 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Identity Perceptual Watermark Against Deepfake Face Swapping
Nov 02, 2023
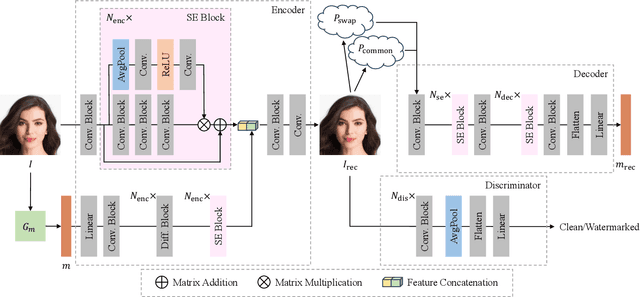
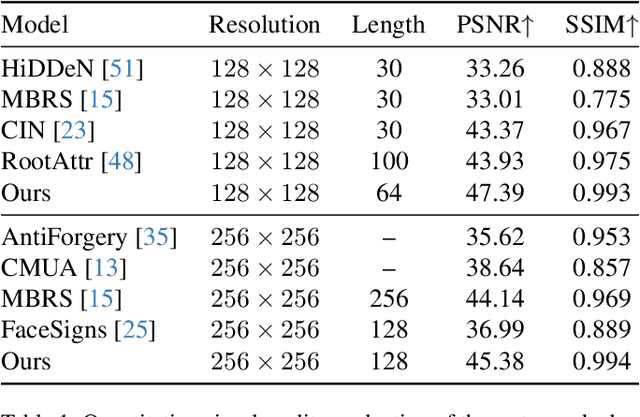

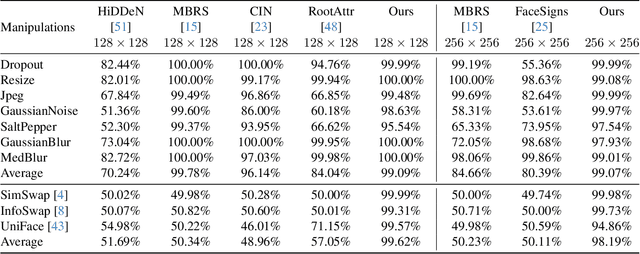
Notwithstanding offering convenience and entertainment to society, Deepfake face swapping has caused critical privacy issues with the rapid development of deep generative models. Due to imperceptible artifacts in high-quality synthetic images, passive detection models against face swapping in recent years usually suffer performance damping regarding the generalizability issue. Therefore, several studies have been attempted to proactively protect the original images against malicious manipulations by inserting invisible signals in advance. However, the existing proactive defense approaches demonstrate unsatisfactory results with respect to visual quality, detection accuracy, and source tracing ability. In this study, we propose the first robust identity perceptual watermarking framework that concurrently performs detection and source tracing against Deepfake face swapping proactively. We assign identity semantics regarding the image contents to the watermarks and devise an unpredictable and unreversible chaotic encryption system to ensure watermark confidentiality. The watermarks are encoded and recovered by jointly training an encoder-decoder framework along with adversarial image manipulations. Extensive experiments demonstrate state-of-the-art performance against Deepfake face swapping under both cross-dataset and cross-manipulation settings.
