 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabReason: A Reinforcement Learning-Enhanced Reasoning LLM for Explainable Tabular Data Prediction
May 29, 2025



Predictive modeling on tabular data is the cornerstone of many real-world applications. Although gradient boosting machines and some recent deep models achieve strong performance on tabular data, they often lack interpretability. On the other hand, large language models (LLMs) have demonstrated powerful capabilities to generate human-like reasoning and explanations, but remain under-performed for tabular data prediction. In this paper, we propose a new approach that leverages reasoning-based LLMs, trained using reinforcement learning, to perform more accurate and explainable predictions on tabular data. Our method introduces custom reward functions that guide the model not only toward high prediction accuracy but also toward human-understandable reasons for its predictions. Experimental results show that our model achieves promising performance on financial benchmark datasets, outperforming most existing LLMs.
Attention as an RNN
May 22, 2024



The advent of Transformers marked a significant breakthrough in sequence modelling, providing a highly performant architecture capable of leveraging GPU parallelism. However, Transformers are computationally expensive at inference time, limiting their applications, particularly in low-resource settings (e.g., mobile and embedded devices). Addressing this, we (1) begin by showing that attention can be viewed as a special Recurrent Neural Network (RNN) with the ability to compute its \textit{many-to-one} RNN output efficiently. We then (2) show that popular attention-based models such as Transformers can be viewed as RNN variants. However, unlike traditional RNNs (e.g., LSTMs), these models cannot be updated efficiently with new tokens, an important property in sequence modelling. Tackling this, we (3) introduce a new efficient method of computing attention's \textit{many-to-many} RNN output based on the parallel prefix scan algorithm. Building on the new attention formulation, we (4) introduce \textbf{Aaren}, an attention-based module that can not only (i) be trained in parallel (like Transformers) but also (ii) be updated efficiently with new tokens, requiring only constant memory for inferences (like traditional RNNs). Empirically, we show Aarens achieve comparable performance to Transformers on $38$ datasets spread across four popular sequential problem settings: reinforcement learning, event forecasting, time series classification, and time series forecasting tasks while being more time and memory-efficient.
Pretext Training Algorithms for Event Sequence Data
Feb 16, 2024



Pretext training followed by task-specific fine-tuning has been a successful approach in vision and language domains. This paper proposes a self-supervised pretext training framework tailored to event sequence data. We introduce a novel alignment verification task that is specialized to event sequences, building on good practices in masked reconstruction and contrastive learning. Our pretext tasks unlock foundational representations that are generalizable across different down-stream tasks, including next-event prediction for temporal point process models, event sequence classification, and missing event interpolation. Experiments on popular public benchmarks demonstrate the potential of the proposed method across different tasks and data domains.
OPSurv: Orthogonal Polynomials Quadrature Algorithm for Survival Analysis
Feb 02, 2024This paper introduces the Orthogonal Polynomials Quadrature Algorithm for Survival Analysis (OPSurv), a new method providing time-continuous functional outputs for both single and competing risks scenarios in survival analysis. OPSurv utilizes the initial zero condition of the Cumulative Incidence function and a unique decomposition of probability densities using orthogonal polynomials, allowing it to learn functional approximation coefficients for each risk event and construct Cumulative Incidence Function estimates via Gauss--Legendre quadrature. This approach effectively counters overfitting, particularly in competing risks scenarios, enhancing model expressiveness and control. The paper further details empirical validations and theoretical justifications of OPSurv, highlighting its robust performance as an advancement in survival analysis with competing risks.
