 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeepLesion: Automated Deep Mining, Categorization and Detection of Significant Radiology Image Findings using Large-Scale Clinical Lesion Annotations
Oct 10, 2017
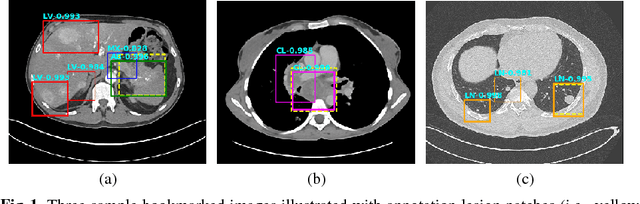
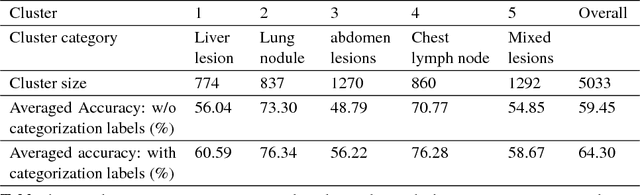
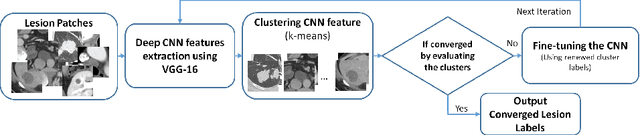
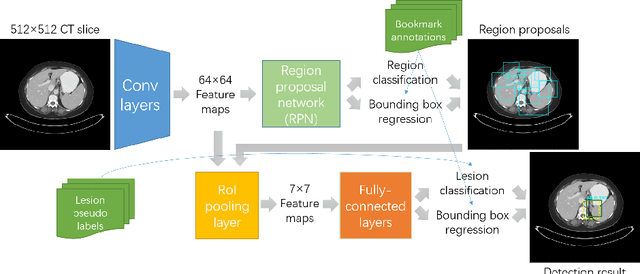
Extracting, harvesting and building large-scale annotated radiological image datasets is a greatly important yet challenging problem. It is also the bottleneck to designing more effective data-hungry computing paradigms (e.g., deep learning) for medical image analysis. Yet, vast amounts of clinical annotations (usually associated with disease image findings and marked using arrows, lines, lesion diameters, segmentation, etc.) have been collected over several decades and stored in hospitals' Picture Archiving and Communication Systems. In this paper, we mine and harvest one major type of clinical annotation data - lesion diameters annotated on bookmarked images - to learn an effective multi-class lesion detector via unsupervised and supervised deep Convolutional Neural Networks (CNN). Our dataset is composed of 33,688 bookmarked radiology images from 10,825 studies of 4,477 unique patients. For every bookmarked image, a bounding box is created to cover the target lesion based on its measured diameters. We categorize the collection of lesions using an unsupervised deep mining scheme to generate clustered pseudo lesion labels. Next, we adopt a regional-CNN method to detect lesions of multiple categories, regardless of missing annotations (normally only one lesion is annotated, despite the presence of multiple co-existing findings). Our integrated mining, categorization and detection framework is validated with promising empirical results, as a scalable, universal or multi-purpose CAD paradigm built upon abundant retrospective medical data. Furthermore, we demonstrate that detection accuracy can be significantly improved by incorporating pseudo lesion labels (e.g., Liver lesion/tumor, Lung nodule/tumor, Abdomen lesions, Chest lymph node and others). This dataset will be made publicly available (under the open science initiative).