PIE: Simulating Disease Progression via Progressive Image Editing
Sep 21, 2023
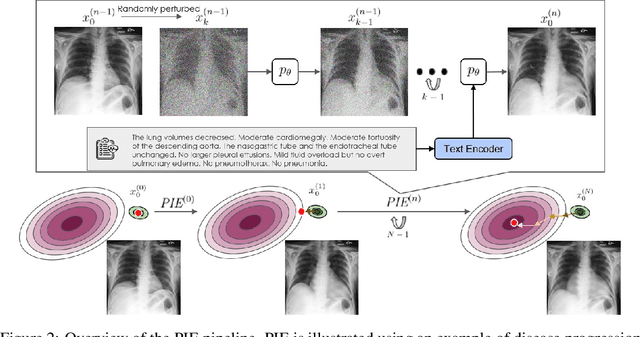
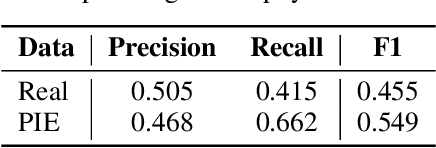
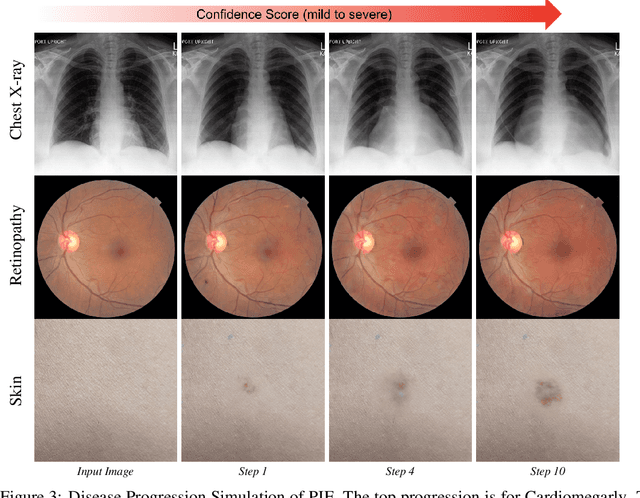
Disease progression simulation is a crucial area of research that has significant implications for clinical diagnosis, prognosis, and treatment. One major challenge in this field is the lack of continuous medical imaging monitoring of individual patients over time. To address this issue, we develop a novel framework termed Progressive Image Editing (PIE) that enables controlled manipulation of disease-related image features, facilitating precise and realistic disease progression simulation. Specifically, we leverage recent advancements in text-to-image generative models to simulate disease progression accurately and personalize it for each patient. We theoretically analyze the iterative refining process in our framework as a gradient descent with an exponentially decayed learning rate. To validate our framework, we conduct experiments in three medical imaging domains. Our results demonstrate the superiority of PIE over existing methods such as Stable Diffusion Walk and Style-Based Manifold Extrapolation based on CLIP score (Realism) and Disease Classification Confidence (Alignment). Our user study collected feedback from 35 veteran physicians to assess the generated progressions. Remarkably, 76.2% of the feedback agrees with the fidelity of the generated progressions. To our best knowledge, PIE is the first of its kind to generate disease progression images meeting real-world standards. It is a promising tool for medical research and clinical practice, potentially allowing healthcare providers to model disease trajectories over time, predict future treatment responses, and improve patient outcomes.
Retargeting video with an end-to-end framework
Nov 09, 2023Video holds significance in computer graphics applications. Because of the heterogeneous of digital devices, retargeting videos becomes an essential function to enhance user viewing experience in such applications. In the research of video retargeting, preserving the relevant visual content in videos, avoiding flicking, and processing time are the vital challenges. Extending image retargeting techniques to the video domain is challenging due to the high running time. Prior work of video retargeting mainly utilizes time-consuming preprocessing to analyze frames. Plus, being tolerant of different video content, avoiding important objects from shrinking, and the ability to play with arbitrary ratios are the limitations that need to be resolved in these systems requiring investigation. In this paper, we present an end-to-end RETVI method to retarget videos to arbitrary aspect ratios. We eliminate the computational bottleneck in the conventional approaches by designing RETVI with two modules, content feature analyzer (CFA) and adaptive deforming estimator (ADE). The extensive experiments and evaluations show that our system outperforms previous work in quality and running time. Visit our project website for more results at http://graphics.csie.ncku.edu.tw/RETVI.
