 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding The Calibration Benefits of Sharpness-Aware Minimization
May 29, 2025Deep neural networks have been increasingly used in safety-critical applications such as medical diagnosis and autonomous driving. However, many studies suggest that they are prone to being poorly calibrated and have a propensity for overconfidence, which may have disastrous consequences. In this paper, unlike standard training such as stochastic gradient descent, we show that the recently proposed sharpness-aware minimization (SAM) counteracts this tendency towards overconfidence. The theoretical analysis suggests that SAM allows us to learn models that are already well-calibrated by implicitly maximizing the entropy of the predictive distribution. Inspired by this finding, we further propose a variant of SAM, coined as CSAM, to ameliorate model calibration. Extensive experiments on various datasets, including ImageNet-1K, demonstrate the benefits of SAM in reducing calibration error. Meanwhile, CSAM performs even better than SAM and consistently achieves lower calibration error than other approaches
Polar R-CNN: End-to-End Lane Detection with Fewer Anchors
Nov 03, 2024



Lane detection is a critical and challenging task in autonomous driving, particularly in real-world scenarios where traffic lanes can be slender, lengthy, and often obscured by other vehicles, complicating detection efforts. Existing anchor-based methods typically rely on prior lane anchors to extract features and subsequently refine the location and shape of lanes. While these methods achieve high performance, manually setting prior anchors is cumbersome, and ensuring sufficient coverage across diverse datasets often requires a large amount of dense anchors. Furthermore, the use of Non-Maximum Suppression (NMS) to eliminate redundant predictions complicates real-world deployment and may underperform in complex scenarios. In this paper, we propose Polar R-CNN, an end-to-end anchor-based method for lane detection. By incorporating both local and global polar coordinate systems, Polar R-CNN facilitates flexible anchor proposals and significantly reduces the number of anchors required without compromising performance.Additionally, we introduce a triplet head with heuristic structure that supports NMS-free paradigm, enhancing deployment efficiency and performance in scenarios with dense lanes.Our method achieves competitive results on five popular lane detection benchmarks--Tusimple, CULane,LLAMAS, CurveLanes, and DL-Rai--while maintaining a lightweight design and straightforward structure. Our source code is available at https://github.com/ShqWW/PolarRCNN.
Enhancing Sound Source Localization via False Negative Elimination
Aug 29, 2024



Sound source localization aims to localize objects emitting the sound in visual scenes. Recent works obtaining impressive results typically rely on contrastive learning. However, the common practice of randomly sampling negatives in prior arts can lead to the false negative issue, where the sounds semantically similar to visual instance are sampled as negatives and incorrectly pushed away from the visual anchor/query. As a result, this misalignment of audio and visual features could yield inferior performance. To address this issue, we propose a novel audio-visual learning framework which is instantiated with two individual learning schemes: self-supervised predictive learning (SSPL) and semantic-aware contrastive learning (SACL). SSPL explores image-audio positive pairs alone to discover semantically coherent similarities between audio and visual features, while a predictive coding module for feature alignment is introduced to facilitate the positive-only learning. In this regard SSPL acts as a negative-free method to eliminate false negatives. By contrast, SACL is designed to compact visual features and remove false negatives, providing reliable visual anchor and audio negatives for contrast. Different from SSPL, SACL releases the potential of audio-visual contrastive learning, offering an effective alternative to achieve the same goal. Comprehensive experiments demonstrate the superiority of our approach over the state-of-the-arts. Furthermore, we highlight the versatility of the learned representation by extending the approach to audio-visual event classification and object detection tasks. Code and models are available at: https://github.com/zjsong/SACL.