RankSim: Ranking Similarity Regularization for Deep Imbalanced Regression
May 30, 2022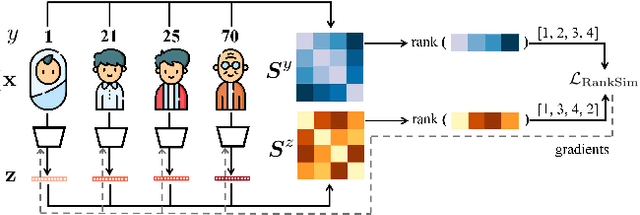
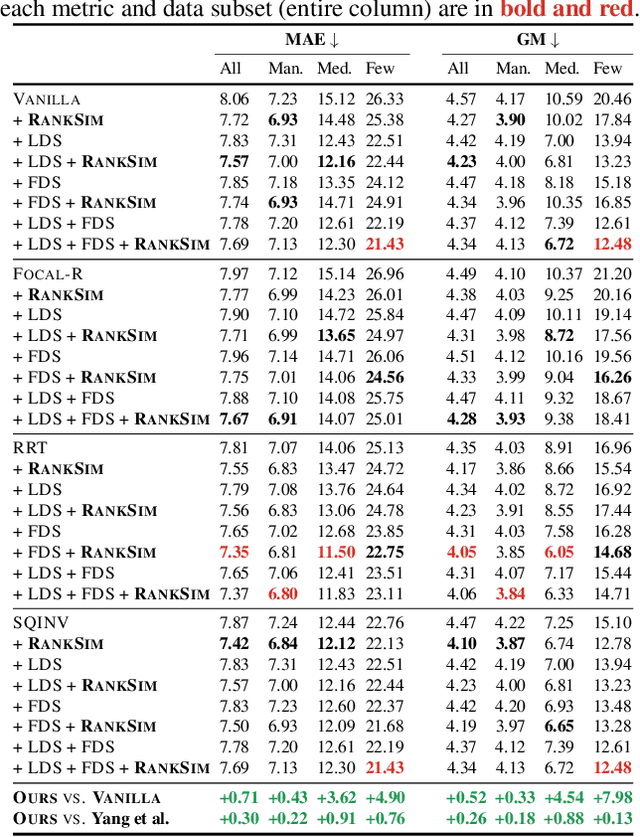
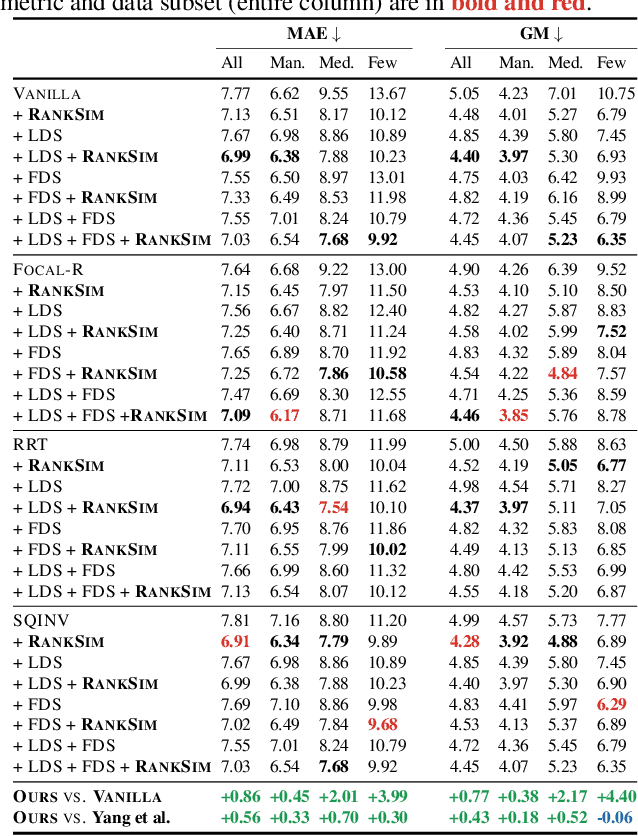

Data imbalance, in which a plurality of the data samples come from a small proportion of labels, poses a challenge in training deep neural networks. Unlike classification, in regression the labels are continuous, potentially boundless, and form a natural ordering. These distinct features of regression call for new techniques that leverage the additional information encoded in label-space relationships. This paper presents the RankSim (ranking similarity) regularizer for deep imbalanced regression, which encodes an inductive bias that samples that are closer in label space should also be closer in feature space. In contrast to recent distribution smoothing based approaches, RankSim captures both nearby and distant relationships: for a given data sample, RankSim encourages the sorted list of its neighbors in label space to match the sorted list of its neighbors in feature space. RankSim is complementary to conventional imbalanced learning techniques, including re-weighting, two-stage training, and distribution smoothing, and lifts the state-of-the-art performance on three imbalanced regression benchmarks: IMDB-WIKI-DIR, AgeDB-DIR, and STS-B-DIR.
