 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning AI Data Centers into Grid-Interactive Assets: Results from a Field Demonstration in Phoenix, Arizona
Jul 01, 2025



Artificial intelligence (AI) is fueling exponential electricity demand growth, threatening grid reliability, raising prices for communities paying for new energy infrastructure, and stunting AI innovation as data centers wait for interconnection to constrained grids. This paper presents the first field demonstration, in collaboration with major corporate partners, of a software-only approach--Emerald Conductor--that transforms AI data centers into flexible grid resources that can efficiently and immediately harness existing power systems without massive infrastructure buildout. Conducted at a 256-GPU cluster running representative AI workloads within a commercial, hyperscale cloud data center in Phoenix, Arizona, the trial achieved a 25% reduction in cluster power usage for three hours during peak grid events while maintaining AI quality of service (QoS) guarantees. By orchestrating AI workloads based on real-time grid signals without hardware modifications or energy storage, this platform reimagines data centers as grid-interactive assets that enhance grid reliability, advance affordability, and accelerate AI's development.
AutoML for Multilayer Perceptron and FPGA Co-design
Sep 14, 2020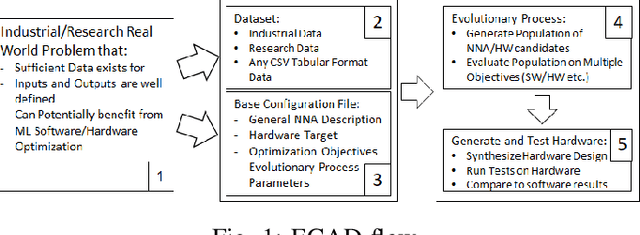
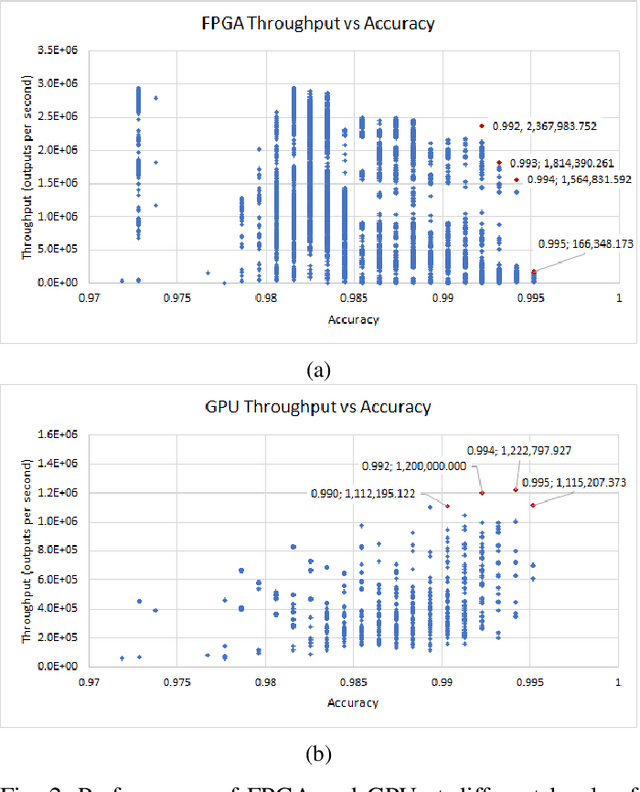
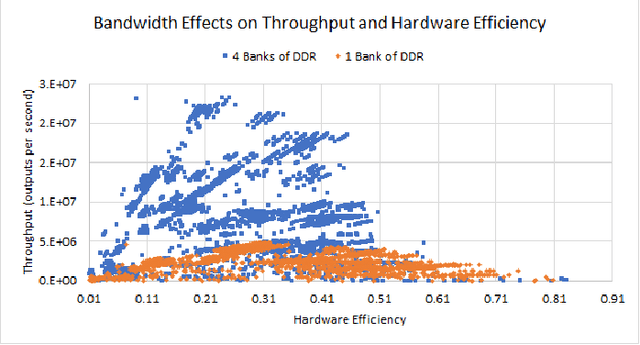
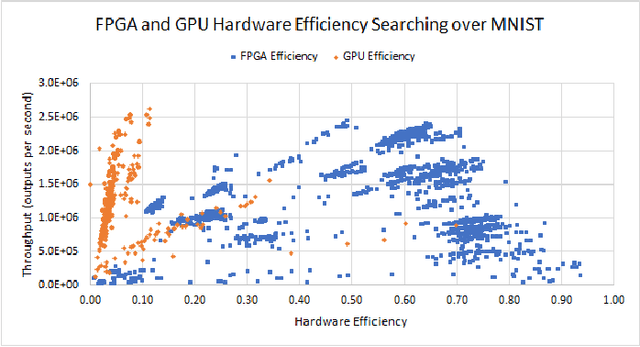
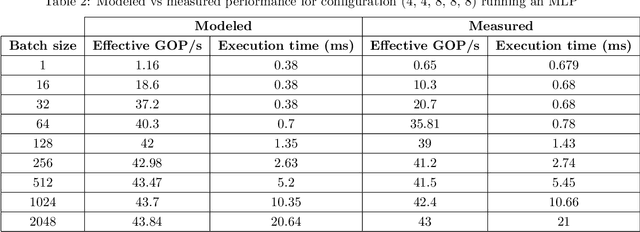
State-of-the-art Neural Network Architectures (NNAs) are challenging to design and implement efficiently in hardware. In the past couple of years, this has led to an explosion in research and development of automatic Neural Architecture Search (NAS) tools. AutomML tools are now used to achieve state of the art NNA designs and attempt to optimize for hardware usage and