 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Disentangling Pose from Appearance in Monochrome Hand Images
Apr 16, 2019
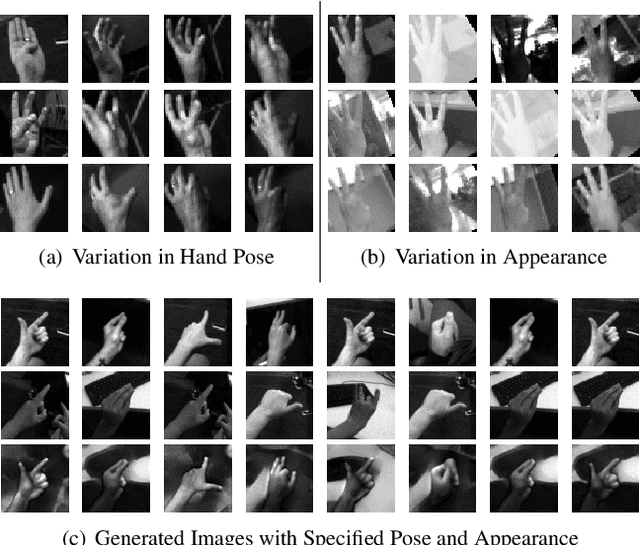

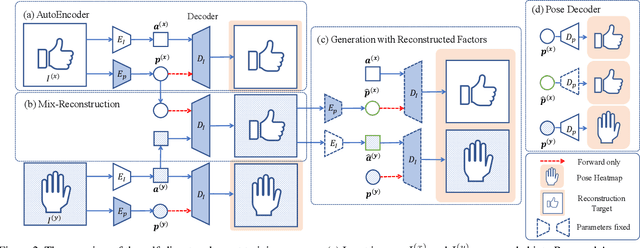

Hand pose estimation from the monocular 2D image is challenging due to the variation in lighting, appearance, and background. While some success has been achieved using deep neural networks, they typically require collecting a large dataset that adequately samples all the axes of variation of hand images. It would, therefore, be useful to find a representation of hand pose which is independent of the image appearance~(like hand texture, lighting, background), so that we can synthesize unseen images by mixing pose-appearance combinations. In this paper, we present a novel technique that disentangles the representation of pose from a complementary appearance factor in 2D monochrome images. We supervise this disentanglement process using a network that learns to generate images of hand using specified pose+appearance features. Unlike previous work, we do not require image pairs with a matching pose; instead, we use the pose annotations already available and introduce a novel use of cycle consistency to ensure orthogonality between the factors. Experimental results show that our self-disentanglement scheme successfully decomposes the hand image into the pose and its complementary appearance features of comparable quality as the method using paired data. Additionally, training the model with extra synthesized images with unseen hand-appearance combinations by re-mixing pose and appearance factors from different images can improve the 2D pose estimation performance.