Monotonicity Regularization: Improved Penalties and Novel Applications to Disentangled Representation Learning and Robust Classification
May 17, 2022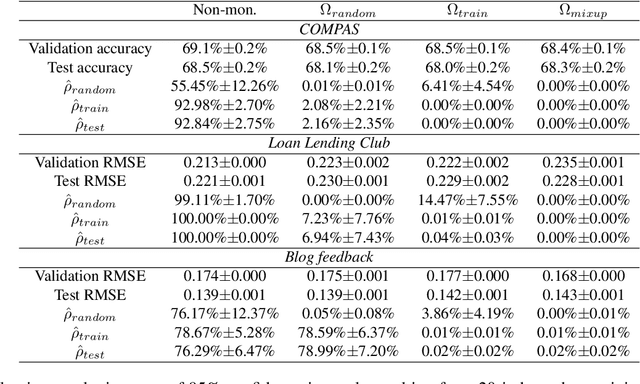


We study settings where gradient penalties are used alongside risk minimization with the goal of obtaining predictors satisfying different notions of monotonicity. Specifically, we present two sets of contributions. In the first part of the paper, we show that different choices of penalties define the regions of the input space where the property is observed. As such, previous methods result in models that are monotonic only in a small volume of the input space. We thus propose an approach that uses mixtures of training instances and random points to populate the space and enforce the penalty in a much larger region. As a second set of contributions, we introduce regularization strategies that enforce other notions of monotonicity in different settings. In this case, we consider applications, such as image classification and generative modeling, where monotonicity is not a hard constraint but can help improve some aspects of the model. Namely, we show that inducing monotonicity can be beneficial in applications such as: (1) allowing for controllable data generation, (2) defining strategies to detect anomalous data, and (3) generating explanations for predictions. Our proposed approaches do not introduce relevant computational overhead while leading to efficient procedures that provide extra benefits over baseline models.
Filtered-CoPhy: Unsupervised Learning of Counterfactual Physics in Pixel Space
Feb 01, 2022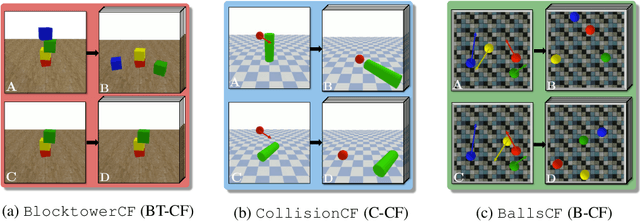
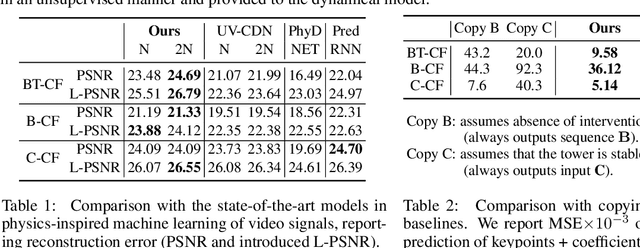
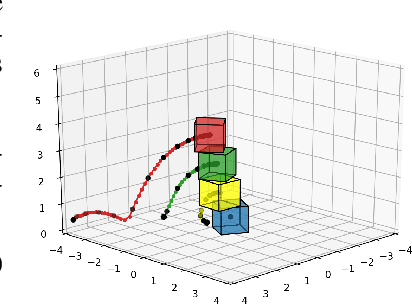
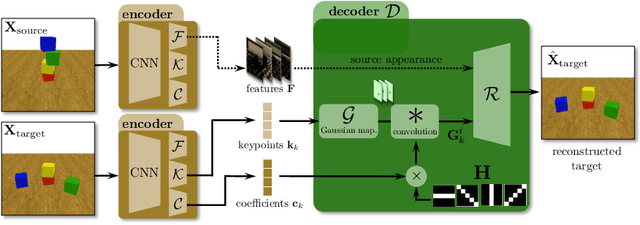
Learning causal relationships in high-dimensional data (images, videos) is a hard task, as they are often defined on low dimensional manifolds and must be extracted from complex signals dominated by appearance, lighting, textures and also spurious correlations in the data. We present a method for learning counterfactual reasoning of physical processes in pixel