 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On The Relationship Between Universal Adversarial Attacks And Sparse Representations
Nov 14, 2023
The prominent success of neural networks, mainly in computer vision tasks, is increasingly shadowed by their sensitivity to small, barely perceivable adversarial perturbations in image input. In this work, we aim at explaining this vulnerability through the framework of sparsity. We show the connection between adversarial attacks and sparse representations, with a focus on explaining the universality and transferability of adversarial examples in neural networks. To this end, we show that sparse coding algorithms, and the neural network-based learned iterative shrinkage thresholding algorithm (LISTA) among them, suffer from this sensitivity, and that common attacks on neural networks can be expressed as attacks on the sparse representation of the input image. The phenomenon that we observe holds true also when the network is agnostic to the sparse representation and dictionary, and thus can provide a possible explanation for the universality and transferability of adversarial attacks. The code is available at https://github.com/danawr/adversarial_attacks_and_sparse_representations.
SAMIHS: Adaptation of Segment Anything Model for Intracranial Hemorrhage Segmentation
Nov 14, 2023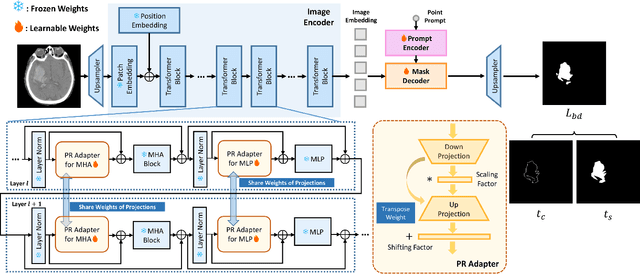
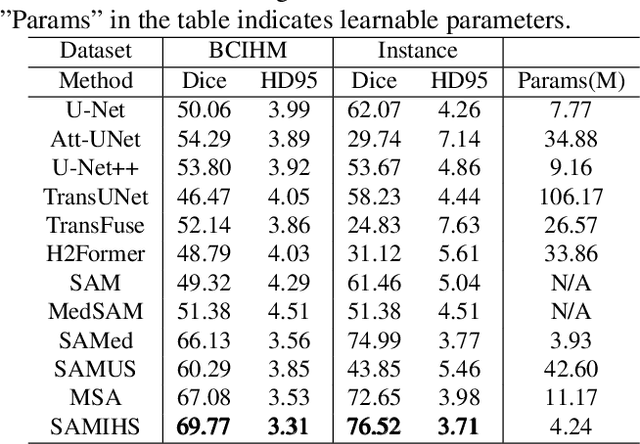
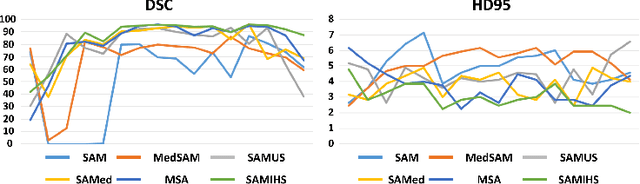
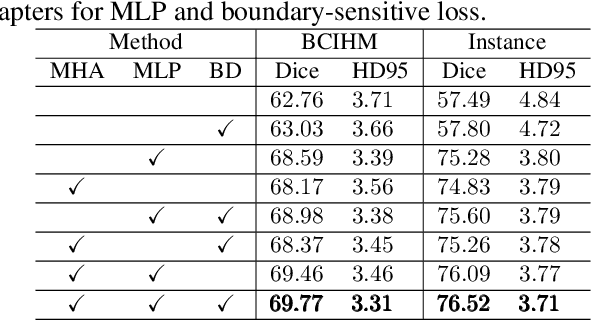
Segment Anything Model (SAM), a vision foundation model trained on large-scale annotations, has recently continued raising awareness within medical image segmentation. Despite the impressive capabilities of SAM on natural scenes, it struggles with performance decline when confronted with medical images, especially those involving blurry boundaries and highly irregular regions of low contrast. In this paper, a SAM-based parameter-efficient fine-tuning method, called SAMIHS, is proposed for intracranial hemorrhage segmentation, which is a crucial and challenging step in stroke diagnosis and surgical planning. Distinguished from previous SAM and SAM-based methods, SAMIHS incorporates parameter-refactoring adapters into SAM's image encoder and considers the efficient and flexible utilization of adapters' parameters. Additionally, we employ a combo loss that combines binary cross-entropy loss and boundary-sensitive loss to enhance SAMIHS's ability to recognize the boundary regions. Our experimental results on two public datasets demonstrate the effectiveness of our proposed method. Code is available at https://github.com/mileswyn/SAMIHS .