Learn to Scale: Generating Multipolar Normalized Density Maps for Crowd Counting
Aug 08, 2019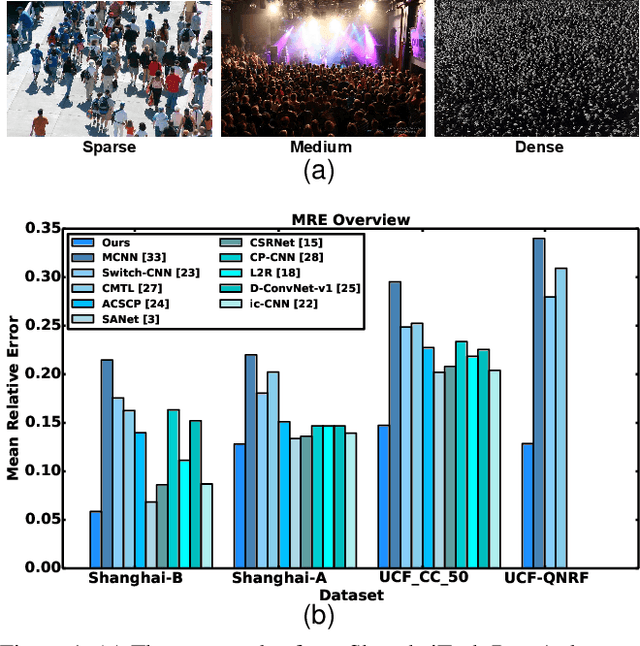
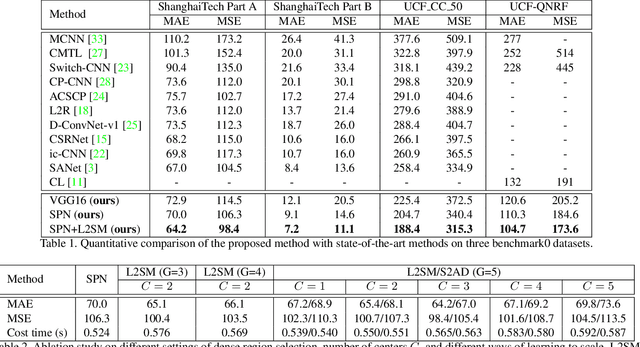

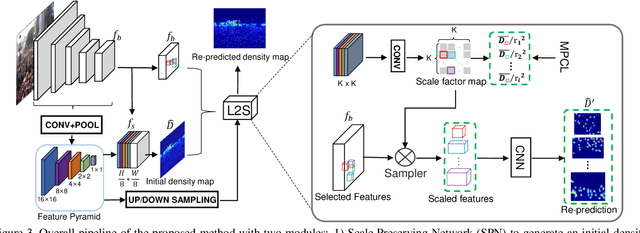
Dense crowd counting aims to predict thousands of human instances from an image, by calculating integrals of a density map over image pixels. Existing approaches mainly suffer from the extreme density variances. Such density pattern shift poses challenges even for multi-scale model ensembling. In this paper, we propose a simple yet effective approach to tackle this problem. First, a patch-level density map is extracted by a density estimation model and further grouped into several density levels which are determined over full datasets. Second, each patch density map is automatically normalized by an online center learning strategy with a multipolar center loss. Such a design can significantly condense the density distribution into several clusters, and enable that the density variance can be learned by a single model. Extensive experiments demonstrate the superiority of the proposed method. Our work outperforms the state-of-the-art by 4.2%, 14.3%, 27.1% and 20.1% in MAE, on ShanghaiTech Part A, ShanghaiTech Part B, UCF_CC_50 and UCF-QNRF datasets, respectively.
Wavelet Based Image Coding Schemes : A Recent Survey
Sep 12, 2012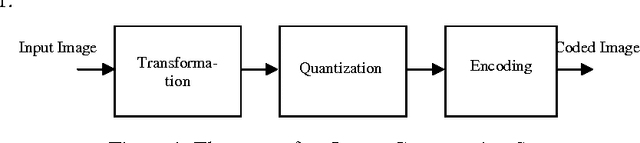
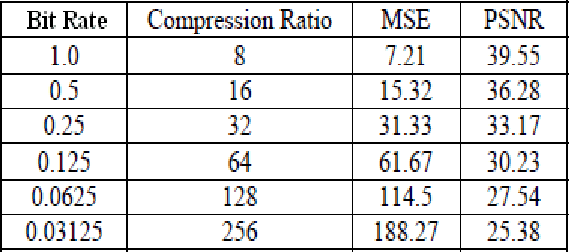
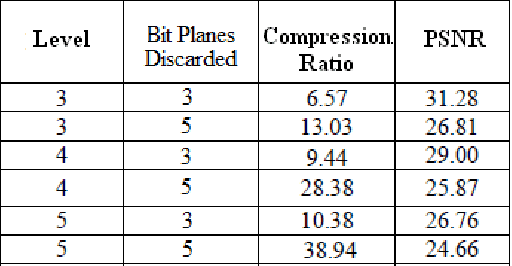
