 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
End-to-End Learning on Multimodal Knowledge Graphs
Sep 03, 2023
Knowledge graphs enable data scientists to learn end-to-end on heterogeneous knowledge. However, most end-to-end models solely learn from the relational information encoded in graphs' structure: raw values, encoded as literal nodes, are either omitted completely or treated as regular nodes without consideration for their values. In either case we lose potentially relevant information which could have otherwise been exploited by our learning methods. We propose a multimodal message passing network which not only learns end-to-end from the structure of graphs, but also from their possibly divers set of multimodal node features. Our model uses dedicated (neural) encoders to naturally learn embeddings for node features belonging to five different types of modalities, including numbers, texts, dates, images and geometries, which are projected into a joint representation space together with their relational information. We implement and demonstrate our model on node classification and link prediction for artificial and real-worlds datasets, and evaluate the effect that each modality has on the overall performance in an inverse ablation study. Our results indicate that end-to-end multimodal learning from any arbitrary knowledge graph is indeed possible, and that including multimodal information can significantly affect performance, but that much depends on the characteristics of the data.
RBA-GCN: Relational Bilevel Aggregation Graph Convolutional Network for Emotion Recognition
Aug 31, 2023Emotion recognition in conversation (ERC) has received increasing attention from researchers due to its wide range of applications.As conversation has a natural graph structure,numerous approaches used to model ERC based on graph convolutional networks (GCNs) have yielded significant results.However,the aggregation approach of traditional GCNs suffers from the node information redundancy problem,leading to node discriminant information loss.Additionally,single-layer GCNs lack the capacity to capture long-range contextual information from the graph. Furthermore,the majority of approaches are based on textual modality or stitching together different modalities, resulting in a weak ability to capture interactions between modalities. To address these problems, we present the relational bilevel aggregation graph convolutional network (RBA-GCN), which consists of three modules: the graph generation module (GGM), similarity-based cluster building module (SCBM) and bilevel aggregation module (BiAM). First, GGM constructs a novel graph to reduce the redundancy of target node information.Then,SCBM calculates the node similarity in the target node and its structural neighborhood, where noisy information with low similarity is filtered out to preserve the discriminant information of the node. Meanwhile, BiAM is a novel aggregation method that can preserve the information of nodes during the aggregation process. This module can construct the interaction between different modalities and capture long-range contextual information based on similarity clusters. On both the IEMOCAP and MELD datasets, the weighted average F1 score of RBA-GCN has a 2.17$\sim$5.21\% improvement over that of the most advanced method.Our code is available at https://github.com/luftmenscher/RBA-GCN and our article with the same name has been published in IEEE/ACM Transactions on Audio,Speech,and Language Processing,vol.31,2023