Visually-Guided Sound Source Separation with Audio-Visual Predictive Coding
Jun 19, 2023The framework of visually-guided sound source separation generally consists of three parts: visual feature extraction, multimodal feature fusion, and sound signal processing. An ongoing trend in this field has been to tailor involved visual feature extractor for informative visual guidance and separately devise module for feature fusion, while utilizing U-Net by default for sound analysis. However, such divide-and-conquer paradigm is parameter inefficient and, meanwhile, may obtain suboptimal performance as jointly optimizing and harmonizing various model components is challengeable. By contrast, this paper presents a novel approach, dubbed audio-visual predictive coding (AVPC), to tackle this task in a parameter efficient and more effective manner. The network of AVPC features a simple ResNet-based video analysis network for deriving semantic visual features, and a predictive coding-based sound separation network that can extract audio features, fuse multimodal information, and predict sound separation masks in the same architecture. By iteratively minimizing the prediction error between features, AVPC integrates audio and visual information recursively, leading to progressively improved performance. In addition, we develop a valid self-supervised learning strategy for AVPC via co-predicting two audio-visual representations of the same sound source. Extensive evaluations demonstrate that AVPC outperforms several baselines in separating musical instrument sounds, while reducing the model size significantly. Code is available at: https://github.com/zjsong/Audio-Visual-Predictive-Coding.
Self-Supervised Predictive Learning: A Negative-Free Method for Sound Source Localization in Visual Scenes
Mar 25, 2022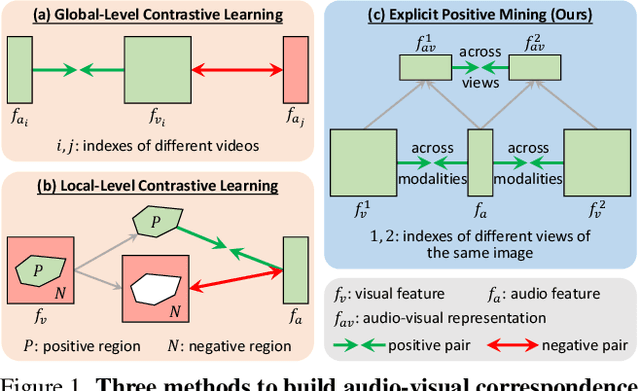
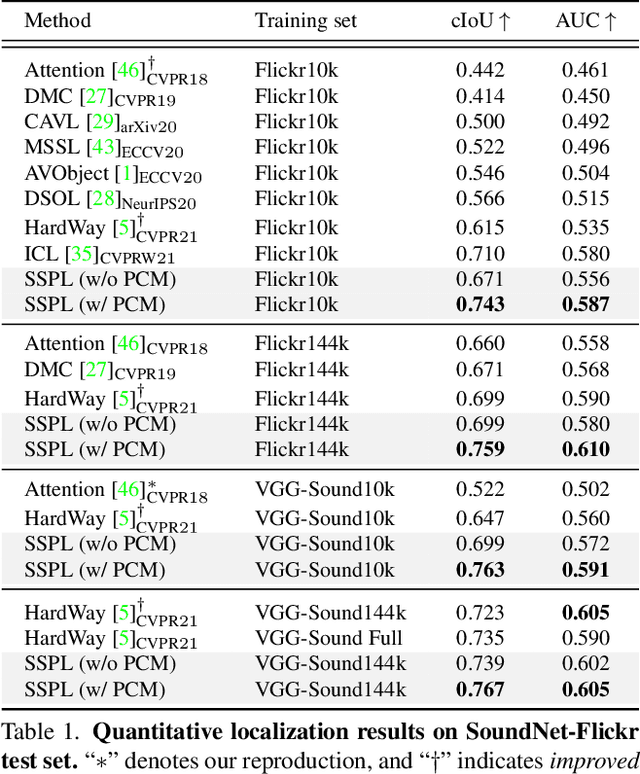
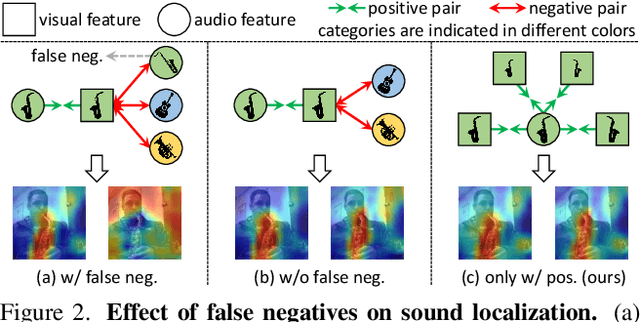
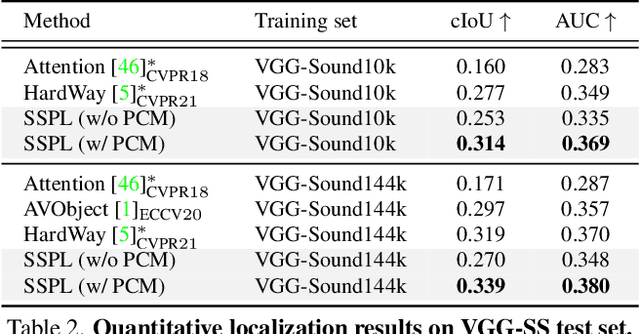
