 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Wardrobe: Compositional 3D Gaussian Avatars for Free-Form Virtual Try-On
Mar 05, 2026We introduce Gaussian Wardrobe, a novel framework to digitalize compositional 3D neural avatars from multi-view videos. Existing methods for 3D neural avatars typically treat the human body and clothing as an inseparable entity. However, this paradigm fails to capture the dynamics of complex free-form garments and limits the reuse of clothing across different individuals. To overcome these problems, we develop a novel, compositional 3D Gaussian representation to build avatars from multiple layers of free-form garments. The core of our method is decomposing neural avatars into bodies and layers of shape-agnostic neural garments. To achieve this, our framework learns to disentangle each garment layer from multi-view videos and canonicalizes it into a shape-independent space. In experiments, our method models photorealistic avatars with high-fidelity dynamics, achieving new state-of-the-art performance on novel pose synthesis benchmarks. In addition, we demonstrate that the learned compositional garments contribute to a versatile digital wardrobe, enabling a practical virtual try-on application where clothing can be freely transferred to new subjects. Project page: https://ait.ethz.ch/gaussianwardrobe
FireRed-Image-Edit-1.0 Techinical Report
Feb 12, 2026We present FireRed-Image-Edit, a diffusion transformer for instruction-based image editing that achieves state-of-the-art performance through systematic optimization of data curation, training methodology, and evaluation design. We construct a 1.6B-sample training corpus, comprising 900M text-to-image and 700M image editing pairs from diverse sources. After rigorous cleaning, stratification, auto-labeling, and two-stage filtering, we retain over 100M high-quality samples balanced between generation and editing, ensuring strong semantic coverage and instruction alignment. Our multi-stage training pipeline progressively builds editing capability via pre-training, supervised fine-tuning, and reinforcement learning. To improve data efficiency, we introduce a Multi-Condition Aware Bucket Sampler for variable-resolution batching and Stochastic Instruction Alignment with dynamic prompt re-indexing. To stabilize optimization and enhance controllability, we propose Asymmetric Gradient Optimization for DPO, DiffusionNFT with layout-aware OCR rewards for text editing, and a differentiable Consistency Loss for identity preservation. We further establish REDEdit-Bench, a comprehensive benchmark spanning 15 editing categories, including newly introduced beautification and low-level enhancement tasks. Extensive experiments on REDEdit-Bench and public benchmarks (ImgEdit and GEdit) demonstrate competitive or superior performance against both open-source and proprietary systems. We release code, models, and the benchmark suite to support future research.
Growth First, Care Second? Tracing the Landscape of LLM Value Preferences in Everyday Dilemmas
Feb 04, 2026People increasingly seek advice online from both human peers and large language model (LLM)-based chatbots. Such advice rarely involves identifying a single correct answer; instead, it typically requires navigating trade-offs among competing values. We aim to characterize how LLMs navigate value trade-offs across different advice-seeking contexts. First, we examine the value trade-off structure underlying advice seeking using a curated dataset from four advice-oriented subreddits. Using a bottom-up approach, we inductively construct a hierarchical value framework by aggregating fine-grained values extracted from individual advice options into higher-level value categories. We construct value co-occurrence networks to characterize how values co-occur within dilemmas and find substantial heterogeneity in value trade-off structures across advice-seeking contexts: a women-focused subreddit exhibits the highest network density, indicating more complex value conflicts; women's, men's, and friendship-related subreddits exhibit highly correlated value-conflict patterns centered on security-related tensions (security vs. respect/connection/commitment); by contrast, career advice forms a distinct structure where security frequently clashes with self-actualization and growth. We then evaluate LLM value preferences against these dilemmas and find that, across models and contexts, LLMs consistently prioritize values related to Exploration & Growth over Benevolence & Connection. This systemically skewed value orientation highlights a potential risk of value homogenization in AI-mediated advice, raising concerns about how such systems may shape decision-making and normative outcomes at scale.