Vision Encoder-Decoder Models for AI Coaching
Nov 09, 2023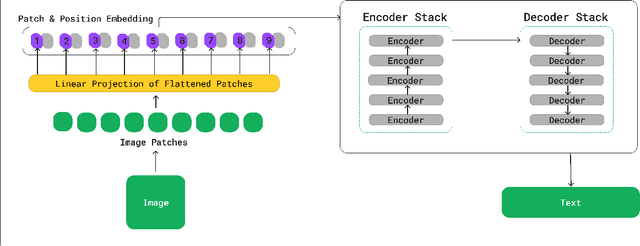
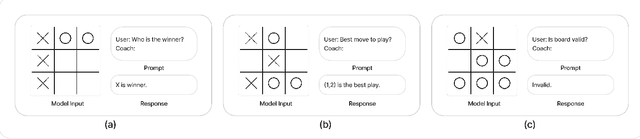
This research paper introduces an innovative AI coaching approach by integrating vision-encoder-decoder models. The feasibility of this method is demonstrated using a Vision Transformer as the encoder and GPT-2 as the decoder, achieving a seamless integration of visual input and textual interaction. Departing from conventional practices of employing distinct models for image recognition and text-based coaching, our integrated architecture directly processes input images, enabling natural question-and-answer dialogues with the AI coach. This unique strategy simplifies model architecture while enhancing the overall user experience in human-AI interactions. We showcase sample results to demonstrate the capability of the model. The results underscore the methodology's potential as a promising paradigm for creating efficient AI coach models in various domains involving visual inputs. Importantly, this potential holds true regardless of the particular visual encoder or text decoder chosen. Additionally, we conducted experiments with different sizes of GPT-2 to assess the impact on AI coach performance, providing valuable insights into the scalability and versatility of our proposed methodology.
Proceedings of the 5th International Workshop on Reading Music Systems
Nov 07, 2023The International Workshop on Reading Music Systems (WoRMS) is a workshop that tries to connect researchers who develop systems for reading music, such as in the field of Optical Music Recognition, with other researchers and practitioners that could benefit from such systems, like librarians or musicologists. The relevant topics of interest for the workshop include, but are not limited to: Music reading systems; Optical music recognition; Datasets and performance evaluation; Image processing on music scores; Writer identification; Authoring, editing, storing and presentation systems for music scores; Multi-modal systems; Novel input-methods for music to produce written music; Web-based Music Information Retrieval services; Applications and projects; Use-cases related to written music. These are the proceedings of the 5th International Workshop on Reading Music Systems, held in Milan, Italy on Nov. 4th 2023.
Large Language Models can Share Images, Too!
Oct 23, 2023This paper explores the image-sharing capability of Large Language Models (LLMs), such as InstructGPT, ChatGPT, and GPT-4, in a zero-shot setting, without the help of visual foundation models. Inspired by the two-stage process of image-sharing in human dialogues, we propose a two-stage framework that allows LLMs to predict potential image-sharing turns and generate related image descriptions using our effective restriction-based prompt template. With extensive experiments, we unlock the \textit{image-sharing} capability of LLMs in zero-shot prompting, with GPT-4 achieving the best performance. Additionally, we uncover the emergent \textit{image-sharing} ability in zero-shot prompting, demonstrating the effectiveness of restriction-based prompts in both stages of our framework. Based on this framework, we augment the PhotoChat dataset with images generated by Stable Diffusion at predicted turns, namely PhotoChat++. To our knowledge, this is the first study to assess the image-sharing ability of LLMs in a zero-shot setting without visual foundation models. The source code and the dataset will be released after publication.