Improving Convergence for Nonconvex Composite Programming
Sep 22, 2020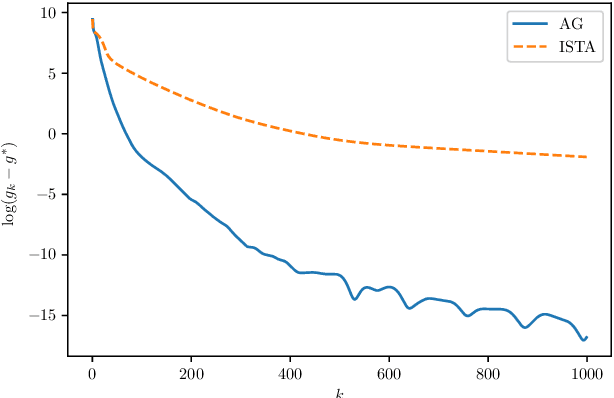
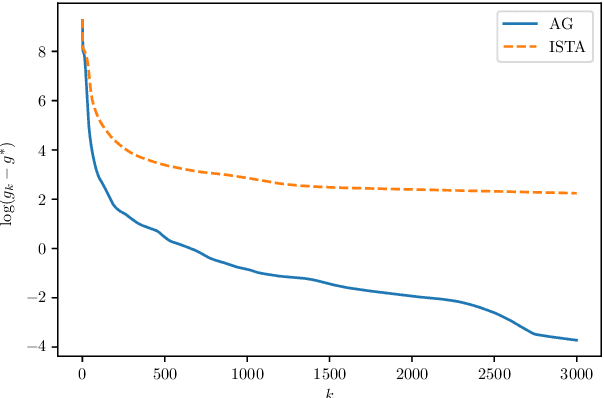
High-dimensional nonconvex problems are popular in today's machine learning and statistical genetics research. Recently, Ghadimi and Lan \cite{Ghadimi} proposed an algorithm to optimize nonconvex high-dimensional problems. There are several parameters in their algorithm that are to be set before running the algorithm. It is not trivial how to choose these parameters nor there is, to the best of our knowledge, an explicit rule how to select the parameters to make the algorithm converges faster. We analyze Ghadimi and Lan's algorithm to gain an interpretation based on the inequality constraints for convergence and the upper bound for the norm of the gradient analogue. Our interpretation of their algorithm suggests this to be a damped Nesterov's acceleration scheme. Based on this, we propose an approach on how to select the parameters to improve convergence of the algorithm. Our numerical studies using high-dimensional nonconvex sparse learning problems, motivated by image denoising and statistical genetics applications, show that convergence can be made, on average, considerably faster than that of the conventional ISTA algorithm for such optimization problems with over $10000$ variables should the parameters be chosen using our proposed approach.
Learning Controllable Disentangled Representations with Decorrelation Regularization
Dec 25, 2019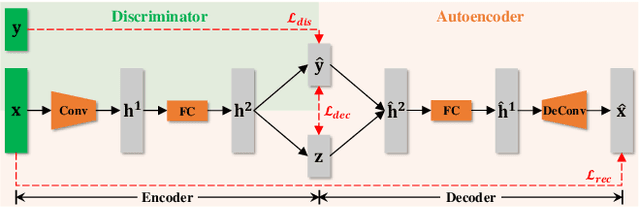
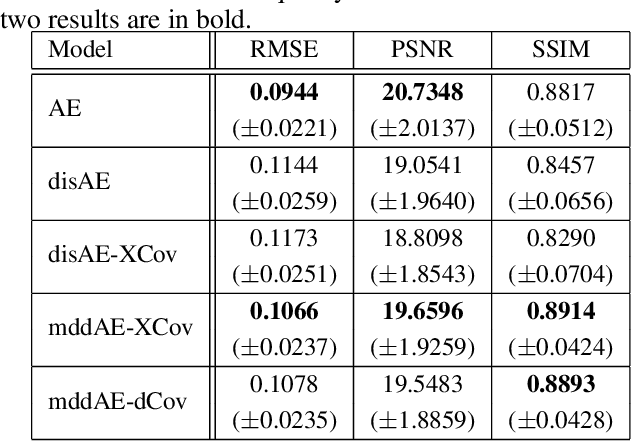
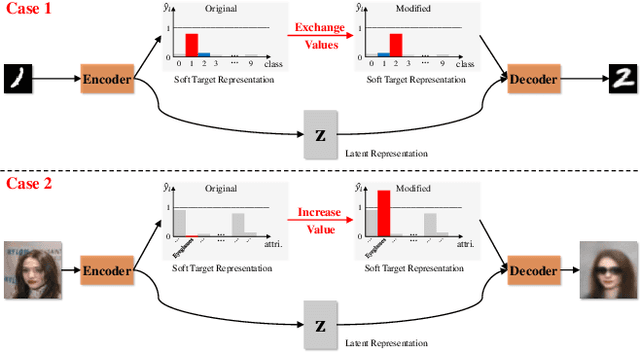
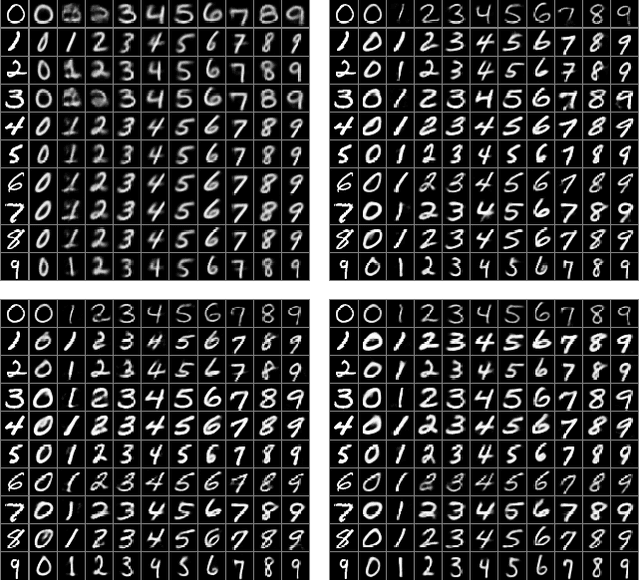