A variety of new and powerful algorithms have been developed for image compression over the years. Among them the wavelet-based image compression schemes have gained much popularity due to their overlapping nature which reduces the blocking artifacts that are common phenomena in JPEG compression and multiresolution character which leads to superior energy compaction with high quality reconstructed images. This paper provides a detailed survey on some of the popular wavelet coding techniques such as the Embedded Zerotree Wavelet (EZW) coding, Set Partitioning in Hierarchical Tree (SPIHT) coding, the Set Partitioned Embedded Block (SPECK) Coder, and the Embedded Block Coding with Optimized Truncation (EBCOT) algorithm. Other wavelet-based coding techniques like the Wavelet Difference Reduction (WDR) and the Adaptive Scanned Wavelet Difference Reduction (ASWDR) algorithms, the Space Frequency Quantization (SFQ) algorithm, the Embedded Predictive Wavelet Image Coder (EPWIC), Compression with Reversible Embedded Wavelet (CREW), the Stack-Run (SR) coding and the recent Geometric Wavelet (GW) coding are also discussed. Based on the review, recommendations and discussions are presented for algorithm development and implementation.
* 18 pages, 7 figures, journal
A sparsity augmented probabilistic collaborative representation based classification method
Dec 27, 2019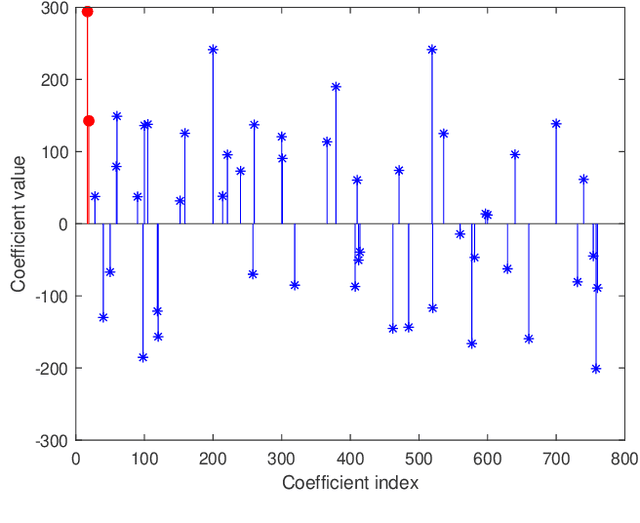
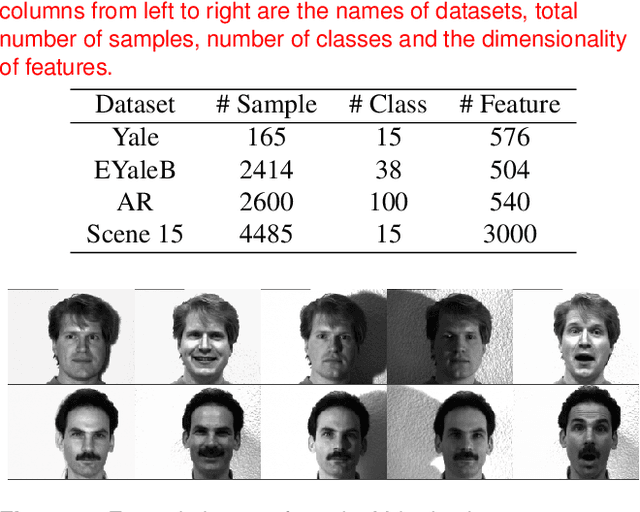
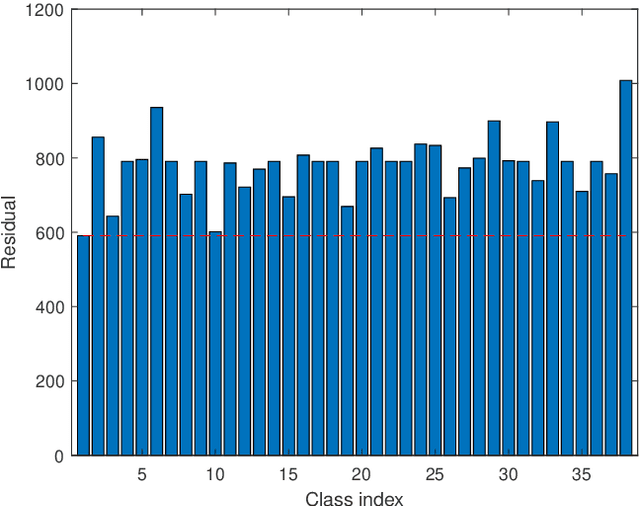
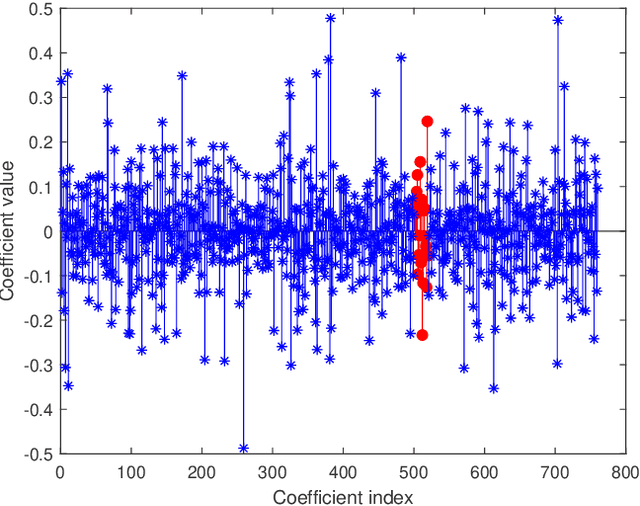
In order to enhance the performance of image recognition, a sparsity augmented probabilistic collaborative representation based classification (SA-ProCRC) method is presented. The proposed method obtains the dense coefficient through ProCRC, then augments the dense