Data Upcycling Knowledge Distillation for Image Super-Resolution
Sep 25, 2023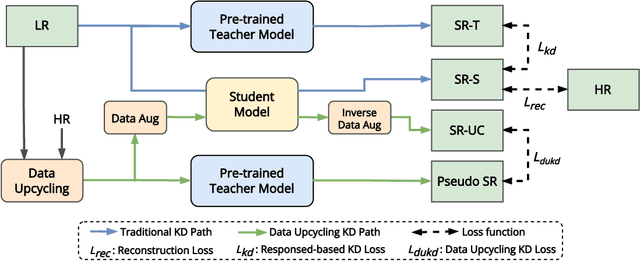
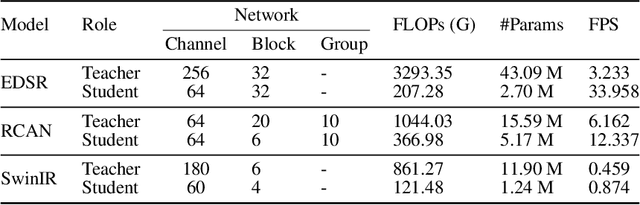
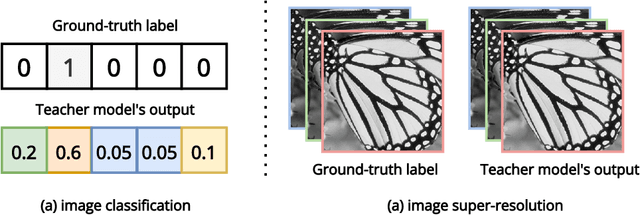
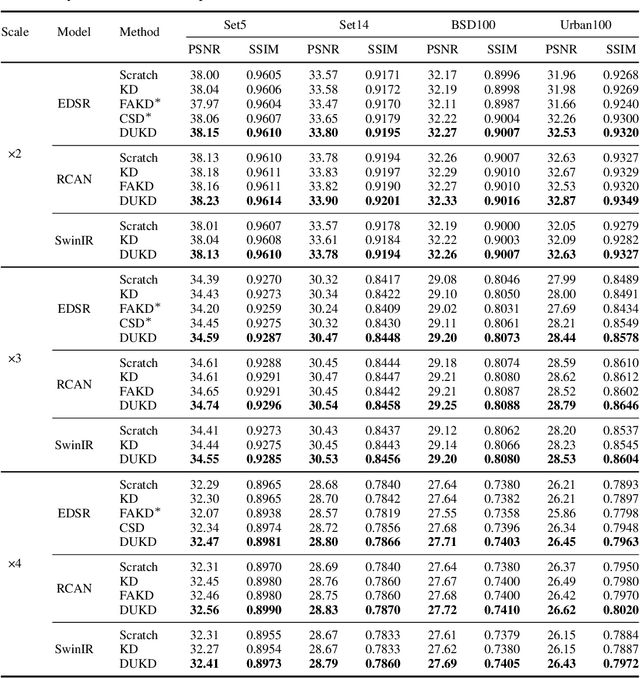
Knowledge distillation (KD) emerges as a challenging yet promising technique for compressing deep learning models, characterized by the transmission of extensive learning representations from proficient and computationally intensive teacher models to compact student models. However, only a handful of studies have endeavored to compress the models for single image super-resolution (SISR) through KD, with their effects on student model enhancement remaining marginal. In this paper, we put forth an approach from the perspective of efficient data utilization, namely, the Data Upcycling Knowledge Distillation (DUKD) which facilitates the student model by the prior knowledge teacher provided via upcycled in-domain data derived from their inputs. This upcycling process is realized through two efficient image zooming operations and invertible data augmentations which introduce the label consistency regularization to the field of KD for SISR and substantially boosts student model's generalization. The DUKD, due to its versatility, can be applied across a broad spectrum of teacher-student architectures. Comprehensive experiments across diverse benchmarks demonstrate that our proposed DUKD method significantly outperforms previous art, exemplified by an increase of up to 0.5dB in PSNR over baselines methods, and a 67% parameters reduced RCAN model's performance remaining on par with that of the RCAN teacher model.