A crucial problem in learning disentangled image representations is controlling the degree of disentanglement during image editing, while preserving the identity of objects. In this work, we propose a simple yet effective model with the encoder-decoder architecture to address this challenge. To encourage disentanglement, we devise a distance covariance based decorrelation regularization. Further, for the reconstruction step, our model leverages a soft target representation combined with the latent image code. By exploiting the real-valued space of the soft target representations, we are able to synthesize novel images with the designated properties. We also design a classification based protocol to quantitatively evaluate the disentanglement strength of our model. Experimental results show that the proposed model competently disentangles factors of variation, and is able to manipulate face images to synthesize the desired attributes.
Adapting Grad-CAM for Embedding Networks
Jan 17, 2020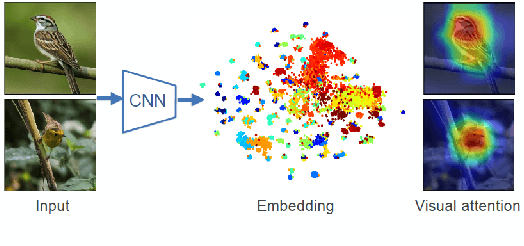

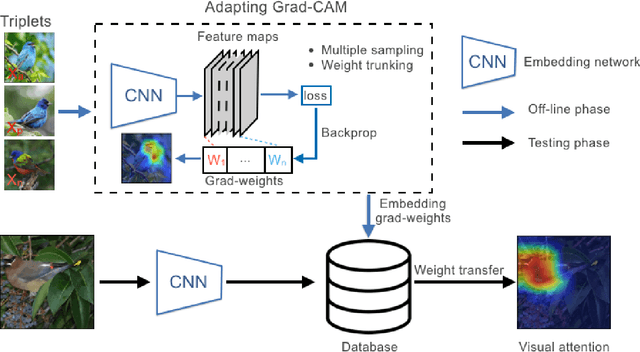
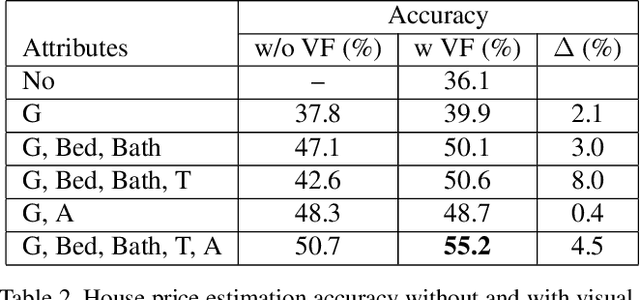
The gradient-weighted class activation mapping (Grad-CAM) method can faithfully highlight important regions in images for deep model prediction in image classification, image captioning and many other tasks. It uses the gradients in back-propagation as weights (grad-weights) to explain network decisions. However, applying Grad-CAM to embedding networks raises significant challenges because embedding networks are trained by millions of dynamically paired examples (e.g. triplets). To overcome these challenges, we propose an adaptation of the Grad-CAM method for embedding networks. First, we aggregate grad-weights from multiple training examples to improve the stability of Grad-CAM. Then, we develop an efficient weight-transfer method to explain decisions for any image without back-propagation. We extensively validate the method on the standard CUB200 dataset in which our method produces more accurate visual attention than the original Grad-CAM method. We also apply the method to a house price estimation application using images. The method produces convincing qualitative results, showcasing the practicality of our approach.
