 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Tale of Two Bases: Local-Nonlocal Regularization on Image Patches with Convolution Framelets
Sep 12, 2016

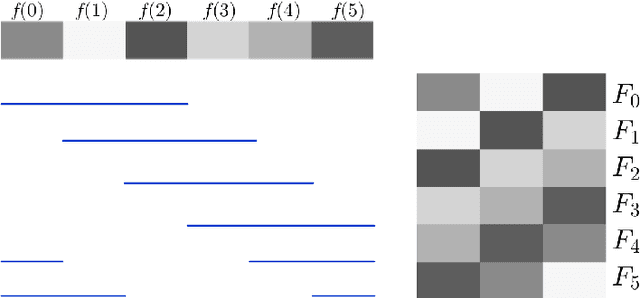
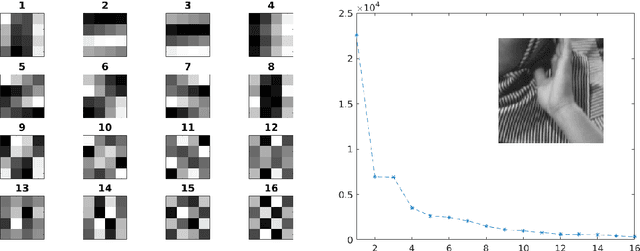
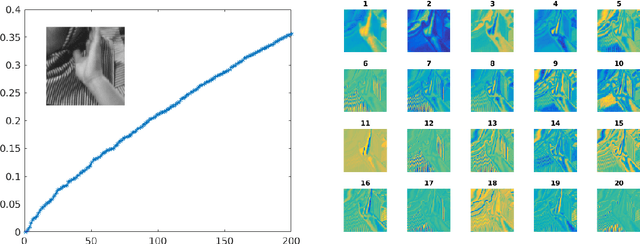
We propose an image representation scheme combining the local and nonlocal characterization of patches in an image. Our representation scheme can be shown to be equivalent to a tight frame constructed from convolving local bases (e.g. wavelet frames, discrete cosine transforms, etc.) with nonlocal bases (e.g. spectral basis induced by nonlinear dimension reduction on patches), and we call the resulting frame elements {\it convolution framelets}. Insight gained from analyzing the proposed representation leads to a novel interpretation of a recent high-performance patch-based image inpainting algorithm using Point Integral Method (PIM) and Low Dimension Manifold Model (LDMM) [Osher, Shi and Zhu, 2016]. In particular, we show that LDMM is a weighted $\ell_2$-regularization on the coefficients obtained by decomposing images into linear combinations of convolution framelets; based on this understanding, we extend the original LDMM to a reweighted version that yields further improved inpainting results. In addition, we establish the energy concentration property of convolution framelet coefficients for the setting where the local basis is constructed from a given nonlocal basis via a linear reconstruction framework; a generalization of this framework to unions of local embeddings can provide a natural setting for interpreting BM3D, one of the state-of-the-art image denoising algorithms.
