 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Reconstruction Transformer for Self-Supervised Time Series Representation Learning
May 20, 2022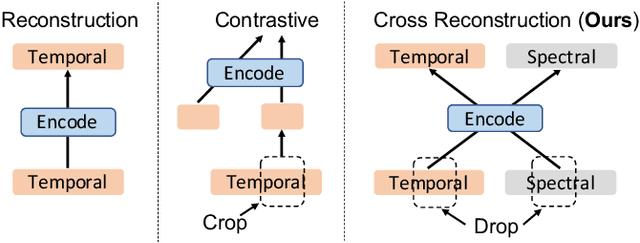
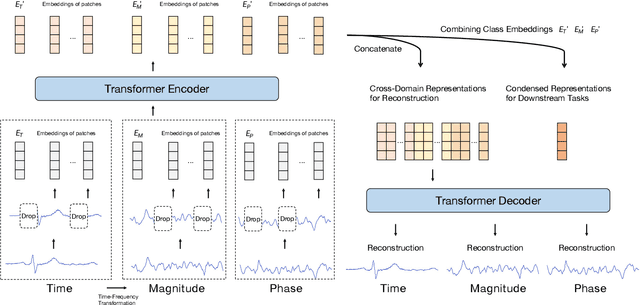
Unsupervised/self-supervised representation learning in time series is critical since labeled samples are usually scarce in real-world scenarios. Existing approaches mainly leverage the contrastive learning framework, which automatically learns to understand the similar and dissimilar data pairs. Nevertheless, they are restricted to the prior knowledge of constructing pairs, cumbersome sampling policy, and unstable performances when encountering sampling bias. Also, few works have focused on effectively modeling across temporal-spectral relations to extend the capacity of representations. In this paper, we aim at learning representations for time series from a new perspective and propose Cross Reconstruction Transformer (CRT) to solve the aforementioned problems in a unified way. CRT achieves time series representation learning through a cross-domain dropping-reconstruction task. Specifically, we transform time series into the frequency domain and randomly drop certain parts in both time and frequency domains. Dropping can maximally preserve the global context compared to cropping and masking. Then a transformer architecture is utilized to adequately capture the cross-domain correlations between temporal and spectral information through reconstructing data in both domains, which is called Dropped Temporal-Spectral Modeling. To discriminate the representations in global latent space, we propose Instance Discrimination Constraint to reduce the mutual information between different time series and sharpen the decision boundaries. Additionally, we propose a specified curriculum learning strategy to optimize the CRT, which progressively increases the dropping ratio in the training process.
MetaVA: Curriculum Meta-learning and Pre-fine-tuning of Deep Neural Networks for Detecting Ventricular Arrhythmias based on ECGs
Mar 01, 2022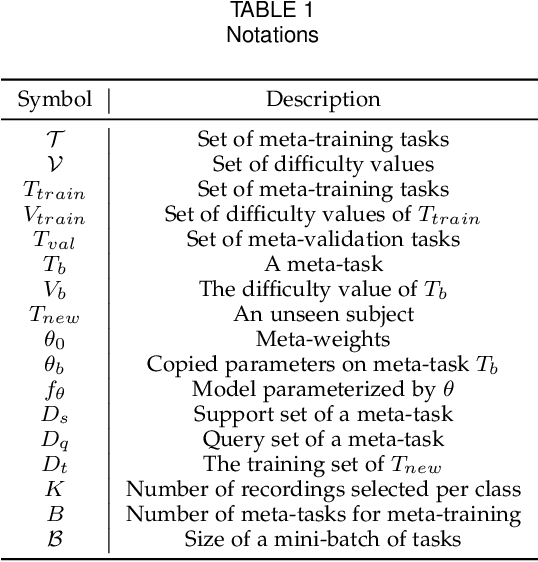
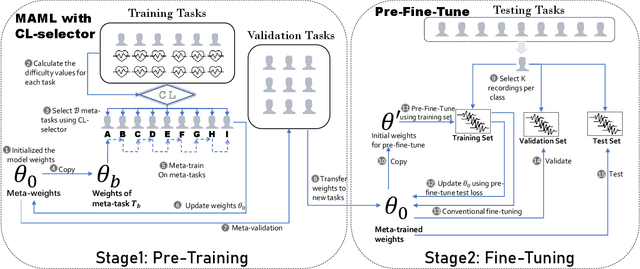

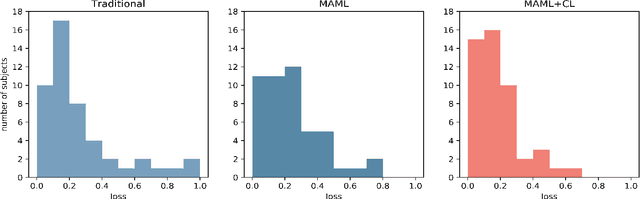
