 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UNK-VQA: A Dataset and A Probe into Multi-modal Large Models' Abstention Ability
Oct 28, 2023
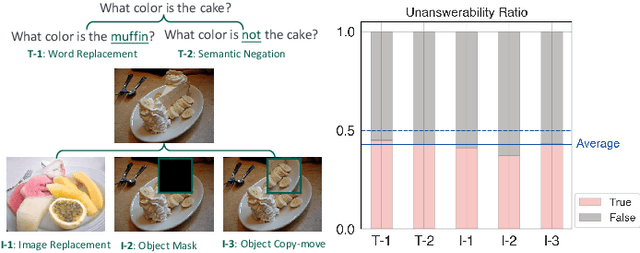


Teaching Visual Question Answering (VQA) models to refrain from answering unanswerable questions is necessary for building a trustworthy AI system. Existing studies, though have explored various aspects of VQA but somewhat ignored this particular attribute. This paper aims to bridge the research gap by contributing a comprehensive dataset, called UNK-VQA. The dataset is specifically designed to address the challenge of questions that models do not know. To this end, we first augment the existing data via deliberate perturbations on either the image or question. In specific, we carefully ensure that the question-image semantics remain close to the original unperturbed distribution. By this means, the identification of unanswerable questions becomes challenging, setting our dataset apart from others that involve mere image replacement. We then extensively evaluate the zero- and few-shot performance of several emerging multi-modal large models and discover their significant limitations when applied to our dataset. Additionally, we also propose a straightforward method to tackle these unanswerable questions. This dataset, we believe, will serve as a valuable benchmark for enhancing the abstention capability of VQA models, thereby leading to increased trustworthiness of AI systems. We have made the \href{https://github.com/guoyang9/UNK-VQA}{dataset} available to facilitate further exploration in this area.
Degradation-Aware Self-Attention Based Transformer for Blind Image Super-Resolution
Oct 06, 2023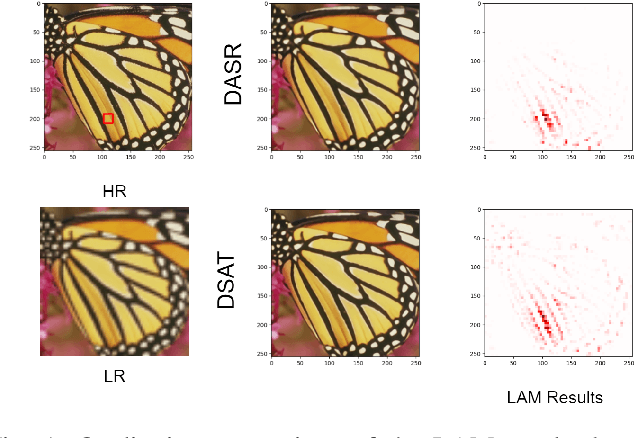

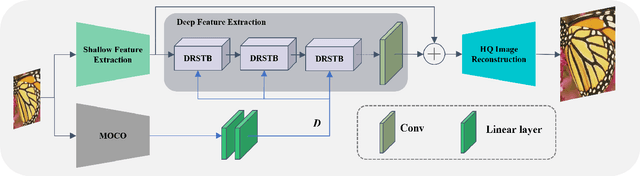
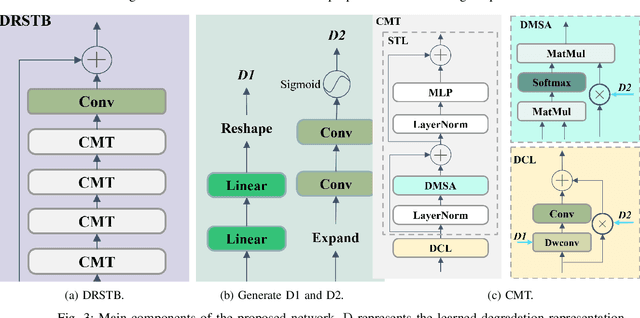
Compared to CNN-based methods, Transformer-based methods achieve impressive image restoration outcomes due to their abilities to model remote dependencies. However, how to apply Transformer-based methods to the field of blind super-resolution (SR) and further make an SR network adaptive to degradation information is still an open problem. In this paper, we propose a new degradation-aware self-attention-based Transformer model, where we incorporate contrastive learning into the Transformer network for learning the degradation representations of input images with unknown noise. In particular, we integrate both CNN and Transformer components into the SR network, where we first use the CNN modulated by the degradation information to extract local features, and then employ the degradation-aware Transformer to extract global semantic features. We apply our proposed model to several popular large-scale benchmark datasets for testing, and achieve the state-of-the-art performance compared to existing methods. In particular, our method yields a PSNR of 32.43 dB on the Urban100 dataset at $\times$2 scale, 0.94 dB higher than DASR, and 26.62 dB on the Urban100 dataset at $\times$4 scale, 0.26 dB improvement over KDSR, setting a new benchmark in this area. Source code is available at: https://github.com/I2-Multimedia-Lab/DSAT/tree/main.
