 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Estimating and Incentivizing Imperfect-Knowledge Agents with Hidden Rewards
Aug 13, 2023
In practice, incentive providers (i.e., principals) often cannot observe the reward realizations of incentivized agents, which is in contrast to many principal-agent models that have been previously studied. This information asymmetry challenges the principal to consistently estimate the agent's unknown rewards by solely watching the agent's decisions, which becomes even more challenging when the agent has to learn its own rewards. This complex setting is observed in various real-life scenarios ranging from renewable energy storage contracts to personalized healthcare incentives. Hence, it offers not only interesting theoretical questions but also wide practical relevance. This paper explores a repeated adverse selection game between a self-interested learning agent and a learning principal. The agent tackles a multi-armed bandit (MAB) problem to maximize their expected reward plus incentive. On top of the agent's learning, the principal trains a parallel algorithm and faces a trade-off between consistently estimating the agent's unknown rewards and maximizing their own utility by offering adaptive incentives to lead the agent. For a non-parametric model, we introduce an estimator whose only input is the history of principal's incentives and agent's choices. We unite this estimator with a proposed data-driven incentive policy within a MAB framework. Without restricting the type of the agent's algorithm, we prove finite-sample consistency of the estimator and a rigorous regret bound for the principal by considering the sequential externality imposed by the agent. Lastly, our theoretical results are reinforced by simulations justifying applicability of our framework to green energy aggregator contracts.
Symbol-level Integrated Sensing and Communication enabled Multiple Base Stations Cooperative Sensing