CrIBo: Self-Supervised Learning via Cross-Image Object-Level Bootstrapping
Oct 11, 2023Leveraging nearest neighbor retrieval for self-supervised representation learning has proven beneficial with object-centric images. However, this approach faces limitations when applied to scene-centric datasets, where multiple objects within an image are only implicitly captured in the global representation. Such global bootstrapping can lead to undesirable entanglement of object representations. Furthermore, even object-centric datasets stand to benefit from a finer-grained bootstrapping approach. In response to these challenges, we introduce a novel Cross-Image Object-Level Bootstrapping method tailored to enhance dense visual representation learning. By employing object-level nearest neighbor bootstrapping throughout the training, CrIBo emerges as a notably strong and adequate candidate for in-context learning, leveraging nearest neighbor retrieval at test time. CrIBo shows state-of-the-art performance on the latter task while being highly competitive in more standard downstream segmentation tasks. Our code and pretrained models will be publicly available upon acceptance.
One Fits All: Universal Time Series Analysis by Pretrained LM and Specially Designed Adaptors
Nov 24, 2023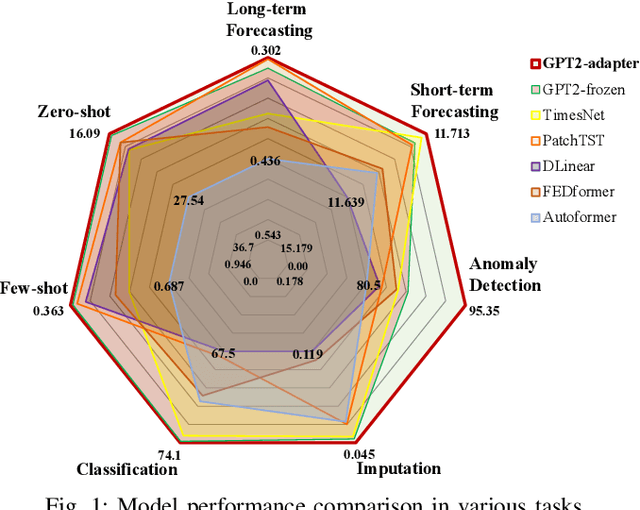
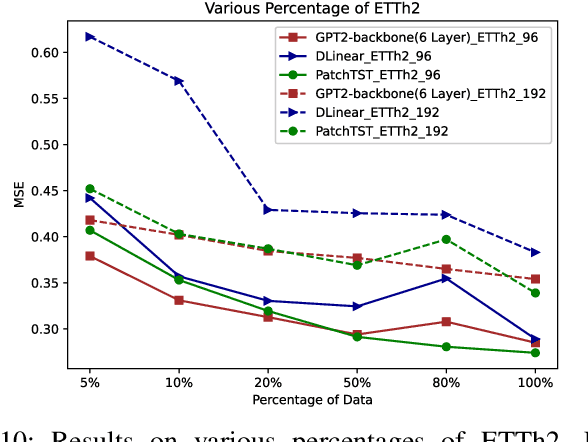
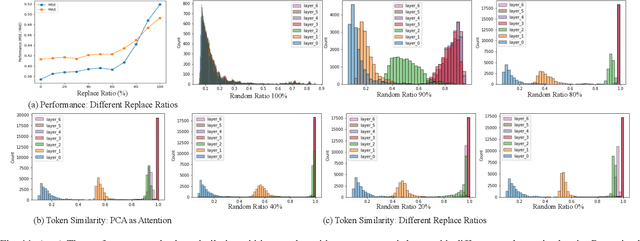
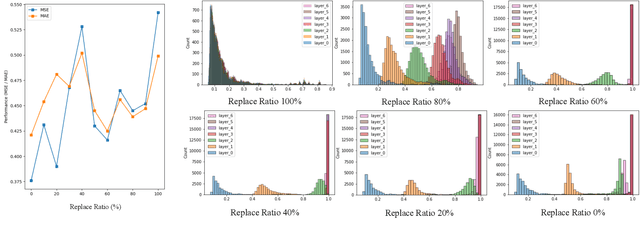
Despite the impressive achievements of pre-trained models in the fields of natural language processing (NLP) and computer vision (CV), progress in the domain of time series analysis has been limited. In contrast to NLP and CV, where a single model can handle various tasks, time series analysis still relies heavily on task-specific methods for activities such as classification, anomaly detection, forecasting, and few-shot learning. The primary obstacle to developing a pre-trained model for time series analysis is the scarcity of sufficient training data. In our research, we overcome this obstacle by utilizing pre-trained models from language or CV, which have been trained on billions of data points, and apply them to time series analysis. We assess the effectiveness of the pre-trained transformer model in two ways. Initially, we maintain the original structure of the self-attention and feedforward layers in the residual blocks of the pre-trained language or image model, using the Frozen Pre-trained Transformer (FPT) for time series analysis with the addition of projection matrices for input and output. Additionally, we introduce four unique adapters, designed