Variational Denoising Network: Toward Blind Noise Modeling and Removal
Aug 29, 2019
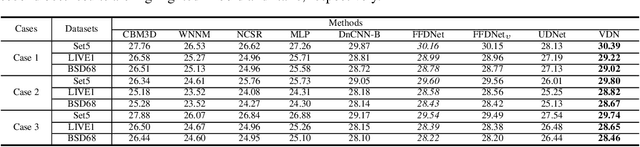
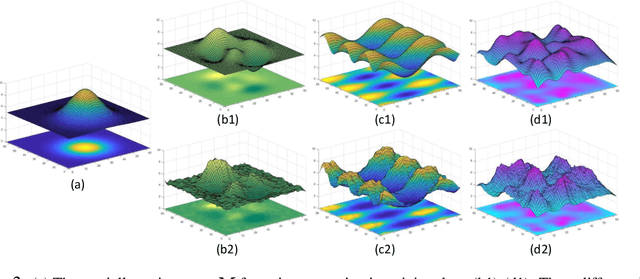
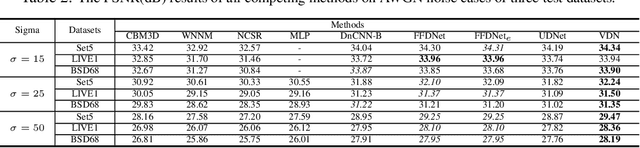
Blind image denoising is an important yet very challenging problem in computer vision due to the complicated acquisition process of real images. In this work we propose a new variational inference method, which integrates both noise estimation and image denoising into a unique Bayesian framework, for blind image denoising. Specifically, an approximate posterior, parameterized by deep neural networks, is presented by taking the intrinsic clean image and noise variances as latent variables conditioned on the input noisy image. This posterior provides explicit parametric forms for all its involved hyper-parameters, and thus can be easily implemented for blind image denoising with automatic noise estimation for the test noisy image. On one hand, as other data-driven deep learning methods, our method, namely variational denoising network (VDN), can perform denoising efficiently due to its explicit form of posterior expression. On the other hand, VDN inherits the advantages of traditional model-driven approaches, especially the good generalization capability of generative models. VDN has good interpretability and can be flexibly utilized to estimate and remove complicated non-i.i.d. noise collected in real scenarios. Comprehensive experiments are performed to substantiate the superiority of our method in blind image denoising.
