 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Surprising Effectiveness of Canonical Knowledge Distillation for Semantic Segmentation
Apr 28, 2026Recent knowledge distillation (KD) methods for semantic segmentation introduce increasingly complex hand-crafted objectives, yet are typically evaluated under fixed iteration schedules. These objectives substantially increase per-iteration cost, meaning equal iteration counts do not correspond to equal training budgets. It is therefore unclear whether reported gains reflect stronger distillation signals or simply greater compute. We show that iteration-based comparisons are misleading: when wall-clock compute is matched, \textit{canonical} logit- and feature-based KD outperform recent segmentation-specific methods. Under extended training, feature-based distillation achieves state-of-the-art ResNet-18 performance on Cityscapes and ADE20K. A PSPNet ResNet-18 student closely approaches its ResNet-101 teacher despite using only one quarter of the parameters, reaching 99\% of the teacher's mIoU on Cityscapes (79.0 vs.\ 79.8) and 92\% on ADE20K. Our results challenge the prevailing assumption that KD for segmentation requires task-specific mechanisms and suggest that scaling, rather than complex hand-crafted objectives, should guide future method design.
Attention Is All You Need For Mixture-of-Depths Routing
Dec 30, 2024



Advancements in deep learning are driven by training models with increasingly larger numbers of parameters, which in turn heightens the computational demands. To address this issue, Mixture-of-Depths (MoD) models have been proposed to dynamically assign computations only to the most relevant parts of the inputs, thereby enabling the deployment of large-parameter models with high efficiency during inference and training. These MoD models utilize a routing mechanism to determine which tokens should be processed by a layer, or skipped. However, conventional MoD models employ additional network layers specifically for the routing which are difficult to train, and add complexity and deployment overhead to the model. In this paper, we introduce a novel attention-based routing mechanism A-MoD that leverages the existing attention map of the preceding layer for routing decisions within the current layer. Compared to standard routing, A-MoD allows for more efficient training as it introduces no additional trainable parameters and can be easily adapted from pretrained transformer models. Furthermore, it can increase the performance of the MoD model. For instance, we observe up to 2% higher accuracy on ImageNet compared to standard routing and isoFLOP ViT baselines. Furthermore, A-MoD improves the MoD training convergence, leading to up to 2x faster transfer learning.
Object-Focused Data Selection for Dense Prediction Tasks
Dec 13, 2024



Dense prediction tasks such as object detection and segmentation require high-quality labels at pixel level, which are costly to obtain. Recent advances in foundation models have enabled the generation of autolabels, which we find to be competitive but not yet sufficient to fully replace human annotations, especially for more complex datasets. Thus, we consider the challenge of selecting a representative subset of images for labeling from a large pool of unlabeled images under a constrained annotation budget. This task is further complicated by imbalanced class distributions, as rare classes are often underrepresented in selected subsets. We propose object-focused data selection (OFDS) which leverages object-level representations to ensure that the selected image subsets semantically cover the target classes, including rare ones. We validate OFDS on PASCAL VOC and Cityscapes for object detection and semantic segmentation tasks. Our experiments demonstrate that prior methods which employ image-level representations fail to consistently outperform random selection. In contrast, OFDS consistently achieves state-of-the-art performance with substantial improvements over all baselines in scenarios with imbalanced class distributions. Moreover, we demonstrate that pre-training with autolabels on the full datasets before fine-tuning on human-labeled subsets selected by OFDS further enhances the final performance.
Analytical Uncertainty-Based Loss Weighting in Multi-Task Learning
Aug 15, 2024With the rise of neural networks in various domains, multi-task learning (MTL) gained significant relevance. A key challenge in MTL is balancing individual task losses during neural network training to improve performance and efficiency through knowledge sharing across tasks. To address these challenges, we propose a novel task-weighting method by building on the most prevalent approach of Uncertainty Weighting and computing analytically optimal uncertainty-based weights, normalized by a softmax function with tunable temperature. Our approach yields comparable results to the combinatorially prohibitive, brute-force approach of Scalarization while offering a more cost-effective yet high-performing alternative. We conduct an extensive benchmark on various datasets and architectures. Our method consistently outperforms six other common weighting methods. Furthermore, we report noteworthy experimental findings for the practical application of MTL. For example, larger networks diminish the influence of weighting methods, and tuning the weight decay has a low impact compared to the learning rate.