coefficient with a sparse one, and the sparse coefficient is attained by the orthogonal matching pursuit (OMP) algorithm. In contrast to conventional methods which require explicit computation of the reconstruction residuals for each class, the proposed method employs the augmented coefficient and the label matrix of the training samples to classify the test sample. Experimental results indicate that the proposed method can achieve promising results for face and scene images. The source code of our proposed SA-ProCRC is accessible at https://github.com/yinhefeng/SAProCRC.
A Multimodal Deep Network for the Reconstruction of T2W MR Images
Aug 08, 2019



Multiple sclerosis is one of the most common chronic neurological diseases affecting the central nervous system. Lesions produced by the MS can be observed through two modalities of magnetic resonance (MR), known as T2W and FLAIR sequences, both providing useful information for formulating a diagnosis. However, long acquisition time makes the acquired MR image vulnerable to motion artifacts. This leads to the need of accelerating the execution of the MR analysis. In this paper, we present a deep learning method that is able to reconstruct subsampled MR images obtained by reducing the k-space data, while maintaining a high image quality that can be used to observe brain lesions. The proposed method exploits the multimodal approach of neural networks and it also focuses on the data acquisition and processing stages to reduce execution time of the MR analysis. Results prove the effectiveness of the proposed method in reconstructing subsampled MR images while saving execution time.