specifically for downstream tasks based on the pre-trained model, including forecasting and anomaly detection. These adapters are further enhanced with efficient parameter tuning, resulting in superior performance compared to all state-of-the-art methods.Our comprehensive experimental studies reveal that (a) the simple FPT achieves top-tier performance across various time series analysis tasks; and (b) fine-tuning the FPT with the custom-designed adapters can further elevate its performance, outshining specialized task-specific models.
Deep convolutional encoder-decoder hierarchical neural networks for conjugate heat transfer surrogate modeling
Nov 24, 2023

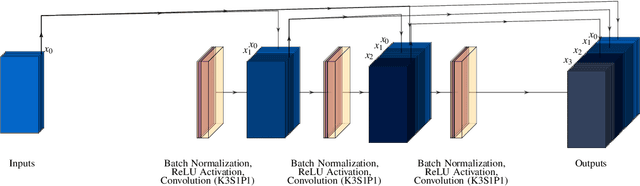
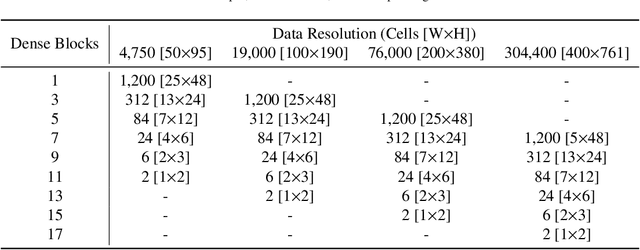
Conjugate heat transfer (CHT) models are vital for the design of many engineering systems. However, high-fidelity CHT models are computationally intensive, which limits their use in applications such as design optimization, where hundreds to thousands of model evaluations are required. In this work, we develop a modular deep convolutional encoder-decoder hierarchical (DeepEDH) neural network, a novel deep-learning-based surrogate modeling methodology for computationally intensive CHT models. Leveraging convective temperature dependencies, we propose a two-stage temperature prediction architecture that couples velocity and temperature models. The proposed DeepEDH methodology is demonstrated by modeling the pressure, velocity, and temperature fields for a liquid-cooled cold-plate-based battery thermal management system with variable channel geometry. A computational model of the cold plate is developed and solved using the finite element method (FEM), generating a dataset of 1,500 simulations. The FEM results are transformed and scaled from unstructured to structured, image-like meshes to create training and test datasets. The DeepEDH methodology's performance is examined in relation to data scaling, training dataset size, and network depth. Our performance analysis covers the impact of the novel architecture, separate field models, output geometry masks, multi-stage temperature models, and optimizations of the hyperparameters and architecture. Furthermore, we quantify the influence of the CHT thermal boundary condition on surrogate model performance, highlighting improved temperature model performance with higher heat fluxes. Compared to other deep learning neural network surrogate models, such as U-Net and DenseED, the proposed DeepEDH methodology for CHT models exhibits up to a 65% enhancement in the coefficient of determination ($R^{2}$).