Denoising and Regularization via Exploiting the Structural Bias of Convolutional Generators
Oct 31, 2019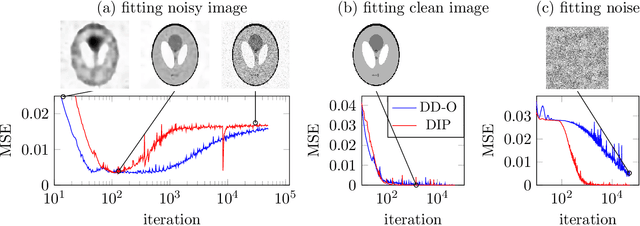


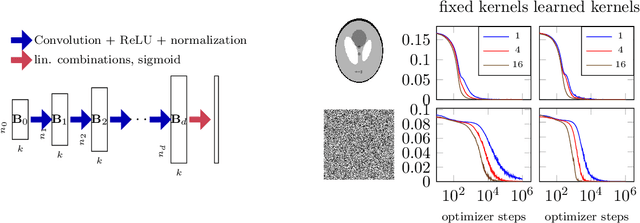
Convolutional Neural Networks (CNNs) have emerged as highly successful tools for image generation, recovery, and restoration. This success is often attributed to large amounts of training data. However, recent experimental findings challenge this view and instead suggest that a major contributing factor to this success is that convolutional networks impose strong prior assumptions about natural images. A surprising experiment that highlights this architectural bias towards natural images is that one can remove noise and corruptions from a natural image without using any training data, by simply fitting (via gradient descent) a randomly initialized, over-parameterized convolutional generator to the single corrupted image. While this over-parameterized network can fit the corrupted image perfectly, surprisingly after a few iterations of gradient descent one obtains the uncorrupted image. This intriguing phenomenon enables state-of-the-art CNN-based denoising and regularization of linear inverse problems such as compressive sensing. In this paper, we take a step towards demystifying this experimental phenomenon by attributing this effect to particular architectural choices of convolutional networks, namely convolutions with fixed interpolating filters. We then formally characterize the dynamics of fitting a two-layer convolutional generator to a noisy signal and prove that early-stopped gradient descent denoises/regularizes. This result relies on showing that convolutional generators fit the structured part of an image significantly faster than the corrupted portion.
Deep Convolutional Neural Network Features and the Original Image
Nov 06, 2016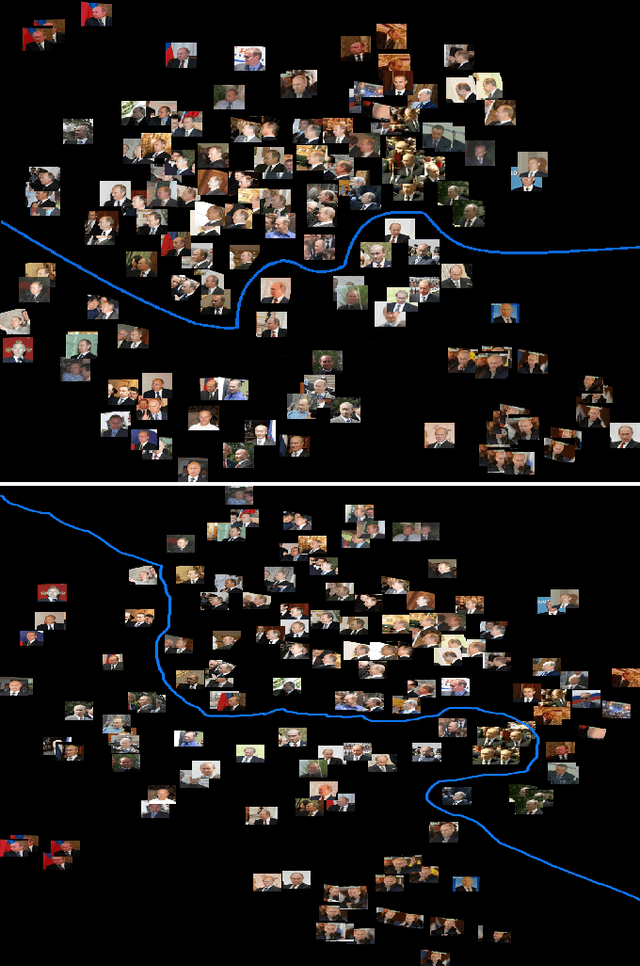
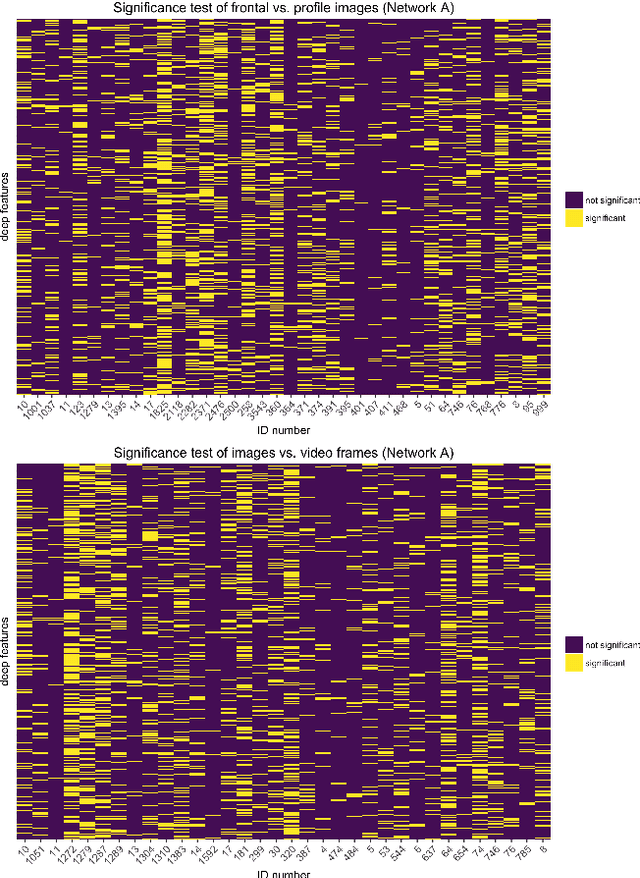


