 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFAFed -- Protocol analysis
Jun 29, 2022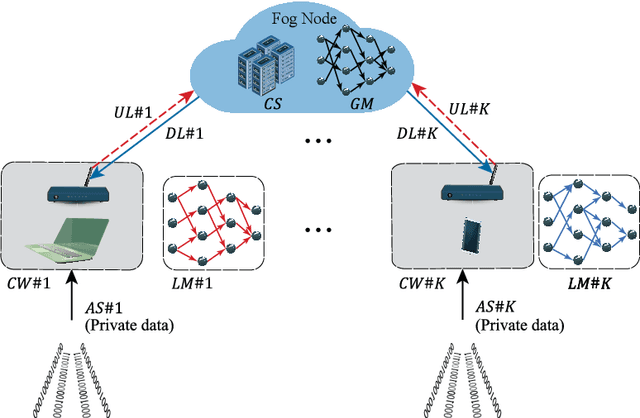
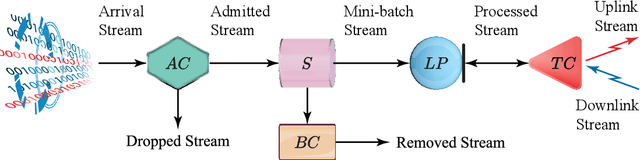
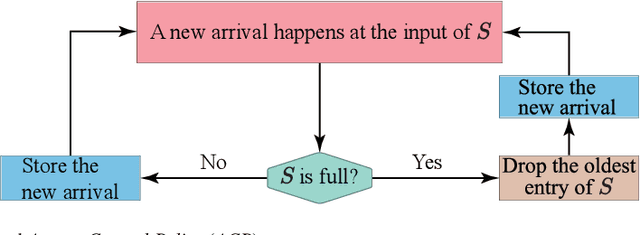
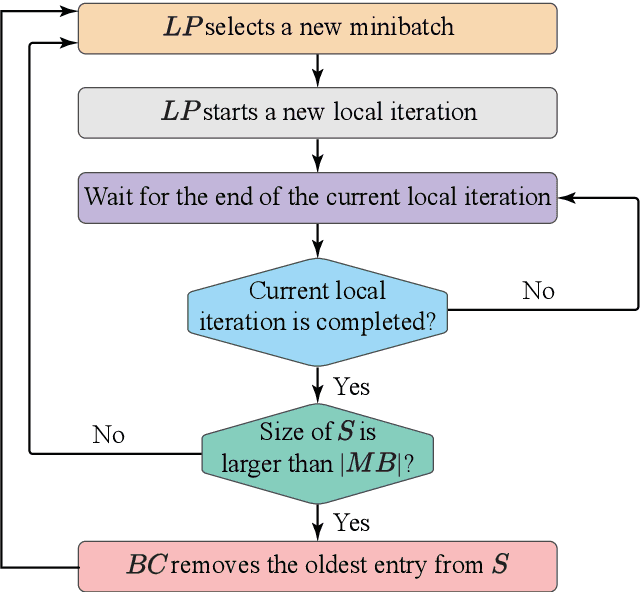
In this paper, we design, analyze the convergence properties and address the implementation aspects of AFAFed. This is a novel Asynchronous Fair Adaptive Federated learning framework for stream-oriented IoT application environments, which are featured by time-varying operating conditions, heterogeneous resource-limited devices (i.e., coworkers), non-i.i.d. local training data and unreliable communication links. The key new of AFAFed is the synergic co-design of: (i) two sets of adaptively tuned tolerance thresholds and fairness coefficients at the coworkers and central server, respectively; and, (ii) a distributed adaptive mechanism, which allows each coworker to adaptively tune own communication rate. The convergence properties of AFAFed under (possibly) non-convex loss functions is guaranteed by a set of new analytical bounds, which formally unveil the impact on the resulting AFAFed convergence rate of a number of Federated Learning (FL) parameters, like, first and second moments of the per-coworker number of consecutive model updates, data skewness, communication packet-loss probability, and maximum/minimum values of the (adaptively tuned) mixing coefficient used for model aggregation.