Mind the Gap Between Synthetic and Real: Utilizing Transfer Learning to Probe the Boundaries of Stable Diffusion Generated Data
May 06, 2024



Generative foundation models like Stable Diffusion comprise a diverse spectrum of knowledge in computer vision with the potential for transfer learning, e.g., via generating data to train student models for downstream tasks. This could circumvent the necessity of collecting labeled real-world data, thereby presenting a form of data-free knowledge distillation. However, the resultant student models show a significant drop in accuracy compared to models trained on real data. We investigate possible causes for this drop and focus on the role of the different layers of the student model. By training these layers using either real or synthetic data, we reveal that the drop mainly stems from the model's final layers. Further, we briefly investigate other factors, such as differences in data-normalization between synthetic and real, the impact of data augmentations, texture vs.\ shape learning, and assuming oracle prompts. While we find that some of those factors can have an impact, they are not sufficient to close the gap towards real data. Building upon our insights that mainly later layers are responsible for the drop, we investigate the data-efficiency of fine-tuning a synthetically trained model with real data applied to only those last layers. Our results suggest an improved trade-off between the amount of real training data used and the model's accuracy. Our findings contribute to the understanding of the gap between synthetic and real data and indicate solutions to mitigate the scarcity of labeled real data.
Challenging Common Assumptions in Multi-task Learning
Nov 10, 2023While multi-task learning (MTL) has gained significant attention in recent years, its underlying mechanisms remain poorly understood. Recent methods did not yield consistent performance improvements over single task learning (STL) baselines, underscoring the importance of gaining more profound insights about challenges specific to MTL. In our study, we challenge common assumptions in MTL in the context of STL: First, the choice of optimizer has only been mildly investigated in MTL. We show the pivotal role of common STL tools such as the Adam optimizer in MTL. We deduce the effectiveness of Adam to its partial loss-scale invariance. Second, the notion of gradient conflicts has often been phrased as a specific problem in MTL. We delve into the role of gradient conflicts in MTL and compare it to STL. For angular gradient alignment we find no evidence that this is a unique problem in MTL. We emphasize differences in gradient magnitude as the main distinguishing factor. Lastly, we compare the transferability of features learned through MTL and STL on common image corruptions, and find no conclusive evidence that MTL leads to superior transferability. Overall, we find surprising similarities between STL and MTL suggesting to consider methods from both fields in a broader context.
Understanding Neural Coding on Latent Manifolds by Sharing Features and Dividing Ensembles