Face recognition algorithms based on deep convolutional neural networks (DCNNs) have made progress on the task of recognizing faces in unconstrained viewing conditions. These networks operate with compact feature-based face representations derived from learning a very large number of face images. While the learned features produced by DCNNs can be highly robust to changes in viewpoint, illumination, and appearance, little is known about the nature of the face code that emerges at the top level of such networks. We analyzed the DCNN features produced by two face recognition algorithms. In the first set of experiments we used the top-level features from the DCNNs as input into linear classifiers aimed at predicting metadata about the images. The results show that the DCNN features contain surprisingly accurate information about the yaw and pitch of a face, and about whether the face came from a still image or a video frame. In the second set of experiments, we measured the extent to which individual DCNN features operated in a view-dependent or view-invariant manner. We found that view-dependent coding was a characteristic of the identities rather than the DCNN features - with some identities coded consistently in a view-dependent way and others in a view-independent way. In our third analysis, we visualized the DCNN feature space for over 24,000 images of 500 identities. Images in the center of the space were uniformly of low quality (e.g., extreme views, face occlusion, low resolution). Image quality increased monotonically as a function of distance from the origin. This result suggests that image quality information is available in the DCNN features, such that consistently average feature values reflect coding failures that reliably indicate poor or unusable images. Combined, the results offer insight into the coding mechanisms that support robust representation of faces in DCNNs.