Sound source localization in visual scenes aims to localize objects emitting the sound in a given image. Recent works showing impressive localization performance typically rely on the contrastive learning framework. However, the random sampling of negatives, as commonly adopted in these methods, can result in misalignment between audio and visual features and thus inducing ambiguity in localization. In this paper, instead of following previous literature, we propose Self-Supervised Predictive Learning (SSPL), a negative-free method for sound localization via explicit positive mining. Specifically, we first devise a three-stream network to elegantly associate sound source with two augmented views of one corresponding video frame, leading to semantically coherent similarities between audio and visual features. Second, we introduce a novel predictive coding module for audio-visual feature alignment. Such a module assists SSPL to focus on target objects in a progressive manner and effectively lowers the positive-pair learning difficulty. Experiments show surprising results that SSPL outperforms the state-of-the-art approach on two standard sound localization benchmarks. In particular, SSPL achieves significant improvements of 8.6% cIoU and 3.4% AUC on SoundNet-Flickr compared to the previous best. Code is available at: https://github.com/zjsong/SSPL.
Towards A Controllable Disentanglement Network
Jan 22, 2020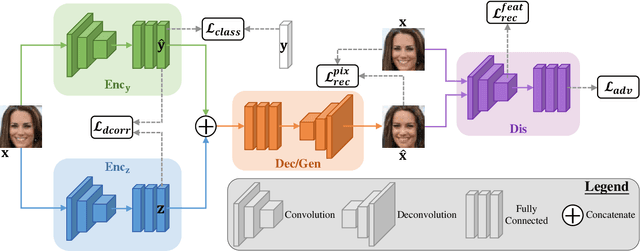
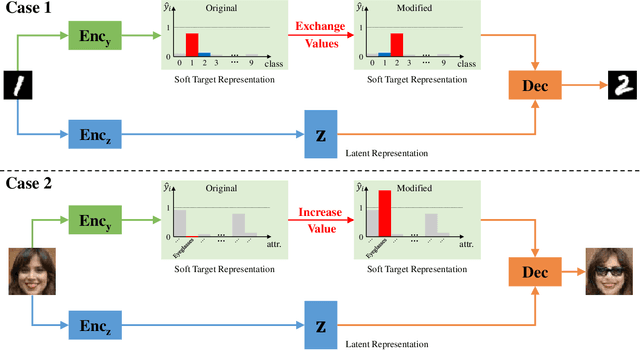


This paper addresses two crucial problems of learning disentangled image representations, namely controlling the degree of disentanglement during image editing, and balancing the disentanglement strength and the reconstruction quality. To encourage disentanglement, we devise a distance covariance based decorrelation regularization. Further, for the reconstruction step, our model leverages a soft target representation combined with the latent image code. By exploring the real-valued space of the soft target representation, we are able to synthesize novel images with the designated properties. To improve the perceptual quality of images generated by autoencoder (AE)-based models, we extend the encoder-decoder architecture with the generative adversarial network (GAN) by collapsing the AE decoder and the GAN generator into one. We also design a classification based protocol to quantitatively evaluate the disentanglement strength of our model. Experimental results showcase the benefits of the proposed model.