Ventricular arrhythmias (VA) are the main causes of sudden cardiac death. Developing machine learning methods for detecting VA based on electrocardiograms (ECGs) can help save people's lives. However, developing such machine learning models for ECGs is challenging because of the following: 1) group-level diversity from different subjects and 2) individual-level diversity from different moments of a single subject. In this study, we aim to solve these problems in the pre-training and fine-tuning stages. For the pre-training stage, we propose a novel model agnostic meta-learning (MAML) with curriculum learning (CL) method to solve group-level diversity. MAML is expected to better transfer the knowledge from a large dataset and use only a few recordings to quickly adapt the model to a new person. CL is supposed to further improve MAML by meta-learning from easy to difficult tasks. For the fine-tuning stage, we propose improved pre-fine-tuning to solve individual-level diversity. We conduct experiments using a combination of three publicly available ECG datasets. The results show that our method outperforms the compared methods in terms of all evaluation metrics. Ablation studies show that MAML and CL could help perform more evenly, and pre-fine-tuning could better fit the model to training data.
A Deep Bayesian Neural Network for Cardiac Arrhythmia Classification with Rejection from ECG Recordings
Feb 26, 2022
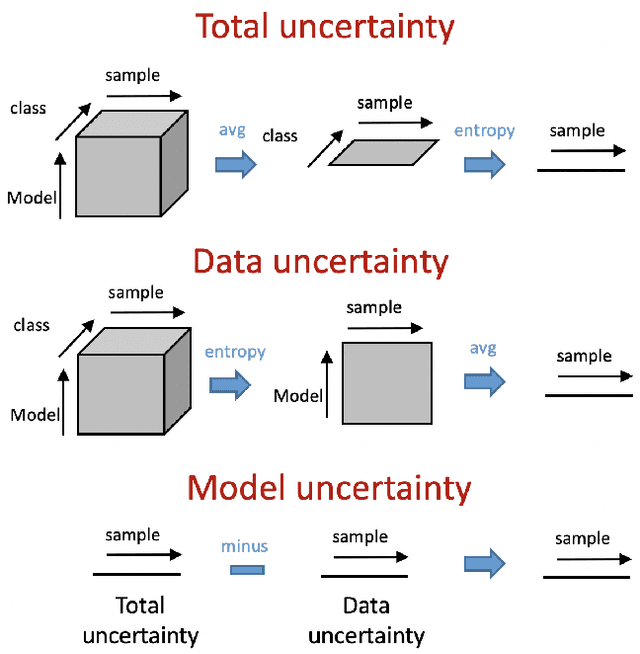
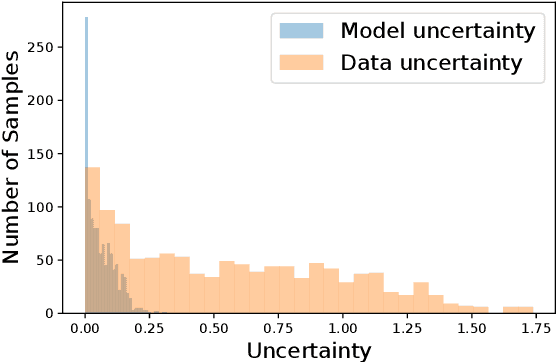
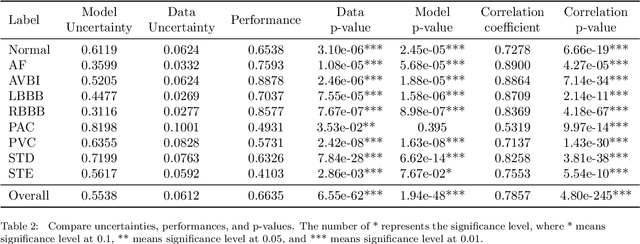
With the development of deep learning-based methods, automated classification of electrocardiograms (ECGs) has recently gained much attention. Although the effectiveness of deep neural networks has been encouraging, the lack of information given by the outputs restricts clinicians' reexamination. If the uncertainty estimation comes along with the classification results, cardiologists can pay more attention to "uncertain" cases. Our study aims to classify ECGs with rejection based on data uncertainty and model uncertainty. We perform experiments on a real-world 12-lead ECG dataset. First, we estimate uncertainties using the Monte Carlo dropout for each classification prediction, based on our Bayesian neural network. Then, we accept predictions