Collectionless Artificial Intelligence
Sep 13, 2023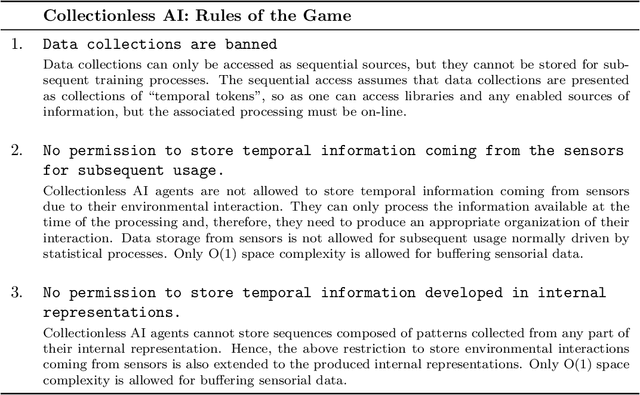

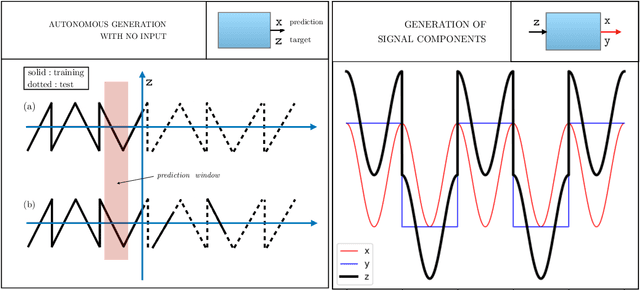
By and large, the professional handling of huge data collections is regarded as a fundamental ingredient of the progress of machine learning and of its spectacular results in related disciplines, with a growing agreement on risks connected to the centralization of such data collections. This paper sustains the position that the time has come for thinking of new learning protocols where machines conquer cognitive skills in a truly human-like context centered on environmental interactions. This comes with specific restrictions on the learning protocol according to the collectionless principle, which states that, at each time instant, data acquired from the environment is processed with the purpose of contributing to update the current internal representation of the environment, and that the agent is not given the privilege of recording the temporal stream. Basically, there is neither permission to store the temporal information coming from the sensors, thus promoting the development of self-organized memorization skills at a more abstract level, instead of relying on bare storage to simulate learning dynamics that are typical of offline learning algorithms. This purposely extreme position is intended to stimulate the development of machines that learn to dynamically organize the information by following human-based schemes. The proposition of this challenge suggests developing new foundations on computational processes of learning and reasoning that might open the doors to a truly orthogonal competitive track on AI technologies that avoid data accumulation by design, thus offering a framework which is better suited concerning privacy issues, control and customizability. Finally, pushing towards massively distributed computation, the collectionless approach to AI will likely reduce the concentration of power in companies and governments, thus better facing geopolitical issues.
All Labels Together: Low-shot Intent Detection with an Efficient Label Semantic Encoding Paradigm
Sep 08, 2023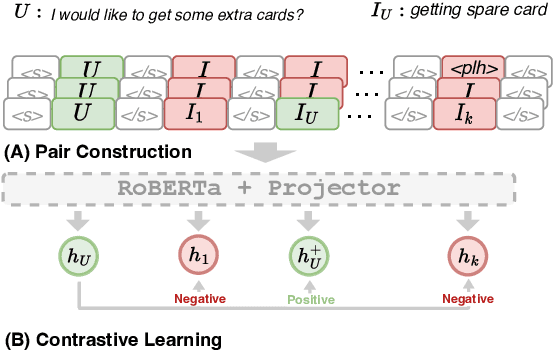
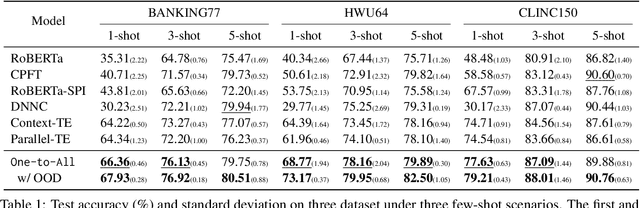
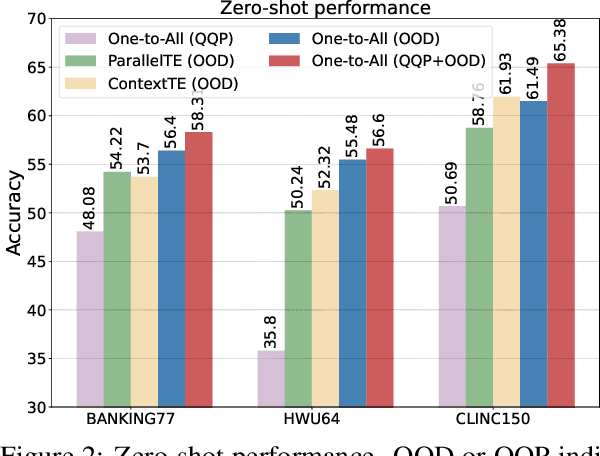

In intent detection tasks, leveraging meaningful semantic information from intent labels can be particularly beneficial for few-shot scenarios. However, existing few-shot intent detection methods either ignore the intent labels, (e.g. treating intents as indices) or do not fully utilize this information (e.g. only using part of the intent labels). In this work, we present an end-to-end One-to-All system that enables the comparison of an input utterance with all label candidates. The system can then fully utilize label semantics in this way. Experiments on three few-shot intent detection tasks demonstrate that One-to-All is especially effective when the training resource is extremely scarce, achieving state-of-the-art performance in 1-, 3- and 5-shot settings. Moreover, we present a novel pretraining strategy for our model that utilizes indirect supervision from paraphrasing, enabling zero-shot cross-domain generalization on intent detection tasks. Our code is at https://github.com/jiangshdd/AllLablesTogether.