Synthesis and Edition of Ultrasound Images via Sketch Guided Progressive Growing GANs
Apr 01, 2020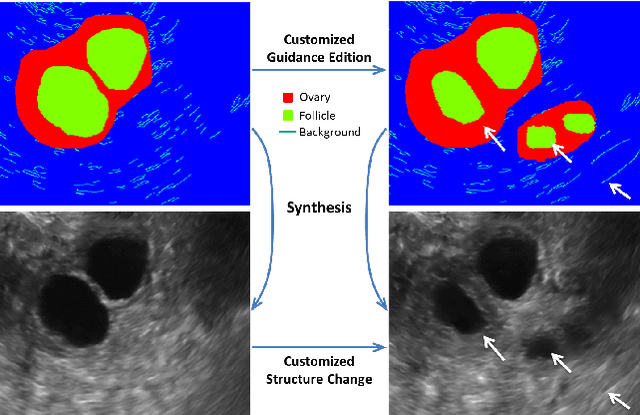
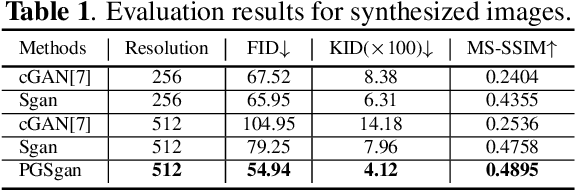
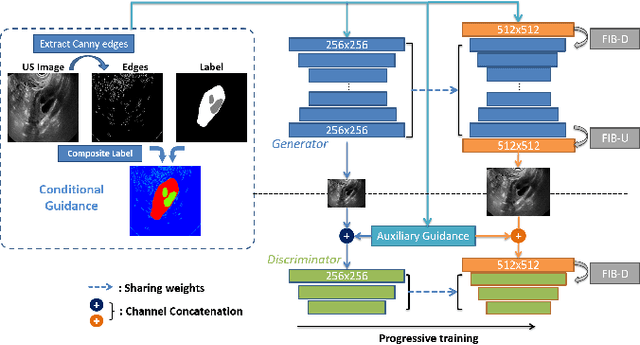
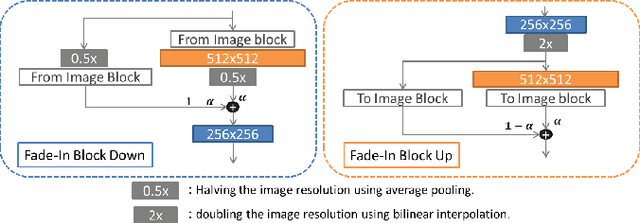
Ultrasound (US) is widely accepted in clinic for anatomical structure inspection. However, lacking in resources to practice US scan, novices often struggle to learn the operation skills. Also, in the deep learning era, automated US image analysis is limited by the lack of annotated samples. Efficiently synthesizing realistic, editable and high resolution US images can solve the problems. The task is challenging and previous methods can only partially complete it. In this paper, we devise a new framework for US image synthesis. Particularly, we firstly adopt a sketch generative adversarial networks (Sgan) to introduce background sketch upon object mask in a conditioned generative adversarial network. With enriched sketch cues, Sgan can generate realistic US images with editable and fine-grained structure details. Although effective, Sgan is hard to generate high resolution US images. To achieve this, we further implant the Sgan into a progressive growing scheme (PGSgan). By smoothly growing both generator and discriminator, PGSgan can gradually synthesize US images from low to high resolution. By synthesizing ovary and follicle US images, our extensive perceptual evaluation, user study and segmentation results prove the promising efficacy and efficiency of the proposed PGSgan.
AIM 2020 Challenge on Video Extreme Super-Resolution: Methods and Results
Sep 14, 2020This paper reviews the video extreme super-resolution challenge associated with the AIM 2020 workshop at ECCV 2020. Common scaling factors for learned video super-resolution (VSR) do not go beyond factor 4. Missing information can be restored well in this region, especially in HR videos, where the high-frequency content mostly consists of texture details. The task in this challenge is to upscale videos with an extreme factor of 16, which results in more serious degradations that also affect the structural integrity of the videos. A single pixel in the low-resolution (LR) domain corresponds to 256 pixels in the high-resolution (HR) domain. Due to this massive information loss, it is hard to accurately restore the missing information. Track 1 is set up to gauge the state-of-the-art for such a demanding task, where fidelity to the ground truth is measured by PSNR and SSIM. Perceptually higher quality can be achieved in trade-off for fidelity by generating plausible high-frequency content. Track 2 therefore aims at generating visually pleasing results, which are ranked according to human perception, evaluated by a user study. In contrast to single image super-resolution (SISR), VSR can benefit from additional information in the temporal domain. However, this also imposes an additional requirement, as the generated frames need to be consistent along time.
New Methods to Improve Large-Scale Microscopy Image Analysis with Prior Knowledge and Uncertainty
Aug 30, 2016
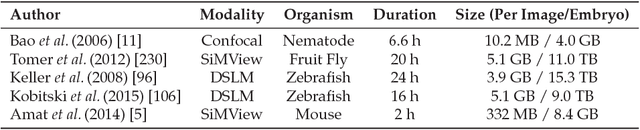


Multidimensional imaging techniques provide powerful ways to examine various kinds of scientific questions. The routinely produced datasets in the terabyte-range, however, can hardly be analyzed manually and require an extensive use of automated image analysis. The present thesis introduces a new concept for the estimation and propagation of uncertainty involved in image analysis operators and new segmentation algorithms that are suitable for terabyte-scale analyses of 3D+t microscopy images.