with uncertainty under a given threshold and provide "uncertain" cases for clinicians. Furthermore, we perform a simulation experiment using varying thresholds. Finally, with the help of a clinician, we conduct case studies to explain the results of large uncertainties and incorrect predictions with small uncertainties. The results show that correct predictions are more likely to have smaller uncertainties, and the performance on accepted predictions improves as the accepting ratio decreases (i.e. more rejections). Case studies also help explain why rejection can improve the performance. Our study helps neural networks produce more accurate results and provide information on uncertainties to better assist clinicians in the diagnosis process. It can also enable deep-learning-based ECG interpretation in clinical implementation.
Learning ECG Representations based on Manipulated Temporal-Spatial Reverse Detection
Feb 25, 2022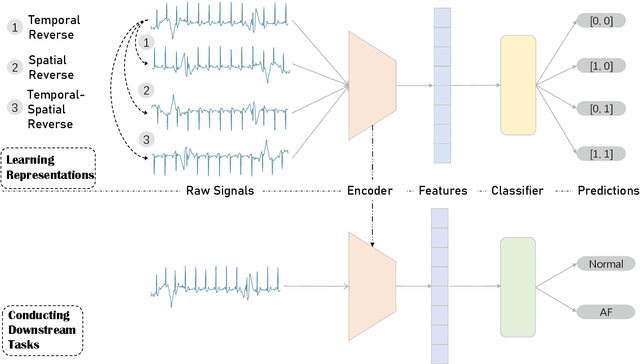
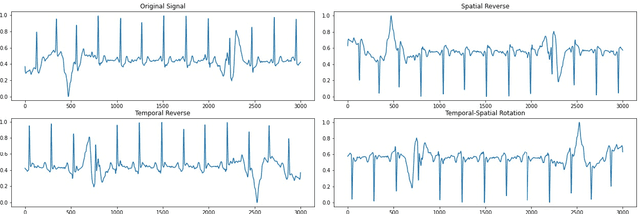
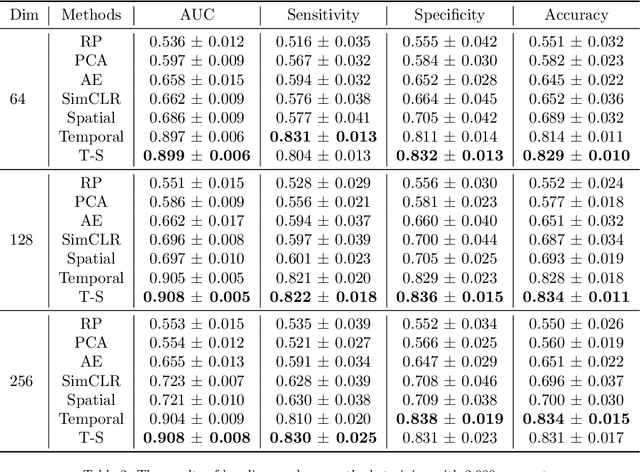
Learning representations from electrocardiogram (ECG) serves as a fundamental step for many downstream machine learning-based ECG analysis tasks. However, the learning process is always restricted by lack of high-quality labeled data in reality. Existing methods addressing data deficiency either cannot provide satisfied representations for downstream tasks or require too much effort to construct similar and dissimilar pairs to learn informative representations. In this paper, we propose a straightforward but effective approach to learn ECG representations. Inspired by the temporal and spatial characteristics of ECG, we flip the original signals horizontally, vertically, and both horizontally and vertically. The learning is then done by classifying the four types of signals including the original one. To verify the effectiveness of the proposed temporal-spatial (T-S) reverse detection method, we conduct a downstream task to detect atrial fibrillation (AF) which is one of the most common ECG tasks. The results show that the ECG representations learned with our method lead to remarkable performances on the downstream task. In addition, after exploring the representational feature space and investigating which parts of the ECG signal contribute to the representations, we conclude that the temporal reverse is more effective than the spatial reverse for learning ECG representations.