Aug 13, 2023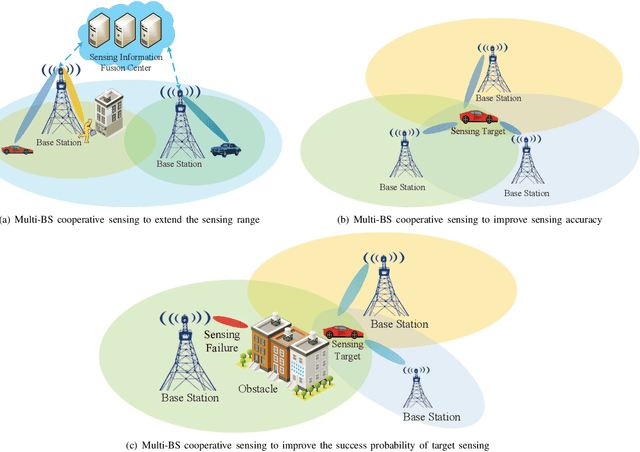
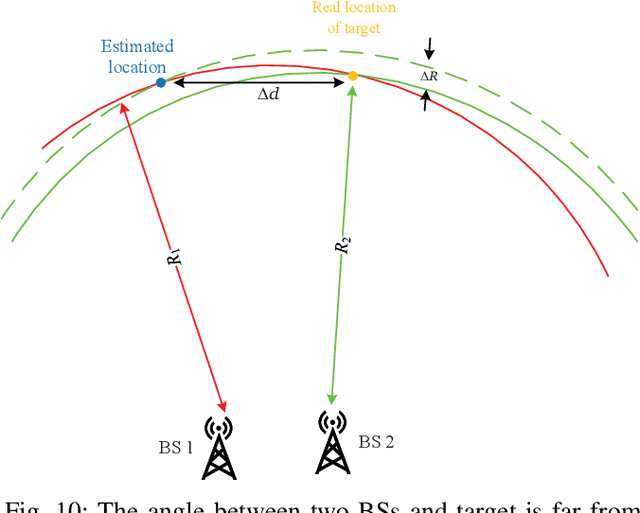
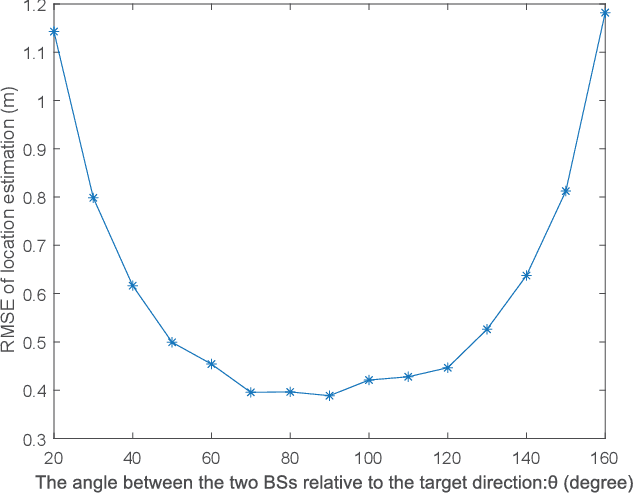
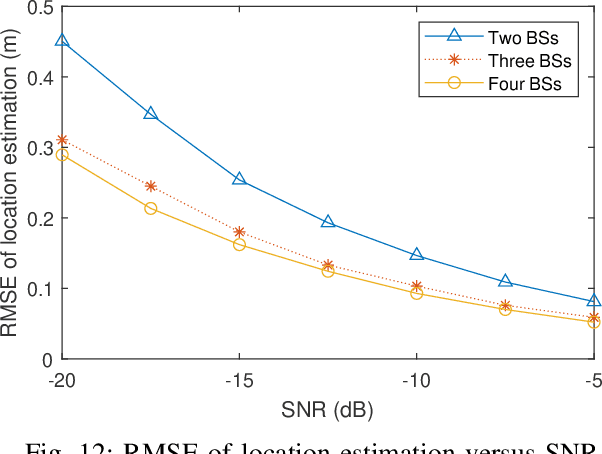
With the support of integrated sensing and communication (ISAC) technology, mobile communication system will integrate the function of wireless sensing, thereby facilitating new intelligent applications such as smart city and intelligent transportation. Due to the limited sensing accuracy and sensing range of single base station (BS), multi-BS cooperative sensing can be applied to realize high-accurate, long-range and continuous sensing, exploiting the specific advantages of large-scale networked mobile communication system. This paper proposes a cooperative sensing method suitable to mobile communication systems, which applies symbol-level sensing information fusion to estimate the location and velocity of target. With the demodulation symbols obtained from the echo signals of multiple BSs, the phase features contained in the demodulation symbols are used in the fusion procedure, which realizes cooperative sensing with the synchronization level of mobile communication system. Compared with the signal-level fusion in the area of distributed aperture coherence-synthetic radars, the requirement of synchronization is much lower. When signal-to-noise ratio (SNR) is -5 dB, it is evaluated that symbol-level multi-BS cooperative sensing effectively improves the accuracy of distance and velocity estimation of target. Compared with single-BS sensing, the accuracy of distance and velocity estimation is improved by 40% and 72%, respectively. Compared with data-level multi-BS cooperative sensing based on maximum likelihood (ML) estimation, the accuracy of location and velocity estimation is improved by 12% and 63%, respectively. This work may provide a guideline for the design of multi-BS cooperative sensing system to exploit the widely deployed networked mobile communication system.