Dissimilarity Mixture Autoencoder for Deep Clustering
Jun 22, 2020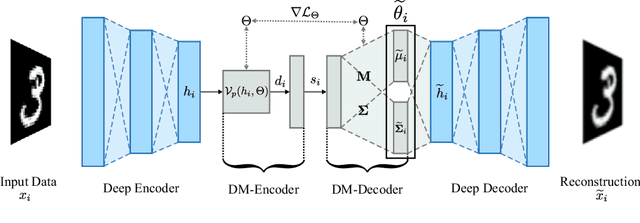
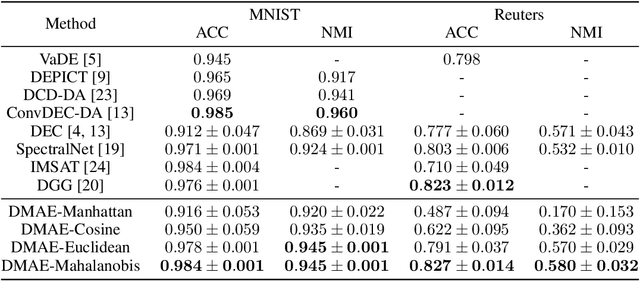
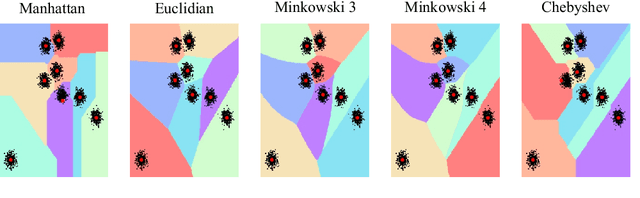
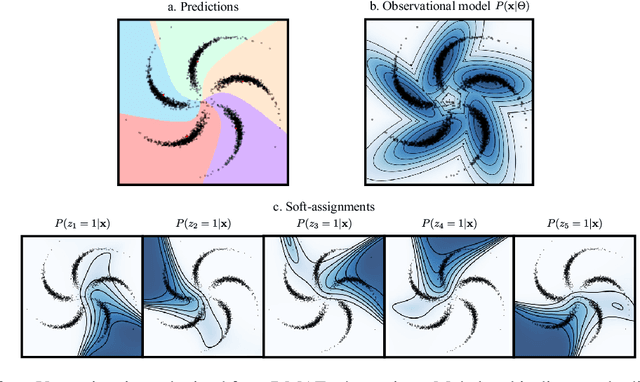
In this paper, we introduce the Dissimilarity Mixture Autoencoder (DMAE), a novel neural network model that uses a dissimilarity function to generalize a family of density estimation and clustering methods. It is formulated in such a way that it internally estimates the parameters of a probability distribution through gradient-based optimization. Also, the proposed model can leverage from deep representation learning due to its straightforward incorporation into deep learning architectures, because, it consists of an encoder-decoder network that computes a probabilistic representation. Experimental evaluation was performed on image and text clustering benchmark datasets showing that the method is competitive in terms of unsupervised classification accuracy and normalized mutual information. The source code to replicate the experiments is publicly available at https://github.com/larajuse/DMAE
Slot Contrastive Networks: A Contrastive Approach for Representing Objects
Jul 18, 2020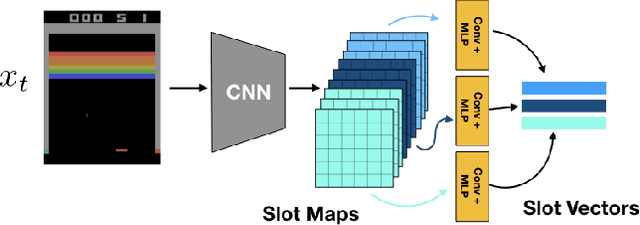
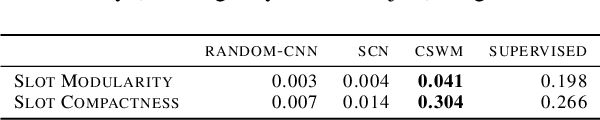
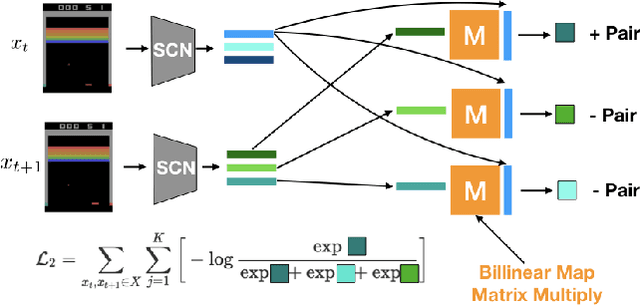

Unsupervised extraction of objects from low-level visual data is an important goal for further progress in machine learning. Existing approaches for representing objects without labels use structured generative models with static images. These methods focus a large amount of their capacity on reconstructing unimportant background