CLIPUNetr: Assisting Human-robot Interface for Uncalibrated Visual Servoing Control with CLIP-driven Referring Expression Segmentation
Sep 17, 2023The classical human-robot interface in uncalibrated image-based visual servoing (UIBVS) relies on either human annotations or semantic segmentation with categorical labels. Both methods fail to match natural human communication and convey rich semantics in manipulation tasks as effectively as natural language expressions. In this paper, we tackle this problem by using referring expression segmentation, which is a prompt-based approach, to provide more in-depth information for robot perception. To generate high-quality segmentation predictions from referring expressions, we propose CLIPUNetr - a new CLIP-driven referring expression segmentation network. CLIPUNetr leverages CLIP's strong vision-language representations to segment regions from referring expressions, while utilizing its ``U-shaped'' encoder-decoder architecture to generate predictions with sharper boundaries and finer structures. Furthermore, we propose a new pipeline to integrate CLIPUNetr into UIBVS and apply it to control robots in real-world environments. In experiments, our method improves boundary and structure measurements by an average of 120% and can successfully assist real-world UIBVS control in an unstructured manipulation environment.
OWL: A Large Language Model for IT Operations
Sep 17, 2023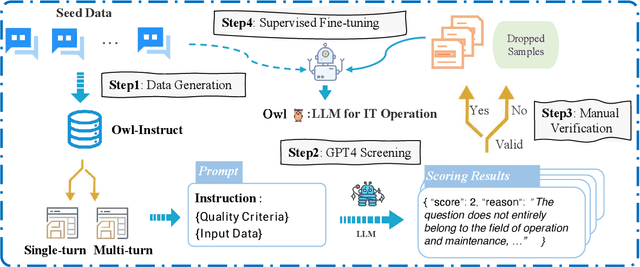



With the rapid development of IT operations, it has become increasingly crucial to efficiently manage and analyze large volumes of data for practical applications. The techniques of Natural Language Processing (NLP) have shown remarkable capabilities for various tasks, including named entity recognition, machine translation and dialogue systems. Recently, Large Language Models (LLMs) have achieved significant improvements across various NLP downstream tasks. However, there is a lack of specialized LLMs for IT operations. In this paper, we introduce the OWL, a large language model trained on our collected OWL-Instruct dataset with a wide range of IT-related information, where the mixture-of-adapter strategy is proposed to improve the parameter-efficient tuning across different domains or tasks. Furthermore, we evaluate the performance of our OWL on the OWL-Bench established by us and open IT-related benchmarks. OWL demonstrates superior performance results on IT tasks, which outperforms existing models by significant margins. Moreover, we hope that the findings of our work will provide more insights to revolutionize the techniques of IT operations with specialized LLMs.
