 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Large Language and Vision-Language Models for Robust Out-of-Distribution Detection
Jan 09, 2025Out-of-distribution (OOD) detection has seen significant advancements with zero-shot approaches by leveraging the powerful Vision-Language Models (VLMs) such as CLIP. However, prior research works have predominantly focused on enhancing Far-OOD performance, while potentially compromising Near-OOD efficacy, as observed from our pilot study. To address this issue, we propose a novel strategy to enhance zero-shot OOD detection performances for both Far-OOD and Near-OOD scenarios by innovatively harnessing Large Language Models (LLMs) and VLMs. Our approach first exploit an LLM to generate superclasses of the ID labels and their corresponding background descriptions followed by feature extraction using CLIP. We then isolate the core semantic features for ID data by subtracting background features from the superclass features. The refined representation facilitates the selection of more appropriate negative labels for OOD data from a comprehensive candidate label set of WordNet, thereby enhancing the performance of zero-shot OOD detection in both scenarios. Furthermore, we introduce novel few-shot prompt tuning and visual prompt tuning to adapt the proposed framework to better align with the target distribution. Experimental results demonstrate that the proposed approach consistently outperforms current state-of-the-art methods across multiple benchmarks, with an improvement of up to 2.9% in AUROC and a reduction of up to 12.6% in FPR95. Additionally, our method exhibits superior robustness against covariate shift across different domains, further highlighting its effectiveness in real-world scenarios.
A Study of Secure Algorithms for Vertical Federated Learning: Take Secure Logistic Regression as an Example
Oct 30, 2024After entering the era of big data, more and more companies build services with machine learning techniques. However, it is costly for companies to collect data and extract helpful handcraft features on their own. Although it is a way to combine with other companies' data for boosting the model's performance, this approach may be prohibited by laws. In other words, finding the balance between sharing data with others and keeping data from privacy leakage is a crucial topic worthy of close attention. This paper focuses on distributed data and conducts secure model training tasks on a vertical federated learning scheme. Here, secure implies that the whole process is executed in the encrypted domain. Therefore, the privacy concern is released.
A Machine Learning-Based Secure Face Verification Scheme and Its Applications to Digital Surveillance
Oct 29, 2024



Face verification is a well-known image analysis application and is widely used to recognize individuals in contemporary society. However, most real-world recognition systems ignore the importance of protecting the identity-sensitive facial images that are used for verification. To address this problem, we investigate how to implement a secure face verification system that protects the facial images from being imitated. In our work, we use the DeepID2 convolutional neural network to extract the features of a facial image and an EM algorithm to solve the facial verification problem. To maintain the privacy of facial images, we apply homomorphic encryption schemes to encrypt the facial data and compute the EM algorithm in the ciphertext domain. We develop three face verification systems for surveillance (or entrance) control of a local community based on three levels of privacy concerns. The associated timing performances are presented to demonstrate their feasibility for practical implementation.
SLIC: Secure Learned Image Codec through Compressed Domain Watermarking to Defend Image Manipulation
Oct 19, 2024



The digital image manipulation and advancements in Generative AI, such as Deepfake, has raised significant concerns regarding the authenticity of images shared on social media. Traditional image forensic techniques, while helpful, are often passive and insufficient against sophisticated tampering methods. This paper introduces the Secure Learned Image Codec (SLIC), a novel active approach to ensuring image authenticity through watermark embedding in the compressed domain. SLIC leverages neural network-based compression to embed watermarks as adversarial perturbations in the latent space, creating images that degrade in quality upon re-compression if tampered with. This degradation acts as a defense mechanism against unauthorized modifications. Our method involves fine-tuning a neural encoder/decoder to balance watermark invisibility with robustness, ensuring minimal quality loss for non-watermarked images. Experimental results demonstrate SLIC's effectiveness in generating visible artifacts in tampered images, thereby preventing their redistribution. This work represents a significant step toward developing secure image codecs that can be widely adopted to safeguard digital image integrity.
Exploring Compressed Image Representation as a Perceptual Proxy: A Study
Jan 14, 2024We propose an end-to-end learned image compression codec wherein the analysis transform is jointly trained with an object classification task. This study affirms that the compressed latent representation can predict human perceptual distance judgments with an accuracy comparable to a custom-tailored DNN-based quality metric. We further investigate various neural encoders and demonstrate the effectiveness of employing the analysis transform as a perceptual loss network for image tasks beyond quality judgments. Our experiments show that the off-the-shelf neural encoder proves proficient in perceptual modeling without needing an additional VGG network. We expect this research to serve as a valuable reference developing of a semantic-aware and coding-efficient neural encoder.
Image Data Hiding in Neural Compressed Latent Representations
Oct 01, 2023



We propose an end-to-end learned image data hiding framework that embeds and extracts secrets in the latent representations of a generic neural compressor. By leveraging a perceptual loss function in conjunction with our proposed message encoder and decoder, our approach simultaneously achieves high image quality and high bit accuracy. Compared to existing techniques, our framework offers superior image secrecy and competitive watermarking robustness in the compressed domain while accelerating the embedding speed by over 50 times. These results demonstrate the potential of combining data hiding techniques and neural compression and offer new insights into developing neural compression techniques and their applications.
CPIPS: Learning to Preserve Perceptual Distances in End-to-End Image Compression
Oct 01, 2023