pixels, missing low contrast or small objects. Conversely, we present a new method that avoids losses in pixel space and over-reliance on the limited signal a static image provides. Our approach takes advantage of objects' motion by learning a discriminative, time-contrastive loss in the space of slot representations, attempting to force each slot to not only capture entities that move, but capture distinct objects from the other slots. Moreover, we introduce a new quantitative evaluation metric to measure how "diverse" a set of slot vectors are, and use it to evaluate our model on 20 Atari games.
Multimodal price prediction
Jul 09, 2020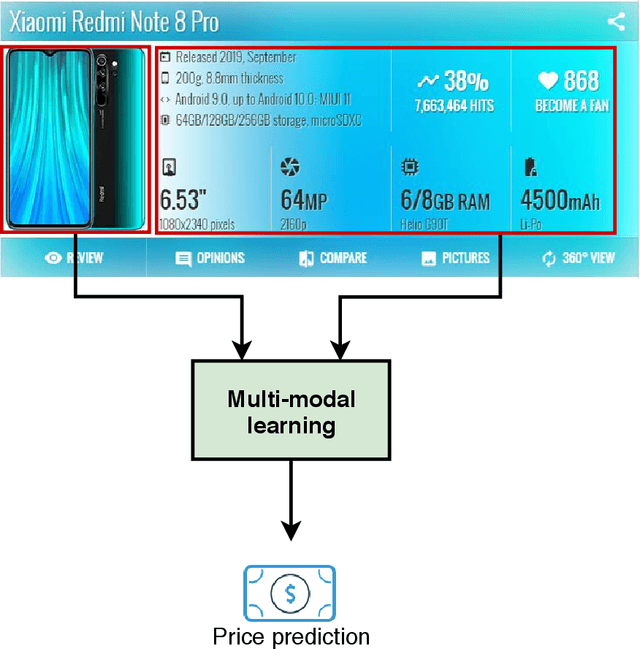

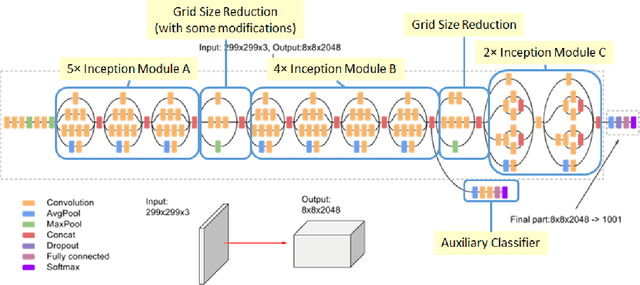
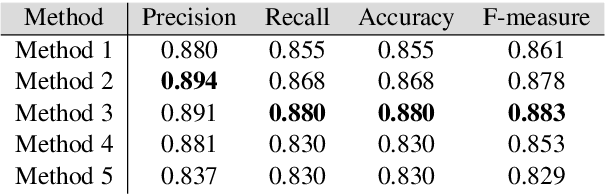
Valorization is one of the most heated discussions in the business community, and commodities valorization is one subset in this task. Features of a product is an essential characteristic in valorization and features are categorized into two classes: graphical and non-graphical. Nowadays, the value of products is measured by price. The goal of this research is to achieve an arrangement to predict the price of a product based on specifications of that. We propose five deep learning models to predict the price range of a product, one unimodal and four multimodal systems. The multimodal methods predict based on the image and non-graphical specification of product. As a platform to evaluate the methods, a cellphones dataset has been gathered from GSMArena. In proposed methods, convolutional neural network is an infrastructure. The experimental results show 88.3% F1-score in the best method.