Misregistration Measurement and Improvement for Sentinel-1 SAR and Sentinel-2 Optical images
May 22, 2020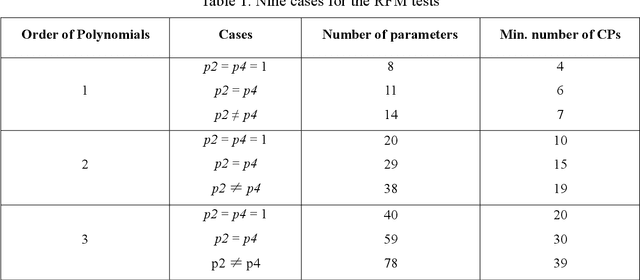
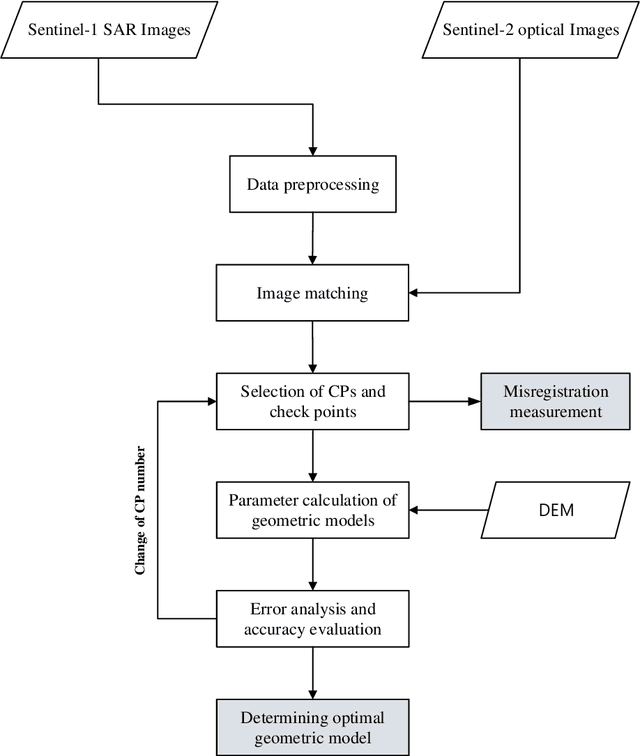
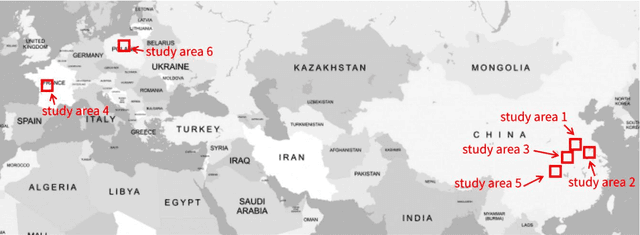
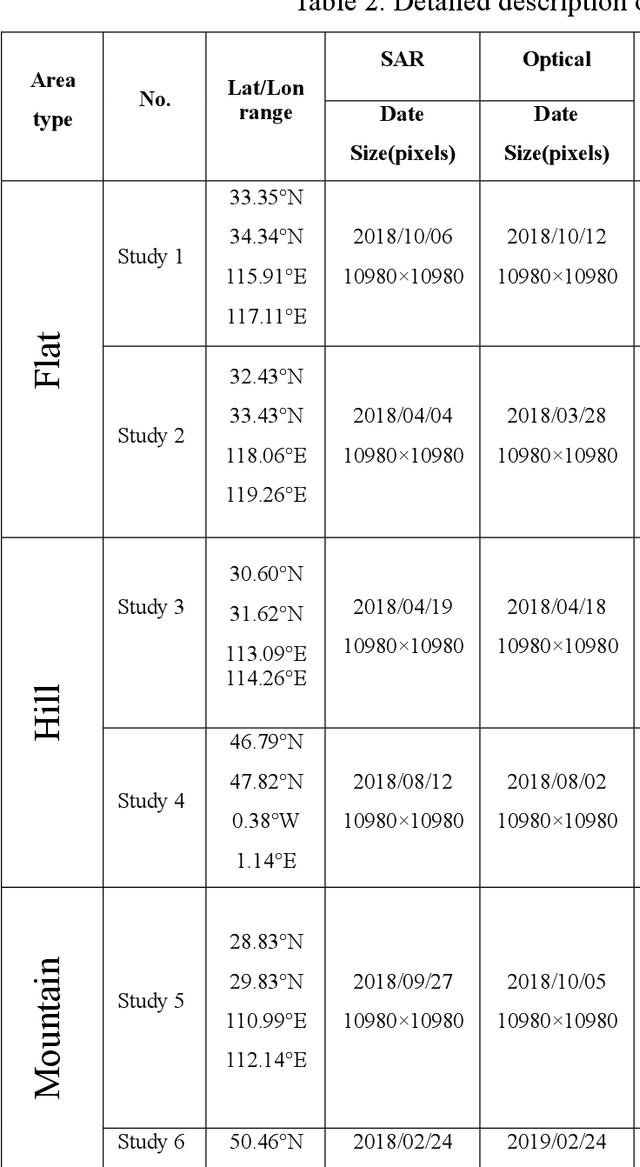
Co-registering the Sentinel-1 SAR and Sentinel-2 optical data of European Space Agency (ESA) is of great importance for many remote sensing applications. The Sentinel-1 and 2 product specifications from ESA show that the Sentinel-1 SAR L1 and the Sentinel-2 optical L1C images have a co-registration accuracy of within 2 pixels. However, we find that the actual misregistration errors are much larger than that between such images. This paper measures the misregistration errors by a block-based multimodal image matching strategy to six pairs of the Sentinel-1 SAR and Sentinel-2 optical images, which locate in China and Europe and cover three different terrains such as flat areas, hilly areas and mountainous areas. Our experimental results show the misregistration errors of the flat areas are 20-30 pixels, and these of the hilly areas are 20-40 pixels. While in the mountainous areas, the errors increase to 50-60 pixels. To eliminate the misregistration, we use some representative geometric transformation models such as polynomial models, projective models, and rational function models for the co-registration of the two types of images, and compare and analyze their registration accuracy under different number of control points and different terrains. The results of our analysis show that the 3rd. Order polynomial achieves the most satisfactory registration results. Its registration accuracy of the flat areas is less than 1.0 10m pixels, and that of the hilly areas is about 1.5 pixels, and that of the mountainous