Deep Koopman-based Control of Quality Variation in Multistage Manufacturing Systems
Jul 24, 2024



This paper presents a modeling-control synthesis to address the quality control challenges in multistage manufacturing systems (MMSs). A new feedforward control scheme is developed to minimize the quality variations caused by process disturbances in MMSs. Notably, the control framework leverages a stochastic deep Koopman (SDK) model to capture the quality propagation mechanism in the MMSs, highlighted by its ability to transform the nonlinear propagation dynamics into a linear one. Two roll-to-roll case studies are presented to validate the proposed method and demonstrate its effectiveness. The overall method is suitable for nonlinear MMSs and does not require extensive expert knowledge.
Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
Apr 02, 2024



Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
Stochastic Deep Koopman Model for Quality Propagation Analysis in Multistage Manufacturing Systems
Sep 18, 2023



The modeling of multistage manufacturing systems (MMSs) has attracted increased attention from both academia and industry. Recent advancements in deep learning methods provide an opportunity to accomplish this task with reduced cost and expertise. This study introduces a stochastic deep Koopman (SDK) framework to model the complex behavior of MMSs. Specifically, we present a novel application of Koopman operators to propagate critical quality information extracted by variational autoencoders. Through this framework, we can effectively capture the general nonlinear evolution of product quality using a transferred linear representation, thus enhancing the interpretability of the data-driven model. To evaluate the performance of the SDK framework, we carried out a comparative study on an open-source dataset. The main findings of this paper are as follows. Our results indicate that SDK surpasses other popular data-driven models in accuracy when predicting stagewise product quality within the MMS. Furthermore, the unique linear propagation property in the stochastic latent space of SDK enables traceability for quality evolution throughout the process, thereby facilitating the design of root cause analysis schemes. Notably, the proposed framework requires minimal knowledge of the underlying physics of production lines. It serves as a virtual metrology tool that can be applied to various MMSs, contributing to the ultimate goal of Zero Defect Manufacturing.
DiffPrep: Differentiable Data Preprocessing Pipeline Search for Learning over Tabular Data
Aug 20, 2023



Data preprocessing is a crucial step in the machine learning process that transforms raw data into a more usable format for downstream ML models. However, it can be costly and time-consuming, often requiring the expertise of domain experts. Existing automated machine learning (AutoML) frameworks claim to automate data preprocessing. However, they often use a restricted search space of data preprocessing pipelines which limits the potential performance gains, and they are often too slow as they require training the ML model multiple times. In this paper, we propose DiffPrep, a method that can automatically and efficiently search for a data preprocessing pipeline for a given tabular dataset and a differentiable ML model such that the performance of the ML model is maximized. We formalize the problem of data preprocessing pipeline search as a bi-level optimization problem. To solve this problem efficiently, we transform and relax the discrete, non-differential search space into a continuous and differentiable one, which allows us to perform the pipeline search using gradient descent with training the ML model only once. Our experiments show that DiffPrep achieves the best test accuracy on 15 out of the 18 real-world datasets evaluated and improves the model's test accuracy by up to 6.6 percentage points.