AutoML for Multilayer Perceptron and FPGA Co-design
Sep 14, 2020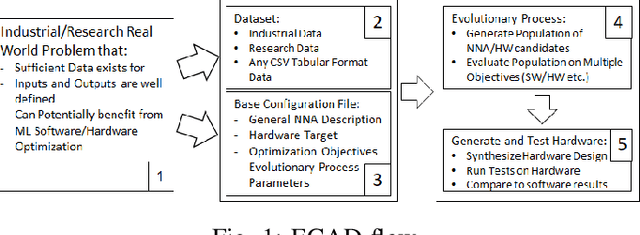
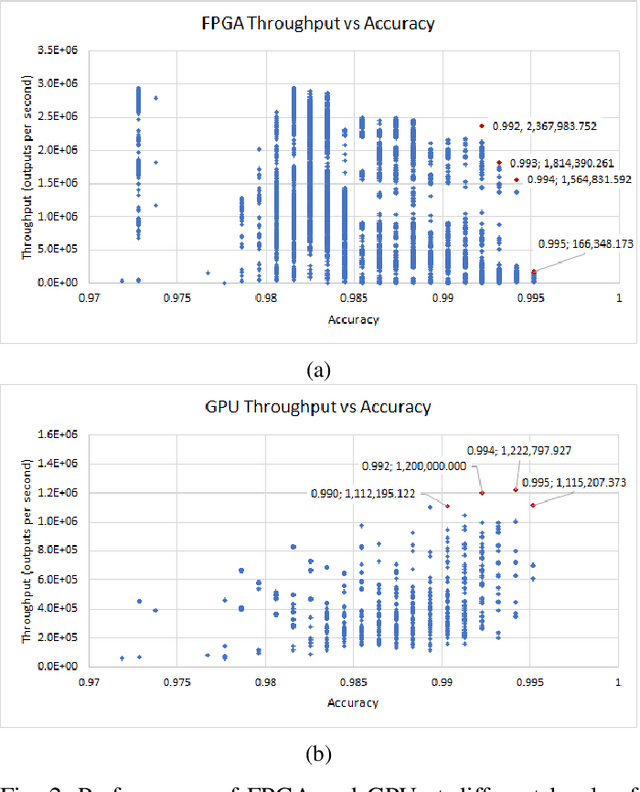
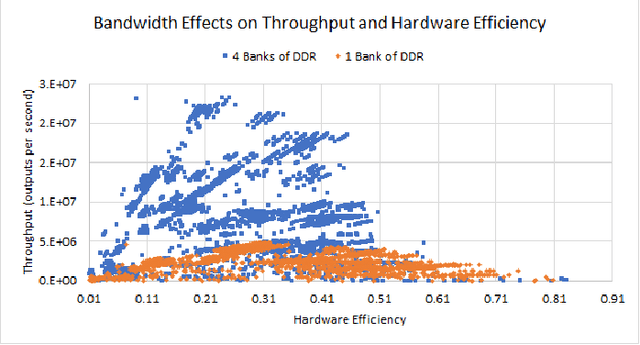
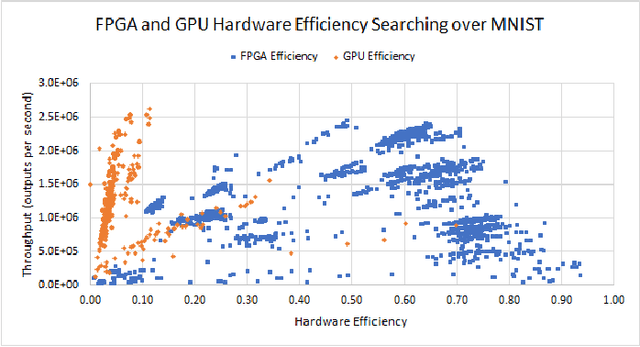
State-of-the-art Neural Network Architectures (NNAs) are challenging to design and implement efficiently in hardware. In the past couple of years, this has led to an explosion in research and development of automatic Neural Architecture Search (NAS) tools. AutomML tools are now used to achieve state of the art NNA designs and attempt to optimize for hardware usage and design. Much of the recent research in the auto-design of NNAs has focused on convolution networks and image recognition, ignoring the fact that a significant part of the workload in data centers is general-purpose deep neural networks. In this work, we develop and test a general multilayer perceptron (MLP) flow that can take arbitrary datasets as input and automatically produce optimized NNAs and hardware designs. We test the flow on six benchmarks. Our results show we exceed the performance of currently published MLP accuracy results and are competitive with non-MLP based results. We compare general and common GPU architectures with our scalable FPGA design and show we can achieve higher efficiency and higher throughput (outputs per second) for the majority of datasets. Further insights into the design space for both accurate networks and high performing hardware shows the power of co-design by correlating accuracy versus throughput, network size versus accuracy, and scaling to high-performance devices.