Composing Recurrent Spiking Neural Networks using Locally-Recurrent Motifs and Risk-Mitigating Architectural Optimization
Aug 04, 2021

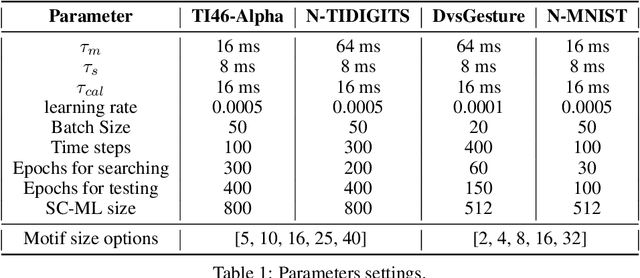
In neural circuits, recurrent connectivity plays a crucial role in network function and stability. However, existing recurrent spiking neural networks (RSNNs) are often constructed by random connections without optimization. While RSNNs can produce rich dynamics that are critical for memory formation and learning, systemic architectural optimization of RSNNs is still an opening challenge. We aim to enable systemic design of large RSNNs via a new scalable RSNN architecture and automated architectural optimization. We compose RSNNs based on a layer architecture called Sparsely-Connected Recurrent Motif Layer (SC-ML) that consists of multiple small recurrent motifs wired together by sparse lateral connections. The small size of the motifs and sparse inter-motif connectivity leads to an RSNN architecture scalable to large network sizes. We further propose a method called Hybrid Risk-Mitigating Architectural Search (HRMAS) to systematically optimize the topology of the proposed recurrent motifs and SC-ML layer architecture. HRMAS is an alternating two-step optimization process by which we mitigate the risk of network instability and performance degradation caused by architectural change by introducing a novel biologically-inspired "self-repairing" mechanism through intrinsic plasticity. The intrinsic plasticity is introduced to the second step of each HRMAS iteration and acts as unsupervised fast self-adaption to structural and synaptic weight modifications introduced by the first step during the RSNN architectural "evolution". To the best of the authors' knowledge, this is the first work that performs systematic architectural optimization of RSNNs. Using one speech and three neuromorphic datasets, we demonstrate the significant performance improvement brought by the proposed automated architecture optimization over existing manually-designed RSNNs.