High-resolution power equipment recognition based on improved self-attention
Nov 06, 2023The current trend of automating inspections at substations has sparked a surge in interest in the field of transformer image recognition. However, due to restrictions in the number of parameters in existing models, high-resolution images can't be directly applied, leaving significant room for enhancing recognition accuracy. Addressing this challenge, the paper introduces a novel improvement on deep self-attention networks tailored for this issue. The proposed model comprises four key components: a foundational network, a region proposal network, a module for extracting and segmenting target areas, and a final prediction network. The innovative approach of this paper differentiates itself by decoupling the processes of part localization and recognition, initially using low-resolution images for localization followed by high-resolution images for recognition. Moreover, the deep self-attention network's prediction mechanism uniquely incorporates the semantic context of images, resulting in substantially improved recognition performance. Comparative experiments validate that this method outperforms the two other prevalent target recognition models, offering a groundbreaking perspective for automating electrical equipment inspections.
GQKVA: Efficient Pre-training of Transformers by Grouping Queries, Keys, and Values
Nov 06, 2023Massive transformer-based models face several challenges, including slow and computationally intensive pre-training and over-parametrization. This paper addresses these challenges by proposing a versatile method called GQKVA, which generalizes query, key, and value grouping techniques. GQKVA is designed to speed up transformer pre-training while reducing the model size. Our experiments with various GQKVA variants highlight a clear trade-off between performance and model size, allowing for customized choices based on resource and time limitations. Our findings also indicate that the conventional multi-head attention approach is not always the best choice, as there are lighter and faster alternatives available. We tested our method on ViT, which achieved an approximate 0.3% increase in accuracy while reducing the model size by about 4% in the task of image classification. Additionally, our most aggressive model reduction experiment resulted in a reduction of approximately 15% in model size, with only around a 1% drop in accuracy.
TEAL: Tokenize and Embed ALL for Multi-modal Large Language Models
Nov 08, 2023Despite Multi-modal Large Language Models (MM-LLMs) have made exciting strides recently, they are still struggling to efficiently model the interactions among multi-modal inputs and the generation in non-textual modalities. In this work, we propose TEAL (Tokenize and Embed ALl)}, an approach to treat the input from any modality as a token sequence and learn a joint embedding space for all modalities. Specifically, for the input from any modality, TEAL first discretizes it into a token sequence with the off-the-shelf tokenizer and embeds the token sequence into a joint embedding space with a learnable embedding matrix. MM-LLMs just need to predict the multi-modal tokens autoregressively as the textual LLMs do. Finally, the corresponding de-tokenizer is applied to generate the output in each modality based on the predicted token sequence. With the joint embedding space, TEAL enables the frozen LLMs to perform both understanding and generation tasks involving non-textual modalities, such as image and audio. Thus, the textual LLM can just work as an interface and maintain its high performance in textual understanding and generation. Experiments show that TEAL achieves substantial improvements in multi-modal understanding, and implements a simple scheme for multi-modal generations.
Challenging Common Assumptions in Multi-task Learning
Nov 08, 2023While multi-task learning (MTL) has gained significant attention in recent years, its underlying mechanisms remain poorly understood. Recent methods did not yield consistent performance improvements over single task learning (STL) baselines, underscoring the importance of gaining more profound insights about challenges specific to MTL. In our study, we challenge common assumptions in MTL in the context of STL: First, the choice of optimizer has only been mildly investigated in MTL. We show the pivotal role of common STL tools such as the Adam optimizer in MTL. We deduce the effectiveness of Adam to its partial loss-scale invariance. Second, the notion of gradient conflicts has often been phrased as a specific problem in MTL. We delve into the role of gradient conflicts in MTL and compare it to STL. For angular gradient alignment we find no evidence that this is a unique problem in MTL. We emphasize differences in gradient magnitude as the main distinguishing factor. Lastly, we compare the transferability of features learned through MTL and STL on common image corruptions, and find no conclusive evidence that MTL leads to superior transferability. Overall, we find surprising similarities between STL and MTL suggesting to consider methods from both fields in a broader context.