End-to-end Optimized Image Compression
Mar 03, 2017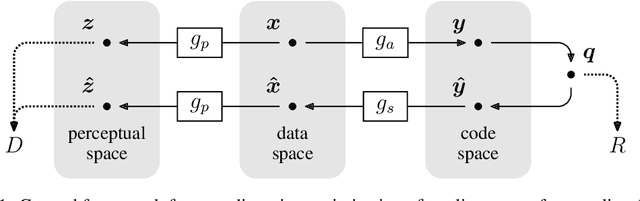
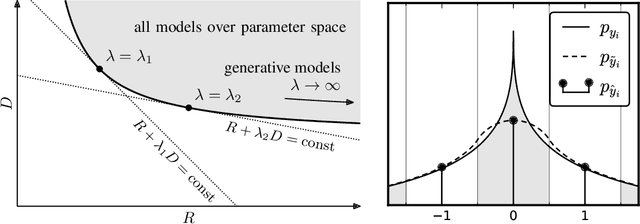
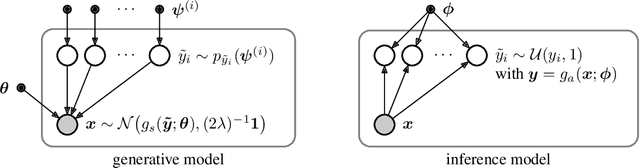
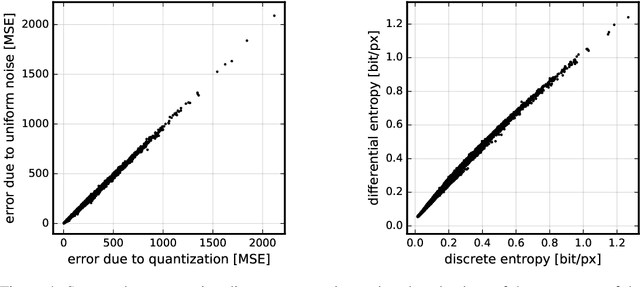
We describe an image compression method, consisting of a nonlinear analysis transformation, a uniform quantizer, and a nonlinear synthesis transformation. The transforms are constructed in three successive stages of convolutional linear filters and nonlinear activation functions. Unlike most convolutional neural networks, the joint nonlinearity is chosen to implement a form of local gain control, inspired by those used to model biological neurons. Using a variant of stochastic gradient descent, we jointly optimize the entire model for rate-distortion performance over a database of training images, introducing a continuous proxy for the discontinuous loss function arising from the quantizer. Under certain conditions, the relaxed loss function may be interpreted as the log likelihood of a generative model, as implemented by a variational autoencoder. Unlike these models, however, the compression model must operate at any given point along the rate-distortion curve, as specified by a trade-off parameter. Across an independent set of test images, we find that the optimized method generally exhibits better rate-distortion performance than the standard JPEG and JPEG 2000 compression methods. More importantly, we observe a dramatic improvement in visual quality for all images at all bit rates, which is supported by objective quality estimates using MS-SSIM.