Backpropagated Neighborhood Aggregation for Accurate Training of Spiking Neural Networks
Jun 22, 2021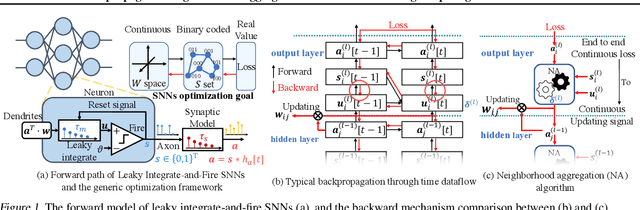

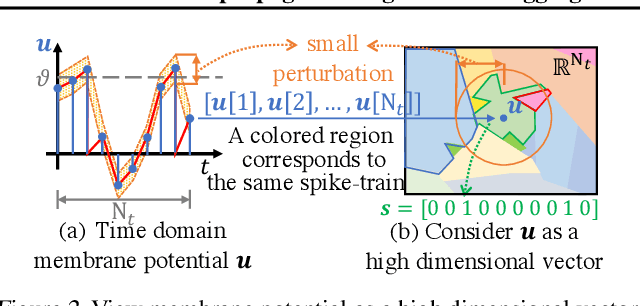
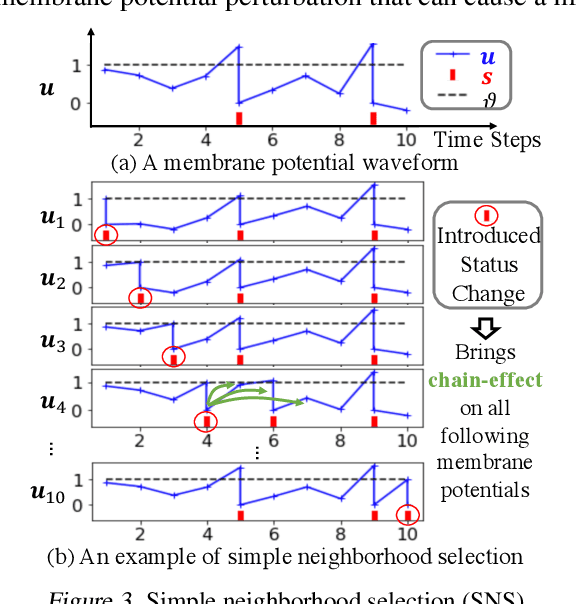
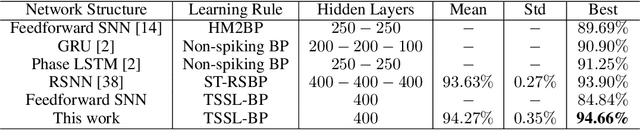
While backpropagation (BP) has been applied to spiking neural networks (SNNs) achieving encouraging results, a key challenge involved is to backpropagate a continuous-valued loss over layers of spiking neurons exhibiting discontinuous all-or-none firing activities. Existing methods deal with this difficulty by introducing compromises that come with their own limitations, leading to potential performance degradation. We propose a novel BP-like method, called neighborhood aggregation (NA), which computes accurate error gradients guiding weight updates that may lead to discontinuous modifications of firing activities. NA achieves this goal by aggregating finite differences of the loss over multiple perturbed membrane potential waveforms in the neighborhood of the present membrane potential of each neuron while utilizing a new membrane potential distance function. Our experiments show that the proposed NA algorithm delivers the state-of-the-art performance for SNN training on several datasets.