Improving One-stage Visual Grounding by Recursive Sub-query Construction
Aug 03, 2020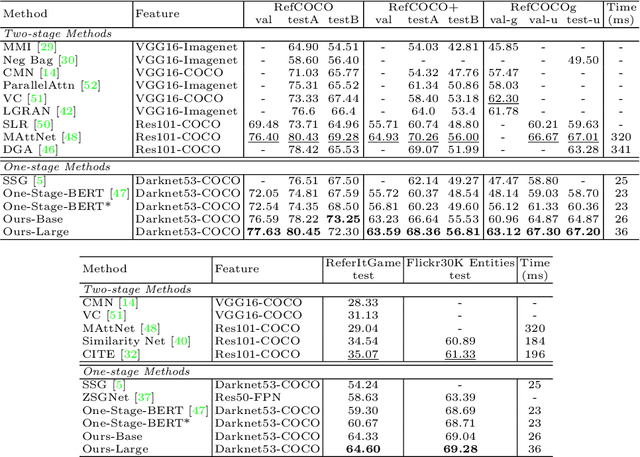

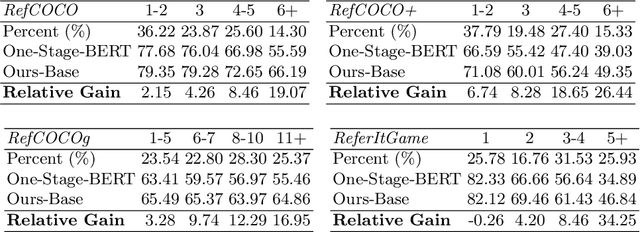
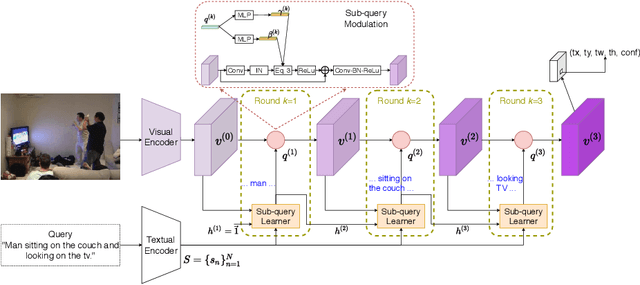
We improve one-stage visual grounding by addressing current limitations on grounding long and complex queries. Existing one-stage methods encode the entire language query as a single sentence embedding vector, e.g., taking the embedding from BERT or the hidden state from LSTM. This single vector representation is prone to overlooking the detailed descriptions in the query. To address this query modeling deficiency, we propose a recursive sub-query construction framework, which reasons between image and query for multiple rounds and reduces the referring ambiguity step by step. We show our new one-stage method obtains 5.0%, 4.5%, 7.5%, 12.8% absolute improvements over the state-of-the-art one-stage baseline on ReferItGame, RefCOCO, RefCOCO+, and RefCOCOg, respectively. In particular, superior performances on longer and more complex queries validates the effectiveness of our query modeling.
Learned Greedy Method (LGM): A Novel Neural Architecture for Sparse Coding and Beyond
Oct 14, 2020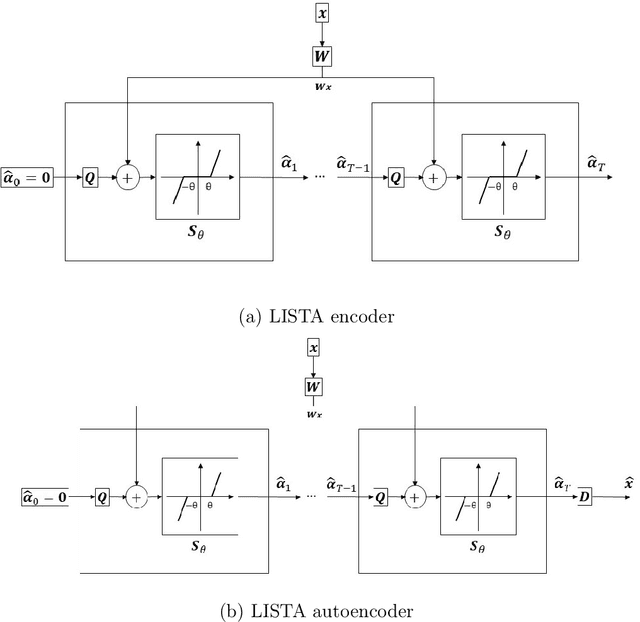
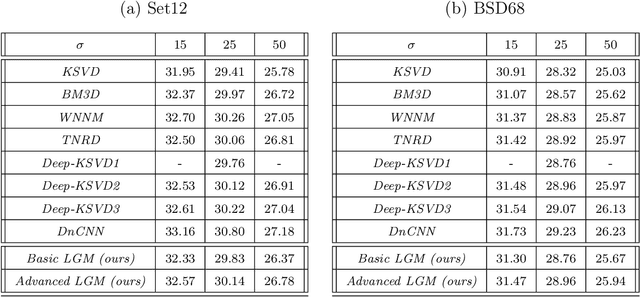
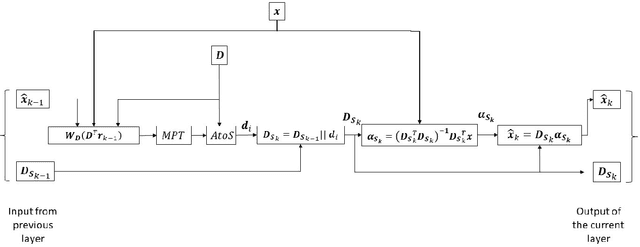
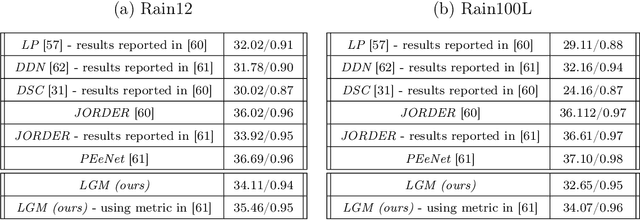
The fields of signal and image processing have been deeply influenced by the introduction of deep neural networks. These are successfully deployed in a wide range of real-world applications, obtaining state of the art results and surpassing well-known and well-established classical methods. Despite their impressive success, the architectures used in many of these neural networks come with no clear justification. As such, these are usually treated as "black box" machines that lack any kind of interpretability. A constructive remedy to this drawback is a systematic design of such networks by unfolding well-understood iterative algorithms. A popular representative of this approach is the Iterative Shrinkage-Thresholding Algorithm (ISTA) and its learned version -- LISTA, aiming for the sparse representations of the processed signals. In this paper we revisit this sparse coding task and propose an unfolded version of a greedy pursuit algorithm for the same goal. More