areas is between 1.8 and 2.3 pixels. In a word, this paper discloses and measures the misregistration between the Sentinel-1 SAR L1 and Sentinel-2 optical L1C images for the first time. Moreover, we also determine a relatively optimal geometric transformation model of the co-registration of the two types of images.
Temporal Spike Sequence Learning via Backpropagation for Deep Spiking Neural Networks
Feb 24, 2020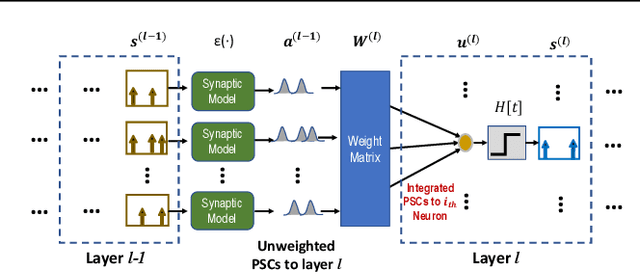

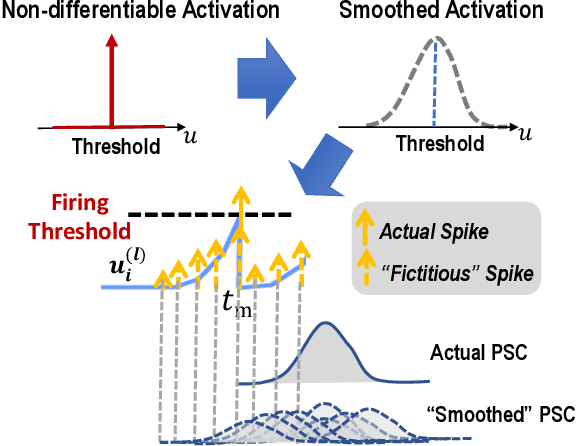

Spiking neural networks (SNNs) are well suited for spatio-temporal learning and implementations on energy-efficient event-driven neuromorphic processors. However, existing SNNs error backpropagation (BP) track methods lack proper handling of spiking discontinuities and suffer from low performance compared to BP methods for traditional artificial neural networks. In addition, a large number of time steps are typically required for SNNs to achieve decent performance, leading to high latency and rendering spike-based computation unscalable to deep architectures. We present a novel Temporal Spike Sequence Learning Backpropagation (TSSL-BP) method for training deep SNNs, which breaks down error backpropagation across two types of inter-neuron and intra-neuron dependencies. It considers the all-or-none characteristics of firing activities, capturing inter-neuron dependencies through presynaptic firing times, and internal evolution of each neuronal state through time capturing intra-neuron dependencies. For various image classification datasets, TSSL-BP efficiently trains deep SNNs within a short temporal time window of a few steps with improved accuracy and runtime efficiency including achieving more than 2% accuracy improvement over the previously reported SNN work on CIFAR10.
