 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Learning on Multimodal Knowledge Graphs
Sep 03, 2023Knowledge graphs enable data scientists to learn end-to-end on heterogeneous knowledge. However, most end-to-end models solely learn from the relational information encoded in graphs' structure: raw values, encoded as literal nodes, are either omitted completely or treated as regular nodes without consideration for their values. In either case we lose potentially relevant information which could have otherwise been exploited by our learning methods. We propose a multimodal message passing network which not only learns end-to-end from the structure of graphs, but also from their possibly divers set of multimodal node features. Our model uses dedicated (neural) encoders to naturally learn embeddings for node features belonging to five different types of modalities, including numbers, texts, dates, images and geometries, which are projected into a joint representation space together with their relational information. We implement and demonstrate our model on node classification and link prediction for artificial and real-worlds datasets, and evaluate the effect that each modality has on the overall performance in an inverse ablation study. Our results indicate that end-to-end multimodal learning from any arbitrary knowledge graph is indeed possible, and that including multimodal information can significantly affect performance, but that much depends on the characteristics of the data.
End-to-End Entity Classification on Multimodal Knowledge Graphs
Mar 25, 2020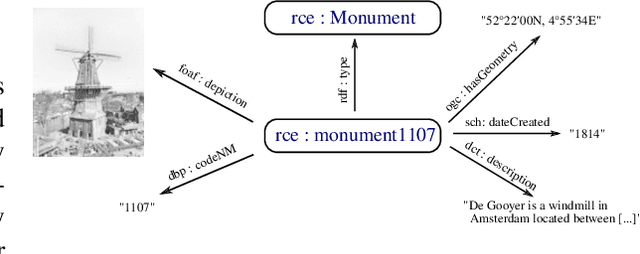
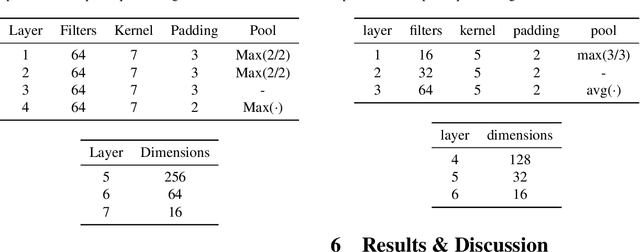
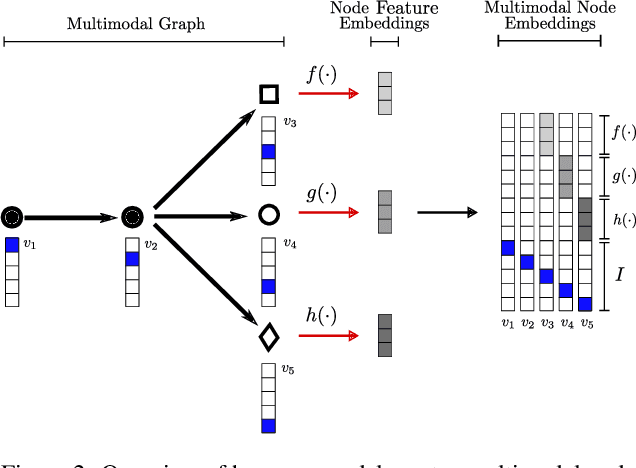
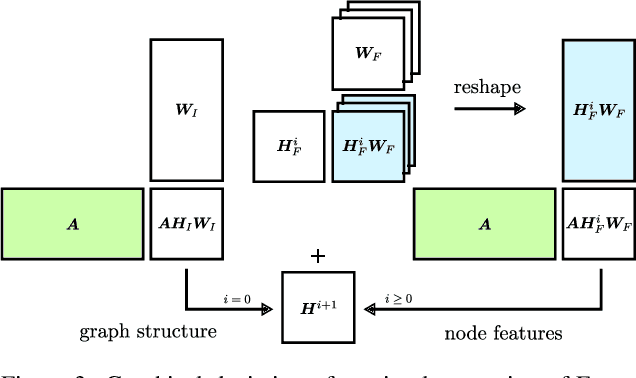
End-to-end multimodal learning on knowledge graphs has been left largely unaddressed. Instead, most end-to-end models such as message passing networks learn solely from the relational information encoded in graphs' structure: raw values, or literals, are either omitted completely or are stripped from their values and treated as regular nodes. In either case we lose potentially relevant information which could have otherwise been exploited by our learning methods. To avoid this, we must treat literals and non-literals as separate cases. We must also address each modality separately and accordingly: numbers, texts, images, geometries, et cetera. We propose a multimodal message passing network which not only learns end-to-end from the structure of graphs, but also from their possibly divers set of multimodal node features. Our model uses dedicated (neural) encoders to naturally learn embeddings for node features belonging to five different types of modalities, including images and geometries, which are projected into a joint representation space together with their relational information. We demonstrate our model on a node classification task, and evaluate the effect that each modality has on the overall performance. Our result supports our hypothesis that including information from multiple modalities can help our models obtain a better overall performance.