Image Aesthetics Assessment via Learnable Queries
Sep 06, 2023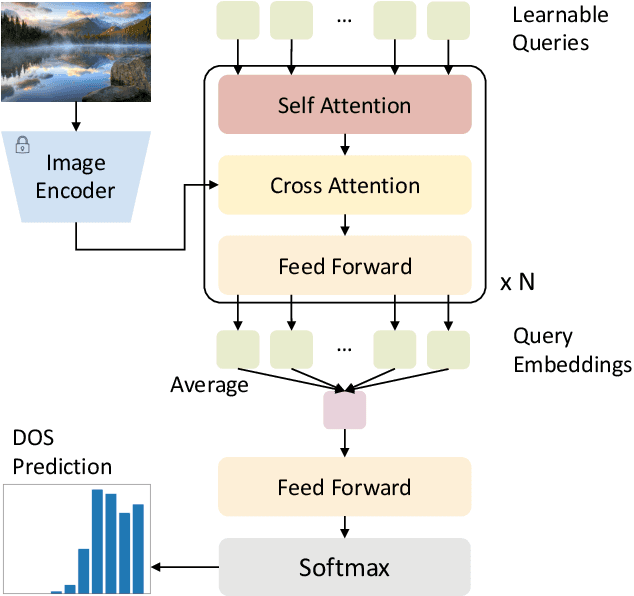
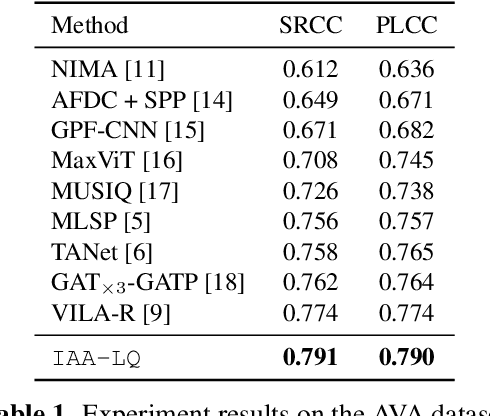
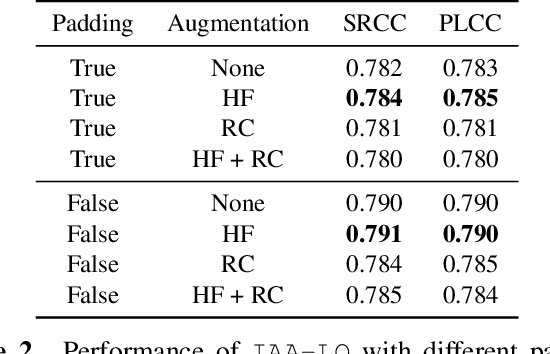

Image aesthetics assessment (IAA) aims to estimate the aesthetics of images. Depending on the content of an image, diverse criteria need to be selected to assess its aesthetics. Existing works utilize pre-trained vision backbones based on content knowledge to learn image aesthetics. However, training those backbones is time-consuming and suffers from attention dispersion. Inspired by learnable queries in vision-language alignment, we propose the Image Aesthetics Assessment via Learnable Queries (IAA-LQ) approach. It adapts learnable queries to extract aesthetic features from pre-trained image features obtained from a frozen image encoder. Extensive experiments on real-world data demonstrate the advantages of IAA-LQ, beating the best state-of-the-art method by 2.2% and 2.1% in terms of SRCC and PLCC, respectively.
Multi-level Asymmetric Contrastive Learning for Medical Image Segmentation Pre-training
Sep 21, 2023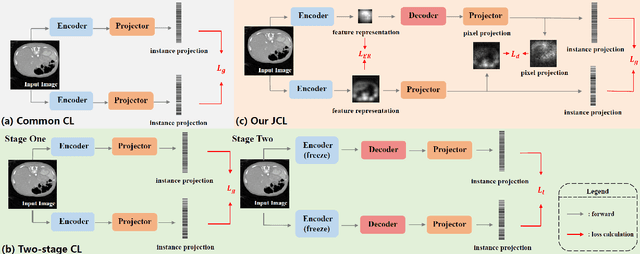
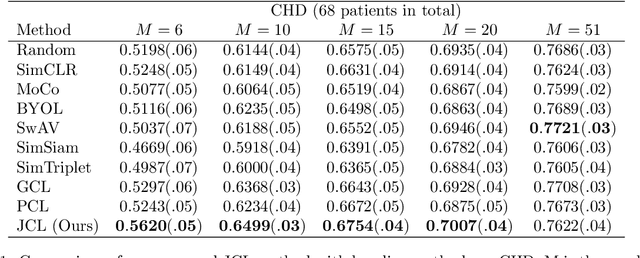
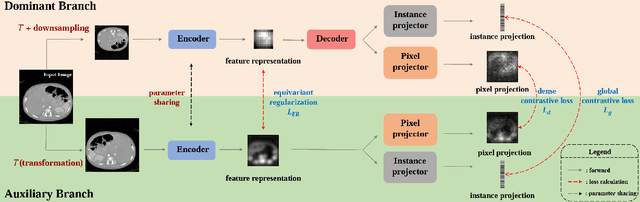
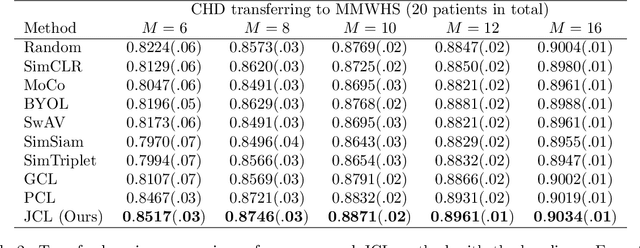
Contrastive learning, which is a powerful technique for learning image-level representations from unlabeled data, leads a promising direction to dealing with the dilemma between large-scale pre-training and limited labeled data. However, most existing contrastive learning strategies are designed mainly for downstream tasks of natural images, therefore they are sub-optimal and even worse than learning from scratch when directly applied to medical images whose downstream tasks are usually segmentation. In this work, we propose a novel asymmetric contrastive learning framework named JCL for medical image segmentation with self-supervised pre-training. Specifically, (1) A