CASIA-SURF CeFA: A Benchmark for Multi-modal Cross-ethnicity Face Anti-spoofing
Mar 11, 2020
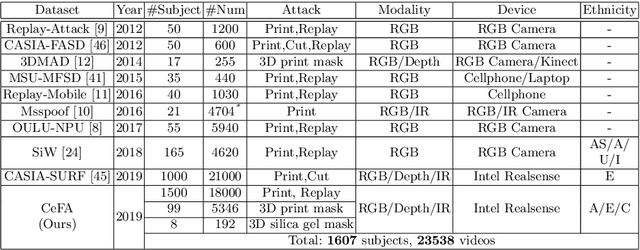
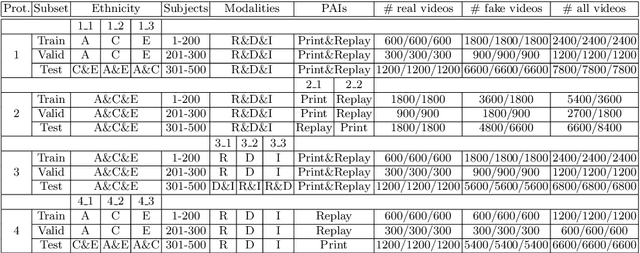
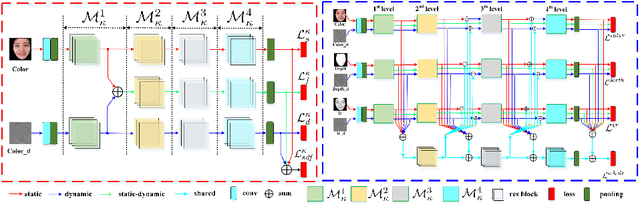
Ethnic bias has proven to negatively affect the performance of face recognition systems, and it remains an open research problem in face anti-spoofing. In order to study the ethnic bias for face anti-spoofing, we introduce the largest up to date CASIA-SURF Cross-ethnicity Face Anti-spoofing (CeFA) dataset (briefly named CeFA), covering $3$ ethnicities, $3$ modalities, $1,607$ subjects, and 2D plus 3D attack types. Four protocols are introduced to measure the affect under varied evaluation conditions, such as cross-ethnicity, unknown spoofs or both of them. To the best of our knowledge, CeFA is the first dataset including explicit ethnic labels in current published/released datasets for face anti-spoofing. Then, we propose a novel multi-modal fusion method as a strong baseline to alleviate these bias, namely, the static-dynamic fusion mechanism applied in each modality (i.e., RGB, Depth and infrared image). Later, a partially shared fusion strategy is proposed to learn complementary information from multiple modalities. Extensive experiments demonstrate that the proposed method achieves state-of-the-art results on the CASIA-SURF, OULU-NPU, SiW and the CeFA dataset.