Oct 06, 2022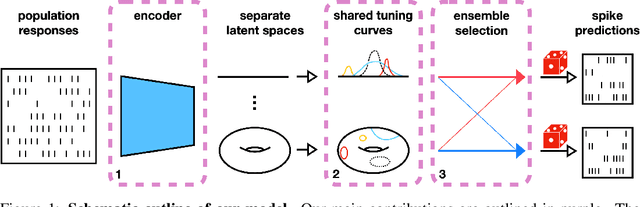
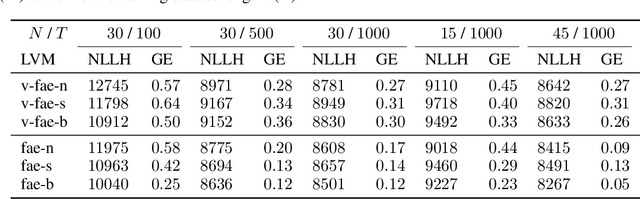
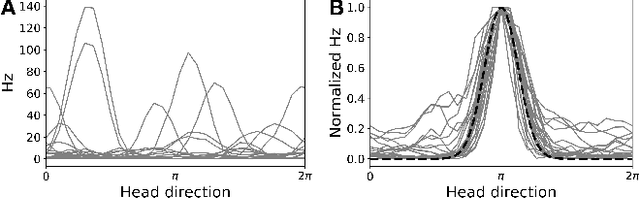
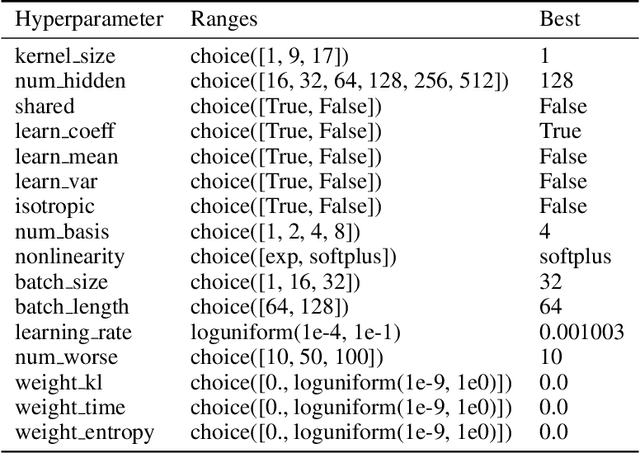
Systems neuroscience relies on two complementary views of neural data, characterized by single neuron tuning curves and analysis of population activity. These two perspectives combine elegantly in neural latent variable models that constrain the relationship between latent variables and neural activity, modeled by simple tuning curve functions. This has recently been demonstrated using Gaussian processes, with applications to realistic and topologically relevant latent manifolds. Those and previous models, however, missed crucial shared coding properties of neural populations. We propose feature sharing across neural tuning curves, which significantly improves performance and leads to better-behaved optimization. We also propose a solution to the problem of ensemble detection, whereby different groups of neurons, i.e., ensembles, can be modulated by different latent manifolds. This is achieved through a soft clustering of neurons during training, thus allowing for the separation of mixed neural populations in an unsupervised manner. These innovations lead to more interpretable models of neural population activity that train well and perform better even on mixtures of complex latent manifolds. Finally, we apply our method on a recently published grid cell dataset, recovering distinct ensembles, inferring toroidal latents and predicting neural tuning curves all in a single integrated modeling framework.
Score-Based Generative Classifiers
Oct 01, 2021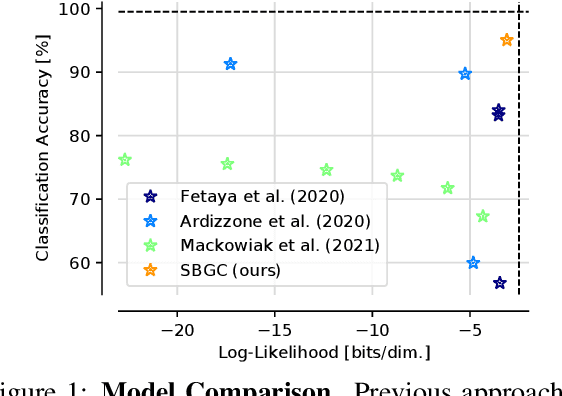
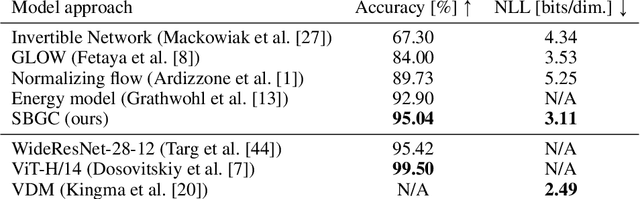

The tremendous success of generative models in recent years raises the question whether they can also be used to perform classification. Generative models have been used as adversarially robust classifiers on simple datasets such as MNIST, but this robustness has not been observed on more complex datasets like CIFAR-10. Additionally, on natural image datasets, previous results have suggested a trade-off between the likelihood of the data and classification accuracy. In this work, we investigate score-based generative models as classifiers for natural images. We show that these models not only obtain competitive likelihood values but simultaneously achieve state-of-the-art classification accuracy for generative classifiers on CIFAR-10. Nevertheless, we find that these models are only slightly, if at all, more robust than discriminative baseline models on out-of-distribution tasks based on common image corruptions. Similarly and contrary to prior results, we find that score-based are prone to worst-case distribution shifts in the form of adversarial perturbations. Our work highlights that score-based generative models are closing the gap in classification accuracy compared to standard discriminative models. While they do not yet deliver on the promise of adversarial and out-of-domain robustness, they provide a different approach to classification that warrants further research.