On Characterizing the Evolution of Embedding Space of Neural Networks using Algebraic Topology
Nov 08, 2023We study how the topology of feature embedding space changes as it passes through the layers of a well-trained deep neural network (DNN) through Betti numbers. Motivated by existing studies using simplicial complexes on shallow fully connected networks (FCN), we present an extended analysis using Cubical homology instead, with a variety of popular deep architectures and real image datasets. We demonstrate that as depth increases, a topologically complicated dataset is transformed into a simple one, resulting in Betti numbers attaining their lowest possible value. The rate of decay in topological complexity (as a metric) helps quantify the impact of architectural choices on the generalization ability. Interestingly from a representation learning perspective, we highlight several invariances such as topological invariance of (1) an architecture on similar datasets; (2) embedding space of a dataset for architectures of variable depth; (3) embedding space to input resolution/size, and (4) data sub-sampling. In order to further demonstrate the link between expressivity \& the generalization capability of a network, we consider the task of ranking pre-trained models for downstream classification task (transfer learning). Compared to existing approaches, the proposed metric has a better correlation to the actually achievable accuracy via fine-tuning the pre-trained model.
PRED: Pre-training via Semantic Rendering on LiDAR Point Clouds
Nov 08, 2023Pre-training is crucial in 3D-related fields such as autonomous driving where point cloud annotation is costly and challenging. Many recent studies on point cloud pre-training, however, have overlooked the issue of incompleteness, where only a fraction of the points are captured by LiDAR, leading to ambiguity during the training phase. On the other hand, images offer more comprehensive information and richer semantics that can bolster point cloud encoders in addressing the incompleteness issue inherent in point clouds. Yet, incorporating images into point cloud pre-training presents its own challenges due to occlusions, potentially causing misalignments between points and pixels. In this work, we propose PRED, a novel image-assisted pre-training framework for outdoor point clouds in an occlusion-aware manner. The main ingredient of our framework is a Birds-Eye-View (BEV) feature map conditioned semantic rendering, leveraging the semantics of images for supervision through neural rendering. We further enhance our model's performance by incorporating point-wise masking with a high mask ratio (95%). Extensive experiments demonstrate PRED's superiority over prior point cloud pre-training methods, providing significant improvements on various large-scale datasets for 3D perception tasks. Codes will be available at https://github.com/PRED4pc/PRED.
Style-Aware Radiology Report Generation with RadGraph and Few-Shot Prompting
Oct 26, 2023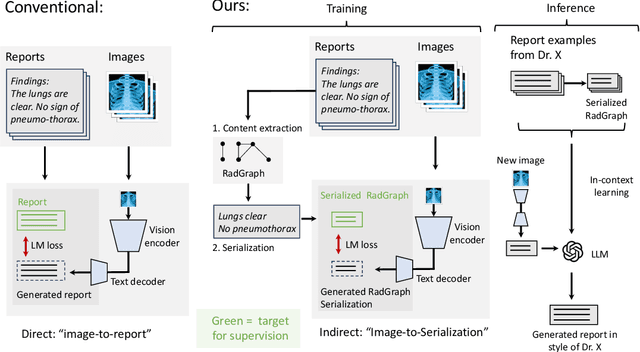

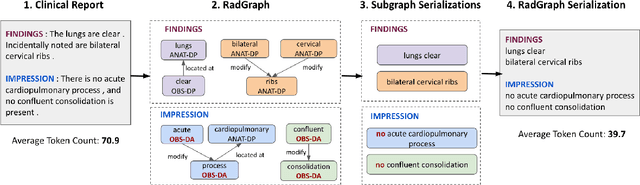

Automatically generated reports from medical images promise to improve the workflow of radiologists. Existing methods consider an image-to-report modeling task by directly generating a fully-fledged report from an image. However, this conflates the content of the report (e.g., findings and their attributes) with its style (e.g., format and choice of words), which can lead to clinically inaccurate reports. To address this, we propose a two-step approach for radiology report generation. First, we extract the content from an image; then, we verbalize the extracted content into a report that matches the style of a specific radiologist. For this, we leverage RadGraph -- a graph representation of reports -- together with large language models (LLMs). In our quantitative evaluations, we find that our approach leads to beneficial performance. Our human evaluation with clinical raters highlights that the AI-generated reports are indistinguishably tailored to the style of individual radiologist despite leveraging only a few examples as context.
SD4Match: Learning to Prompt Stable Diffusion Model for Semantic Matching
Oct 26, 2023In this paper, we address the challenge of matching semantically similar keypoints across image pairs. Existing research indicates that the intermediate output of the UNet within the Stable Diffusion (SD) can serve as robust image feature maps for such a matching task. We demonstrate that by employing a basic prompt tuning technique, the inherent potential of Stable Diffusion can be harnessed, resulting in a significant enhancement in accuracy over previous approaches. We further introduce a novel conditional prompting module that conditions the prompt on the local details of the input image pairs, leading to a further improvement in performance. We designate our approach as SD4Match, short for Stable Diffusion for Semantic Matching. Comprehensive evaluations of SD4Match on the PF-Pascal, PF-Willow, and SPair-71k datasets show that it sets new benchmarks in accuracy across all these datasets. Particularly, SD4Match outperforms the previous state-of-the-art by a margin of 12 percentage points on the challenging SPair-71k dataset.