A Few-Shot Approach to Dysarthric Speech Intelligibility Level Classification Using Transformers
Sep 17, 2023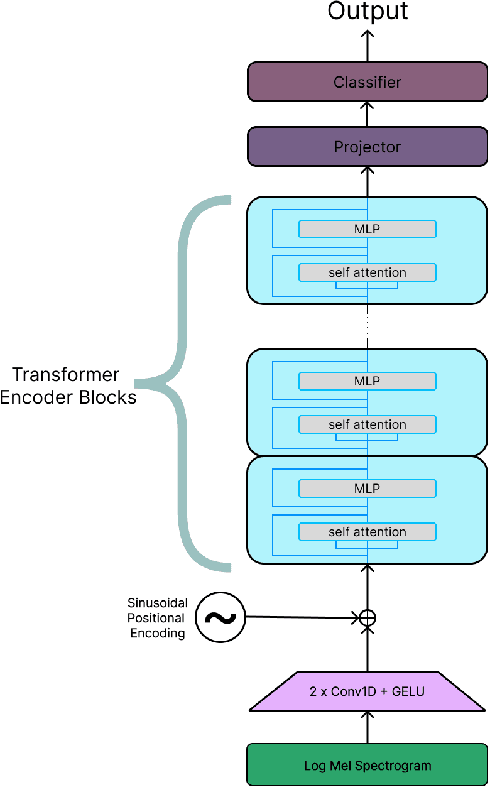
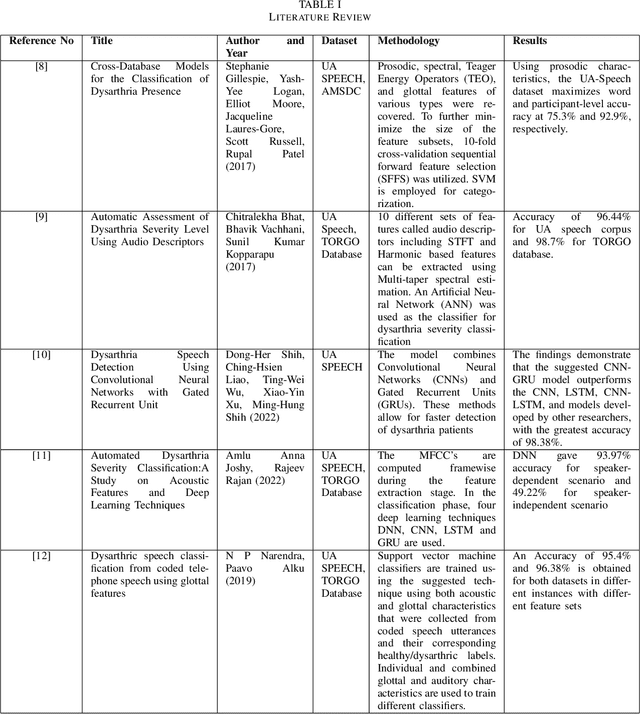
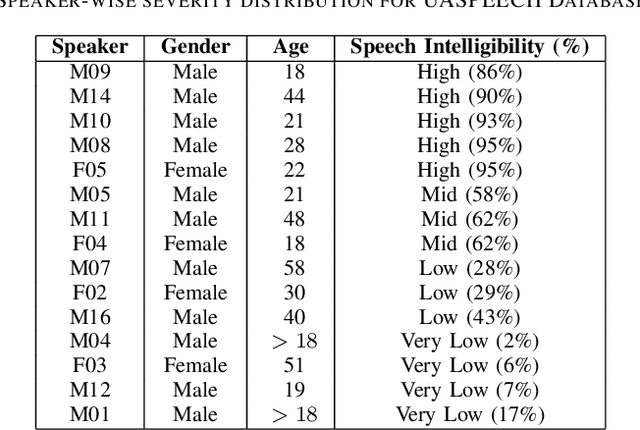
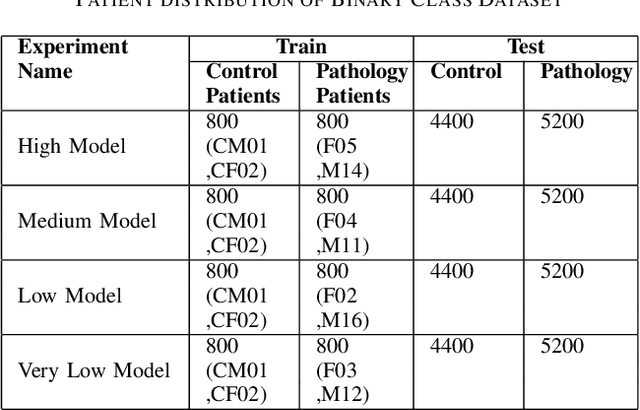
Dysarthria is a speech disorder that hinders communication due to difficulties in articulating words. Detection of dysarthria is important for several reasons as it can be used to develop a treatment plan and help improve a person's quality of life and ability to communicate effectively. Much of the literature focused on improving ASR systems for dysarthric speech. The objective of the current work is to develop models that can accurately classify the presence of dysarthria and also give information about the intelligibility level using limited data by employing a few-shot approach using a transformer model. This work also aims to tackle the data leakage that is present in previous studies. Our whisper-large-v2 transformer model trained on a subset of the UASpeech dataset containing medium intelligibility level patients achieved an accuracy of 85%, precision of 0.92, recall of 0.8 F1-score of 0.85, and specificity of 0.91. Experimental results also demonstrate that the model trained using the 'words' dataset performed better compared to the model trained on the 'letters' and 'digits' dataset. Moreover, the multiclass model achieved an accuracy of 67%.