Gomoku: analysis of the game and of the player Wine
Nov 01, 2021
Gomoku, also known as five in a row, is a classical board game, ideally suited for quickly testing novel Artificial Intelligence (AI) techniques. With the aim of facilitating a developer willing to write a new Gomoku player, in this report we present an analysis of the main game concepts and strategies, which is wider and deeper than existing ones. Moreover, after discussing the general structure of an artificial player, we present and analyse a strong Gomoku player, named Wine, the code of which is freely available on the Internet and which is an excelent example of how a modern player is organised.
A New Class of Efficient Adaptive Filters for Online Nonlinear Modeling
Apr 19, 2021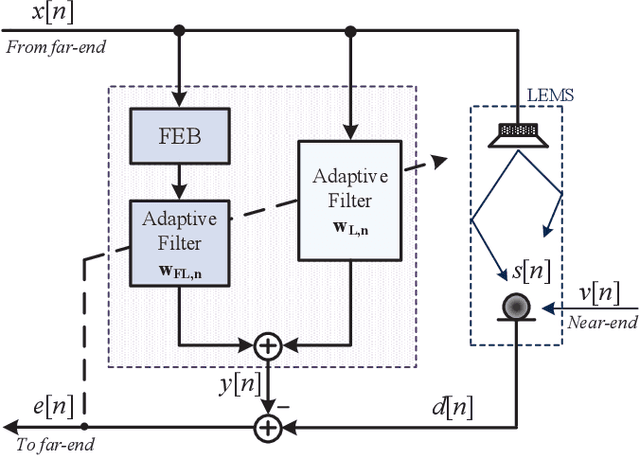
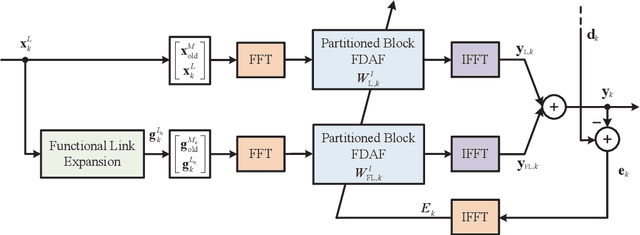
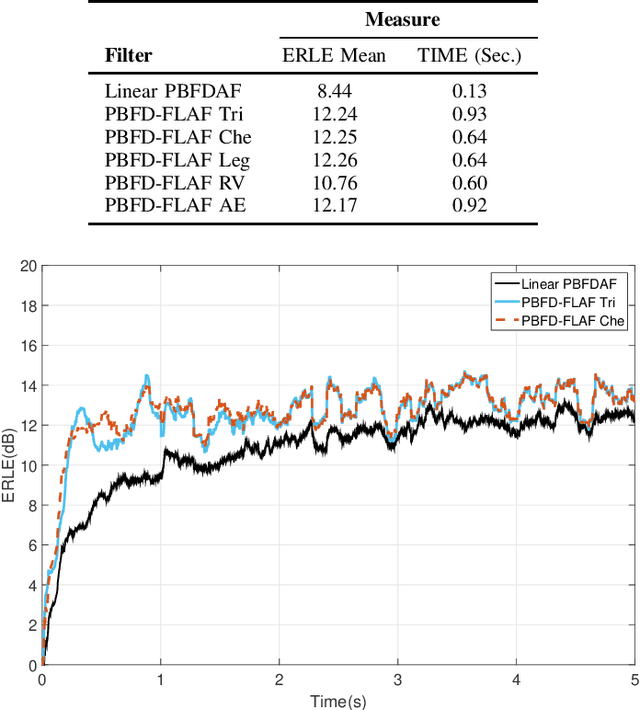

Nonlinear models are known to provide excellent performance in real-world applications that often operate in non-ideal conditions. However, such applications often require online processing to be performed with limited computational resources. In this paper, we propose a new efficient nonlinear model for online applications. The proposed algorithm is based on the linear-in-the-parameters (LIP) nonlinear filters and their implementation as functional link adaptive filters (FLAFs). We focus here on a new effective and efficient approach for FLAFs based on frequency-domain adaptive filters. We introduce the class of frequency-domain functional link adaptive filters (FD-FLAFs) and propose a partitioned block approach for their implementation. We also investigate on the functional link expansions that provide the most significant benefits operating with limited resources in the frequency-domain. We present and compare FD-FLAFs with different expansions to identify the LIP nonlinear filters showing the best tradeoff between performance and computational complexity. Experimental results prove that the frequency domain LIP nonlinear filters can be considered as an efficient and effective solution for online applications, like the nonlinear acoustic echo cancellation.