Visual Representation Learning Does Not Generalize Strongly Within the Same Domain
Jul 23, 2021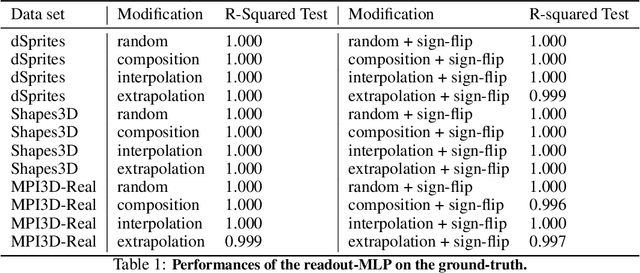



An important component for generalization in machine learning is to uncover underlying latent factors of variation as well as the mechanism through which each factor acts in the world. In this paper, we test whether 17 unsupervised, weakly supervised, and fully supervised representation learning approaches correctly infer the generative factors of variation in simple datasets (dSprites, Shapes3D, MPI3D). In contrast to prior robustness work that introduces novel factors of variation during test time, such as blur or other (un)structured noise, we here recompose, interpolate, or extrapolate only existing factors of variation from the training data set (e.g., small and medium-sized objects during training and large objects during testing). Models that learn the correct mechanism should be able to generalize to this benchmark. In total, we train and test 2000+ models and observe that all of them struggle to learn the underlying mechanism regardless of supervision signal and architectural bias. Moreover, the generalization capabilities of all tested models drop significantly as we move from artificial datasets towards more realistic real-world datasets. Despite their inability to identify the correct mechanism, the models are quite modular as their ability to infer other in-distribution factors remains fairly stable, providing only a single factor is out-of-distribution. These results point to an important yet understudied problem of learning mechanistic models of observations that can facilitate generalization.
Towards Nonlinear Disentanglement in Natural Data with Temporal Sparse Coding
Jul 21, 2020
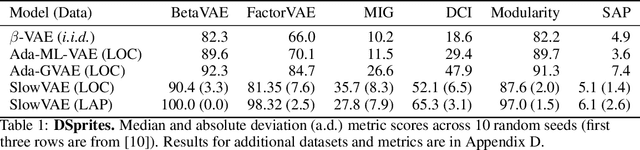
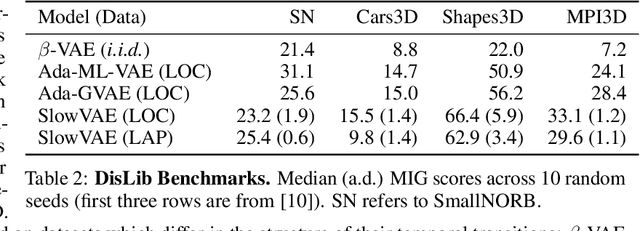
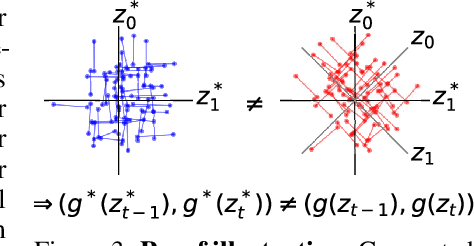
We construct an unsupervised learning model that achieves nonlinear disentanglement of underlying factors of variation in naturalistic videos. Previous work suggests that representations can be disentangled if all but a few factors in the environment stay constant at any point in time. As a result, algorithms proposed for this problem have only been tested on carefully constructed datasets with this exact property, leaving it unclear whether they will transfer to natural scenes. Here we provide evidence that objects in segmented natural movies undergo transitions that are typically small in magnitude with occasional large jumps, which is characteristic of a temporally sparse distribution. We leverage this finding and present SlowVAE, a model for unsupervised representation learning that uses a sparse prior on temporally adjacent observations to disentangle generative factors without any assumptions on the number of changing factors. We provide a proof of identifiability and show that the model reliably learns disentangled representations on several established benchmark datasets, often surpassing the current state-of-the-art. We additionally demonstrate transferability towards video datasets with natural dynamics, Natural Sprites and KITTI Masks, which we contribute as benchmarks for guiding disentanglement research towards more natural data domains.