HACD: Hand-Aware Conditional Diffusion for Monocular Hand-Held Object Reconstruction
Nov 23, 2023Reconstructing hand-held objects from a single RGB image without known 3D object templates, category prior, or depth information is a vital yet challenging problem in computer vision. In contrast to prior works that utilize deterministic modeling paradigms, which make it hard to account for the uncertainties introduced by hand- and self-occlusion, we employ a probabilistic point cloud denoising diffusion model to tackle the above challenge. In this work, we present Hand-Aware Conditional Diffusion for monocular hand-held object reconstruction (HACD), modeling the hand-object interaction in two aspects. First, we introduce hand-aware conditioning to model hand-object interaction from both semantic and geometric perspectives. Specifically, a unified hand-object semantic embedding compensates for the 2D local feature deficiency induced by hand occlusion, and a hand articulation embedding further encodes the relationship between object vertices and hand joints. Second, we propose a hand-constrained centroid fixing scheme, which utilizes hand vertices priors to restrict the centroid deviation of partially denoised point cloud during diffusion and reverse process. Removing the centroid bias interference allows the diffusion models to focus on the reconstruction of shape, thus enhancing the stability and precision of local feature projection. Experiments on the synthetic ObMan dataset and two real-world datasets, HO3D and MOW, demonstrate our approach surpasses all existing methods by a large margin.
Using Human Feedback to Fine-tune Diffusion Models without Any Reward Model
Nov 23, 2023Using reinforcement learning with human feedback (RLHF) has shown significant promise in fine-tuning diffusion models. Previous methods start by training a reward model that aligns with human preferences, then leverage RL techniques to fine-tune the underlying models. However, crafting an efficient reward model demands extensive datasets, optimal architecture, and manual hyperparameter tuning, making the process both time and cost-intensive. The direct preference optimization (DPO) method, effective in fine-tuning large language models, eliminates the necessity for a reward model. However, the extensive GPU memory requirement of the diffusion model's denoising process hinders the direct application of the DPO method. To address this issue, we introduce the Direct Preference for Denoising Diffusion Policy Optimization (D3PO) method to directly fine-tune diffusion models. The theoretical analysis demonstrates that although D3PO omits training a reward model, it effectively functions as the optimal reward model trained using human feedback data to guide the learning process. This approach requires no training of a reward model, proving to be more direct, cost-effective, and minimizing computational overhead. In experiments, our method uses the relative scale of objectives as a proxy for human preference, delivering comparable results to methods using ground-truth rewards. Moreover, D3PO demonstrates the ability to reduce image distortion rates and generate safer images, overcoming challenges lacking robust reward models. Our code is publicly available in https://github.com/yk7333/D3PO/tree/main.
Image Data Hiding in Neural Compressed Latent Representations
Oct 01, 2023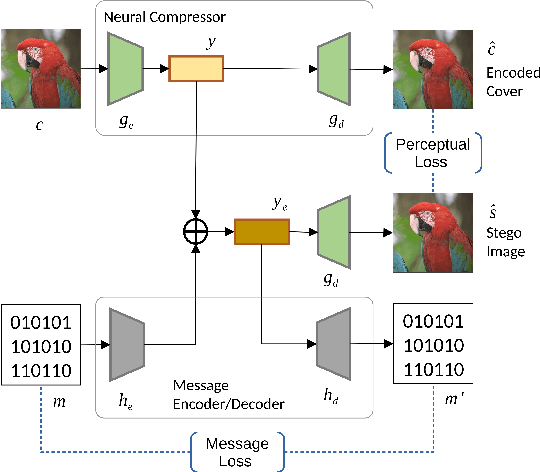
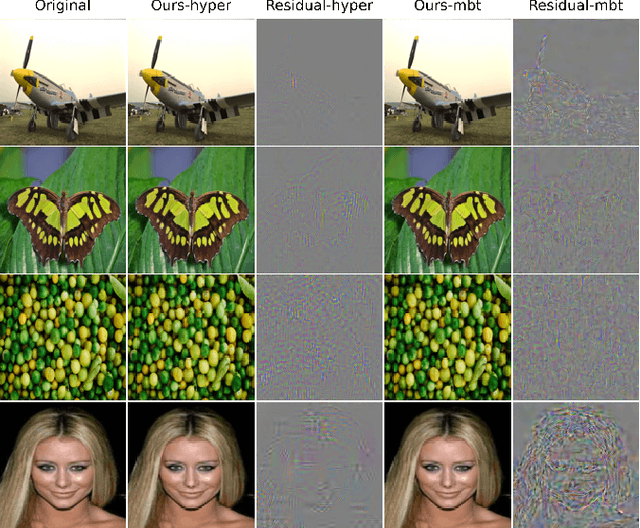

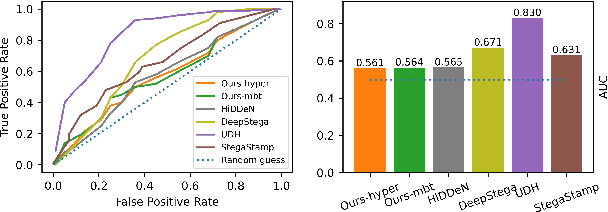
We propose an end-to-end learned image data hiding framework that embeds and extracts secrets in the latent representations of a generic neural compressor. By leveraging a perceptual loss function in conjunction with our proposed message encoder and decoder, our approach simultaneously achieves high image quality and high bit accuracy. Compared to existing techniques, our framework offers superior image secrecy and competitive watermarking robustness in the compressed domain while accelerating the embedding speed by over 50 times. These results demonstrate the potential of combining data hiding techniques and neural compression and offer new insights into developing neural compression techniques and their applications.