Compositional Feature Augmentation for Unbiased Scene Graph Generation
Aug 13, 2023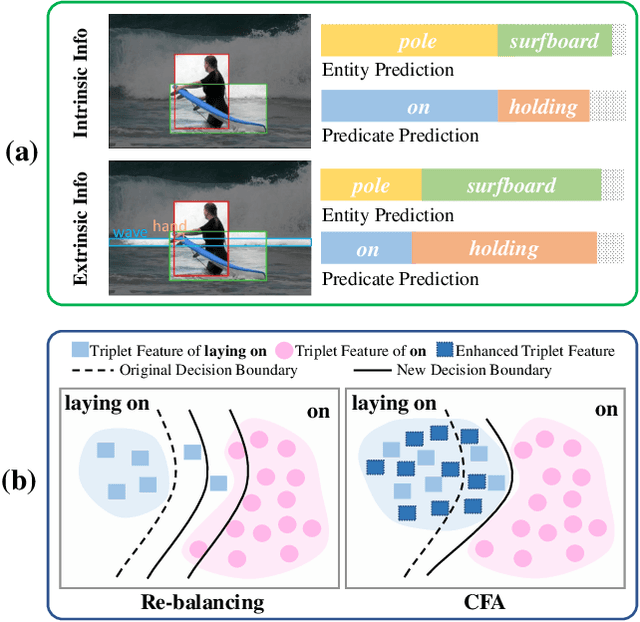
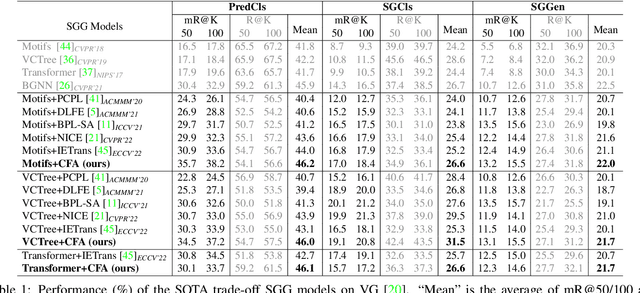
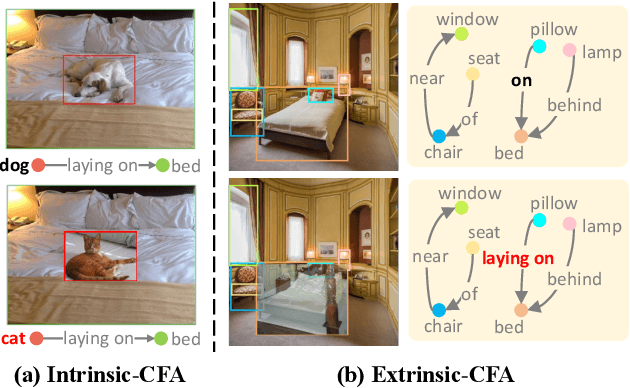
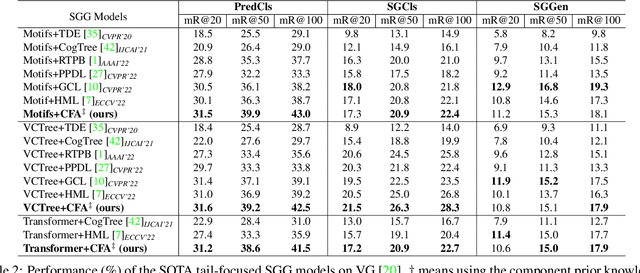
Scene Graph Generation (SGG) aims to detect all the visual relation triplets <sub, pred, obj> in a given image. With the emergence of various advanced techniques for better utilizing both the intrinsic and extrinsic information in each relation triplet, SGG has achieved great progress over the recent years. However, due to the ubiquitous long-tailed predicate distributions, today's SGG models are still easily biased to the head predicates. Currently, the most prevalent debiasing solutions for SGG are re-balancing methods, e.g., changing the distributions of original training samples. In this paper, we argue that all existing re-balancing strategies fail to increase the diversity of the relation triplet features of each predicate, which is critical for robust SGG. To this end, we propose a novel Compositional Feature Augmentation (CFA) strategy, which is the first unbiased SGG work to mitigate the bias issue from the perspective of increasing the diversity of triplet features. Specifically, we first decompose each relation triplet feature into two components: intrinsic feature and extrinsic feature, which correspond to the intrinsic characteristics and extrinsic contexts of a relation triplet, respectively. Then, we design two different feature augmentation modules to enrich the feature diversity of original relation triplets by replacing or mixing up either their intrinsic or extrinsic features from other samples. Due to its model-agnostic nature, CFA can be seamlessly incorporated into various SGG frameworks. Extensive ablations have shown that CFA achieves a new state-of-the-art performance on the trade-off between different metrics.