specifically, we concentrate on the well-known Orthogonal-Matching-Pursuit (OMP) algorithm, and introduce its unfolded and learned version. Key features of our Learned Greedy Method (LGM) are the ability to accommodate a dynamic number of unfolded layers, and a stopping mechanism based on representation error, both adapted to the input. We develop several variants of the proposed LGM architecture and test some of them in various experiments, demonstrating their flexibility and efficiency.
Simultaneous Enhancement and Super-Resolution of Underwater Imagery for Improved Visual Perception
Feb 04, 2020


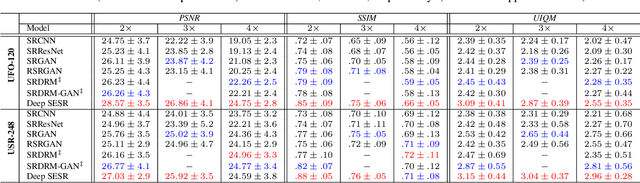
In this paper, we introduce and tackle the simultaneous enhancement and super-resolution (SESR) problem for underwater robot vision and provide an efficient solution for near real-time applications. We present Deep SESR, a residual-in-residual network-based generative model that can learn to restore perceptual image qualities at 2x, 3x, or 4x higher spatial resolution. We supervise its training by formulating a multi-modal objective function that addresses the chrominance-specific underwater color degradation, lack of image sharpness, and loss in high-level feature representation. It is also supervised to learn salient foreground regions in the image, which in turn guides the network to learn global contrast enhancement. We design an end-to-end training pipeline to jointly learn the saliency prediction and SESR on a shared hierarchical feature space for fast inference. Moreover, we present UFO-120, the first dataset to facilitate large-scale SESR learning; it contains over 1500 training samples and a benchmark test set of 120 samples. By thorough experimental evaluation on the UFO-120 and other standard datasets, we demonstrate that Deep SESR outperforms the existing solutions for underwater image enhancement and super-resolution. We also validate its generalization performance on several test cases that include underwater images with diverse spectral and spatial degradation levels, and also terrestrial images with unseen natural objects. Lastly, we analyze its computational feasibility for single-board deployments and demonstrate its operational benefits for visually-guided underwater robots. The model and dataset information will be available at: https://github.com/xahidbuffon/Deep-SESR.