Lossy image coding standards such as JPEG and MPEG have successfully achieved high compression rates for human consumption of multimedia data. However, with the increasing prevalence of IoT devices, drones, and self-driving cars, machines rather than humans are processing a greater portion of captured visual content. Consequently, it is crucial to pursue an efficient compressed representation that caters not only to human vision but also to image processing and machine vision tasks. Drawing inspiration from the efficient coding hypothesis in biological systems and the modeling of the sensory cortex in neural science, we repurpose the compressed latent representation to prioritize semantic relevance while preserving perceptual distance. Our proposed method, Compressed Perceptual Image Patch Similarity (CPIPS), can be derived at a minimal cost from a learned neural codec and computed significantly faster than DNN-based perceptual metrics such as LPIPS and DISTS.
Multi-task deep CNN model for no-reference image quality assessment on smartphone camera photos
Aug 27, 2020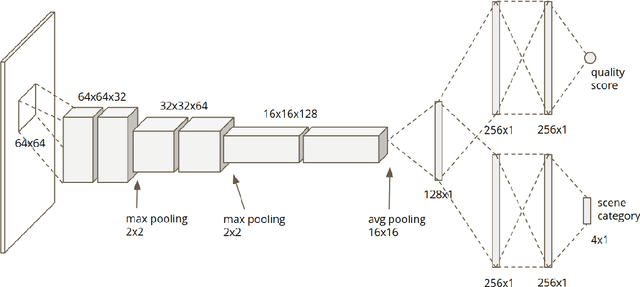
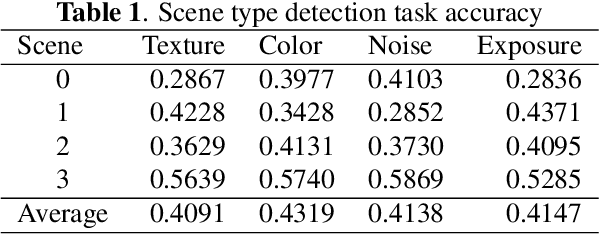
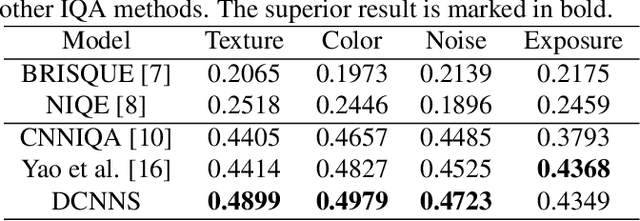
Smartphone is the most successful consumer electronic product in today's mobile social network era. The smartphone camera quality and its image post-processing capability is the dominant factor that impacts consumer's buying decision. However, the quality evaluation of photos taken from smartphones remains a labor-intensive work and relies on professional photographers and experts. As an extension of the prior CNN-based NR-IQA approach, we propose a multi-task deep CNN model with scene type detection as an auxiliary task. With the shared model parameters in the convolution layer, the learned feature maps could become more scene-relevant and enhance the performance. The evaluation result shows improved SROCC performance compared to traditional NR-IQA methods and single task CNN-based models.
k-Same-Siamese-GAN: k-Same Algorithm with Generative Adversarial Network for Facial Image De-identification with Hyperparameter Tuning and Mixed Precision Training
Mar 27, 2019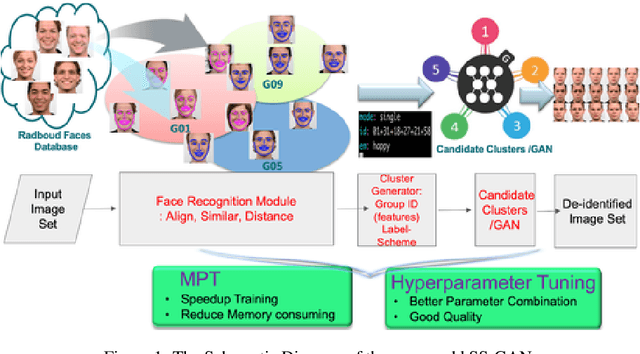

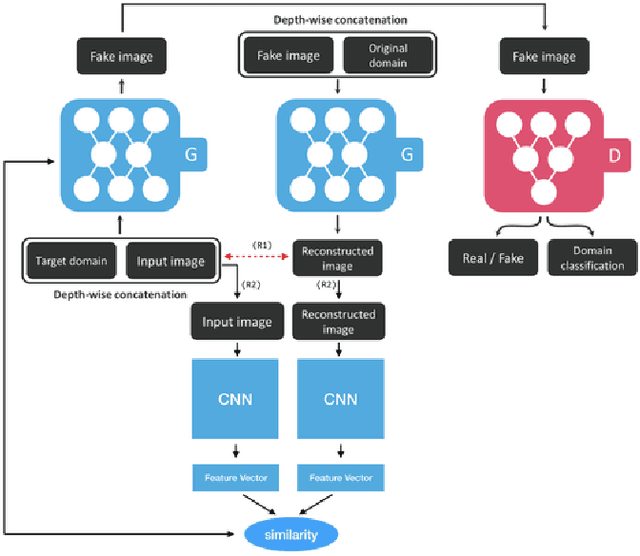

In recent years, advances in camera and computing hardware have made it easy to capture and store amounts of image and video data. Consider a data holder, such as a hospital or a government entity, who has a privately held collection of personal data. Then, how can we ensure that the data holder does conceal the identity of each individual in the imagery of personal data while still preserving certain useful aspects of the data after de-identification? In this work, we proposed a novel approach towards high-resolution facial image de-identification, called k-Same-Siamese-GAN (kSS-GAN), which leverages k-Same-Anonymity mechanism, Generative Adversarial Network (GAN), and hyperparameter tuning. To speed up training and reduce memory consumption, the mixed precision training (MPT) technique is also applied to make kSS-GAN provide guarantees regarding privacy protection on close-form identities and be trained much more efficiently as well. Finally, we dedicated our system to an actual dataset: RafD dataset for performance testing. Besides protecting privacy of high resolution of facial images, the proposed system is also justified for its ability in automating parameter tuning and breaking through the limitation of the number of adjustable parameters.