design. Much of the recent research in the auto-design of NNAs has focused on convolution networks and image recognition, ignoring the fact that a significant part of the workload in data centers is general-purpose deep neural networks. In this work, we develop and test a general multilayer perceptron (MLP) flow that can take arbitrary datasets as input and automatically produce optimized NNAs and hardware designs. We test the flow on six benchmarks. Our results show we exceed the performance of currently published MLP accuracy results and are competitive with non-MLP based results. We compare general and common GPU architectures with our scalable FPGA design and show we can achieve higher efficiency and higher throughput (outputs per second) for the majority of datasets. Further insights into the design space for both accurate networks and high performing hardware shows the power of co-design by correlating accuracy versus throughput, network size versus accuracy, and scaling to high-performance devices.
Evolutionary Cell Aided Design for Neural Network Architectures
Mar 11, 2019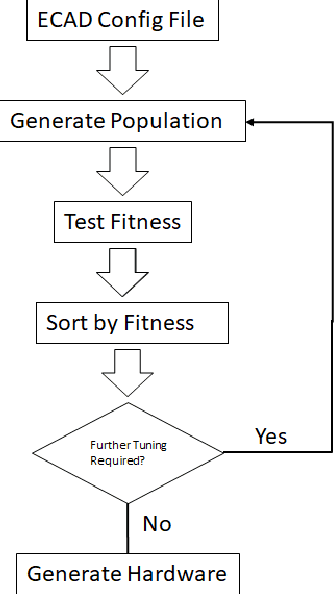

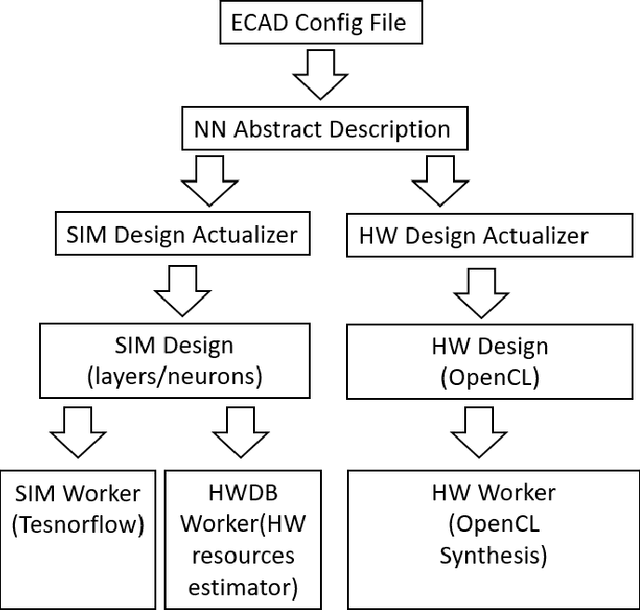
Mathematical theory shows us that multilayer feedforward Artificial Neural Networks(ANNs) are universal function approximators, capable of approximating any measurable function to any desired degree of accuracy. In practice designing practical and efficient neural network architectures require significant effort and expertise. We present a new software framework called Evolutionary Cell Aided Design(ECAD) meant to aid in the exploration and design of Neural Network Architectures(NNAs) for reconfigurable hardware. The framework uses evolutionary algorithms to search for efficient hardware architectures. Given a general structure, a set of constraints and fitness functions, the framework will explore the space of hardware solutions and attempt to find the fittest solutions.