Skip-Connected Self-Recurrent Spiking Neural Networks with Joint Intrinsic Parameter and Synaptic Weight Training
Oct 23, 2020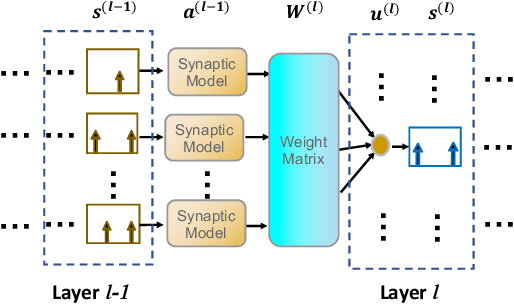

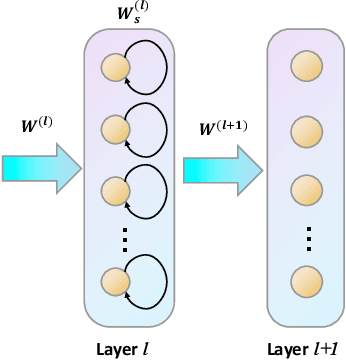
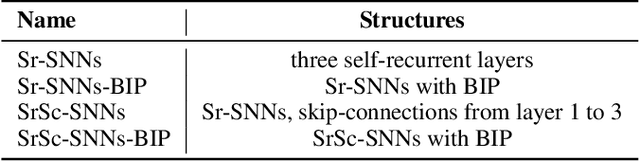
As an important class of spiking neural networks (SNNs), recurrent spiking neural networks (RSNNs) possess great computational power and have been widely used for processing sequential data like audio and text. However, most RSNNs suffer from two problems. 1. Due to a lack of architectural guidance, random recurrent connectivity is often adopted, which does not guarantee good performance. 2. Training of RSNNs is in general challenging, bottlenecking achievable model accuracy. To address these problems, we propose a new type of RSNNs called Skip-Connected Self-Recurrent SNNs (ScSr-SNNs). Recurrence in ScSr-SNNs is introduced in a stereotyped manner by adding self-recurrent connections to spiking neurons, which implements local memory. The network dynamics is enriched by skip connections between nonadjacent layers. Constructed by simplified self-recurrent and skip connections, ScSr-SNNs are able to realize recurrent behaviors similar to those of more complex RSNNs while the error gradients can be more straightforwardly calculated due to the mostly feedforward nature of the network. Moreover, we propose a new backpropagation (BP) method called backpropagated intrinsic plasticity (BIP) to further boost the performance of ScSr-SNNs by training intrinsic model parameters. Unlike standard intrinsic plasticity rules that adjust the neuron's intrinsic parameters according to neuronal activity, the proposed BIP methods optimize intrinsic parameters based on the backpropagated error gradient of a well-defined global loss function in addition to synaptic weight training. Based upon challenging speech and neuromorphic speech datasets including TI46-Alpha, TI46-Digits, and N-TIDIGITS, the proposed ScSr-SNNs can boost performance by up to 2.55% compared with other types of RSNNs trained by state-of-the-art BP methods.
Temporal Spike Sequence Learning via Backpropagation for Deep Spiking Neural Networks
Feb 24, 2020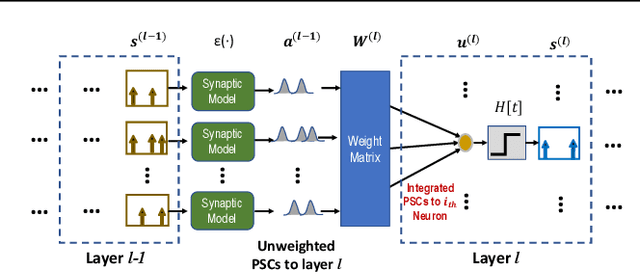

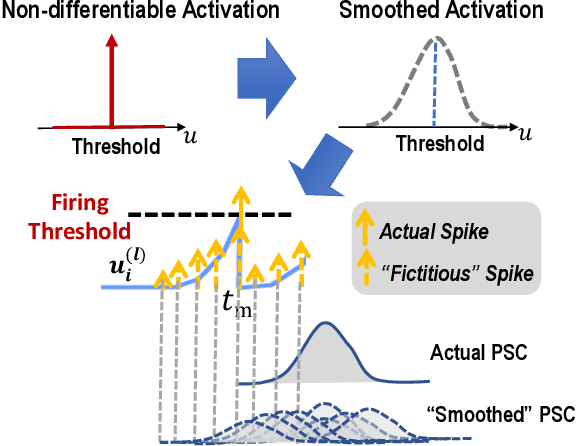

Spiking neural networks (SNNs) are well suited for spatio-temporal learning and implementations on energy-efficient event-driven neuromorphic processors. However, existing SNNs error backpropagation (BP) track methods lack proper handling of spiking discontinuities and suffer from low performance compared to BP methods for traditional artificial neural networks. In addition, a large number of time steps are typically required for SNNs to achieve decent performance, leading to high latency and rendering spike-based computation unscalable to deep architectures. We present a novel Temporal Spike Sequence Learning Backpropagation (TSSL-BP) method for training deep SNNs, which breaks down error backpropagation across two types of inter-neuron and intra-neuron dependencies. It considers the all-or-none characteristics of firing activities, capturing inter-neuron dependencies through presynaptic firing times, and internal evolution of each neuronal state through time capturing intra-neuron dependencies. For various image classification datasets, TSSL-BP efficiently trains deep SNNs within a short temporal time window of a few steps with improved accuracy and runtime efficiency including achieving more than 2% accuracy improvement over the previously reported SNN work on CIFAR10.