Why should we add early exits to neural networks?
Apr 27, 2020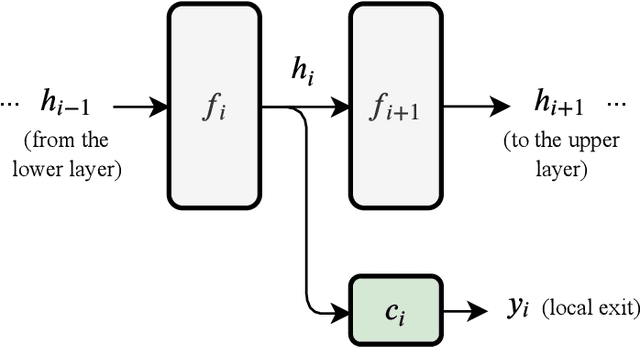
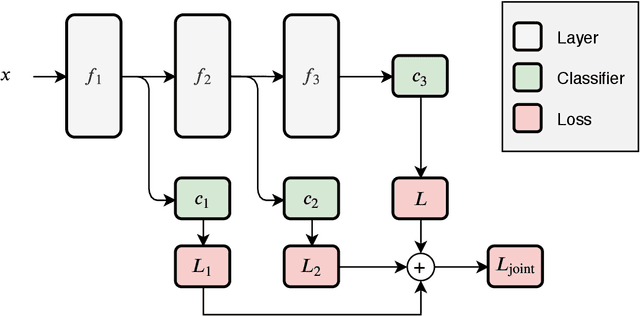
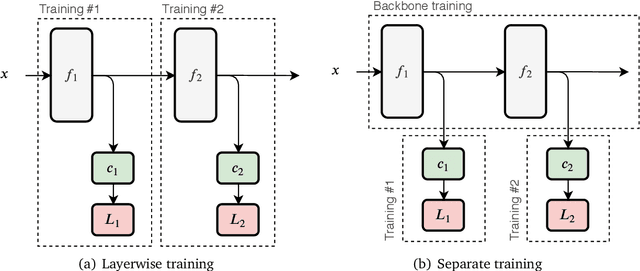
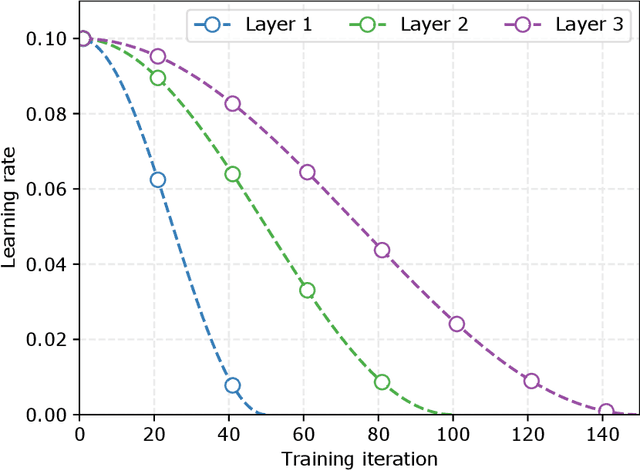
Deep neural networks are generally designed as a stack of differentiable layers, in which a prediction is obtained only after running the full stack. Recently, some contributions have proposed techniques to endow the networks with early exits, allowing to obtain predictions at intermediate points of the stack. These multi-output networks have a number of advantages, including: (i) significant reductions of the inference time, (ii) reduced tendency to overfitting and vanishing gradients, and (iii) capability of being distributed over multi-tier computation platforms. In addition, they connect to the wider themes of biological plausibility and layered cognitive reasoning. In this paper, we provide a comprehensive introduction to this family of neural networks, by describing in a unified fashion the way these architectures can be designed, trained, and actually deployed in time-constrained scenarios. We also describe in-depth their application scenarios in 5G and Fog computing environments, as long as some of the open research questions connected to them.