A Review of Change of Variable Formulas for Generative Modeling
Aug 04, 2023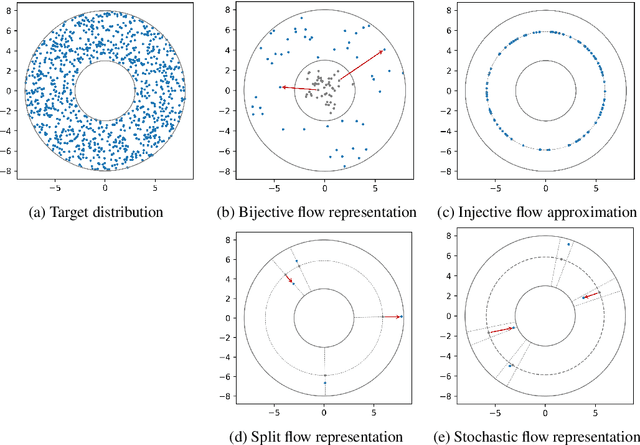

Change-of-variables (CoV) formulas allow to reduce complicated probability densities to simpler ones by a learned transformation with tractable Jacobian determinant. They are thus powerful tools for maximum-likelihood learning, Bayesian inference, outlier detection, model selection, etc. CoV formulas have been derived for a large variety of model types, but this information is scattered over many separate works. We present a systematic treatment from the unifying perspective of encoder/decoder architectures, which collects 28 CoV formulas in a single place, reveals interesting relationships between seemingly diverse methods, emphasizes important distinctions that are not always clear in the literature, and identifies surprising gaps for future research.
Network Fault-tolerant and Byzantine-resilient Social Learning via Collaborative Hierarchical Non-Bayesian Learning
Jul 27, 2023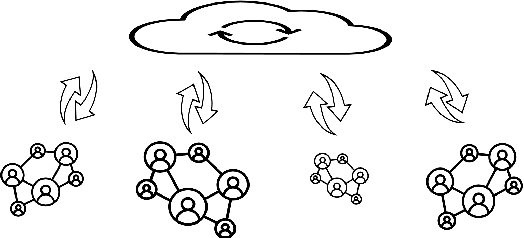
As the network scale increases, existing fully distributed solutions start to lag behind the real-world challenges such as (1) slow information propagation, (2) network communication failures, and (3) external adversarial attacks. In this paper, we focus on hierarchical system architecture and address the problem of non-Bayesian learning over networks that are vulnerable to communication failures and adversarial attacks. On network communication, we consider packet-dropping link failures. We first propose a hierarchical robust push-sum algorithm that can achieve average consensus despite frequent packet-dropping link failures. We provide a sparse information fusion rule between the parameter server and arbitrarily selected network representatives. Then, interleaving the consensus update step with a dual averaging update with Kullback-Leibler (KL) divergence as the proximal function, we obtain a packet-dropping fault-tolerant non-Bayesian learning algorithm with provable convergence guarantees. On external adversarial attacks, we consider Byzantine attacks in which the compromised agents can send maliciously calibrated messages to others (including both the agents and the parameter server). To avoid the curse of dimensionality of Byzantine consensus, we solve the non-Bayesian learning problem via running multiple dynamics, each of which only involves Byzantine consensus with scalar inputs. To facilitate resilient information propagation across sub-networks, we use a novel Byzantine-resilient gossiping-type rule at the parameter server.