novel asymmetric contrastive learning strategy is proposed to pre-train both encoder and decoder simultaneously in one-stage to provide better initialization for segmentation models. (2) A multi-level contrastive loss is designed to take the correspondence among feature-level, image-level and pixel-level projections, respectively into account to make sure multi-level representations can be learned by the encoder and decoder during pre-training. (3) Experiments on multiple medical image datasets indicate our JCL framework outperforms existing SOTA contrastive learning strategies.
RigNet++: Efficient Repetitive Image Guided Network for Depth Completion
Sep 15, 2023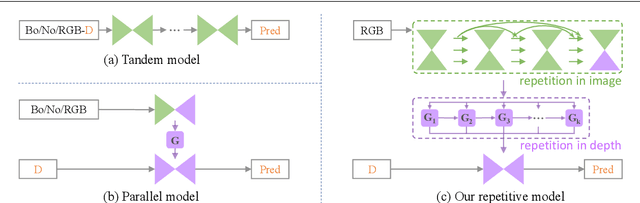
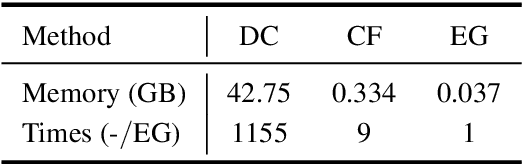
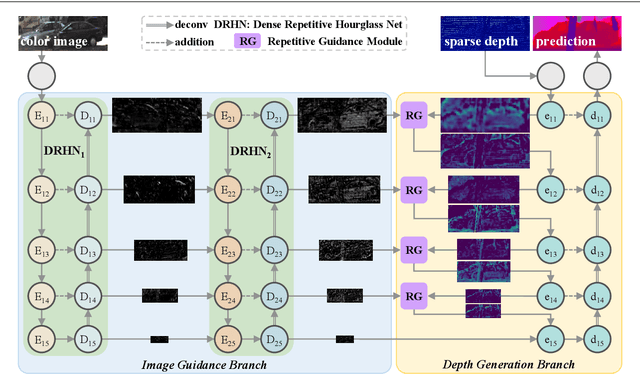

Depth completion aims to recover dense depth maps from sparse ones, where color images are often used to facilitate this task. Recent depth methods primarily focus on image guided learning frameworks. However, blurry guidance in the image and unclear structure in the depth still impede their performance. To tackle these challenges, we explore an efficient repetitive design in our image guided network to gradually and sufficiently recover depth values. Specifically, the efficient repetition is embodied in both the image guidance branch and depth generation branch. In the former branch, we design a dense repetitive hourglass network to extract discriminative image features of complex environments, which can provide powerful contextual instruction for depth prediction. In the latter branch, we introduce a repetitive guidance module based on dynamic convolution, in which an efficient convolution factorization is proposed to reduce the complexity while modeling high-frequency structures progressively. Extensive experiments indicate that our approach achieves superior or competitive results on KITTI, VKITTI, NYUv2, 3D60, and Matterport3D datasets.