 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning Beyond Text: Graph-based Reasoning for Complex Narrative Generation
Apr 23, 2026While LLMs demonstrate remarkable fluency in narrative generation, existing methods struggle to maintain global narrative coherence, contextual logical consistency, and smooth character development, often producing monotonous scripts with structural fractures. To this end, we introduce PLOTTER, a framework that performs narrative planning on structural graph representations instead of the direct sequential text representations used in existing work. Specifically, PLOTTER executes the Evaluate-Plan-Revise cycle on the event graph and character graph. By diagnosing and repairing issues of the graph topology under rigorous logical constraints, the model optimizes the causality and narrative skeleton before complete context generation. Experiments demonstrate that PLOTTER significantly outperforms representative baselines across diverse narrative scenarios. These findings verify that planning narratives on structural graph representations-rather than directly on text-is crucial to enhance the long context reasoning of LLMs in complex narrative generation.
Stop Summation: Min-Form Credit Assignment Is All Process Reward Model Needs for Reasoning
Apr 21, 2025



Process reward models (PRMs) have proven effective for test-time scaling of Large Language Models (LLMs) on challenging reasoning tasks. However, reward hacking issues with PRMs limit their successful application in reinforcement fine-tuning. In this paper, we identify the main cause of PRM-induced reward hacking: the canonical summation-form credit assignment in reinforcement learning (RL), which defines the value as cumulative gamma-decayed future rewards, easily induces LLMs to hack steps with high rewards. To address this, we propose PURE: Process sUpervised Reinforcement lEarning. The key innovation of PURE is a min-form credit assignment that formulates the value function as the minimum of future rewards. This method significantly alleviates reward hacking by limiting the value function range and distributing advantages more reasonably. Through extensive experiments on 3 base models, we show that PRM-based approaches enabling min-form credit assignment achieve comparable reasoning performance to verifiable reward-based methods within only 30% steps. In contrast, the canonical sum-form credit assignment collapses training even at the beginning! Additionally, when we supplement PRM-based fine-tuning with just 10% verifiable rewards, we further alleviate reward hacking and produce the best fine-tuned model based on Qwen2.5-Math-7B in our experiments, achieving 82.5% accuracy on AMC23 and 53.3% average accuracy across 5 benchmarks. Moreover, we summarize the observed reward hacking cases and analyze the causes of training collapse. Code and models are available at https://github.com/CJReinforce/PURE.
Through the Curved Cover: Synthesizing Cover Aberrated Scenes with Refractive Field
Nov 10, 2024



Recent extended reality headsets and field robots have adopted covers to protect the front-facing cameras from environmental hazards and falls. The surface irregularities on the cover can lead to optical aberrations like blurring and non-parametric distortions. Novel view synthesis methods like NeRF and 3D Gaussian Splatting are ill-equipped to synthesize from sequences with optical aberrations. To address this challenge, we introduce SynthCover to enable novel view synthesis through protective covers for downstream extended reality applications. SynthCover employs a Refractive Field that estimates the cover's geometry, enabling precise analytical calculation of refracted rays. Experiments on synthetic and real-world scenes demonstrate our method's ability to accurately model scenes viewed through protective covers, achieving a significant improvement in rendering quality compared to prior methods. We also show that the model can adjust well to various cover geometries with synthetic sequences captured with covers of different surface curvatures. To motivate further studies on this problem, we provide the benchmarked dataset containing real and synthetic walkable scenes captured with protective cover optical aberrations.
NeRF-VINS: A Real-time Neural Radiance Field Map-based Visual-Inertial Navigation System
Sep 17, 2023



Achieving accurate, efficient, and consistent localization within an a priori environment map remains a fundamental challenge in robotics and computer vision. Conventional map-based keyframe localization often suffers from sub-optimal viewpoints due to limited field of view (FOV), thus degrading its performance. To address this issue, in this paper, we design a real-time tightly-coupled Neural Radiance Fields (NeRF)-aided visual-inertial navigation system (VINS), termed NeRF-VINS. By effectively leveraging NeRF's potential to synthesize novel views, essential for addressing limited viewpoints, the proposed NeRF-VINS optimally fuses IMU and monocular image measurements along with synthetically rendered images within an efficient filter-based framework. This tightly coupled integration enables 3D motion tracking with bounded error. We extensively compare the proposed NeRF-VINS against the state-of-the-art methods that use prior map information, which is shown to achieve superior performance. We also demonstrate the proposed method is able to perform real-time estimation at 15 Hz, on a resource-constrained Jetson AGX Orin embedded platform with impressive accuracy.
A multi view multi stage and multi window framework for pulmonary artery segmentation from CT scans
Sep 14, 2022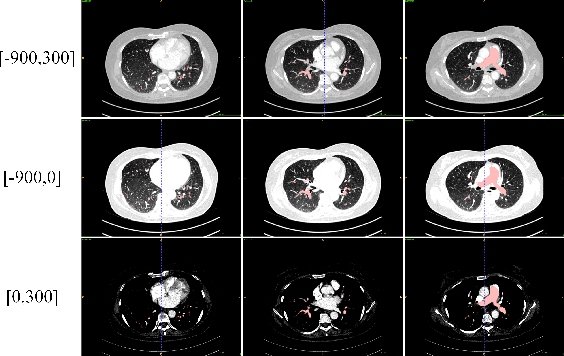

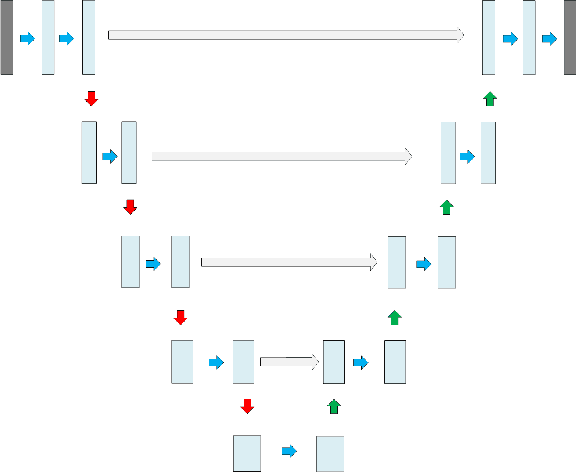

This is the technical report of the 9th place in the final result of PARSE2022 Challenge. We solve the segmentation problem of the pulmonary artery by using a two-stage method based on a 3D CNN network. The coarse model is used to locate the ROI, and the fine model is used to refine the segmentation result. In addition, in order to improve the segmentation performance, we adopt multi-view and multi-window level method, at the same time we employ a fine-tune strategy to mitigate the impact of inconsistent labeling.