DeltaSpace: A Semantic-aligned Feature Space for Flexible Text-guided Image Editing
Oct 12, 2023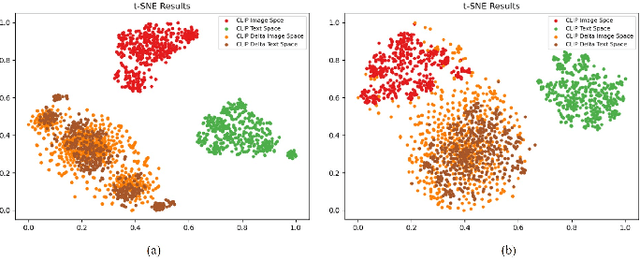
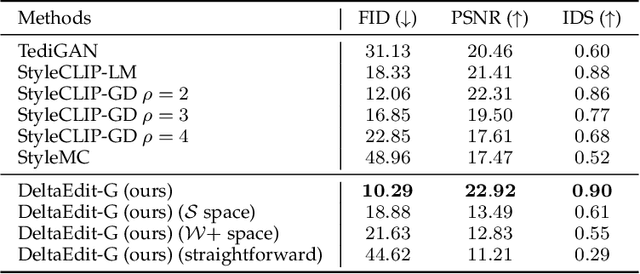


Text-guided image editing faces significant challenges to training and inference flexibility. Much literature collects large amounts of annotated image-text pairs to train text-conditioned generative models from scratch, which is expensive and not efficient. After that, some approaches that leverage pre-trained vision-language models are put forward to avoid data collection, but they are also limited by either per text-prompt optimization or inference-time hyper-parameters tuning. To address these issues, we investigate and identify a specific space, referred to as CLIP DeltaSpace, where the CLIP visual feature difference of two images is semantically aligned with the CLIP textual feature difference of their corresponding text descriptions. Based on DeltaSpace, we propose a novel framework called DeltaEdit, which maps the CLIP visual feature differences to the latent space directions of a generative model during the training phase, and predicts the latent space directions from the CLIP textual feature differences during the inference phase. And this design endows DeltaEdit with two advantages: (1) text-free training; (2) generalization to various text prompts for zero-shot inference. Extensive experiments validate the effectiveness and versatility of DeltaEdit with different generative models, including both the GAN model and the diffusion model, in achieving flexible text-guided image editing. Code is available at https://github.com/Yueming6568/DeltaEdit.
JointNet: Extending Text-to-Image Diffusion for Dense Distribution Modeling
Oct 10, 2023We introduce JointNet, a novel neural network architecture for modeling the joint distribution of images and an additional dense modality (e.g., depth maps). JointNet is extended from a pre-trained text-to-image diffusion model, where a copy of the original network is created for the new dense modality branch and is densely connected with the RGB branch. The RGB branch is locked during network fine-tuning, which enables efficient learning of the new modality distribution while maintaining the strong generalization ability of the large-scale pre-trained diffusion model. We demonstrate the effectiveness of JointNet by using RGBD diffusion as an example and through extensive experiments, showcasing its applicability in a variety of applications, including joint RGBD generation, dense depth prediction, depth-conditioned image generation, and coherent tile-based 3D panorama generation.