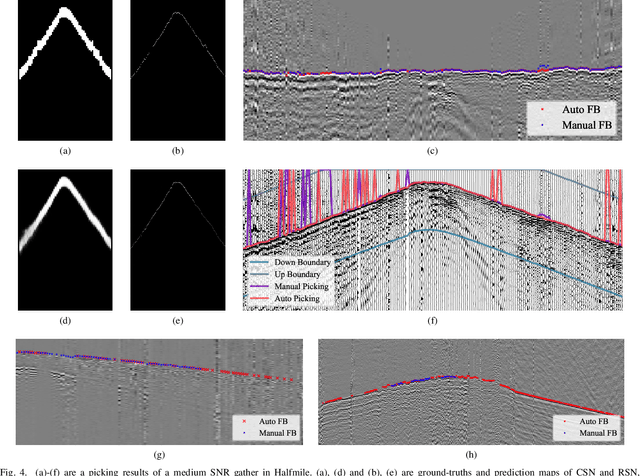
Picking the first arrival times of prestack gathers is called First Arrival Time (FAT) picking, which is an indispensable step in seismic data processing, and is mainly solved manually in the past. With the current increasing density of seismic data collection, the efficiency of manual picking has been unable to meet the actual needs. Therefore, automatic picking methods have been greatly developed in recent decades, especially those based on deep learning. However, few of the current supervised deep learning-based method can avoid the dependence on labeled samples. Besides, since the gather data is a set of signals which are greatly different from the natural images, it is difficult for the current method to solve the FAT picking problem in case of a low Signal to Noise Ratio (SNR). In this paper, for hard rock seismic gather data, we propose a Multi-Stage Segmentation Pickup Network (MSSPN), which solves the generalization problem across worksites and the picking problem in the case of low SNR. In MSSPN, there are four sub-models to simulate the manually picking processing, which is assumed to four stages from coarse to fine. Experiments on seven field datasets with different qualities show that our MSSPN outperforms benchmarks by a large margin.Particularly, our method can achieve more than 90\% accurate picking across worksites in the case of medium and high SNRs, and even fine-tuned model can achieve 88\% accurate picking of the dataset with low SNR.
Thompson Sampling on Asymmetric $α$-Stable Bandits
Mar 25, 2022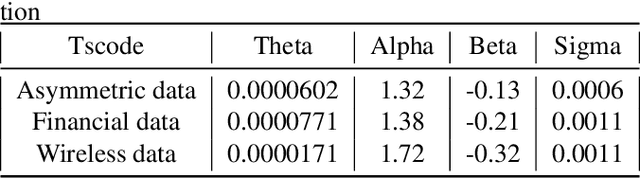
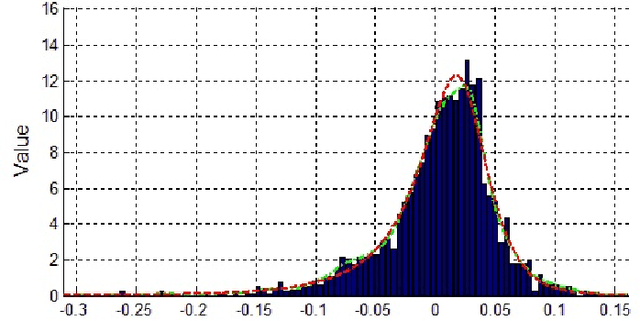
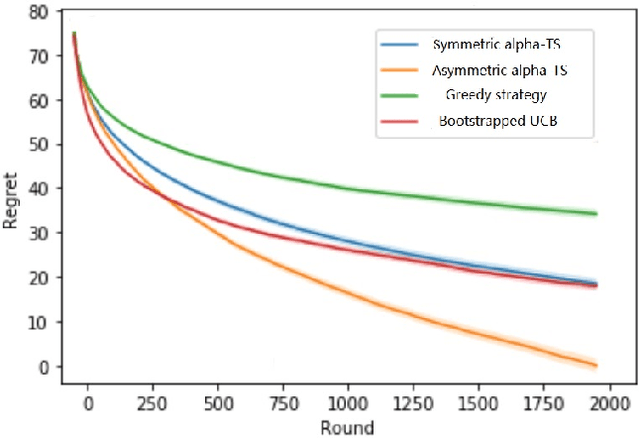
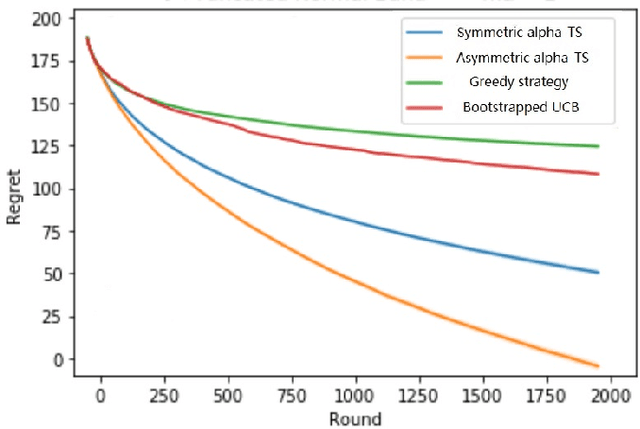
In algorithm optimization in reinforcement learning, how to deal with the exploration-exploitation dilemma is particularly important. Multi-armed bandit problem can optimize the proposed solutions by changing the reward distribution to realize the dynamic balance between exploration and exploitation. Thompson Sampling is a common method for solving multi-armed bandit problem and has been used to explore data that conform to various laws. In this paper, we consider the Thompson Sampling approach for multi-armed bandit problem, in which rewards conform to unknown asymmetric $\alpha$-stable distributions and explore their applications in modelling financial and wireless data.
Mean-Field Multi-Agent Reinforcement Learning: A Decentralized Network Approach
Aug 05, 2021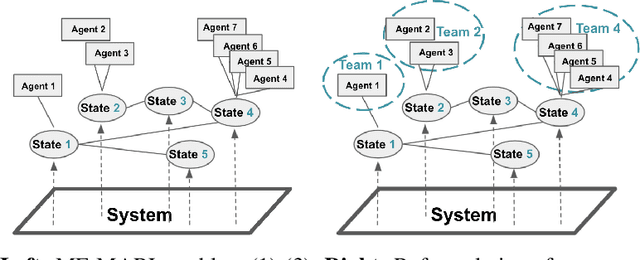
One of the challenges for multi-agent reinforcement learning (MARL) is designing efficient learning algorithms for a large system in which each agent has only limited or partial information of the entire system. In this system, it is desirable to learn policies of a decentralized type. A recent and promising paradigm to analyze such decentralized MARL is to take network structures into consideration. While exciting progress has been made to analyze decentralized MARL with the network of agents, often found in social networks and team video games, little is known theoretically for decentralized MARL with the network of states, frequently used for modeling self-driving vehicles, ride-sharing, and data and traffic routing. This paper proposes a framework called localized training and decentralized execution to study MARL with network of states, with homogeneous (a.k.a. mean-field type) agents. Localized training means that agents only need to collect local information in their neighboring states during the training phase; decentralized execution implies that, after the training stage, agents can execute the learned decentralized policies, which only requires knowledge of the agents' current states. The key idea is to utilize the homogeneity of agents and regroup them according to their states, thus the formulation of a networked Markov decision process with teams of agents, enabling the update of the Q-function in a localized fashion. In order to design an efficient and scalable reinforcement learning algorithm under such a framework, we adopt the actor-critic approach with over-parameterized neural networks, and establish the convergence and sample complexity for our algorithm, shown to be scalable with respect to the size of both agents and states.