 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResults of the NeurIPS 2023 Neural MMO Competition on Multi-task Reinforcement Learning
Aug 17, 2025We present the results of the NeurIPS 2023 Neural MMO Competition, which attracted over 200 participants and submissions. Participants trained goal-conditional policies that generalize to tasks, maps, and opponents never seen during training. The top solution achieved a score 4x higher than our baseline within 8 hours of training on a single 4090 GPU. We open-source everything relating to Neural MMO and the competition under the MIT license, including the policy weights and training code for our baseline and for the top submissions.
Using Human Feedback to Fine-tune Diffusion Models without Any Reward Model
Nov 23, 2023



Using reinforcement learning with human feedback (RLHF) has shown significant promise in fine-tuning diffusion models. Previous methods start by training a reward model that aligns with human preferences, then leverage RL techniques to fine-tune the underlying models. However, crafting an efficient reward model demands extensive datasets, optimal architecture, and manual hyperparameter tuning, making the process both time and cost-intensive. The direct preference optimization (DPO) method, effective in fine-tuning large language models, eliminates the necessity for a reward model. However, the extensive GPU memory requirement of the diffusion model's denoising process hinders the direct application of the DPO method. To address this issue, we introduce the Direct Preference for Denoising Diffusion Policy Optimization (D3PO) method to directly fine-tune diffusion models. The theoretical analysis demonstrates that although D3PO omits training a reward model, it effectively functions as the optimal reward model trained using human feedback data to guide the learning process. This approach requires no training of a reward model, proving to be more direct, cost-effective, and minimizing computational overhead. In experiments, our method uses the relative scale of objectives as a proxy for human preference, delivering comparable results to methods using ground-truth rewards. Moreover, D3PO demonstrates the ability to reduce image distortion rates and generate safer images, overcoming challenges lacking robust reward models. Our code is publicly available in https://github.com/yk7333/D3PO/tree/main.
Neural MMO 2.0: A Massively Multi-task Addition to Massively Multi-agent Learning
Nov 07, 2023

Neural MMO 2.0 is a massively multi-agent environment for reinforcement learning research. The key feature of this new version is a flexible task system that allows users to define a broad range of objectives and reward signals. We challenge researchers to train agents capable of generalizing to tasks, maps, and opponents never seen during training. Neural MMO features procedurally generated maps with 128 agents in the standard setting and support for up to. Version 2.0 is a complete rewrite of its predecessor with three-fold improved performance and compatibility with CleanRL. We release the platform as free and open-source software with comprehensive documentation available at neuralmmo.github.io and an active community Discord. To spark initial research on this new platform, we are concurrently running a competition at NeurIPS 2023.
The NeurIPS 2022 Neural MMO Challenge: A Massively Multiagent Competition with Specialization and Trade
Nov 07, 2023



In this paper, we present the results of the NeurIPS-2022 Neural MMO Challenge, which attracted 500 participants and received over 1,600 submissions. Like the previous IJCAI-2022 Neural MMO Challenge, it involved agents from 16 populations surviving in procedurally generated worlds by collecting resources and defeating opponents. This year's competition runs on the latest v1.6 Neural MMO, which introduces new equipment, combat, trading, and a better scoring system. These elements combine to pose additional robustness and generalization challenges not present in previous competitions. This paper summarizes the design and results of the challenge, explores the potential of this environment as a benchmark for learning methods, and presents some practical reinforcement learning training approaches for complex tasks with sparse rewards. Additionally, we have open-sourced our baselines, including environment wrappers, benchmarks, and visualization tools for future research.
Benchmarking Robustness and Generalization in Multi-Agent Systems: A Case Study on Neural MMO
Aug 30, 2023

We present the results of the second Neural MMO challenge, hosted at IJCAI 2022, which received 1600+ submissions. This competition targets robustness and generalization in multi-agent systems: participants train teams of agents to complete a multi-task objective against opponents not seen during training. The competition combines relatively complex environment design with large numbers of agents in the environment. The top submissions demonstrate strong success on this task using mostly standard reinforcement learning (RL) methods combined with domain-specific engineering. We summarize the competition design and results and suggest that, as an academic community, competitions may be a powerful approach to solving hard problems and establishing a solid benchmark for algorithms. We will open-source our benchmark including the environment wrapper, baselines, a visualization tool, and selected policies for further research.
Emergent collective intelligence from massive-agent cooperation and competition
Jan 05, 2023