NeRF-VINS: A Real-time Neural Radiance Field Map-based Visual-Inertial Navigation System
Sep 17, 2023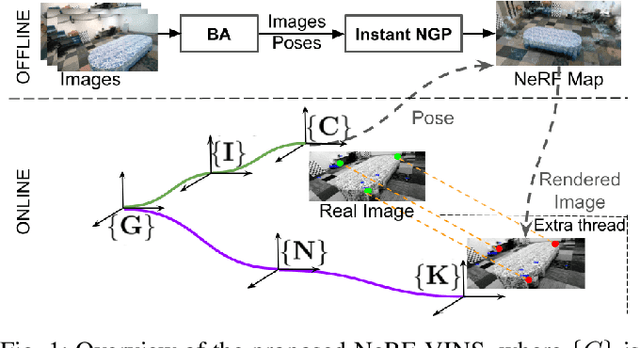


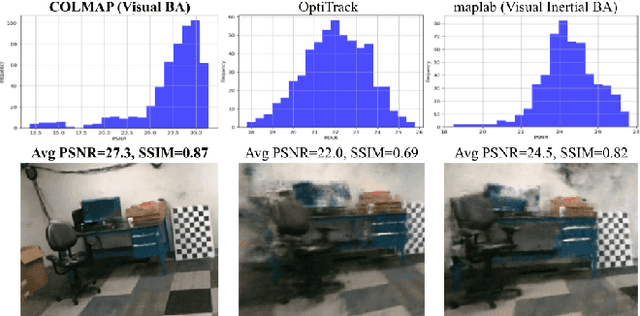
Achieving accurate, efficient, and consistent localization within an a priori environment map remains a fundamental challenge in robotics and computer vision. Conventional map-based keyframe localization often suffers from sub-optimal viewpoints due to limited field of view (FOV), thus degrading its performance. To address this issue, in this paper, we design a real-time tightly-coupled Neural Radiance Fields (NeRF)-aided visual-inertial navigation system (VINS), termed NeRF-VINS. By effectively leveraging NeRF's potential to synthesize novel views, essential for addressing limited viewpoints, the proposed NeRF-VINS optimally fuses IMU and monocular image measurements along with synthetically rendered images within an efficient filter-based framework. This tightly coupled integration enables 3D motion tracking with bounded error. We extensively compare the proposed NeRF-VINS against the state-of-the-art methods that use prior map information, which is shown to achieve superior performance. We also demonstrate the proposed method is able to perform real-time estimation at 15 Hz, on a resource-constrained Jetson AGX Orin embedded platform with impressive accuracy.
Heuristic-based Incremental Probabilistic Roadmap for Efficient UAV Exploration in Dynamic Environments
Sep 17, 2023Autonomous exploration in dynamic environments necessitates a planner that can proactively respond to changes and make efficient and safe decisions for robots. Although plenty of sampling-based works have shown success in exploring static environments, their inherent sampling randomness and limited utilization of previous samples often result in sub-optimal exploration efficiency. Additionally, most of these methods struggle with efficient replanning and collision avoidance in dynamic settings. To overcome these limitations, we propose the Heuristic-based Incremental Probabilistic Roadmap Exploration (HIRE) planner for UAVs exploring dynamic environments. The proposed planner adopts an incremental sampling strategy based on the probabilistic roadmap constructed by heuristic sampling toward the unexplored region next to the free space, defined as the heuristic frontier regions. The heuristic frontier regions are detected by applying a lightweight vision-based method to the different levels of the occupancy map. Moreover, our dynamic module ensures that the planner dynamically updates roadmap information based on the environment changes and avoids dynamic obstacles. Simulation and physical experiments prove that our planner can efficiently and safely explore dynamic environments.