space, which requires the prediction of the impact of interventions on initial conditions. Going beyond the identification of structural relationships, we deal with the challenging problem of forecasting raw video over long horizons. Our method does not require the knowledge or supervision of any ground truth positions or other object or scene properties. Our model learns and acts on a suitable hybrid latent representation based on a combination of dense features, sets of 2D keypoints and an additional latent vector per keypoint. We show that this better captures the dynamics of physical processes than purely dense or sparse representations. We introduce a new challenging and carefully designed counterfactual benchmark for predictions in pixel space and outperform strong baselines in physics-inspired ML and video prediction.
MUSE: Feature Self-Distillation with Mutual Information and Self-Information
Oct 25, 2021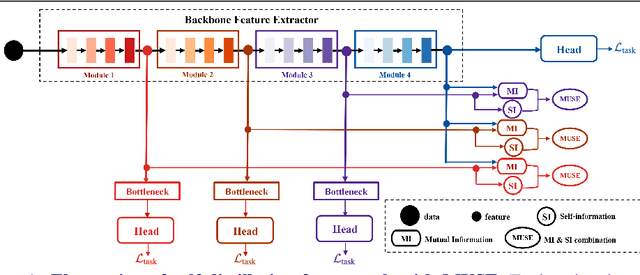
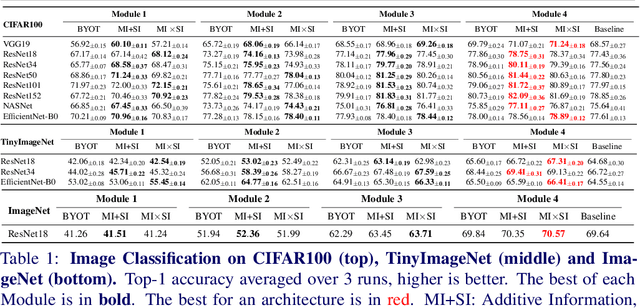

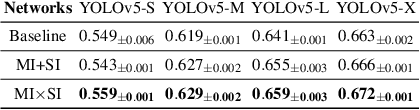
We present a novel information-theoretic approach to introduce dependency among features of a deep convolutional neural network (CNN). The core idea of our proposed method, called MUSE, is to combine MUtual information and SElf-information to jointly improve the expressivity of all features extracted from different layers in a CNN. We present two variants of the realization of MUSE -- Additive Information and Multiplicative Information. Importantly, we argue and empirically demonstrate that MUSE, compared to other feature discrepancy functions, is a more functional proxy to introduce dependency and effectively improve the expressivity of all features in the knowledge distillation framework. MUSE achieves superior performance over a variety of popular architectures and feature discrepancy functions for self-distillation and online distillation, and performs competitively with the state-of-the-art methods for offline distillation. MUSE is also demonstrably versatile that enables it to be easily extended to CNN-based models on tasks other than image classification such as object detection.