Inspired by organisms evolving through cooperation and competition between different populations on Earth, we study the emergence of artificial collective intelligence through massive-agent reinforcement learning. To this end, We propose a new massive-agent reinforcement learning environment, Lux, where dynamic and massive agents in two teams scramble for limited resources and fight off the darkness. In Lux, we build our agents through the standard reinforcement learning algorithm in curriculum learning phases and leverage centralized control via a pixel-to-pixel policy network. As agents co-evolve through self-play, we observe several stages of intelligence, from the acquisition of atomic skills to the development of group strategies. Since these learned group strategies arise from individual decisions without an explicit coordination mechanism, we claim that artificial collective intelligence emerges from massive-agent cooperation and competition. We further analyze the emergence of various learned strategies through metrics and ablation studies, aiming to provide insights for reinforcement learning implementations in massive-agent environments.
Multi-Agent Path Finding via Tree LSTM
Oct 24, 2022



In recent years, Multi-Agent Path Finding (MAPF) has attracted attention from the fields of both Operations Research (OR) and Reinforcement Learning (RL). However, in the 2021 Flatland3 Challenge, a competition on MAPF, the best RL method scored only 27.9, far less than the best OR method. This paper proposes a new RL solution to Flatland3 Challenge, which scores 125.3, several times higher than the best RL solution before. We creatively apply a novel network architecture, TreeLSTM, to MAPF in our solution. Together with several other RL techniques, including reward shaping, multiple-phase training, and centralized control, our solution is comparable to the top 2-3 OR methods.
