 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Enriched Latent Visual Reasoning
May 19, 2026Multimodal latent-space reasoning aims to replace explicit thinking with images by performing visual reasoning directly in a compact latent space. However, existing approaches largely rely on visual supervision and produce latent representations that lack sufficient semantic richness, limiting their ability to support diverse region-level reasoning tasks. In this work, we introduce Semantic-Enriched Latent Visual Reasoning (SLVR), a two-stage learning framework that enriches latent representations with attribute-level visual semantics and aligns them with diverse reasoning objectives. In the first stage, SLVR learns semantically enriched region-centric latents under fine-grained attribute supervision. In the second stage, we design Multi-query Group Relative Policy Optimization (M-GRPO) to align latent representations across multiple queries grounded in the same region. To support this framework, we construct SLV-Set, comprising approximately 400K region-level attribute annotations and 800K multi-query question answering samples, and introduce SV-QA, a benchmark that evaluates latent reasoning under semantic variation. Experiments demonstrate that SLVR improves the robustness and semantic consistency of latent visual reasoning compared to existing baselines.
Inpaint4Drag: Repurposing Inpainting Models for Drag-Based Image Editing via Bidirectional Warping
Sep 04, 2025



Drag-based image editing has emerged as a powerful paradigm for intuitive image manipulation. However, existing approaches predominantly rely on manipulating the latent space of generative models, leading to limited precision, delayed feedback, and model-specific constraints. Accordingly, we present Inpaint4Drag, a novel framework that decomposes drag-based editing into pixel-space bidirectional warping and image inpainting. Inspired by elastic object deformation in the physical world, we treat image regions as deformable materials that maintain natural shape under user manipulation. Our method achieves real-time warping previews (0.01s) and efficient inpainting (0.3s) at 512x512 resolution, significantly improving the interaction experience compared to existing methods that require minutes per edit. By transforming drag inputs directly into standard inpainting formats, our approach serves as a universal adapter for any inpainting model without architecture modification, automatically inheriting all future improvements in inpainting technology. Extensive experiments demonstrate that our method achieves superior visual quality and precise control while maintaining real-time performance. Project page: https://visual-ai.github.io/inpaint4drag/
Semantic Correspondence: Unified Benchmarking and a Strong Baseline
May 26, 2025Establishing semantic correspondence is a challenging task in computer vision, aiming to match keypoints with the same semantic information across different images. Benefiting from the rapid development of deep learning, remarkable progress has been made over the past decade. However, a comprehensive review and analysis of this task remains absent. In this paper, we present the first extensive survey of semantic correspondence methods. We first propose a taxonomy to classify existing methods based on the type of their method designs. These methods are then categorized accordingly, and we provide a detailed analysis of each approach. Furthermore, we aggregate and summarize the results of methods in literature across various benchmarks into a unified comparative table, with detailed configurations to highlight performance variations. Additionally, to provide a detailed understanding on existing methods for semantic matching, we thoroughly conduct controlled experiments to analyse the effectiveness of the components of different methods. Finally, we propose a simple yet effective baseline that achieves state-of-the-art performance on multiple benchmarks, providing a solid foundation for future research in this field. We hope this survey serves as a comprehensive reference and consolidated baseline for future development. Code is publicly available at: https://github.com/Visual-AI/Semantic-Correspondence.
Nature's Insight: A Novel Framework and Comprehensive Analysis of Agentic Reasoning Through the Lens of Neuroscience
May 07, 2025Autonomous AI is no longer a hard-to-reach concept, it enables the agents to move beyond executing tasks to independently addressing complex problems, adapting to change while handling the uncertainty of the environment. However, what makes the agents truly autonomous? It is agentic reasoning, that is crucial for foundation models to develop symbolic logic, statistical correlations, or large-scale pattern recognition to process information, draw inferences, and make decisions. However, it remains unclear why and how existing agentic reasoning approaches work, in comparison to biological reasoning, which instead is deeply rooted in neural mechanisms involving hierarchical cognition, multimodal integration, and dynamic interactions. In this work, we propose a novel neuroscience-inspired framework for agentic reasoning. Grounded in three neuroscience-based definitions and supported by mathematical and biological foundations, we propose a unified framework modeling reasoning from perception to action, encompassing four core types, perceptual, dimensional, logical, and interactive, inspired by distinct functional roles observed in the human brain. We apply this framework to systematically classify and analyze existing AI reasoning methods, evaluating their theoretical foundations, computational designs, and practical limitations. We also explore its implications for building more generalizable, cognitively aligned agents in physical and virtual environments. Finally, building on our framework, we outline future directions and propose new neural-inspired reasoning methods, analogous to chain-of-thought prompting. By bridging cognitive neuroscience and AI, this work offers a theoretical foundation and practical roadmap for advancing agentic reasoning in intelligent systems. The associated project can be found at: https://github.com/BioRAILab/Awesome-Neuroscience-Agent-Reasoning .