Explainable Topic-Enhanced Argument Mining from Heterogeneous Sources
Jul 22, 2023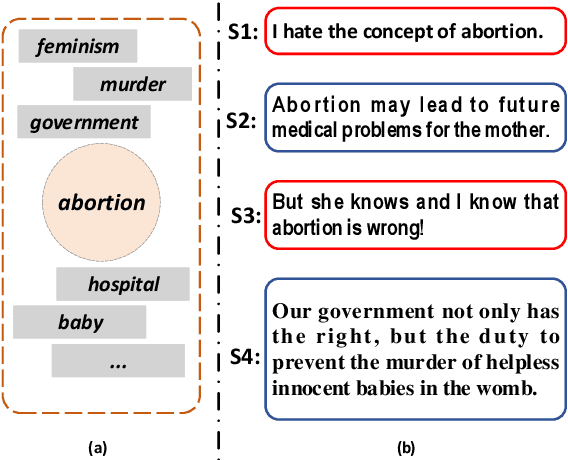
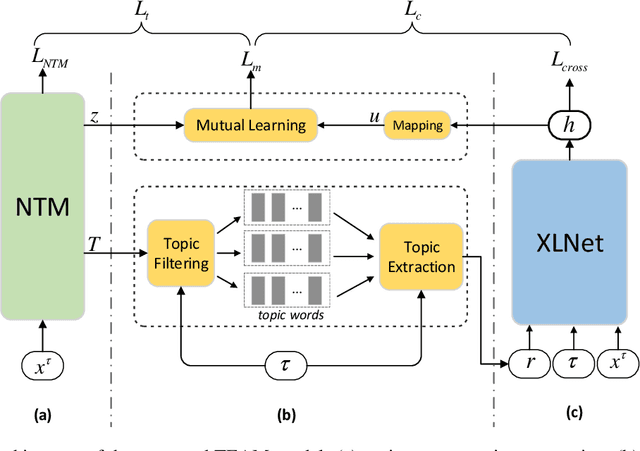

Given a controversial target such as ``nuclear energy'', argument mining aims to identify the argumentative text from heterogeneous sources. Current approaches focus on exploring better ways of integrating the target-associated semantic information with the argumentative text. Despite their empirical successes, two issues remain unsolved: (i) a target is represented by a word or a phrase, which is insufficient to cover a diverse set of target-related subtopics; (ii) the sentence-level topic information within an argument, which we believe is crucial for argument mining, is ignored. To tackle the above issues, we propose a novel explainable topic-enhanced argument mining approach. Specifically, with the use of the neural topic model and the language model, the target information is augmented by explainable topic representations. Moreover, the sentence-level topic information within the argument is captured by minimizing the distance between its latent topic distribution and its semantic representation through mutual learning. Experiments have been conducted on the benchmark dataset in both the in-target setting and the cross-target setting. Results demonstrate the superiority of the proposed model against the state-of-the-art baselines.
Collecting Channel State Information in Wi-Fi Access Points for IoT Forensics
May 17, 2023The Internet of Things (IoT) has boomed in recent years, with an ever-growing number of connected devices and a corresponding exponential increase in network traffic. As a result, IoT devices have become potential witnesses of the surrounding environment and people living in it, creating a vast new source of forensic evidence. To address this need, a new field called IoT Forensics has emerged. In this paper, we present \textit{CSI Sniffer}, a tool that integrates the collection and management of Channel State Information (CSI) in Wi-Fi Access Points. CSI is a physical layer indicator that enables human sensing, including occupancy monitoring and activity recognition. After a description of the tool architecture and implementation, we demonstrate its capabilities through two application scenarios that use binary classification techniques to classify user behavior based on CSI features extracted from IoT traffic. Our results show that the proposed tool can enhance the capabilities of forensic investigations by providing additional sources of evidence. Wi-Fi Access Points integrated with \textit{CSI Sniffer} can be used by ISP or network managers to facilitate the collection of information from IoT devices and the surrounding environment. We conclude the work by analyzing the storage requirements of CSI sample collection and discussing the impact of lossy compression techniques on classification performance.