Imbalanced Data Learning by Minority Class Augmentation using Capsule Adversarial Networks
Apr 08, 2020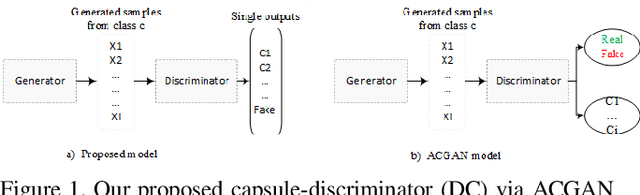

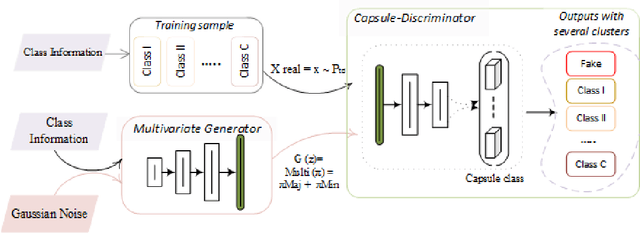
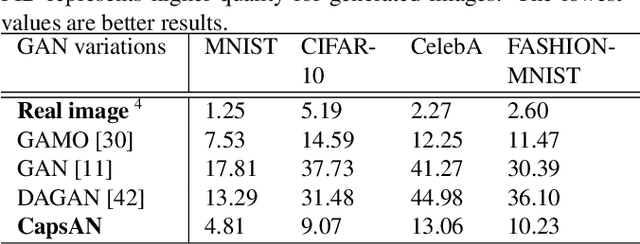
The fact that image datasets are often imbalanced poses an intense challenge for deep learning techniques. In this paper, we propose a method to restore the balance in imbalanced images, by coalescing two concurrent methods, generative adversarial networks (GANs) and capsule network. In our model, generative and discriminative networks play a novel competitive game, in which the generator generates samples towards specific classes from multivariate probabilities distribution. The discriminator of our model is designed in a way that while recognizing the real and fake samples, it is also requires to assign classes to the inputs. Since GAN approaches require fully observed data during training, when the training samples are imbalanced, the approaches might generate similar samples which leading to data overfitting. This problem is addressed by providing all the available information from both the class components jointly in the adversarial training. It improves learning from imbalanced data by incorporating the majority distribution structure in the generation of new minority samples. Furthermore, the generator is trained with feature matching loss function to improve the training convergence. In addition, prevents generation of outliers and does not affect majority class space. The evaluations show the effectiveness of our proposed methodology; in particular, the coalescing of capsule-GAN is effective at recognizing highly overlapping classes with much fewer parameters compared with the convolutional-GAN.
Alternating Segmentation and Simulation for Contrast Adaptive Tissue Classification
Nov 17, 2018A key feature of magnetic resonance (MR) imaging is its ability to manipulate how the intrinsic tissue parameters of the anatomy ultimately contribute to the contrast properties of the final, acquired image. This flexibility, however, can lead to substantial challenges for segmentation algorithms, particularly supervised methods. These methods require atlases or training data, which are composed of MR image and labeled image pairs. In most cases, the training data are obtained with a fixed acquisition protocol, leading to suboptimal performance when an input data set that requires segmentation has differing contrast properties. This drawback is increasingly significant with the recent movement towards multi-center research studies involving multiple scanners and acquisition protocols. In this work, we propose a new framework for supervised segmentation approaches that is robust to contrast differences between the training MR image and the input image. Our approach uses a generative simulation model within the segmentation process to compensate for the contrast differences. We allow the contrast of the MR image in the training data to vary by simulating a new contrast from the corresponding label image. The model parameters are optimized by a cost function measuring the consistency between the input MR image and its simulation based on a current estimate of the segmentation labels. We provide a proof of concept of this approach by combining a supervised classifier with a simple simulation model, and apply the resulting algorithm to synthetic images and actual MR images.