D3D-HOI: Dynamic 3D Human-Object Interactions from Videos
Aug 19, 2021

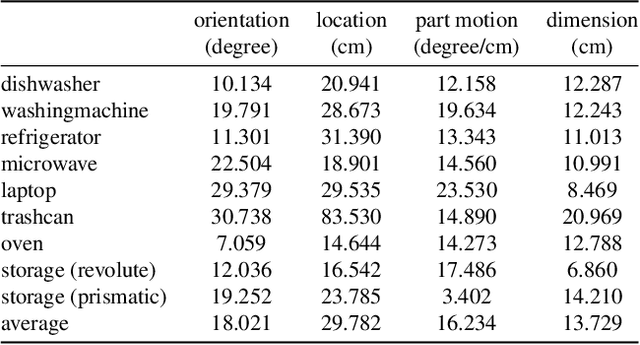

We introduce D3D-HOI: a dataset of monocular videos with ground truth annotations of 3D object pose, shape and part motion during human-object interactions. Our dataset consists of several common articulated objects captured from diverse real-world scenes and camera viewpoints. Each manipulated object (e.g., microwave oven) is represented with a matching 3D parametric model. This data allows us to evaluate the reconstruction quality of articulated objects and establish a benchmark for this challenging task. In particular, we leverage the estimated 3D human pose for more accurate inference of the object spatial layout and dynamics. We evaluate this approach on our dataset, demonstrating that human-object relations can significantly reduce the ambiguity of articulated object reconstructions from challenging real-world videos. Code and dataset are available at https://github.com/facebookresearch/d3d-hoi.
Continuous Latent Process Flows
Jun 29, 2021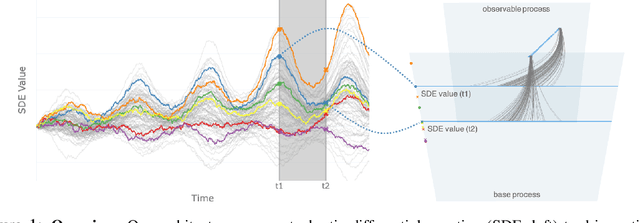
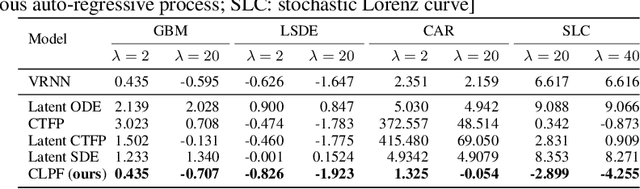
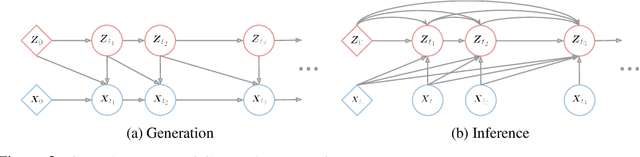
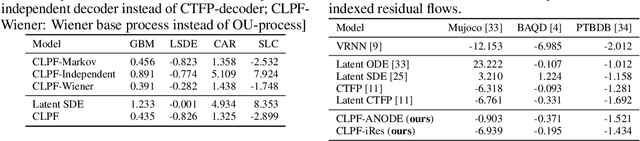
Partial observations of continuous time-series dynamics at arbitrary time stamps exist in many disciplines. Fitting this type of data using statistical models with continuous dynamics is not only promising at an intuitive level but also has practical benefits, including the ability to generate continuous trajectories and to perform inference on previously unseen time stamps. Despite exciting progress in this area, the existing models still face challenges in terms of their representational power and the quality of their variational approximations. We tackle these challenges with continuous latent process flows (CLPF), a principled architecture decoding continuous latent processes into continuous observable processes using a time-dependent normalizing flow driven by a stochastic differential equation. To optimize our model using maximum likelihood, we propose a novel piecewise construction of a variational posterior process and derive the corresponding variational lower bound using trajectory re-weighting. Our ablation studies demonstrate the effectiveness of our contributions in various inference tasks on irregular time grids. Comparisons to state-of-the-art baselines show our model's favourable performance on both synthetic and real-world time-series data.