* Published at SIGMOD 2023
Principal Gradient Direction and Confidence Reservoir Sampling for Continual Learning
Aug 21, 2021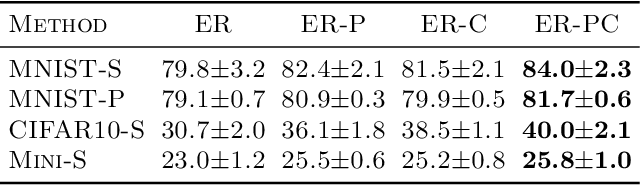

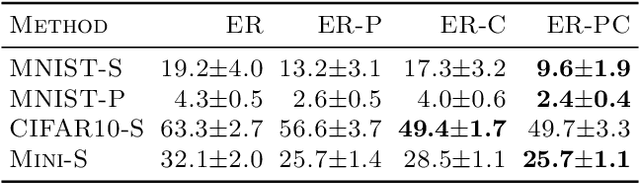
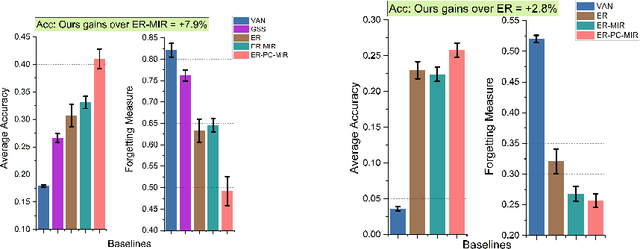
Task-free online continual learning aims to alleviate catastrophic forgetting of the learner on a non-iid data stream. Experience Replay (ER) is a SOTA continual learning method, which is broadly used as the backbone algorithm for other replay-based methods. However, the training strategy of ER is too simple to take full advantage of replayed examples and its reservoir sampling strategy is also suboptimal. In this work, we propose a general proximal gradient framework so that ER can be viewed as a special case. We further propose two improvements accordingly: Principal Gradient Direction (PGD) and Confidence Reservoir Sampling (CRS). In Principal Gradient Direction, we optimize a target gradient that not only represents the major contribution of past gradients, but also retains the new knowledge of the current gradient. We then present Confidence Reservoir Sampling for maintaining a more informative memory buffer based on a margin-based metric that measures the value of stored examples. Experiments substantiate the effectiveness of both our improvements and our new algorithm consistently boosts the performance of MIR-replay, a SOTA ER-based method: our algorithm increases the average accuracy up to 7.9% and reduces forgetting up to 15.4% on four datasets.
Contrastive Rendering for Ultrasound Image Segmentation
Oct 10, 2020
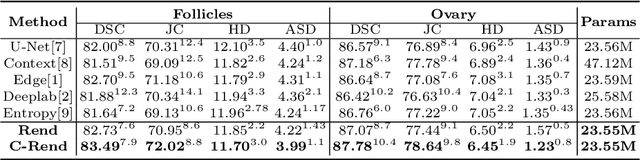
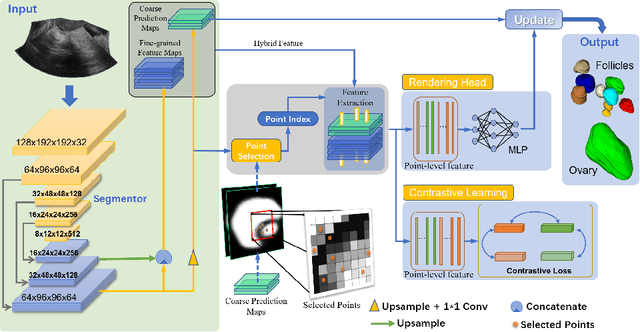
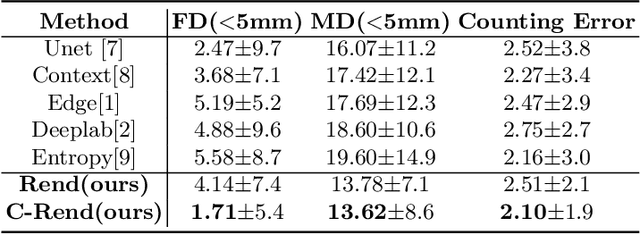
Ultrasound (US) image segmentation embraced its significant improvement in deep learning era. However, the lack of sharp boundaries in US images still remains an inherent challenge for segmentation. Previous methods often resort to global context, multi-scale cues or auxiliary guidance to estimate the boundaries. It is hard for these methods to approach pixel-level learning for fine-grained boundary generating. In this paper, we propose a novel and effective framework to improve boundary estimation in US images. Our work has three highlights. First, we propose to formulate the boundary estimation as a rendering task, which can recognize ambiguous points (pixels/voxels) and calibrate the boundary prediction via enriched feature representation learning. Second, we introduce point-wise contrastive learning to enhance the similarity of points from the same class and contrastively decrease the similarity of points from different classes. Boundary ambiguities are therefore further addressed. Third, both rendering and contrastive learning tasks contribute to consistent improvement while reducing network parameters. As a proof-of-concept, we performed validation experiments on a challenging dataset of 86 ovarian US volumes. Results show that our proposed method outperforms state-of-the-art methods and has the potential to be used in clinical practice.