Incentivizing Massive Unknown Workers for Budget-Limited Crowdsensing: From Off-Line and On-Line Perspectives
Sep 21, 2023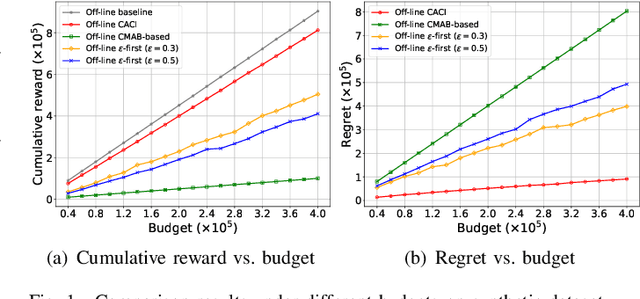
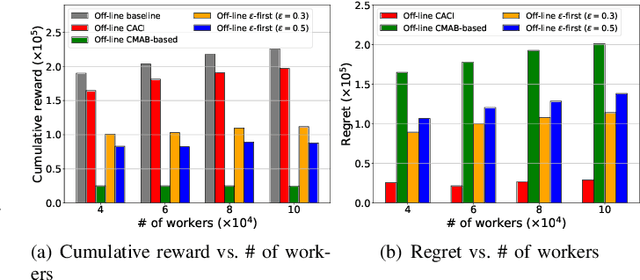
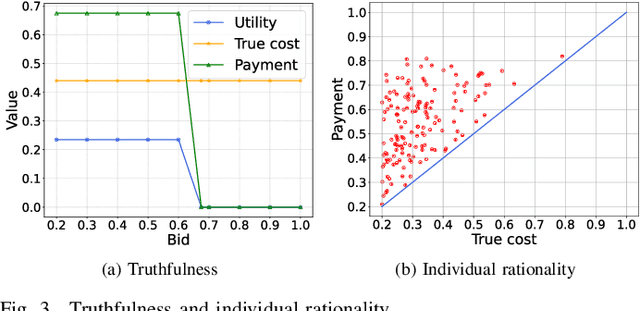
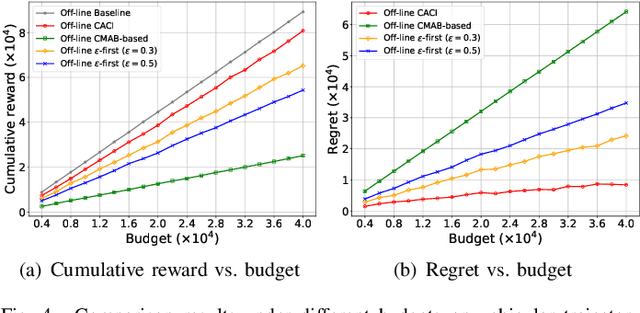
Although the uncertainties of the workers can be addressed by the standard Combinatorial Multi-Armed Bandit (CMAB) framework in existing proposals through a trade-off between exploration and exploitation, we may not have sufficient budget to enable the trade-off among the individual workers, especially when the number of the workers is huge while the budget is limited. Moreover, the standard CMAB usually assumes the workers always stay in the system, whereas the workers may join in or depart from the system over time, such that what we have learnt for an individual worker cannot be applied after the worker leaves. To address the above challenging issues, in this paper, we first propose an off-line Context-Aware CMAB-based Incentive (CACI) mechanism. We innovate in leveraging the exploration-exploitation trade-off in a elaborately partitioned context space instead of the individual workers, to effectively incentivize the massive unknown workers with very limited budget. We also extend the above basic idea to the on-line setting where unknown workers may join in or depart from the systems dynamically, and propose an on-line version of the CACI mechanism. Specifically, by the exploitation-exploration trade-off in the context space, we learn to estimate the sensing ability of any unknown worker (even it never appeared in the system before) according to its context information. We perform rigorous theoretical analysis to reveal the upper bounds on the regrets of our CACI mechanisms and to prove their truthfulness and individual rationality, respectively. Extensive experiments on both synthetic and real datasets are also conducted to verify the efficacy of our mechanisms.