Boosting Throughput and Efficiency of Hardware Spiking Neural Accelerators using Time Compression Supporting Multiple Spike Codes
Sep 10, 2019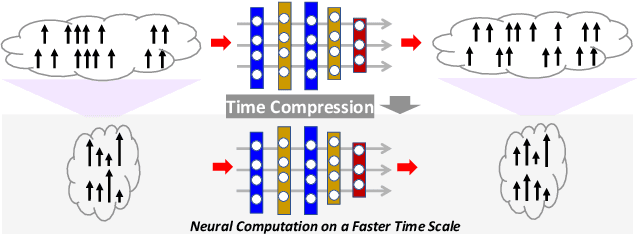
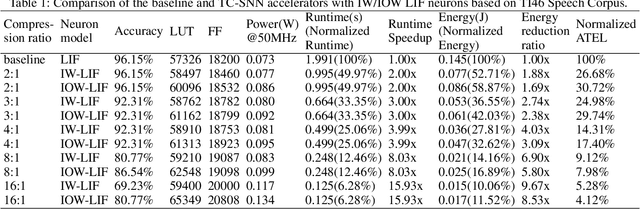
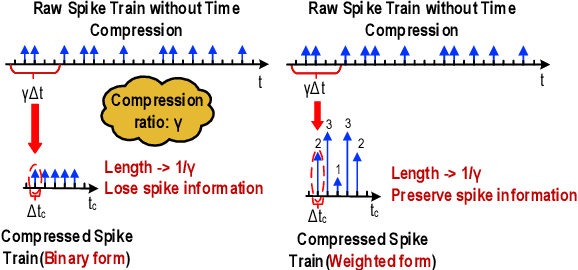
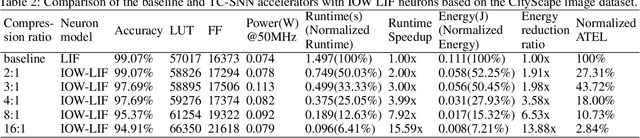
Spiking neural networks (SNNs) are the third generation of neural networks and can explore both rate and temporal coding for energy-efficient event-driven computation. However, the decision accuracy of existing SNN designs is contingent upon processing a large number of spikes over a long period. Nevertheless, the switching power of SNN hardware accelerators is proportional to the number of spikes processed while the length of spike trains limits throughput and static power efficiency. This paper presents the first study on developing temporal compression to significantly boost throughput and reduce energy dissipation of digital hardware SNN accelerators while being applicable to multiple spike codes. The proposed compression architectures consist of low-cost input spike compression units, novel input-and-output-weighted spiking neurons, and reconfigurable time constant scaling to support large and flexible time compression ratios. Our compression architectures can be transparently applied to any given pre-designed SNNs employing either rate or temporal codes while incurring minimal modification of the neural models, learning algorithms, and hardware design. Using spiking speech and image recognition datasets, we demonstrate the feasibility of supporting large time compression ratios of up to 16x, delivering up to 15.93x, 13.88x, and 86.21x improvements in throughput, energy dissipation, the tradeoffs between hardware area, runtime, energy, and classification accuracy, respectively based on different spike codes on a Xilinx Zynq-7000 FPGA. These results are achieved while incurring little extra hardware overhead.