A Multi-UAV System for Exploration and Target Finding in Cluttered and GPS-Denied Environments
Jul 19, 2021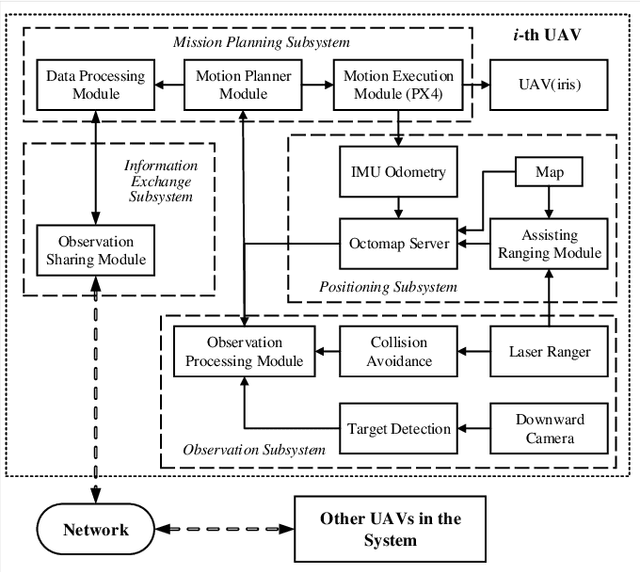
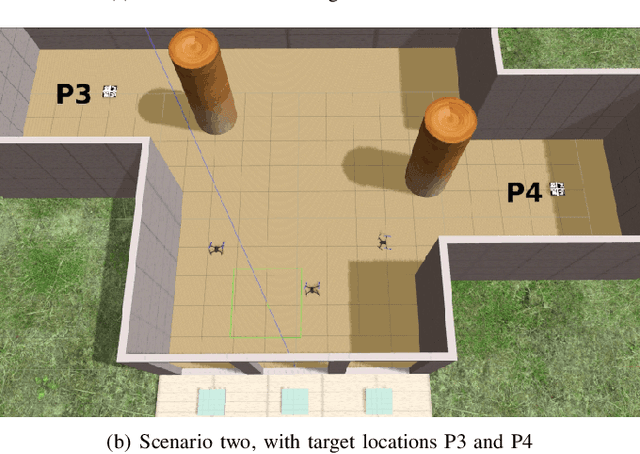
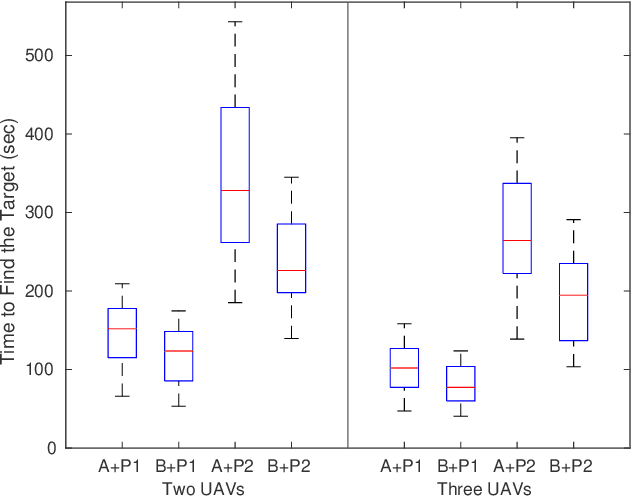
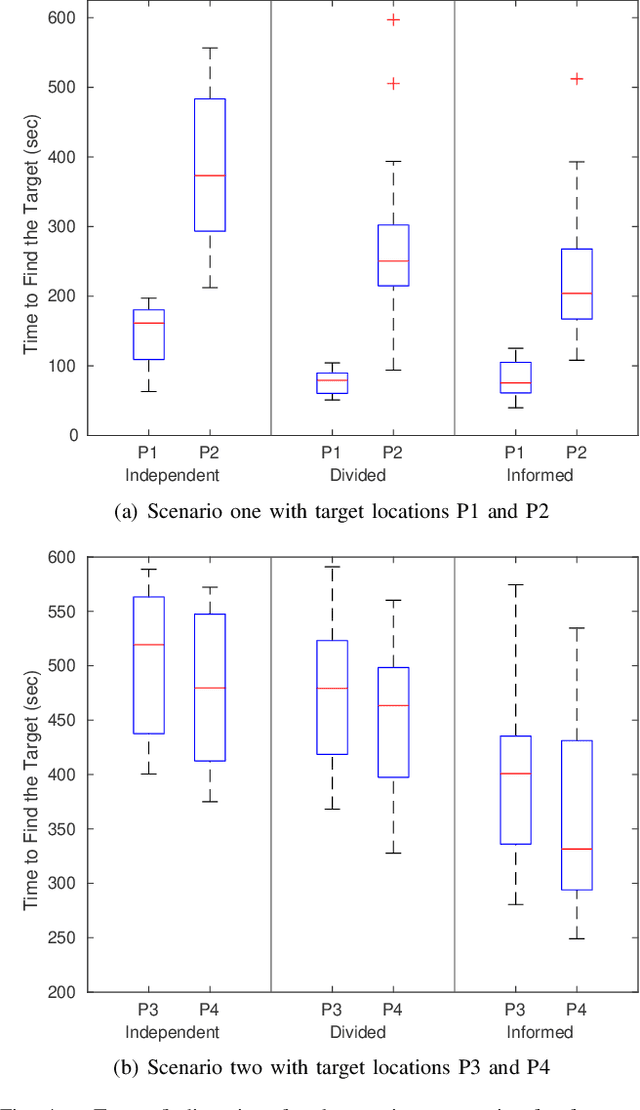
The use of multi-rotor Unmanned Aerial Vehicles (UAVs) for search and rescue as well as remote sensing is rapidly increasing. Multi-rotor UAVs, however, have limited endurance. The range of UAV applications can be widened if teams of multiple UAVs are used. We propose a framework for a team of UAVs to cooperatively explore and find a target in complex GPS-denied environments with obstacles. The team of UAVs autonomously navigates, explores, detects, and finds the target in a cluttered environment with a known map. Examples of such environments include indoor scenarios, urban or natural canyons, caves, and tunnels, where the GPS signal is limited or blocked. The framework is based on a probabilistic decentralised Partially Observable Markov Decision Process which accounts for the uncertainties in sensing and the environment. The team can cooperate efficiently, with each UAV sharing only limited processed observations and their locations during the mission. The system is simulated using the Robotic Operating System and Gazebo. Performance of the system with an increasing number of UAVs in several indoor scenarios with obstacles is tested. Results indicate that the proposed multi-UAV system has improvements in terms of time-cost, the proportion of search area surveyed, as well as successful rates for search and rescue missions.