RegionDrag: Fast Region-Based Image Editing with Diffusion Models
Jul 25, 2024



Point-drag-based image editing methods, like DragDiffusion, have attracted significant attention. However, point-drag-based approaches suffer from computational overhead and misinterpretation of user intentions due to the sparsity of point-based editing instructions. In this paper, we propose a region-based copy-and-paste dragging method, RegionDrag, to overcome these limitations. RegionDrag allows users to express their editing instructions in the form of handle and target regions, enabling more precise control and alleviating ambiguity. In addition, region-based operations complete editing in one iteration and are much faster than point-drag-based methods. We also incorporate the attention-swapping technique for enhanced stability during editing. To validate our approach, we extend existing point-drag-based datasets with region-based dragging instructions. Experimental results demonstrate that RegionDrag outperforms existing point-drag-based approaches in terms of speed, accuracy, and alignment with user intentions. Remarkably, RegionDrag completes the edit on an image with a resolution of 512x512 in less than 2 seconds, which is more than 100x faster than DragDiffusion, while achieving better performance. Project page: https://visual-ai.github.io/regiondrag.
SD4Match: Learning to Prompt Stable Diffusion Model for Semantic Matching
Oct 26, 2023In this paper, we address the challenge of matching semantically similar keypoints across image pairs. Existing research indicates that the intermediate output of the UNet within the Stable Diffusion (SD) can serve as robust image feature maps for such a matching task. We demonstrate that by employing a basic prompt tuning technique, the inherent potential of Stable Diffusion can be harnessed, resulting in a significant enhancement in accuracy over previous approaches. We further introduce a novel conditional prompting module that conditions the prompt on the local details of the input image pairs, leading to a further improvement in performance. We designate our approach as SD4Match, short for Stable Diffusion for Semantic Matching. Comprehensive evaluations of SD4Match on the PF-Pascal, PF-Willow, and SPair-71k datasets show that it sets new benchmarks in accuracy across all these datasets. Particularly, SD4Match outperforms the previous state-of-the-art by a margin of 12 percentage points on the challenging SPair-71k dataset.
Learning Roles with Emergent Social Value Orientations
Jan 31, 2023



Social dilemmas can be considered situations where individual rationality leads to collective irrationality. The multi-agent reinforcement learning community has leveraged ideas from social science, such as social value orientations (SVO), to solve social dilemmas in complex cooperative tasks. In this paper, by first introducing the typical "division of labor or roles" mechanism in human society, we provide a promising solution for intertemporal social dilemmas (ISD) with SVOs. A novel learning framework, called Learning Roles with Emergent SVOs (RESVO), is proposed to transform the learning of roles into the social value orientation emergence, which is symmetrically solved by endowing agents with altruism to share rewards with other agents. An SVO-based role embedding space is then constructed by individual conditioning policies on roles with a novel rank regularizer and mutual information maximizer. Experiments show that RESVO achieves a stable division of labor and cooperation in ISDs with different complexity.