Synthesis and Edition of Ultrasound Images via Sketch Guided Progressive Growing GANs
Apr 01, 2020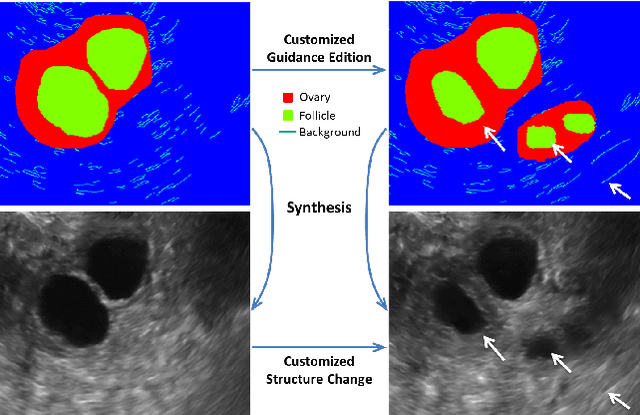
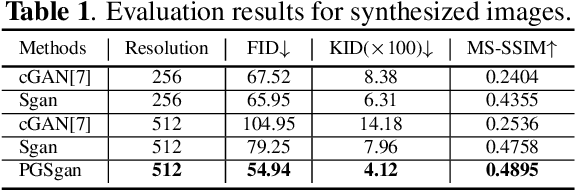
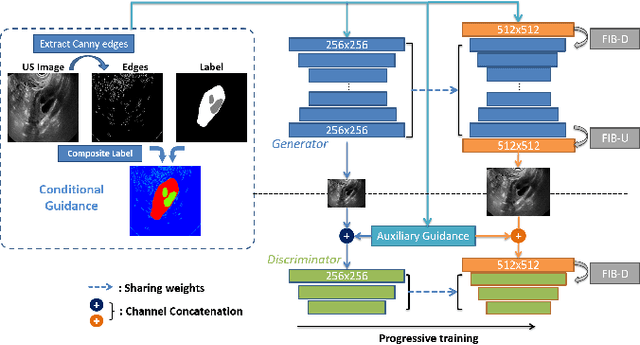
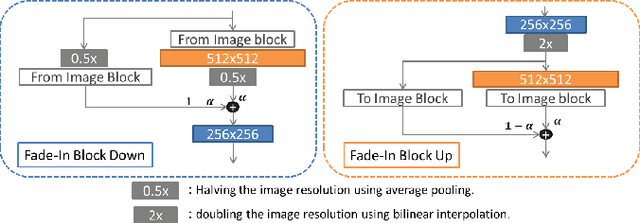
Ultrasound (US) is widely accepted in clinic for anatomical structure inspection. However, lacking in resources to practice US scan, novices often struggle to learn the operation skills. Also, in the deep learning era, automated US image analysis is limited by the lack of annotated samples. Efficiently synthesizing realistic, editable and high resolution US images can solve the problems. The task is challenging and previous methods can only partially complete it. In this paper, we devise a new framework for US image synthesis. Particularly, we firstly adopt a sketch generative adversarial networks (Sgan) to introduce background sketch upon object mask in a conditioned generative adversarial network. With enriched sketch cues, Sgan can generate realistic US images with editable and fine-grained structure details. Although effective, Sgan is hard to generate high resolution US images. To achieve this, we further implant the Sgan into a progressive growing scheme (PGSgan). By smoothly growing both generator and discriminator, PGSgan can gradually synthesize US images from low to high resolution. By synthesizing ovary and follicle US images, our extensive perceptual evaluation, user study and segmentation results prove the promising efficacy and efficiency of the proposed PGSgan.