A Multimodal Deep Network for the Reconstruction of T2W MR Images
Aug 08, 2019



Multiple sclerosis is one of the most common chronic neurological diseases affecting the central nervous system. Lesions produced by the MS can be observed through two modalities of magnetic resonance (MR), known as T2W and FLAIR sequences, both providing useful information for formulating a diagnosis. However, long acquisition time makes the acquired MR image vulnerable to motion artifacts. This leads to the need of accelerating the execution of the MR analysis. In this paper, we present a deep learning method that is able to reconstruct subsampled MR images obtained by reducing the k-space data, while maintaining a high image quality that can be used to observe brain lesions. The proposed method exploits the multimodal approach of neural networks and it also focuses on the data acquisition and processing stages to reduce execution time of the MR analysis. Results prove the effectiveness of the proposed method in reconstructing subsampled MR images while saving execution time.
Efficient data augmentation using graph imputation neural networks
Jun 20, 2019



Recently, data augmentation in the semi-supervised regime, where unlabeled data vastly outnumbers labeled data, has received a considerable attention. In this paper, we describe an efficient technique for this task, exploiting a recent framework we proposed for missing data imputation called graph imputation neural network (GINN). The key idea is to leverage both supervised and unsupervised data to build a graph of similarities between points in the dataset. Then, we augment the dataset by severely damaging a few of the nodes (up to 80\% of their features), and reconstructing them using a variation of GINN. On several benchmark datasets, we show that our method can obtain significant improvements compared to a fully-supervised model, and we are able to augment the datasets up to a factor of 10x. This points to the power of graph-based neural networks to represent structural affinities in the samples for tasks of data reconstruction and augmentation.
Learning activation functions from data using cubic spline interpolation
May 11, 2017
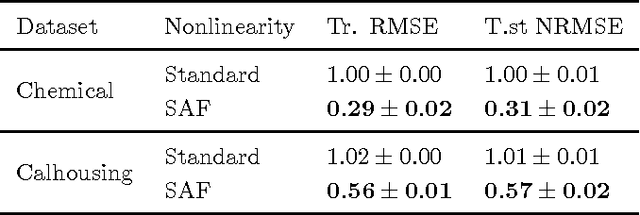

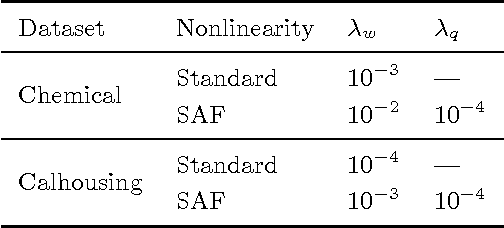
Neural networks require a careful design in order to perform properly on a given task. In particular, selecting a good activation function (possibly in a data-dependent fashion) is a crucial step, which remains an open problem in the research community. Despite a large amount of investigations, most current implementations simply select one fixed function from a small set of candidates, which is not adapted during training, and is shared among all neurons throughout the different layers. However, neither two of these assumptions can be supposed optimal in practice. In this paper, we present a principled way to have data-dependent adaptation of the activation functions, which is performed independently for each neuron. This is achieved by leveraging over past and present advances on cubic spline interpolation, allowing for local adaptation of the functions around their regions of use. The resulting algorithm is relatively cheap to implement, and overfitting is counterbalanced by the inclusion of a novel damping criterion, which penalizes unwanted oscillations from a predefined shape. Experimental results validate the proposal over two well-known benchmarks.
Effective Blind Source Separation Based on the Adam Algorithm
Sep 26, 2016



In this paper, we derive a modified InfoMax algorithm for the solution of Blind Signal Separation (BSS) problems by using advanced stochastic methods. The proposed approach is based on a novel stochastic optimization approach known as the Adaptive Moment Estimation (Adam) algorithm. The proposed BSS solution can benefit from the excellent properties of the Adam approach. In order to derive the new learning rule, the Adam algorithm is introduced in the derivation of the cost function maximization in the standard InfoMax algorithm. The natural gradient adaptation is also considered. Finally, some experimental results show the effectiveness of the proposed approach.