E2N: Error Estimation Networks for Goal-Oriented Mesh Adaptation
Jul 22, 2022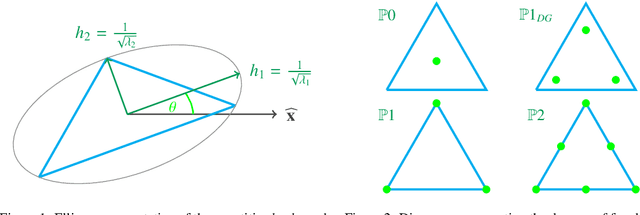
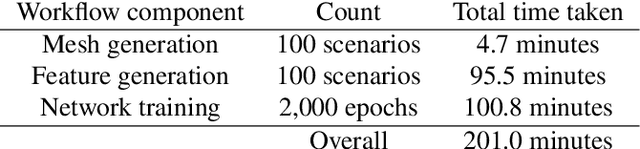
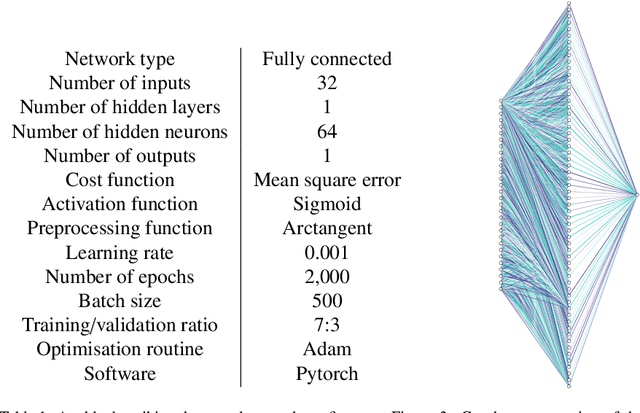
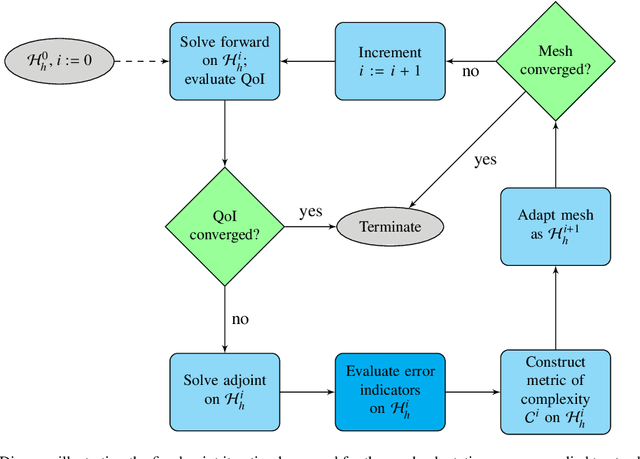
Given a partial differential equation (PDE), goal-oriented error estimation allows us to understand how errors in a diagnostic quantity of interest (QoI), or goal, occur and accumulate in a numerical approximation, for example using the finite element method. By decomposing the error estimates into contributions from individual elements, it is possible to formulate adaptation methods, which modify the mesh with the objective of minimising the resulting QoI error. However, the standard error estimate formulation involves the true adjoint solution, which is unknown in practice. As such, it is common practice to approximate it with an 'enriched' approximation (e.g. in a higher order space or on a refined mesh). Doing so generally results in a significant increase in computational cost, which can be a bottleneck compromising the competitiveness of (goal-oriented) adaptive simulations. The central idea of this paper is to develop a "data-driven" goal-oriented mesh adaptation approach through the selective replacement of the expensive error estimation step with an appropriately configured and trained neural network. In doing so, the error estimator may be obtained without even constructing the enriched spaces. An element-by-element construction is employed here, whereby local values of various parameters related to the mesh geometry and underlying problem physics are taken as inputs, and the corresponding contribution to the error estimator is taken as output. We demonstrate that this approach is able to obtain the same accuracy with a reduced computational cost, for adaptive mesh test cases related to flow around tidal turbines, which interact via their downstream wakes, and where the overall power output of the farm is taken as the QoI. Moreover, we demonstrate that the element-by-element approach implies reasonably low training costs.
FORCE: A Framework of Rule-Based Conversational Recommender System
Mar 18, 2022
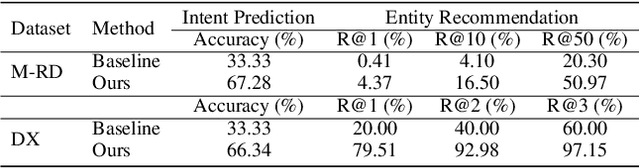
The conversational recommender systems (CRSs) have received extensive attention in recent years. However, most of the existing works focus on various deep learning models, which are largely limited by the requirement of large-scale human-annotated datasets. Such methods are not able to deal with the cold-start scenarios in industrial products. To alleviate the problem, we propose FORCE, a Framework Of Rule-based Conversational Recommender system that helps developers to quickly build CRS bots by simple configuration. We conduct experiments on two datasets in different languages and domains to verify its effectiveness and usability.