Learning Controllable Disentangled Representations with Decorrelation Regularization
Dec 25, 2019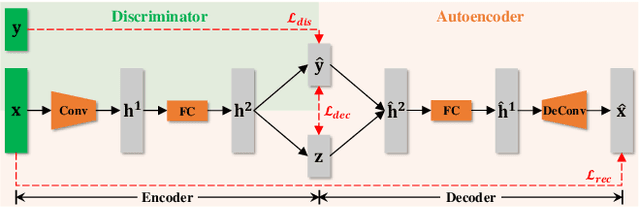
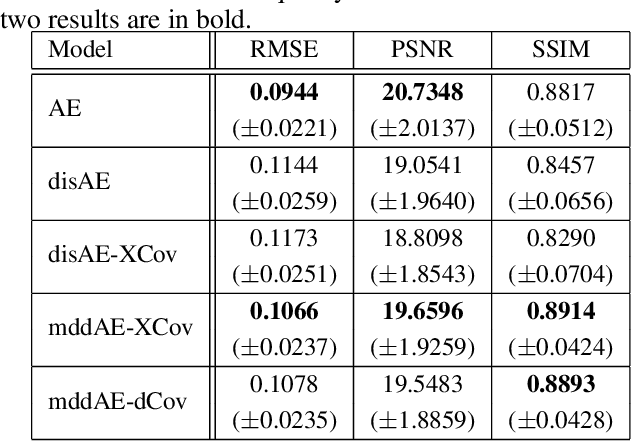
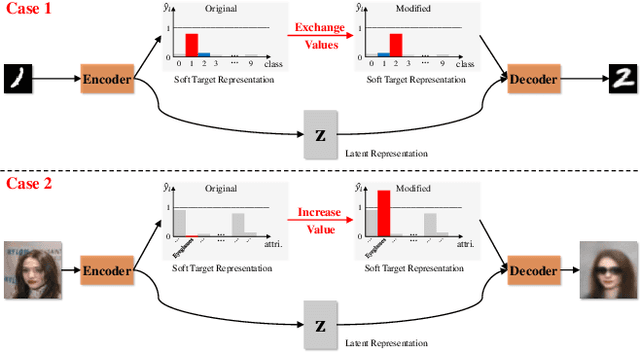
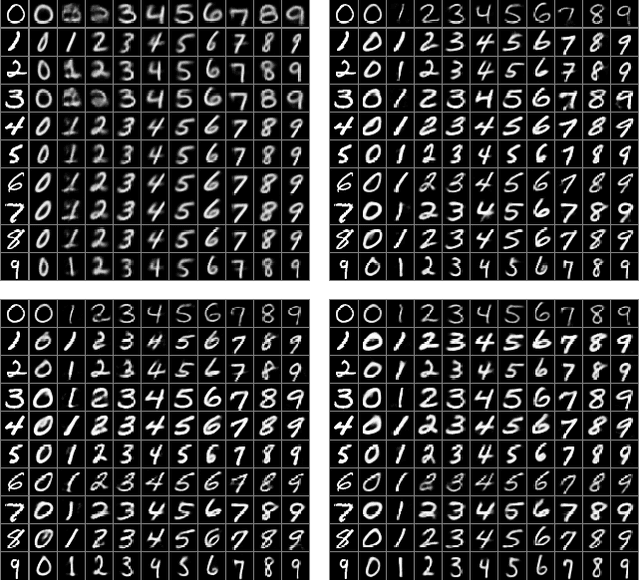
A crucial problem in learning disentangled image representations is controlling the degree of disentanglement during image editing, while preserving the identity of objects. In this work, we propose a simple yet effective model with the encoder-decoder architecture to address this challenge. To encourage disentanglement, we devise a distance covariance based decorrelation regularization. Further, for the reconstruction step, our model leverages a soft target representation combined with the latent image code. By exploiting the real-valued space of the soft target representations, we are able to synthesize novel images with the designated properties. We also design a classification based protocol to quantitatively evaluate the disentanglement strength of our model. Experimental results show that the proposed model competently disentangles factors of variation, and is able to manipulate face images to synthesize the desired attributes.