What Can an Accent Identifier Learn? Probing Phonetic and Prosodic Information in a Wav2vec2-based Accent Identification Model
Jun 10, 2023
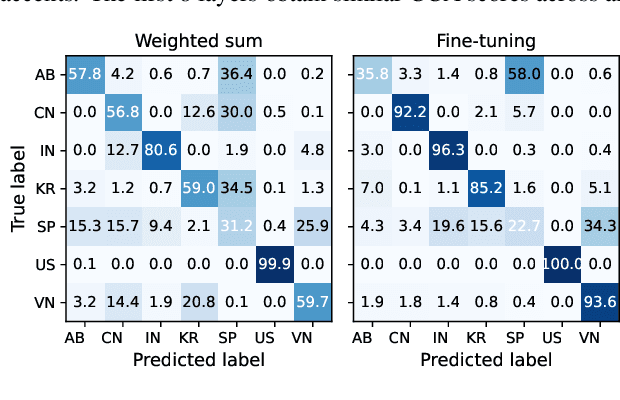
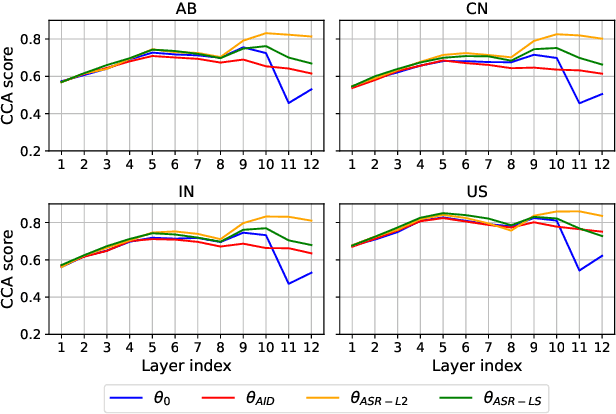
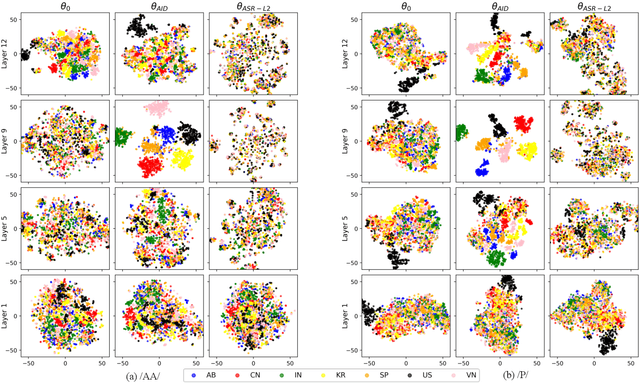
This study is focused on understanding and quantifying the change in phoneme and prosody information encoded in the Self-Supervised Learning (SSL) model, brought by an accent identification (AID) fine-tuning task. This problem is addressed based on model probing. Specifically, we conduct a systematic layer-wise analysis of the representations of the Transformer layers on a phoneme correlation task, and a novel word-level prosody prediction task. We compare the probing performance of the pre-trained and fine-tuned SSL models. Results show that the AID fine-tuning task steers the top 2 layers to learn richer phoneme and prosody representation. These changes share some similarities with the effects of fine-tuning with an Automatic Speech Recognition task. In addition, we observe strong accent-specific phoneme representations in layer 9. To sum up, this study provides insights into the understanding of SSL features and their interactions with fine-tuning tasks.
CFR-p: Counterfactual Regret Minimization with Hierarchical Policy Abstraction, and its Application to Two-player Mahjong
Jul 22, 2023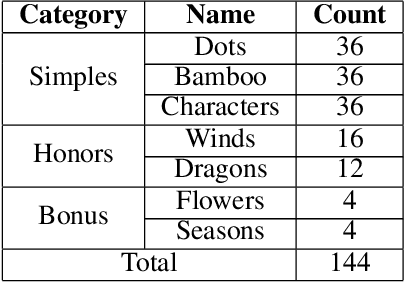
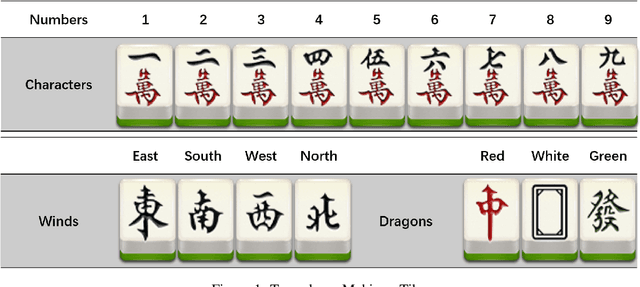

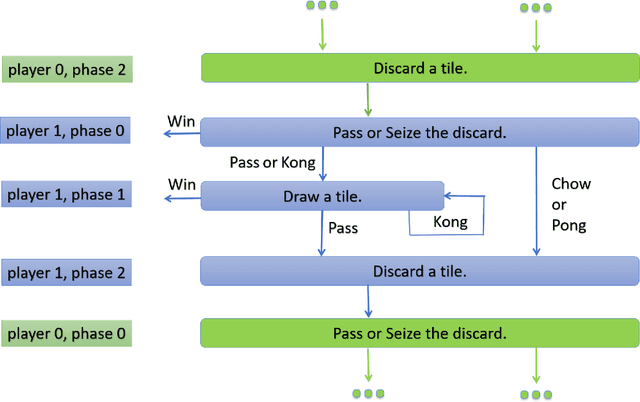
Counterfactual Regret Minimization(CFR) has shown its success in Texas Hold'em poker. We apply this algorithm to another popular incomplete information game, Mahjong. Compared to the poker game, Mahjong is much more complex with many variants. We study two-player Mahjong by conducting game theoretical analysis and making a hierarchical abstraction to CFR based on winning policies. This framework can be generalized to other imperfect information games.