Spike-Train Level Backpropagation for Training Deep Recurrent Spiking Neural Networks
Aug 18, 2019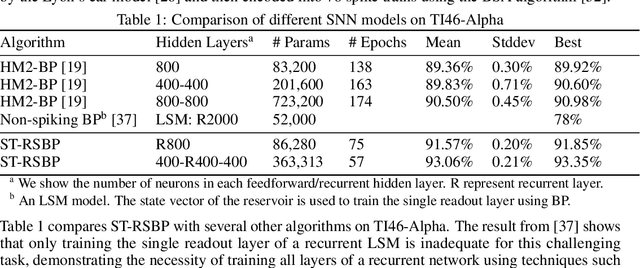
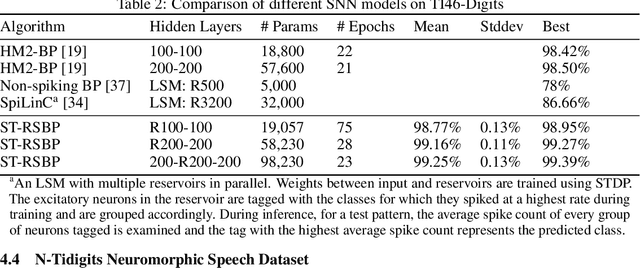
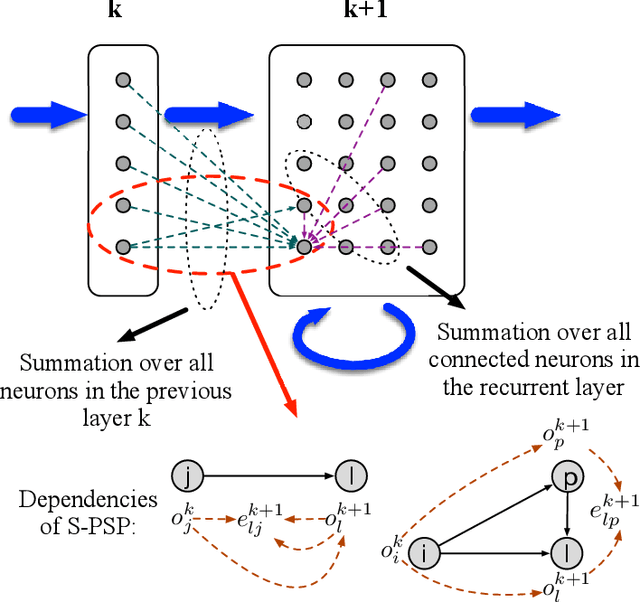
Spiking neural networks (SNNs) are more biologically plausible than conventional artificial neural networks (ANNs). SNNs well support spatiotemporal learning and energy-efficient event-driven hardware neuromorphic processors. As an important class of SNNs, recurrent spiking neural networks (RSNNs) possess great computational power. However, the practical application of RSNNs is severely limited by challenges in training. Biologically-inspired unsupervised learning has limited capability in boosting the performance of RSNNs. On the other hand, existing backpropagation (BP) methods suffer from high complexity of unrolling in time, vanishing and exploding gradients, and approximate differentiation of discontinuous spiking activities when applied to RSNNs. To enable supervised training of RSNNs under a well-defined loss function, we present a novel Spike-Train level RSNNs Backpropagation (ST-RSBP) algorithm for training deep RSNNs. The proposed ST-RSBP directly computes the gradient of a rated-coded loss function defined at the output layer of the network w.r.t tunable parameters. The scalability of ST-RSBP is achieved by the proposed spike-train level computation during which temporal effects of the SNN is captured in both the forward and backward pass of BP. Our ST-RSBP algorithm can be broadly applied to RSNNs with a single recurrent layer or deep RSNNs with multiple feed-forward and recurrent layers. Based upon challenging speech and image datasets including TI46, N-TIDIGITS, and Fashion-MNIST, ST-RSBP is able to train RSNNs with an accuracy surpassing that of the current state-of-art SNN BP algorithms and conventional non-spiking deep learning models.