Image Quality Assessment for Performance Evaluation of Focus Measure Operators
Apr 02, 2016
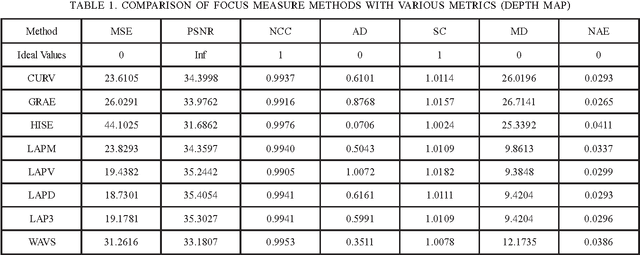
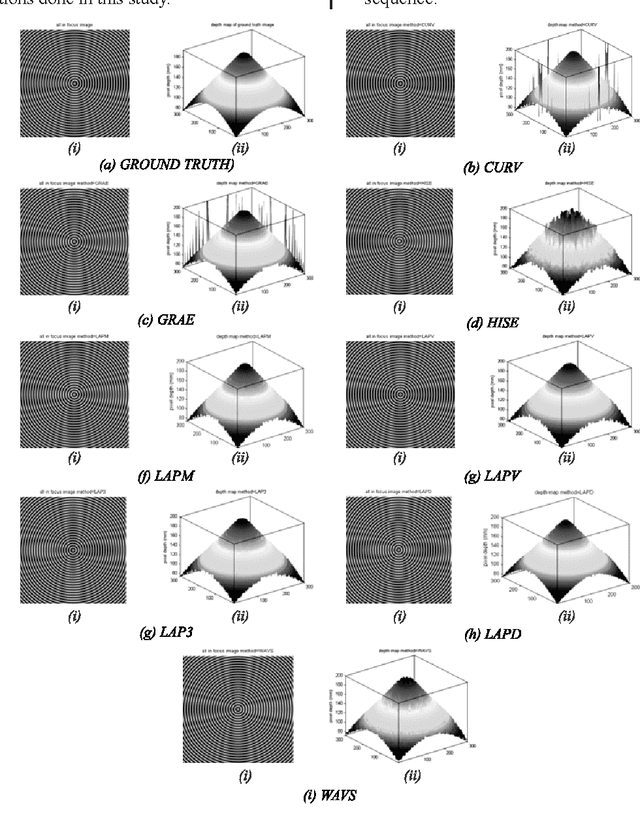
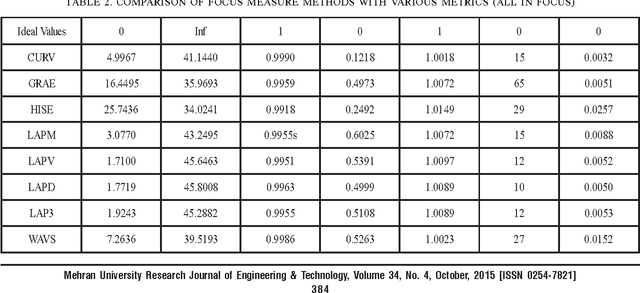
This paper presents the performance evaluation of eight focus measure operators namely Image CURV (Curvature), GRAE (Gradient Energy), HISE (Histogram Entropy), LAPM (Modified Laplacian), LAPV (Variance of Laplacian), LAPD (Diagonal Laplacian), LAP3 (Laplacian in 3D Window) and WAVS (Sum of Wavelet Coefficients). Statistical matrics such as MSE (Mean Squared Error), PNSR (Peak Signal to Noise Ratio), SC (Structural Content), NCC (Normalized Cross Correlation), MD (Maximum Difference) and NAE (Normalized Absolute Error) are used to evaluate stated focus measures in this research. . FR (Full Reference) method of the image quality assessment is utilized in this paper. Results indicate that LAPD method is comparatively better than other seven focus operators at typical imaging conditions.