SwinMM: Masked Multi-view with Swin Transformers for 3D Medical Image Segmentation
Jul 24, 2023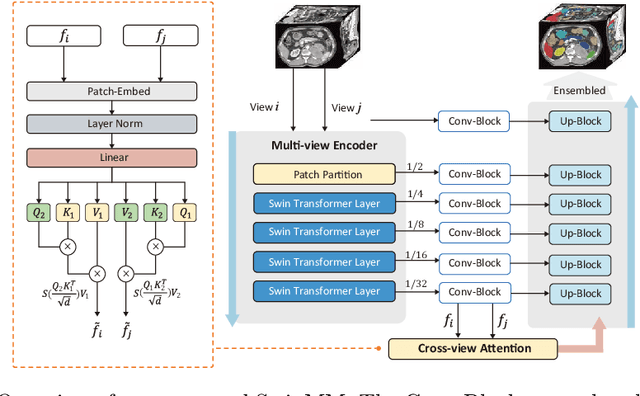
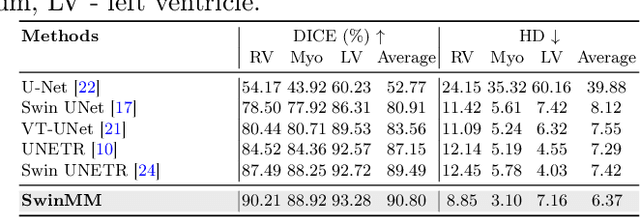
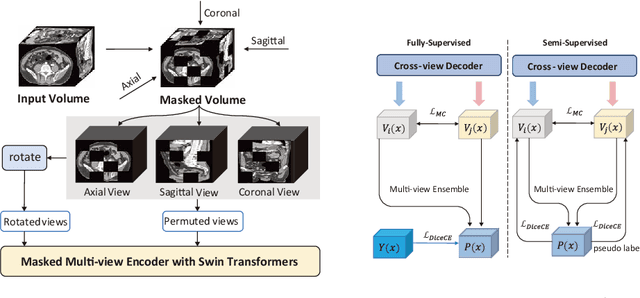

Recent advancements in large-scale Vision Transformers have made significant strides in improving pre-trained models for medical image segmentation. However, these methods face a notable challenge in acquiring a substantial amount of pre-training data, particularly within the medical field. To address this limitation, we present Masked Multi-view with Swin Transformers (SwinMM), a novel multi-view pipeline for enabling accurate and data-efficient self-supervised medical image analysis. Our strategy harnesses the potential of multi-view information by incorporating two principal components. In the pre-training phase, we deploy a masked multi-view encoder devised to concurrently train masked multi-view observations through a range of diverse proxy tasks. These tasks span image reconstruction, rotation, contrastive learning, and a novel task that employs a mutual learning paradigm. This new task capitalizes on the consistency between predictions from various perspectives, enabling the extraction of hidden multi-view information from 3D medical data. In the fine-tuning stage, a cross-view decoder is developed to aggregate the multi-view information through a cross-attention block. Compared with the previous state-of-the-art self-supervised learning method Swin UNETR, SwinMM demonstrates a notable advantage on several medical image segmentation tasks. It allows for a smooth integration of multi-view information, significantly boosting both the accuracy and data-efficiency of the model. Code and models are available at https://github.com/UCSC-VLAA/SwinMM/.